在进行接口测试时,有时候需要给一个接口传入多组数据,这时候就会用到参数化数据驱动。
HttpRunner v3.x开始,测试用例和测试用例集都可以实现参数化数据驱动,需要使用parameters关键字,定义参数名称并指定数据源取值方式。
数据源有三种,分别是参数列表,CSV文件,自定义函数。
参数列表
独立参数
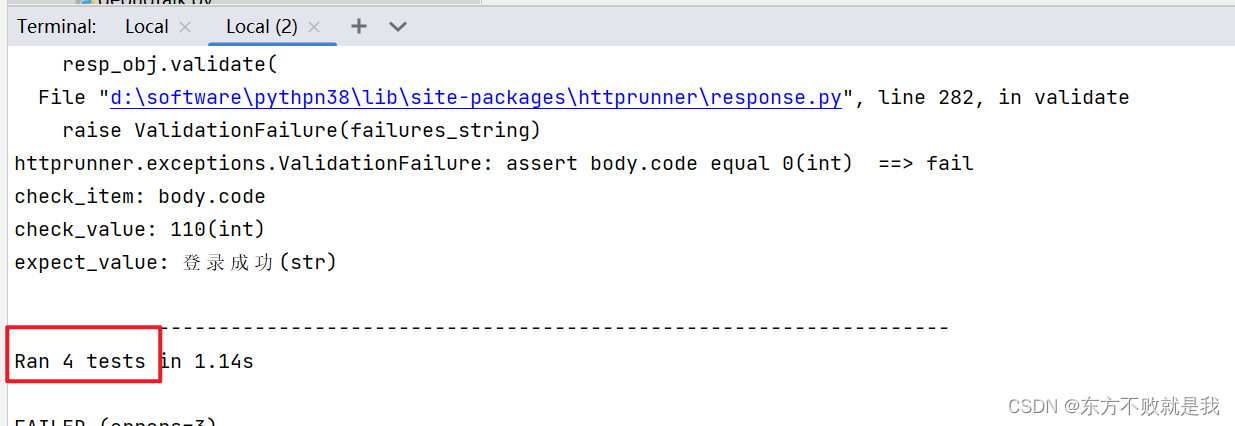
对于单个参数,可以直接传入参数。如下例子,username传入一个列表,每次执行时,会从这个列表取出一个username。
运行这个用例,可以看到一共执行了三个用例,1个通过,2个失败。
config:
name: "登录成功"
variables:
password: tester
expect_foo2: config_bar2
base_url: "https://api.pity.fun"
verify: False
export:
- token
parameters:
username: [tester,tester1,tester2]
teststeps:
-
name: 登录成功
variables:
foo1: bar1
request:
method: POST
url: /auth/login
headers:
Content-Type: "application/json"
json:
{"username":"$username","password":"$password"}
extract:
token: body.data.token
validate:
- eq: ["status_code", 200]
- eq: [body.code,0]
- eq: [body.msg,"登录成功"]
多个参数
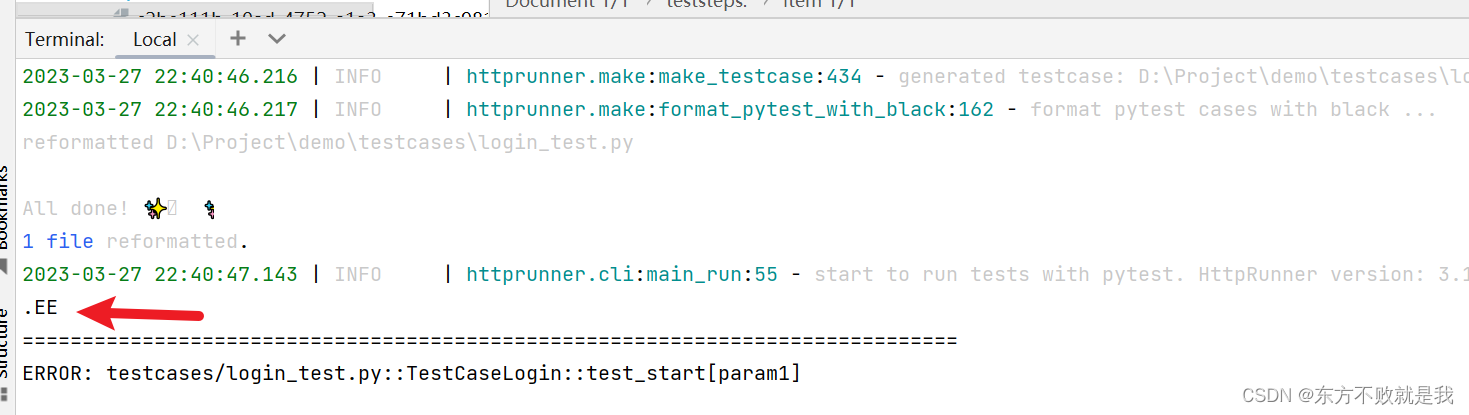
同时传入username和password,多个参数具有关联性的参数需要将其定义在一起,采用短横线(-)进行链接。
config:
name: "登录成功"
variables:
expect_foo2: config_bar2
base_url: "https://api.pity.fun"
verify: False
export:
- token
parameters:
username-password:
- [tester,tester]
- [tester1,tester1]
- [tester2,tester2]
teststeps:
-
name: 登录成功
variables:
foo1: bar1
request:
method: POST
url: /auth/login
headers:
Content-Type: "application/json"
json:
{"username":"$username","password":"$password"}
extract:
token: body.data.token
validate:
- eq: ["status_code", 200]
- eq: [body.code,0]
- eq: [body.msg,"登录成功"]
执行用例,可以看到执行了三条,分别传入了三组数据。
CSV文件传参
CSV 数据文件,需要遵循如下几项约定的规则:
- CSV 文件中的第一行必须为参数名称,从第二行开始为参数值,每个(组)值占一行;
- 若同一个 CSV 文件中具有多个参数,则参数名称和数值的间隔符需实用英文逗号;
- 在 YAML/JSON 文件引用 CSV 文件时,文件路径为基于项目根目录(debugtalk.py 所在路径)的相对路径。
在data目录下新建login.csv,写入测试数据

config:
name: "登录成功"
variables:
expect_foo2: config_bar2
base_url: "https://api.pity.fun"
verify: False
export:
- token
parameters:
username-password: ${P(data/login.csv)}
teststeps:
-
name: 登录成功
variables:
foo1: bar1
request:
method: POST
url: /auth/login
headers:
Content-Type: "application/json"
json:
{"username":"$username","password":"$password"}
extract:
token: body.data.token
validate:
- eq: ["status_code", 200]
- eq: [body.code,0]
- eq: [body.msg,"登录成功"]
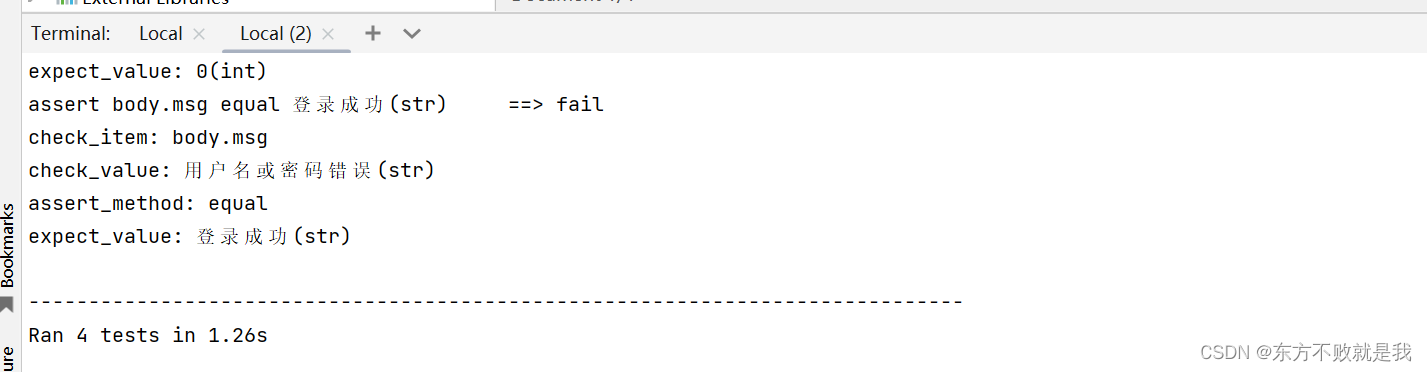
运行测试用例,可以看到执行了四条测试。
自定义函数
独立参数
对于没有现成参数列表,或者需要更灵活的方式动态生成参数的情况,可以通过在 debugtalk.py 中自定义函数生成参数列表,并在 YAML/JSON 引用自定义函数的方式。
例如,若需对 username 进行参数化数据驱动,参数取值范围为tester,tester1,tester2,tester3,那么就可以在 debugtalk.py 中定义一个函数,返回参数列表。
def get_username():
return [
{"username": tester},
{"username": tester1},
{"username": tester2},
{"username": tester3}
]
然后,在 YAML/JSON 的 parameters 中就可以通过调用自定义函数的形式来指定数据源。
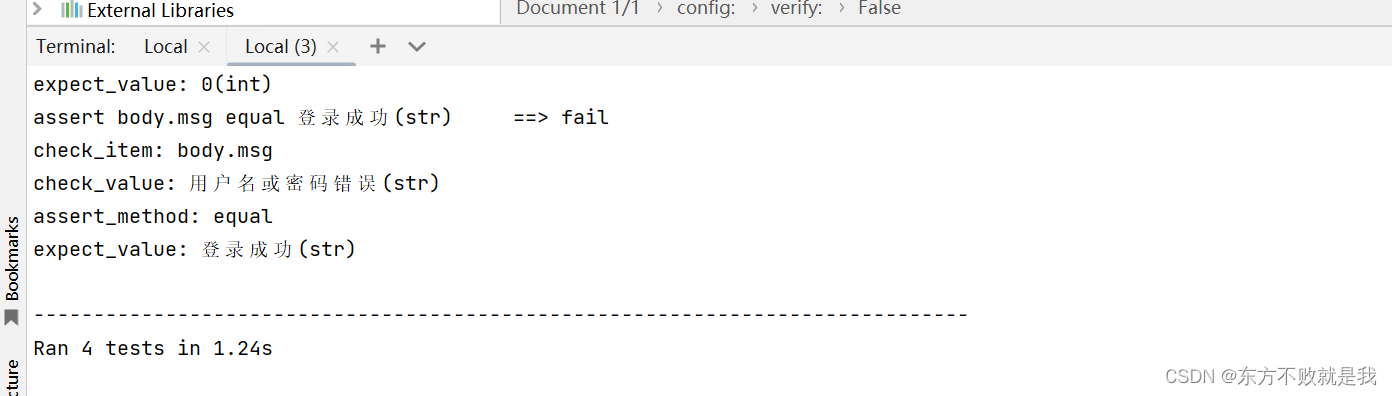
执行用例,可以看到执行了4条。
config:
name: "登录成功"
variables:
password: tester
expect_foo2: config_bar2
base_url: "https://api.pity.fun"
verify: False
export:
- token
parameters:
username: ${get_username()}
teststeps:
-
name: 登录成功
variables:
foo1: bar1
request:
method: POST
url: /auth/login
headers:
Content-Type: "application/json"
json:
{"username":"$username","password":"$password"}
extract:
token: body.data.token
validate:
- eq: ["status_code", 200]
- eq: [body.code,0]
- eq: [body.msg,"登录成功"]
另外,通过函数的传参机制,还可以实现更灵活的参数生成功能,在调用函数时指定需要生成的参数个数。
关联参数
对于具有关联性的多个参数,实现方式也类似。 例如,在debugtalk.py中定义函数get_account,生成指定数量的账号密码参数列表。
def get_account():
accounts = [ {"username": "tester","password":"tester"},
{"username": "tester1","password":"tester"},
{"username": "tester2","password":"tester"},
{"username": "tester3","password":"tester"}]
在YAML/JSON的parameters中就可以调用自定义函数生成指定数量的参数列表
config:
name: "登录成功"
variables:
password: tester
expect_foo2: config_bar2
base_url: "https://api.pity.fun"
verify: False
export:
- token
parameters:
username-password: ${get_account()}
teststeps:
-
name: 登录成功
variables:
foo1: bar1
request:
method: POST
url: /auth/login
headers:
Content-Type: "application/json"
json:
{"username":"$username","password":"$password"}
extract:
token: body.data.token
validate:
- eq: ["status_code", 200]
- eq: [body.code,0]
- eq: [body.msg,"登录成功"]
需要注意的是,在自定义函数中,生成的参数列表必须为 list of dict 的数据结构,该设计主要是为了与 CSV 文件的处理机制保持一致。