文章认为量化会使网络激活值的均值发生偏移,通过对偏移进行修正,可以有效提高量化模型的性能。
首先考虑“激活值的均值偏移”。
网络BN会统计出数据经过某层后的均值和方差信息。
而网络在经过量化后,同样的数据经过该层后,其均值已经不符合原BN统计出的均值,也即数据分布发生了变化(注意BN存在于多个层,这里说的数据分布是泛指各个层的激活,而不仅仅指第一层网络的输入)。
如上图所示,是32张图片经过MobileNet某层某channel后激活值分布情况,Q是量化模型,FP是float模型,可以看到两个数据分布是不一样的,均值会发生偏移。
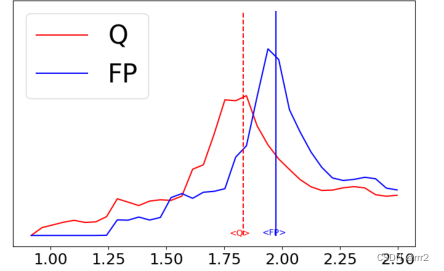
其次感性上理解这个过程:某个channel的均值发生偏移,感性上可以理解为量化模型在该channel上计算出的值会偏大或偏小。那么既然我们知道量化模型某层的激活会偏大或偏小,那么我们就可以对其进行修正。
IBC方法:使用calibration数据,逐层迭代,逐channel进行偏差修正,具体如下:
# IBC伪代码
for:对网络层数进行遍历:
for:对该层channel进行遍历:
偏差deta = 该channel float网络激活值 - 该channel量化网络激活值
量化网络的bias += 偏差deta
end
end
# 注意“该channel float网络激活值”和“该channel量化网络激活值”都是在全部calibration
# 数据下计算出平均激活值,calibration数据集文章说只需要8-64张;
目前在网络量化上,偏差修正已经成了一个较为常见的操作,涨点明显。