摘要:
本次项目主要是对英文文献进行词频统计,利用给定的数据集中已分好的初级、中级、高级三个等级,对英文文献中的单词进行分级处理,并得到各个等级所占比重,画出统计图(饼图)。此项目用到python的模块有:tkinter(用来搭建词频统计的前台界面)、pandas、numpy、operator、matplotlib。第一章主要介绍数据预处理,第二章对功能进行介绍,第三章实现前台界面与功能实现。
一、数据处理
1.导入xlsx数据集

导入后利用head初步查看数据集情况
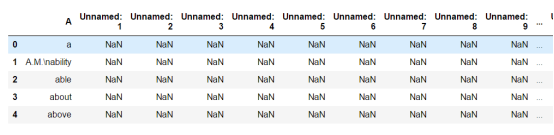
根据显示结果可以看出,数据集中有大量的NaN空值出现,两个单词挤在同一个单元格中的情况,单词前后还有大量的空格等问题,单词无法全部正常读入,这样都会影响后面词频统计和计算各个等级占比,所以下面要对数据进行清洗。
2.查看数据类型

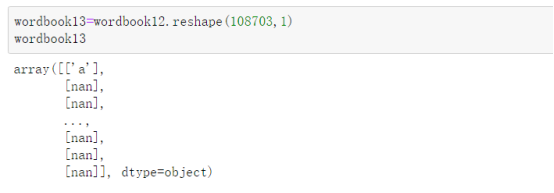
3.多列变为一列
首先要把DataFrame类型转化为Array,然后运用Array中的reshape方法把多列变为一列。

4.去除含有NaN的行
去除NaN需要用到dropna方法,但是dropna方法针对DataFrame类型,所以首先需要把array类型转为DataFrame。


5.定义列名

6.去除特殊符号
单词中含有空格、特殊字符等一些特殊符号,会影响到计算结果。所以我们利用Strip方法对primary数据集进行操作
去空格

去数学符号
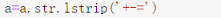
7.分裂数据
单词有多个单词在一个单元格的情况。要对其进行分裂处理,word book1 中可以看到两个单词中间是\n,所以我们用\n来作为标志,来进行分裂。

可以看出单词已从第一列中分离出来,并多出两列进行存放分裂出来的单词,下面把分裂出的单词也都放在第一列。

再次去除数据集中的NaN,得到处理完成的数据集为:primary。

根据处理word book1 的方法,同样处理word book2、word book3,处理完成后的命名分别为middle、senior。
二、功能实现
需要实现三个功能,一个是词频统计,一个是各个等级占比统计,还有统计图的绘制。我选取了一篇英文演讲稿。
1.词频统计

首先把文章中所有的单词转换为小写,然后利用字典遍历文章中所有的单词,计算每一个单词所出现的次数,为了能够更清楚直观的显示,修改词频格式。
结果图:

2.词汇等级统计
此功能为了实现统计文章中的单词都在初、中、高、其他词汇中所占比重。也可以看出文章的难以程度,我们利用For循环遍历整个文章,其中如果单词在数据集primary中则我们给定计数器j加1,如果在数据集middle则给计数器k加1,如果在数据集senior给计数器m加1,剩下的单词则为其他词汇的计数器W所接受,g为总单词数的计数器。最后输出各个计数器数值与总数的比例。代码如下:

结果图:

3.绘制统计图
根据上面词频统计所得到的各个等级的单词数,可以进行绘制统计图。利用matplotlib.pyplot中的pie进行绘制饼图,可以更好的体现各个等级占比数。代码如下:

结果图:

三、前台界面设计与功能实现
Python中前台界面设计需要利用tkinter模块来实现。

首先创建窗口并定义名字和大小。界面设计代码如下:

界面展示:

Entry为输入英文文章框,与词频统计button紧密相连,点击“词频统计”则触发onclick方法,onclick方法为封装好的词频统计功能。其中统计的文章为用户在Entry中输入的英文文章,利用get方法得到输入框内容,来进行统计。统计结果利用insert方法输出到下面的Text文本框中。
实现代码为:

词频统计结果图:

点击“统计每个级别所占比”按钮,运用Buttoon 中的command调用封装好的word_frequency方法,用来计算占比,和绘制统计图。计算的占比显示在下面的Text文本框中。实现代码为:

结果图:

点击“画出统计图”则弹出另一个界面显示所绘制得饼图。界面封装函数代码为:

利用PhotoImage提取打印出的饼图,显示在Label中,并且利用TOPLEVEL重新开启一个新的窗口中显示。得到如图下面得结果。

结论
第二章中我们是给定一个英文文章,然后给定词频统计、各个等级占比、绘制统计图,第三章中利用图形界面我们把这项工作变得智能化。可以输入不同得文章进行词频统计、各个等级占比、绘制统计图。可以说这是个小型得软件程序。通过此次实验中遇到得问题我看到了数据预处理的重要性,它可以直接关系到后面功能的准确度。根据自己不断的优化和清洗数据,使得现在得程序已经基本稳定,数值基本准确。以前没有接触到Tkinter,通过这次学习也对它有了进一步得了解,下一次应该会找一个更大得数据集来对软件进行优化。