1, 网络结构
左边Darknet网络结构,右边YOLOv3网络结构 ,详细解析可参考链接

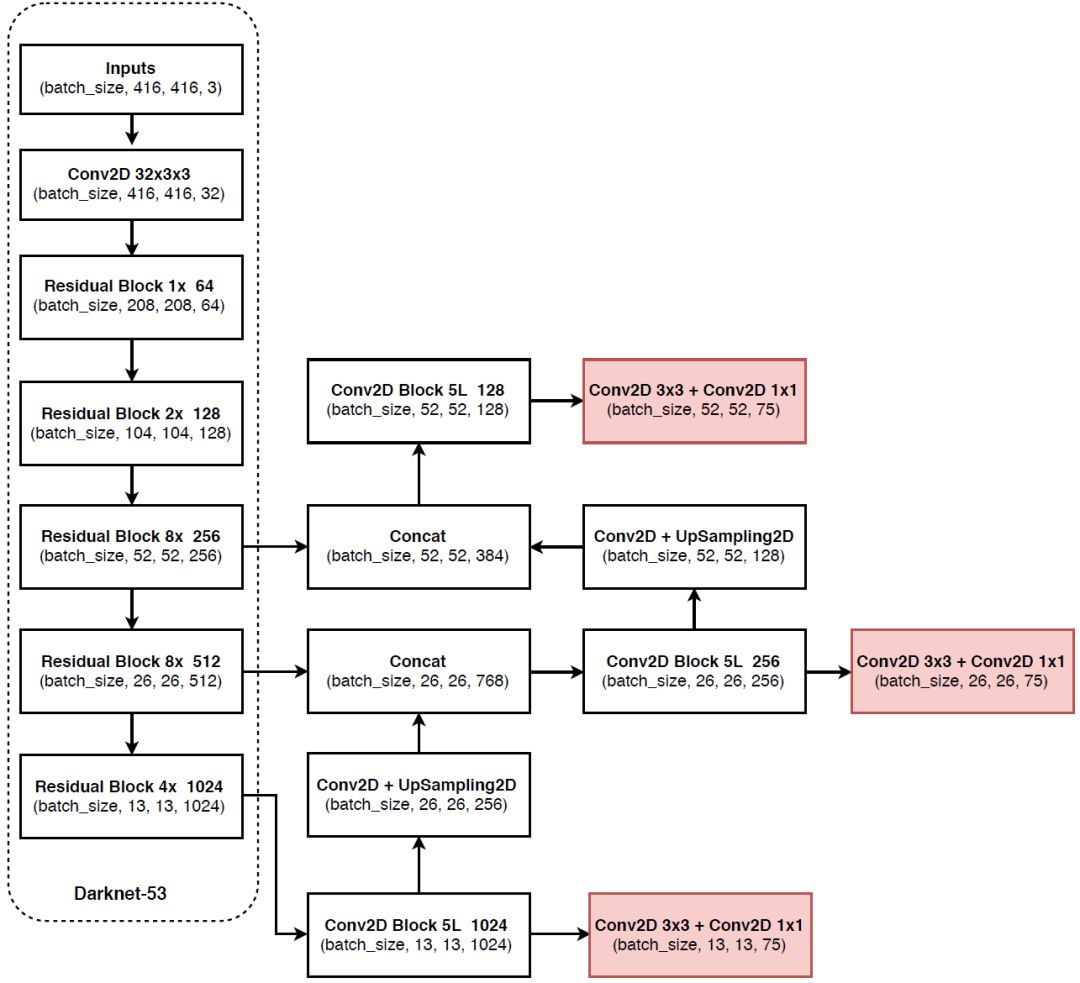
2, pytorch代码实现
darknet53.py
# -*- coding: utf-8 -*-
# @Time : 2020/10/20 下午10:17
# @Author : zxq
# @File : YOLOv3_model.py
# @Software: PyCharm
from collections import OrderedDict
import torch
import torch.nn as nn
class Conv2dBatchLeaky(nn.Module):
""" This convenience layer groups a 2D convolution, a batchnorm and a leaky ReLU.
They are executed in a sequential manner.
对应左图中Convolutional
DarkNet最小子模块
只有stride=1控制特征缩放
Args:
in_channels (int): Number of input channels
out_channels (int): Number of output channels
kernel_size (int or tuple): Size of the kernel of the convolution
stride (int or tuple): Stride of the convolution
negative_slope (number, optional): Controls the angle of the negative slope of the leaky ReLU; Default **0.1**
"""
def __init__(self, in_channels, out_channels, kernel_size, stride, negative_slope=0.1):
super(Conv2dBatchLeaky, self).__init__()
# Parameters
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
# padding, 所以如果stride=1,则不会改变特征的高宽
if isinstance(kernel_size, (list, tuple)):
self.padding = [int(ii / 2) for ii in kernel_size]
else:
self.padding = int(kernel_size / 2) # 向下取整
self.leaky_slope = negative_slope
# Layer,打包
self.layers = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, self.kernel_size, self.stride, self.padding, bias=False),
nn.BatchNorm2d(self.out_channels), # , eps=1e-6, momentum=0.01),
nn.LeakyReLU(self.leaky_slope, inplace=True)
)
def forward(self, x):
x = self.layers(x) # 因为打包好了,这里只需一句搞定
return x
class ResBlock(nn.Module):
def __init__(self, in_channels):
"""
残差块
每个BasizeBlock由两次conv+bn+leakyReLU组成
特征图的通道数变化: in_channels -> in_channels//2 -> in_channels
:param in_channels: 输入x特征图的通道数
"""
super(ResBlock, self).__init__()
# in_channels -> in_channels // 2,channel维度降维,减少参数目的,这也是为什么两次卷积后再残差的原因。
self.conv1 = Conv2dBatchLeaky(in_channels, in_channels // 2, kernel_size=1, stride=1, negative_slope=0.1)
# in_channels//2 -> in_channels
self.conv2 = Conv2dBatchLeaky(in_channels // 2, in_channels, kernel_size=3, stride=1, negative_slope=0.1)
def forward(self, x):
input_feature = x # in_channels = 64, 则out_channels=32
x = self.conv1(x) # -> in_channels//2
x = self.conv2(x) # -> channels=64
x += input_feature # 残差块:输入的特征加上两次卷积后的特征,作为下一个残差块的输入。
return x
class DarkNet(nn.Module):
def __init__(self, layers):
"""
DarkNet由5个模块组成,每个模块又由多个残差块组成
:param layers: list. len(layers)==5,每个数字代表各个模块的残差块个数,可以用来控制模型的大小。
eg.
Darknet53, layers==[1, 2, 8, 8, 4]
"""
super(DarkNet, self).__init__()
start_channel = 32 # 第一个卷积后的特征图通道数,这里固定 # c= 32
self.conv = Conv2dBatchLeaky(in_channels=3, out_channels=start_channel, kernel_size=3, stride=1) # 高宽不变
# 定义5个模块,每个模块前面都有一个卷积用于高宽的下采样,同时通道数翻倍。每个模块不会改变特征维度,包括h,w,c。
self.conv1 = Conv2dBatchLeaky(in_channels=start_channel, out_channels=start_channel * 2, kernel_size=3, stride=2) # 32->64
self.layer1 = self._build_layer(input_channels=start_channel * 2, num_res_block=layers[0]) # 64->64
self.conv2 = Conv2dBatchLeaky(in_channels=start_channel * 2, out_channels=start_channel * 4, kernel_size=3, stride=2) # ->128
self.layer2 = self._build_layer(input_channels=start_channel * 4, num_res_block=layers[1]) # 128->128
self.conv3 = Conv2dBatchLeaky(in_channels=start_channel * 4, out_channels=start_channel * 8, kernel_size=3, stride=2) # ->256
self.layer3 = self._build_layer(input_channels=start_channel * 8, num_res_block=layers[2]) # 256->256
self.conv4 = Conv2dBatchLeaky(in_channels=start_channel * 8, out_channels=start_channel * 16, kernel_size=3, stride=2) # ->512
self.layer4 = self._build_layer(input_channels=start_channel * 16, num_res_block=layers[3]) # 512->512
self.conv5 = Conv2dBatchLeaky(in_channels=start_channel * 16, out_channels=start_channel * 32, kernel_size=3, stride=2) # ->1024
self.layer5 = self._build_layer(input_channels=start_channel * 32, num_res_block=layers[4]) # 1024->1024
self.output_channels = [start_channel * 2, # 64 layer1
start_channel * 4, # 128 layer2
start_channel * 8, # 256
start_channel * 16, # 512
start_channel * 32, ] # 1024
@staticmethod
def _build_layer(input_channels, num_res_block=1):
"""
建议DarkNet子模块
每个子模块都是由多个残差块组成
:param input_channels: 输入特征的通道数
:param num_res_block: 子模块的残差块个数。
:return:
"""
layers = []
for i in range(0, num_res_block):
layers.append(("res_block_{}".format(i), ResBlock(in_channels=input_channels)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv(x) # [b,3,416,416] -> [b,32,416,416]
x = self.conv1(x) # [b,32,416,416] -> [b,64,208,208]
x = self.layer1(x) # 维度不变
x = self.conv2(x) # [b,64,208,208] -> [b,128,104,104]
x = self.layer2(x)
x = self.conv3(x) # [b,128,104,104] -> [b,256,52,52]
out3 = self.layer3(x)
out4 = self.conv4(out3) # [b,256,52,52] -> [b,512,26,26]
out4 = self.layer4(out4)
out5 = self.conv5(out4) # [b,512,26,26] -> [b,1024,13,13]
out5 = self.layer5(out5)
return out3, out4, out5 # [b,256,52,52], [b,512,26,26], [b,1024,13,13]
def darknet53(pretrained, **kwargs):
model = DarkNet([1, 2, 8, 8, 4])
if pretrained: # 如果不用,则False,如果用,则必须是权重路径
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request pretrained path. got [{}]".format(pretrained))
return model
yolov3_module.py
# -*- coding: utf-8 -*-
# @Time : 2020/10/22 下午10:10
# @Author : zxq
# @File : yolov3_module.py
# @Software: PyCharm
import torch
import torch.nn as nn
import torch.nn.functional as F
import yaml
from backbone.darknet53 import Conv2dBatchLeaky, darknet53
class Conv2dBlock5L(nn.Module):
"""
对应网络结构图中的Conv2D Block 5L,具体功能是6个conv+bn+leakyReLU,
为什么叫5L,我猜是输出通道有5次是在c1和c2两种之间变换
只改变通道数
"""
def __init__(self, in_channels, out_channels):
"""
:param in_channels: 前面DarkNet输出的特征图通道数
:param out_channels: list. [c1, c2]. 通道数就在c1和c2之间变化,最后输出c2通道数
然后5个卷积的通道数就在in_channels和in_channels//2两者间变化
"""
super(Conv2dBlock5L, self).__init__()
conv = Conv2dBatchLeaky(in_channels=in_channels, out_channels=out_channels[0], kernel_size=1, stride=1) # 降维,减少计算量
conv1 = Conv2dBatchLeaky(in_channels=out_channels[0], out_channels=out_channels[1], kernel_size=3, stride=1)
conv2 = Conv2dBatchLeaky(in_channels=out_channels[1], out_channels=out_channels[0], kernel_size=1, stride=1)
conv3 = Conv2dBatchLeaky(in_channels=out_channels[0], out_channels=out_channels[1], kernel_size=3, stride=1)
conv4 = Conv2dBatchLeaky(in_channels=out_channels[1], out_channels=out_channels[0], kernel_size=1, stride=1)
conv5 = Conv2dBatchLeaky(in_channels=out_channels[0], out_channels=out_channels[1], kernel_size=3, stride=1)
self.out_channels = out_channels[1]
# 打包下,省得在forward重复写
self.layers = nn.Sequential(
conv,
conv1,
conv2,
conv3,
conv4,
conv5
)
def forward(self, x):
x = self.layers(x)
return x
class Upsample(nn.Module):
""" nn.Upsample is deprecated """
def __init__(self, scale_factor, mode="nearest"):
super(Upsample, self).__init__()
self.scale_factor = scale_factor
self.mode = mode
def forward(self, x):
x = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode)
return x
class YOLOv3(nn.Module):
def __init__(self, config):
super(YOLOv3, self).__init__()
self.backbone = darknet53(pretrained=False)
# num_anchors * (5+num_classes): 3 * (5+ 80) = 255
anchors = config['yolo']['anchor'] # [10,13, 16,30, 33,23, 30,61, 62,45, ...] # 9个
self.anchors = [(anchors[i], anchors[i + 1]) for i in
range(0, len(anchors) - 1, 2)] # [(10,13), (16,30), ...]
num_anchors = len(self.anchors) // 3 # 平均分成3份
num_classes = config['yolo']['classes']
# 默认每个输出层的anchor个数都是len(config['yolo']['anchor'][0]),
# 对于每个输出层的所有位置输出属性维度: coco: 3x85=255, 图中是3x(5+20)=75
self.final_out_channels = num_anchors * (5 + num_classes)
# 1, stride 32
# output_channels[-1]是DarkNet最后一层输出, 这里layer5对应的尺度是DarkNet第5个模块的输出尺度
self.block_layer5 = Conv2dBlock5L(in_channels=self.backbone.output_channels[-1], out_channels=[512, 1024])
# yolo layer,这里使用1x1卷积,简单的把channels修改为self.final_out_channels
self.conv1x1_out5 = nn.Conv2d(in_channels=self.block_layer5.out_channels, out_channels=self.final_out_channels,
kernel_size=1, stride=1, padding=0, bias=True)
# 2, stride 16
# 对应结构图中的Conv2D + UpSampling2D, 其中conv用来修改通道数,upsample用来修改高宽尺度
# channels: -> 256
self.conv5 = Conv2dBatchLeaky(in_channels=self.block_layer5.out_channels, out_channels=256, kernel_size=1,
stride=1)
# upSample: 13x13 -> 26x26
self.up_sample = Upsample(scale_factor=2, mode='nearest')
# concat up_sample4 + backbone.out4
in_channels = self.backbone.output_channels[-2] + 256 # 512+256=768
# yolo layer 4
self.block_layer4 = Conv2dBlock5L(in_channels=in_channels, out_channels=[256, 512]) # 768->512
self.conv1x1_out4 = nn.Conv2d(in_channels=self.block_layer4.out_channels, out_channels=self.final_out_channels,
kernel_size=1, stride=1, padding=0, bias=True)
# 3, stride 8
self.conv4 = Conv2dBatchLeaky(in_channels=self.block_layer4.out_channels, out_channels=128, kernel_size=1,
stride=1) # 512 -> 128
# up_sample3: 26x26 -> 52x52
# concat: up_sample3 + backbone.out3
in_channels = self.backbone.output_channels[-3] + 128 # 256+128=384
# yolo layer 3
self.block_layer3 = Conv2dBlock5L(in_channels=in_channels, out_channels=[128, 256]) # channels: -> 256
self.conv1x1_out3 = nn.Conv2d(in_channels=self.block_layer3.out_channels, out_channels=self.final_out_channels,
kernel_size=1, stride=1, padding=0, bias=True)
def forward(self, x):
backbone_out3, backbone_out4, backbone_out5 = self.backbone(x) # [b,256,52,52],[b,512,26,26],[b,1024,52,52]
# stride 32
block_out5 = self.block_layer5(backbone_out5) # [b,1024,13,13]. chw都没变,1024,13,13
yolo_out5 = self.conv1x1_out5(block_out5) # [b,1024,13,13]->[b,255,13,13]省去了一步conv3x3,这里通过1x1的卷积输出固定channel的特征图
# stride 16
x = self.conv5(block_out5) # [b,1024,13,13] -> [b,256,13,13]
x = self.up_sample(x) # [b,256,13,13] -> [b,256,26,26]
x = torch.cat([backbone_out4, x], 1) # backbone_out4: [b,512,26,26], x: [b,256,26,26] -> [b,768,26,26]
block_out4 = self.block_layer4(x) # [b,768,26,26] -> [b,512,26,26], 图中是变成[256]
yolo_out4 = self.conv1x1_out4(block_out4) # [b,512,26,26] -> [b,255,26,26]
# stride 8
x = self.conv4(block_out4) # [b,512,26,26] -> [b,128,26,26]
x = self.up_sample(x) # [b,128,26,26] -> [b,128,52,52]
x = torch.cat([backbone_out3, x], 1) # backbone_out3: [b,256,52,52], x: [b,128,52,52] -> [b,384,52,52]
block_out3 = self.block_layer3(x) # [b,384,52,52] -> [b,256,52,52]
yolo_out3 = self.conv1x1_out3(block_out3) # [b,256,52,52] -> [b,255,52,52]
return yolo_out3, yolo_out4, yolo_out5
if __name__ == '__main__':
cfg_dict = yaml.load(open('./config/cfg.yaml'), Loader=yaml.SafeLoader)
yolo_module = YOLOv3(config=cfg_dict)
x = torch.Tensor(4, 3, 416, 416)
output3, output4, output5 = yolo_module(x)
print(output3.shape, output4.shape, output5.shape)
yolov3_loss.py
# -*- coding: utf-8 -*-
# @Time : 2020/10/23 下午10:10
# @Author : zxq
# @File : yolov3_loss.py
# @Software: PyCharm
import math
import torch
import torch.nn as nn
import numpy as np
from utils.utils import bbox_iou
class YOLOLoss(nn.Module):
def __init__(self, image_size, num_classes, anchors):
super(YOLOLoss, self).__init__()
self.image_size = image_size # 原始图片大小: (x, y)
self.num_classes = num_classes # 检测目标类别数
self.anchors = anchors # [[x1, y1], [x2, y2], [x3, y3] 在原图上的尺度
self.num_anchors = len(anchors)
self.bbox_attrs = 5 + num_classes # num_classes: 类别个数, bbox_attrs:属性个数。(x,y,w,h,conf,c0,c1,c2,...,c79)
self.ignore_threshold = 0.5
self.lambda_xy = 2.5
self.lambda_wh = 2.5
self.lambda_conf = 1.0
self.lambda_cls = 1.0
self.bce_loss = nn.BCELoss()
self.mse_loss = nn.MSELoss()
def forward(self, input, targets=None):
"""
:param input: [b, c, h, w]
:param targets: [b, num_gt, num_attr]. attr = [cls, x_ratio, y_ratio, w_ratio, h_ratio]. 存放的是比例, x_r = x/img_w
:return:
"""
batch_size = input.shape[0]
in_h = input.shape[2]
in_w = input.shape[3]
stride_h = self.image_size[1] / in_h # 高下采样的倍数
stride_w = self.image_size[0] / in_w
# 原图缩放了,anchor也要缩放对应的倍数,获取在特征图上的anchors
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors] # anchors缩放到对应的yolo输出层
# [b,c,h,w] -> [b,num_anchors, bbox_attr,h,w] -> [b,num_anchors, h,w, bbox_attr]
prediction = input.view(batch_size, self.num_anchors, self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4,
2).contiguous()
# Get outputs attr
# [b,num_anchors,h,w,bbox_attr] -> [b, num_anchors,h,w] 中心坐标相对于cell左上角的偏移量 (0,1)之间
x = torch.sigmoid(prediction[..., 0]).cuda()
y = torch.sigmoid(prediction[..., 1]).cuda() # -> [b, num_anchors,h,w] Center y
w = prediction[..., 2].cuda() # -> [b, num_anchors,h,w]
h = prediction[..., 3].cuda() # -> [b, num_anchors,h,w]
conf = torch.sigmoid(prediction[..., 4]).cuda() # 目标概率
pred_cls = prediction[..., 5:].cuda() # [b, num_anchors, h,w, num_classes]类别概率
# train
if targets is not None:
mask, noobj_mask, tx, ty, tw, th, tconf, tcls = \
self.build_target(targets, scaled_anchors, in_w, in_h, self.ignore_threshold)
mask, noobj_mask = mask.cuda(), noobj_mask.cuda()
tx, ty, tw, th = tx.cuda(), ty.cuda(), tw.cuda(), th.cuda()
tconf, tcls = tconf.cuda(), tcls.cuda()
# loss
# 1 location loss
# x.shape: [b, num_anchors,h,w]. mask.shape: [b, num_anchors,h,w]
loss_x = self.bce_loss(x * mask, tx * mask) # x*mask: 预测的偏移量, tx: 标注的偏移量。mask值为1的位置是最佳anchor的位置
loss_y = self.bce_loss(y * mask, ty * mask)
loss_w = self.mse_loss(w * mask, tw * mask)
loss_h = self.mse_loss(h * mask, th * mask)
# 2 object loss
# mask值为1的位置是有目标的cell,noobj_mask值为1的位置是没有目标的cell。
loss_conf = self.bce_loss(conf * mask, mask) + 0.5 * self.bce_loss(conf * noobj_mask, noobj_mask * 0.0)
# 3 class loss
# pred_cls.shape: [2,3,52,52,80], mask.shape: [2,3,52,52]
loss_cls = self.bce_loss(pred_cls[mask == 1], tcls[mask == 1]) # pred_cls[mask == 1].shape: [num_obj, 80]
# total loss = losses * weight
loss = (loss_x + loss_y) * self.lambda_xy + \
(loss_w + loss_h) * self.lambda_wh + \
loss_conf * self.lambda_conf + \
loss_cls * self.lambda_cls
return loss, loss_x.item(), loss_y.item(), loss_w.item(), loss_h.item(), loss_conf.item(), loss_cls.item()
# detect
else:
pass
def build_target(self, target, anchors, in_w, in_h, ignore_threshold):
"""
:param target: [b, num_gt, num_attr]. attr = [cls, x_ratio, y_ratio, w_ratio, h_ratio]. 标注的gt box信息
:param anchors: list. [(w1, h1), (w2, h2), (w3, h3)]. 在特征图尺度上的anchor
:param in_w: 预测的特征图宽
:param in_h: 预测的特征图高
:param ignore_threshold: 计算标注的gt_bbox和3个anchor_box之间的iou,找到比较合适的anchor用于训练;
长方形的目标,最好不要用竖直的anchor训练。
:return:
mask: bool. mask[b, best_anchor_index, gj, gi] = 1. 值为1的地方,就是对应cell最佳的anchor
noobj_mask: bool. noobj_mask[b, anchor_ious > ignore_threshold, gj, gi] = 0, 值为1的地方,没有目标
tx: tx[b, best_anchor_index, gj, gi] = gx - gi 存放相对于cell(gj, gj)左上角的偏移量, 网络学习的是偏移量
ty: ty[b, best_anchor_index, gj, gi] = gy - gj
tw: tw[b, best_anchor_index, gj, gi] = math.log(gw / anchors[best_n][0] + 1e-16),网络学习的是log(gw/aw)
th: th[b, best_anchor_index, gj, gi] = math.log(gh / anchors[best_n][1] + 1e-16)
tconf: tconf[b, best_n, gj, gi] = 1
tcls: tcls[b, best_n, gj, gi, int(target[b, t, 0])] = 1
"""
batch_size = target.shape[0]
mask = torch.zeros(batch_size, self.num_anchors, in_h, in_w,
requires_grad=False) # [b,num_anchors,w,h]. [2,3,52,52]
noobj_mask = torch.ones(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
tx = torch.zeros(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
ty = torch.zeros(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
tw = torch.zeros(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
th = torch.zeros(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
tconf = torch.zeros(batch_size, self.num_anchors, in_h, in_w, requires_grad=False) # [b,num_anchors,w,h]
# [b,num_anchors,w,h, num_cls]
tcls = torch.zeros(batch_size, self.num_anchors, in_h, in_w, self.num_classes,
requires_grad=False) # [2,3,52,52,80]
for b in range(batch_size): # 遍历batch中的每个图像
for t in range(target.shape[1]): # 遍历图像中的所有目标
if target[b, t].sum() == 0: # 当前图像中没有目标,每张图片的目标个数可能不同,组成batch时进行了填0操作
continue
# 标注存放的x_ratio,y_ratio,w_ratio,h_ratio值是相对于原始图像的比例值,
# 获取在特征图尺度下的gt标注bbox信息
gx = target[b, t, 1] * in_w # float. 在特征层尺度的gt x坐标。tensor(0.3282) × 52 = 17.06
gy = target[b, t, 2] * in_h # tensor(0.7696) * 52 = 40.02
gw = target[b, t, 3] * in_w # 在特征层尺度上的高. tensor(0.4632) * 52 = 24.08
gh = target[b, t, 4] * in_h # 12.59
# Get grid box indices
# 17.06, 40.02 -> 17, 40
gi = int(gx) # 对特征图上的坐标gx向下取整
gj = int(gy) # (gi, gj)就是有目标的网格
# Get shape of gt box
# tensor([ 0.0000, 0.0000, gw, gh]) -> tensor([[ 0.0000, 0.0000, gw, gh]])
gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0) # tensor([[ 0.0000, 0.0000, 24.0841, 12.5948]])
# Get shape of anchor box
# ->(3, 4). 每一行是类似于[0. , 0. , 2.2, 3.4]的anchor宽高信息。
anchor_box = torch.FloatTensor(np.concatenate((np.zeros((self.num_anchors, 2)),
np.array(anchors)), 1))
# Calculate iou between gt and anchor shapes
"""
gt_box = tensor([[0.0000, 0.0000, gw, gh]])
anchor_box = tensor([[0.0000, 0.0000, 2.2000, 3.4000],
[0.0000, 0.0000, 4.2000, 5.1000],
[0.0000, 0.0000, 2.3000, 6.5000]])
"""
anchor_ious = bbox_iou(gt_box, anchor_box) # gt_box.shape: (1,4). anchor_box.shape: (3,4)
# Where the overlap is larger than threshold set mask to zero (ignore)
noobj_mask[b, anchor_ious > ignore_threshold, gj, gi] = 0 # noobj_mask值为1就没有目标,ignore_threshold越大,值为1的越多
# Find the best matching anchor box
best_anchor_index = np.argmax(anchor_ious)
# masks
mask[b, best_anchor_index, gj, gi] = 1 # 最合适的anchor索引
# Coordinates tx, ty
tx[b, best_anchor_index, gj, gi] = gx - gi # 存放相对于cell左上角的偏移量
ty[b, best_anchor_index, gj, gi] = gy - gj
# Width and height tw, th
tw[b, best_anchor_index, gj, gi] = math.log(gw / anchors[best_anchor_index][0] + 1e-16)
th[b, best_anchor_index, gj, gi] = math.log(gh / anchors[best_anchor_index][1] + 1e-16)
# object
tconf[b, best_anchor_index, gj, gi] = 1
# One-hot encoding of label
tcls[b, best_anchor_index, gj, gi, int(target[b, t, 0])] = 1
return mask, noobj_mask, tx, ty, tw, th, tconf, tcls
if __name__ == '__main__':
loss_module = YOLOLoss(image_size=(416, 416), num_classes=80, anchors=[[116, 90], [156, 198], [373, 326]])
net_output = torch.rand(2, 255, 52, 52) * 10 # out5层的输出特征
target1 = torch.FloatTensor([[16, 0.328250, 0.769577, 0.463156, 0.242207],
[1, 0.128828, 0.375258, 0.249063, 0.733333],
[0, 0.521430, 0.258251, 0.021172, 0.060869]])
target2 = torch.FloatTensor([[59, 0.510930, 0.442073, 0.978141, 0.872188],
[77, 0.858305, 0.073521, 0.074922, 0.059833],
[0, 0.569492, 0.285235, 0.024547, 0.122254]])
# [b, num_gt, num_attr]. [b, num_gt, cls, x_ratio, y_ratio, w_ratio, h_ratio]
targets = torch.cat((target1.unsqueeze(0), target2.unsqueeze(0)), 0) # [2, 2, 5]
loss = loss_module(input=net_output, targets=targets) # [b, num_gt, cls, x_r, y_r, w_r, h_r]
train.py
import torch
import yaml
from yolov3_module import YOLOv3
if __name__ == '__main__':
cfg_dict = yaml.load(open('./config/cfg.yaml'), Loader=yaml.SafeLoader)
yolo_module = YOLOv3(config=cfg_dict)
x = torch.Tensor(4, 3, 416, 416)
output3, output4, output5 = yolo_module(x)
print(output3.shape, output4.shape, output5.shape)
# YOLO loss with 3 scales
yolo_loss = []
待续。。。