在数据建模过程中,尤其是通过线性回归、逻辑回归等传统机器学习算法进行模型训练之前,往往需要对样本数据进行清洗,其中缺失值处理是一种常用方法。根据特征的类别属性与缺失特点,采用合适的方法进行缺失处理,可以有效提升模型拟合的效果,甚至在某些场景下,缺失值处理是作为模型拟合样本的前提步骤。
对于缺失值的处理方式,从难易程度可以分为“简单”和“复杂”两个方面,“简单”主要是指根据常用的统计指标进行缺失值填充,例如平均值、最大值、最小值、众数、中位数等;“复杂”主要是结合相关算法进行处理,例如极大似然估计、贝叶斯估计、决策树模型等,具体使用哪一种方法都是需要根据样本数据情况而定,但在实际业务中,经常采用的是“简单”方式,即采用平均值、众数等指标进行填充。
1、原理逻辑描述
当采用常规方法实现缺失值的处理后,虽然达到了关于数据清洗的需求,但是在很多场景下对数据样本的实际分布会产生较大偏差。现举个例子进行说明,样本数据如图1所示,共包含10个样本(ID01~ID10),work_type是指工作属性(1代表有工作,0代表无工作),social_security是指社保金额(元)。
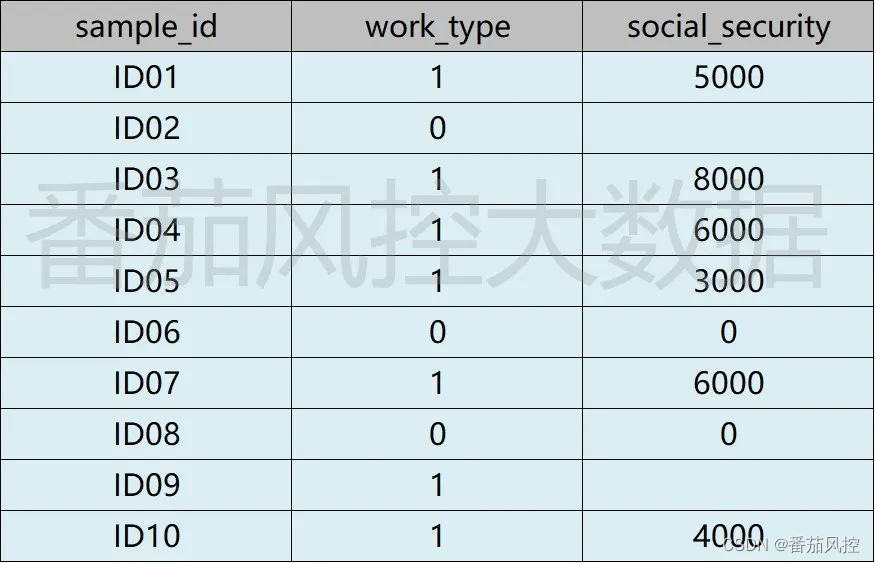
图1 缺失值处理前
对于样例1字段social_security的缺失情况,假设采用平均值进行填充,若直接对字段全量平均值处理,则ID02与ID09的填充结果如下所示:
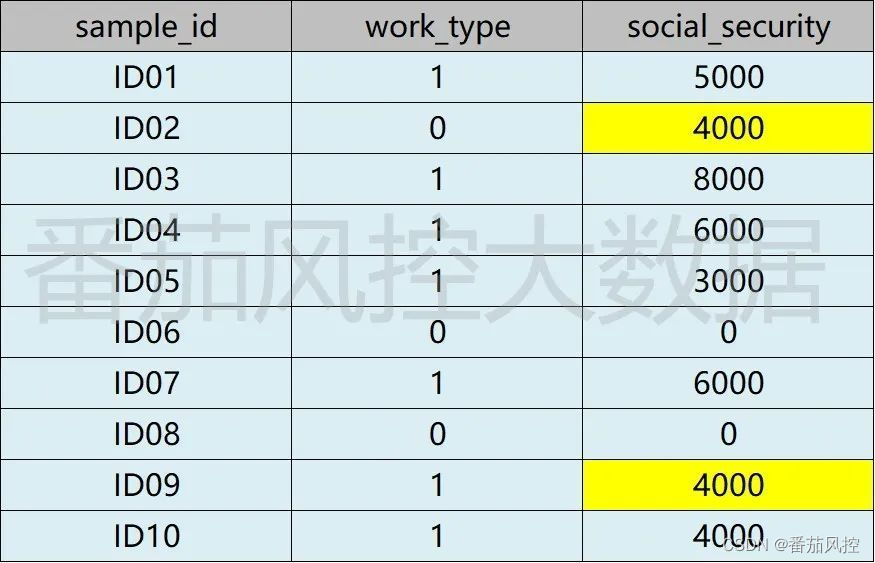
图2 缺失值处理后1
针对缺失值处理结果(图2),对于ID02用户的social_security=4000,但这里要注意到,该用户特征work_type(是否有工作)为0,说明用户是无工作的,那social_security(社保金额)的结果显然是不合理的,正常情况应为0才准确。在这种情况下,为了更符合实际业务理解,应对用户群体进行分类(聚类思想),即将用户分为有无工作2个类别(work_type=0/1),然后根据不同群体的平均值进行填充,实现结果如图3所示。
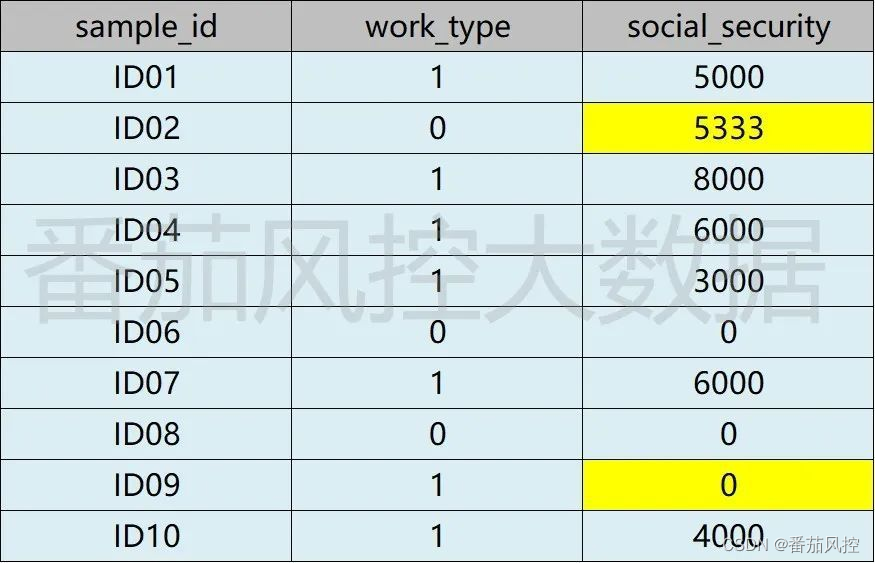
图3 缺失值处理后2
从图3最终的缺失值处理结果可以直观看出,对于样本ID02用户(有工作)的social_security(社保金额)为5333,而样本ID09用户(无工作)的social_security(社保金额)为0,这个结果显然是更符合实际情况。同样是采用平均值填充,但通过特征聚类后的处理方式在实际业务中更为合理。
2、案例实操介绍
前边的举例描述中,特征聚类的思想仅仅是从单个字段的业务含义直接进行分类判断的,在实际工作场景中,样本数据往往会包含多个特征,而且通过业务经验是无法区分类别的,因此必然需要借助于相关聚类算法进行实现。常用的聚类算法包括K-means、DBSCAN等,都可以有效划分样本的类别属性。下面我们结合一个具体场景案例,并采用基于密度的聚类算法DBSCAN,给大家详细介绍下特征聚类后的缺失值处理过程。
(1)样本数据
现有一份样本数据,包含2000条样本和5个特征,各字段的标签含义分别为客户订单(主键)、年龄、月收入、信用等级、消费等级,取数据集前10条样本具体如图4所示。
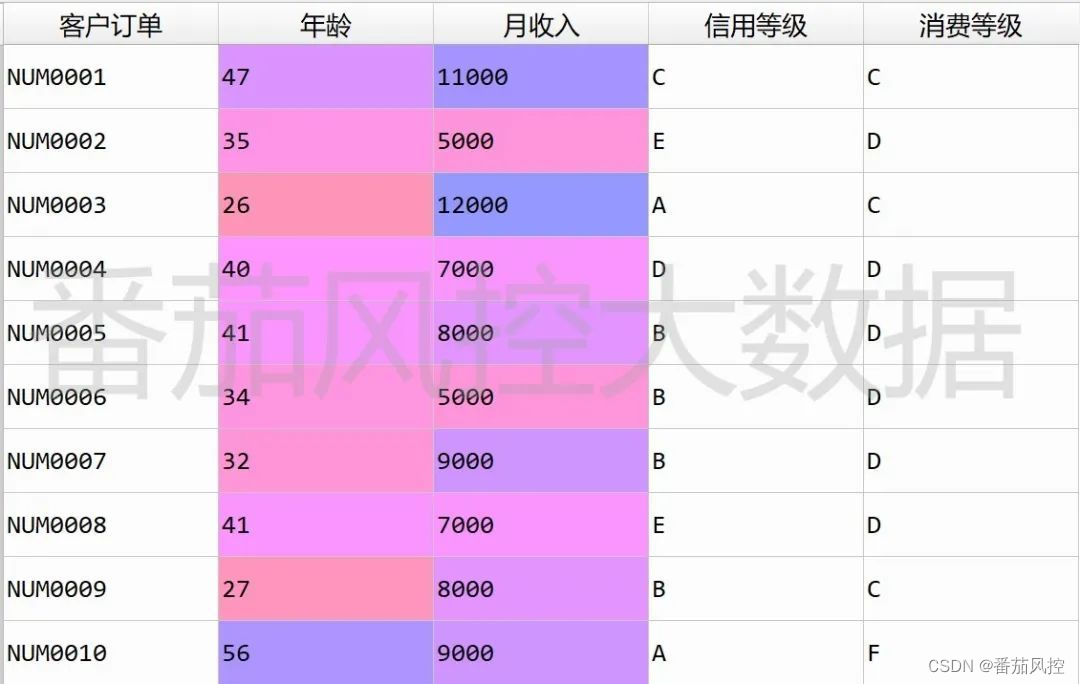
图4 样本数据前10
对样本特征的缺失情况进行统计汇总,python代码实现与结果输出分别如图5、图6所示。

图5 缺失情况汇总
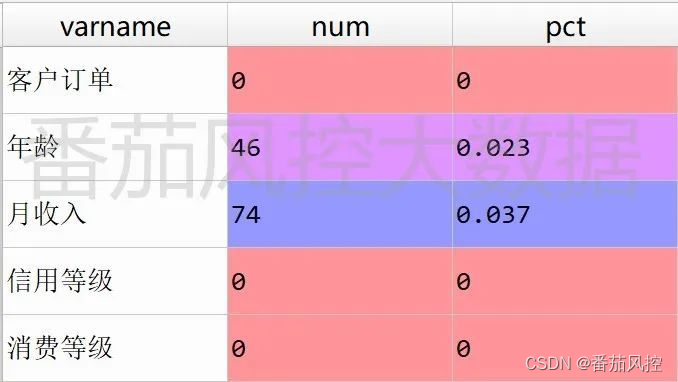
图6 特征缺失分布
从特征缺失情况可知,字段“年龄”与“月收入”均存在缺失,且缺失比例较低,分别为2.3%和3.7%,这种情况可以采用平均值进行填充。为了使得填充后效果更符合实际业务,我们首先需要选取字段进行聚类,这里需要特别注意的是,聚类字段必须是非缺失字段,至于字段数量多少没有限定,但最好是选取区分度较好,且业务解释意义较强的特征。本例根据以上描述分析,则采用剩余2个分析字段进行聚类,即“信用等级”与“消费等级”。
(2)特征工程
从图4样本可知,字段“信用等级”与“消费等级”均属于字符型,需要将其转换为数值型,可以采用标签编码实现此过程。另外,由于聚类算法DBSCAN是基于样本的距离进行模型训练的,因此为了排除各特征量纲的影响,还需要对特征进行标准化,这里采用z-score标准化(归一化)。具体实现代码如图7所示,输出结果如图8所示。

图7 特征工程代码
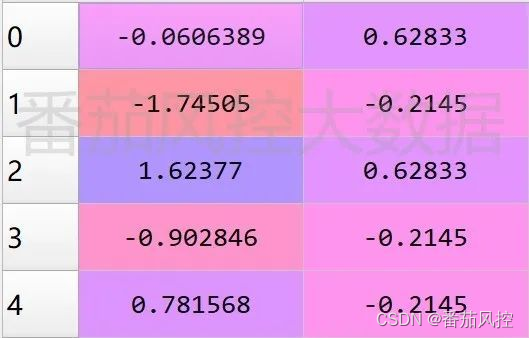
图8 数据处理结果
(3)特征聚类
根据特征标准化后的数据,采用K-means算法对特征“信用等级”与“消费等级”进行聚类分析,模型的聚类数量设置为3,具体代码与结果分别如图9-11所示。
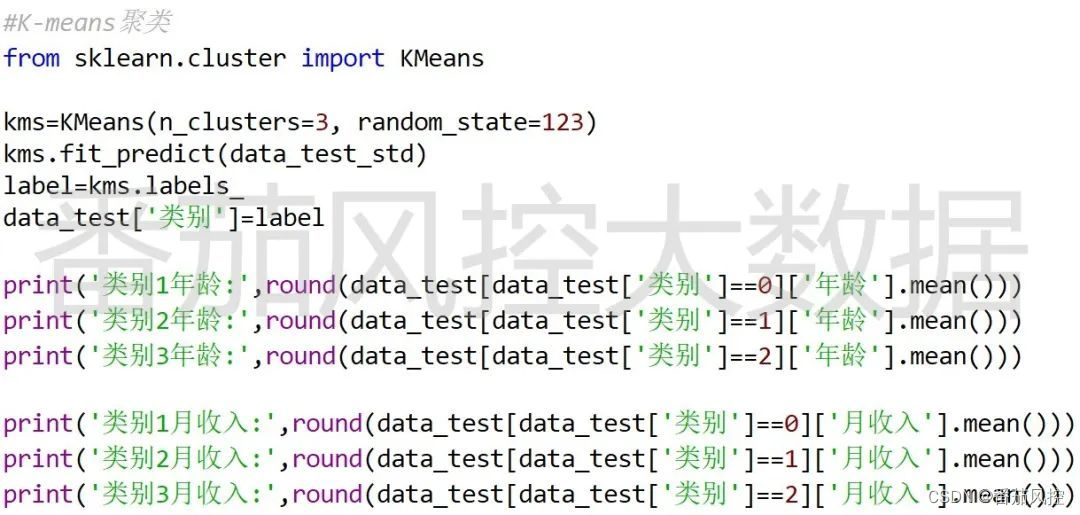
图9 特征K-means聚类
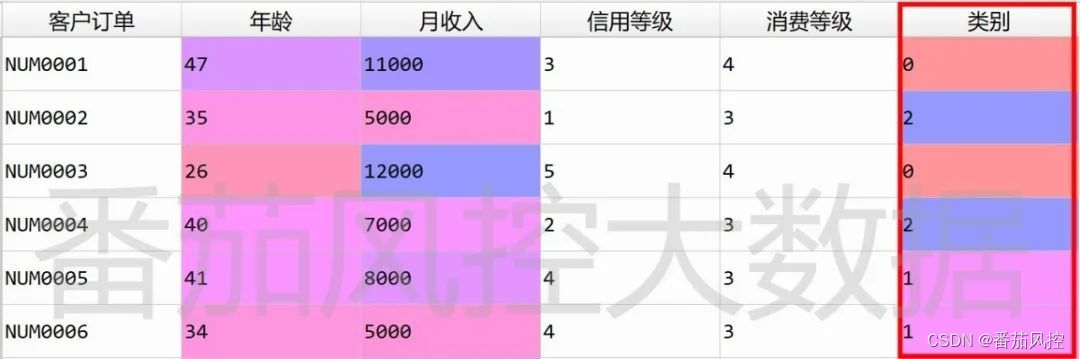
图10 特征聚类结果
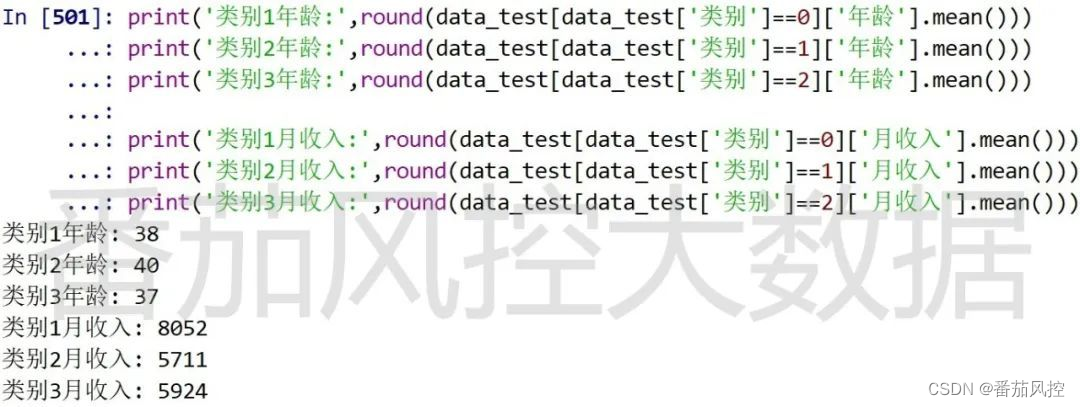
图11 聚类特征均值
(4)缺失填充
通过特征聚类分析,将样本数据划分为3个类别,并输出每类群体的特征分布指标,即“年龄”与“月收入”的平均值(图11)。从结果来看,对于每类用户群体,在“信用等级”和“消费等级”指标相似的情况下,平均“年龄”和平均“月收入”还是有着较明显差异,尤其是“月收入”指标,类别1与类别2相差较大。接下来我们根据不同样本类别的分布情况,针对性进行字段缺失值填充,具体代码的实现过程如图12所示。

图12 特征缺失填充
经过以上分析与处理,我们采用了特征聚类下的缺失值处理方法,通过结果可以说明这种思路显然比直接填充的效果更好,从样本数据分布与业务场景理解,都是更贴近实际情况,对于数据分析或数据建模等工作的有效开展都有较好的支撑效果。
关于本文中所提及的数据集与代码内容,此部分内容已更新到知识星球平台,可据此进行动手实操,详情如下:
…
end