Python解决VRPTW问题
一、VRPTW问题是什么?
VRP问题一般是指从物流配送中心用多辆车向多个客户需求点送货,每个客户需求点的位置和需求量是已知的,车辆的最大载质量是一定的,要求合理安排配送路线使得目标函数最优,并且满足以下条件:每个客户需求点只能被一辆车访问,并且只能访问一次;每辆车都是从配送中心出发,最后回到配送中心;每个客户需求点的需求量必须满足。
带时间窗的VRP问题是在该基础上,还需要满足服务时间约束,即配送人员需要在一定的时间窗内到达客户需求点进行服务。带时间窗的VRP问题分为硬时间窗和软时间窗两种,硬时间窗是车辆一定要在时间窗范围内到达指定用户处,不能早于时间窗要求的最早时间,也不能晚于时间窗的最晚时间;软时间窗是允许车辆早于或晚于时间窗限制到达用户处,但是早于时间窗的最早时间到达需要增加一个机会损失成本,晚于时间窗的最晚时间到达需要增加一个迟到的惩罚成本。
二、Python代码解决VRPTW问题
2.1 引入库
代码如下(示例):
import random, math, sys
import matplotlib.pyplot as plt
from copy import deepcopy
from tqdm import *
导入Python依赖库,matplotlib库是用来画图的,tqdm库是用来显示进度条的
2.2 参数的设置
代码如下(示例):
DEBUG = False
sampleSolution = [0, 1, 20, 9, 3, 12, 26, 25, 24, 4, 23, 22, 21, 0, 13, 2, 15, 14, 6, 27, 5, 16, 17, 8, 18, 0, 7, 19,
11, 10, 0]
geneNum = 100 # 种群数量
generationNum = 3000 # 迭代次数
CENTER = 0 # 配送中心
HUGE = 9999999
VARY = 0.05 # 变异几率
n = 25 # 客户点数量
m = 2 # 换电站数量
k = 3 # 车辆数量
Q = 5 # 额定载重量, t
dis = 160 # 续航里程, km
costPerKilo = 10 # 油价
epu = 20 # 早到惩罚成本
lpu = 30 # 晚到惩罚成本
speed = 40 # 速度,km/h
# 坐标
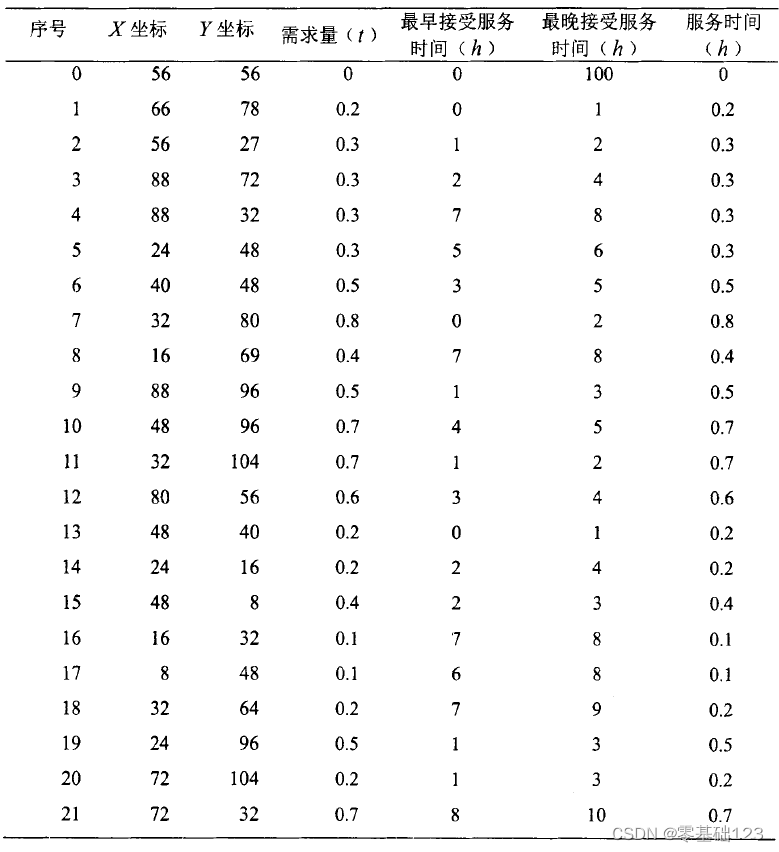
X = [56, 66, 56, 88, 88, 24, 40, 32, 16, 88, 48, 32, 80, 48, 23, 48, 16, 8, 32, 24, 72, 72, 72, 88, 104, 104, 83, 32]
Y = [56, 78, 27, 72, 32, 48, 48, 80, 69, 96, 96, 104, 56, 40, 16, 8, 32, 48, 64, 96, 104, 32, 16, 8, 56, 32, 45, 40]
# 需求量
t = [0, 0.2, 0.3, 0.3, 0.3, 0.3, 0.5, 0.8, 0.4, 0.5, 0.7, 0.7, 0.6, 0.2, 0.2, 0.4, 0.1, 0.1, 0.2, 0.5, 0.2, 0.7, 0.2,
0.7, 0.1, 0.5, 0.4, 0.4]
# 最早到达时间
eh = [0, 0, 1, 2, 7, 5, 3, 0, 7, 1, 4, 1, 3, 0, 2, 2, 7, 6, 7, 1, 1, 8, 6, 7, 6, 4, 0, 0]
# 最晚到达时间
lh = [100, 1, 2, 4, 8, 6, 5, 2, 8, 3, 5, 2, 4, 1, 4, 3, 8, 8, 9, 3, 3, 10, 10, 8, 7, 6, 100, 100]
# 服务时间
h = [0, 0.2, 0.3, 0.3, 0.3, 0.3, 0.5, 0.8, 0.4, 0.5, 0.7, 0.7, 0.6, 0.2, 0.2, 0.4, 0.1, 0.1, 0.2, 0.5, 0.2, 0.7, 0.2,
0.7, 0.1, 0.5, 0.4, 0.4]
2.3 算法部分
class Gene:
def __init__(self, name='Gene', data=None):
self.name = name
self.length = n + m + 1
if data is None:
self.data = self._getGene(self.length)
else:
assert(self.length+k == len(data))
self.data = data
self.fit = self.getFit()
self.chooseProb = 0 # 选择概率
# randomly choose a gene
def _generate(self, length):
data = [i for i in range(1, length)]
random.shuffle(data)
data.insert(0, CENTER)
data.append(CENTER)
return data
# insert zeors at proper positions
def _insertZeros(self, data):
sum = 0
newData = []
for index, pos in enumerate(data):
sum += t[pos]
if sum > Q:
newData.append(CENTER)
sum = t[pos]
newData.append(pos)
return newData
# return a random gene with proper center assigned
def _getGene(self, length):
data = self._generate(length)
data = self._insertZeros(data)
return data
# return fitness
def getFit(self):
fit = distCost = timeCost = overloadCost = fuelCost = 0
dist = [] # from this to next
# calculate distance
i = 1
while i < len(self.data):
calculateDist = lambda x1, y1, x2, y2: math.sqrt(((x1 - x2) ** 2) + ((y1 - y2) ** 2))
dist.append(calculateDist(X[self.data[i]], Y[self.data[i]], X[self.data[i - 1]], Y[self.data[i - 1]]))
i += 1
# distance cost
distCost = sum(dist) * costPerKilo
# time cost
timeSpent = 0
for i, pos in enumerate(self.data):
# skip first center
if i == 0:
continue
# new car
elif pos == CENTER:
timeSpent = 0
# update time spent on road
timeSpent += (dist[i - 1] / speed)
# arrive early
if timeSpent < eh[pos]:
timeCost += ((eh[pos] - timeSpent) * epu)
timeSpent = eh[pos]
# arrive late
elif timeSpent > lh[pos]:
timeCost += ((timeSpent - lh[pos]) * lpu)
# update time
timeSpent += h[pos]
# overload cost and out of fuel cost
load = 0
distAfterCharge = 0
for i, pos in enumerate(self.data):
# skip first center
if i == 0:
continue
# charge here
if pos > n:
distAfterCharge = 0
# at center, re-load
elif pos == CENTER:
load = 0
distAfterCharge = 0
# normal
else:
load += t[pos]
distAfterCharge += dist[i - 1]
# update load and out of fuel cost
overloadCost += (HUGE * (load > Q))
fuelCost += (HUGE * (distAfterCharge > dis))
fit = distCost + timeCost + overloadCost + fuelCost
return 1/fit
def updateChooseProb(self, sumFit):
self.chooseProb = self.fit / sumFit
def moveRandSubPathLeft(self):
path = random.randrange(k) # choose a path index
index = self.data.index(CENTER, path+1) # move to the chosen index
# move first CENTER
locToInsert = 0
self.data.insert(locToInsert, self.data.pop(index))
index += 1
locToInsert += 1
# move data after CENTER
while self.data[index] != CENTER:
self.data.insert(locToInsert, self.data.pop(index))
index += 1
locToInsert += 1
assert(self.length+k == len(self.data))
# plot this gene in a new window
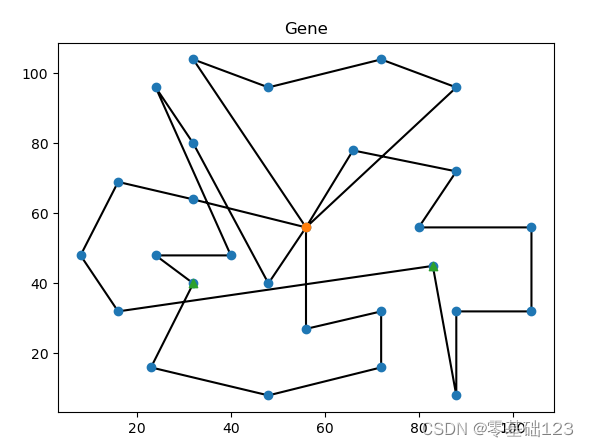
def plot(self):
Xorder = [X[i] for i in self.data]
Yorder = [Y[i] for i in self.data]
plt.plot(Xorder, Yorder, c='black', zorder=1)
plt.scatter(X, Y, zorder=2)
plt.scatter([X[0]], [Y[0]], marker='o', zorder=3)
plt.scatter(X[-m:], Y[-m:], marker='^', zorder=3)
plt.title(self.name)
plt.show()
def getSumFit(genes):
sum = 0
for gene in genes:
sum += gene.fit
return sum
# return a bunch of random genes
def getRandomGenes(size):
genes = []
for i in range(size):
genes.append(Gene("Gene "+str(i)))
return genes
# 计算适应度和
def getSumFit(genes):
sumFit = 0
for gene in genes:
sumFit += gene.fit
return sumFit
# 更新选择概率
def updateChooseProb(genes):
sumFit = getSumFit(genes)
for gene in genes:
gene.updateChooseProb(sumFit)
# 计算累计概率
def getSumProb(genes):
sum = 0
for gene in genes:
sum += gene.chooseProb
return sum
# 选择复制,选择前 1/3
def choose(genes):
num = int(geneNum/6) * 2 # 选择偶数个,方便下一步交叉
# sort genes with respect to chooseProb
key = lambda gene: gene.chooseProb
genes.sort(reverse=True, key=key)
# return shuffled top 1/3
return genes[0:num]
# 交叉一对
def crossPair(gene1, gene2, crossedGenes):
gene1.moveRandSubPathLeft()
gene2.moveRandSubPathLeft()
newGene1 = []
newGene2 = []
# copy first paths
centers = 0
firstPos1 = 1
for pos in gene1.data:
firstPos1 += 1
centers += (pos == CENTER)
newGene1.append(pos)
if centers >= 2:
break
centers = 0
firstPos2 = 1
for pos in gene2.data:
firstPos2 += 1
centers += (pos == CENTER)
newGene2.append(pos)
if centers >= 2:
break
# copy data not exits in father gene
for pos in gene2.data:
if pos not in newGene1:
newGene1.append(pos)
for pos in gene1.data:
if pos not in newGene2:
newGene2.append(pos)
# add center at end
newGene1.append(CENTER)
newGene2.append(CENTER)
# 计算适应度最高的
key = lambda gene: gene.fit
possible = []
while gene1.data[firstPos1] != CENTER:
newGene = newGene1.copy()
newGene.insert(firstPos1, CENTER)
newGene = Gene(data=newGene.copy())
possible.append(newGene)
firstPos1 += 1
possible.sort(reverse=True, key=key)
assert(possible)
crossedGenes.append(possible[0])
key = lambda gene: gene.fit
possible = []
while gene2.data[firstPos2] != CENTER:
newGene = newGene2.copy()
newGene.insert(firstPos2, CENTER)
newGene = Gene(data=newGene.copy())
possible.append(newGene)
firstPos2 += 1
possible.sort(reverse=True, key=key)
crossedGenes.append(possible[0])
# 交叉
def cross(genes):
crossedGenes = []
for i in range(0, len(genes), 2):
crossPair(genes[i], genes[i+1], crossedGenes)
return crossedGenes
# 合并
def mergeGenes(genes, crossedGenes):
# sort genes with respect to chooseProb
key = lambda gene: gene.chooseProb
genes.sort(reverse=True, key=key)
pos = geneNum - 1
for gene in crossedGenes:
genes[pos] = gene
pos -= 1
return genes
# 变异一个
def varyOne(gene):
varyNum = 10
variedGenes = []
for i in range(varyNum):
p1, p2 = random.choices(list(range(1,len(gene.data)-2)), k=2)
newGene = gene.data.copy()
newGene[p1], newGene[p2] = newGene[p2], newGene[p1] # 交换
variedGenes.append(Gene(data=newGene.copy()))
key = lambda gene: gene.fit
variedGenes.sort(reverse=True, key=key)
return variedGenes[0]
# 变异
def vary(genes):
for index, gene in enumerate(genes):
# 精英主义,保留前三十
if index < 30:
continue
if random.random() < VARY:
genes[index] = varyOne(gene)
return genes
2.4 主函数
if __name__ == "__main__" and not DEBUG:
genes = getRandomGenes(geneNum) # 初始种群
# 迭代
for i in tqdm(range(generationNum)):
updateChooseProb(genes)
sumProb = getSumProb(genes)
chosenGenes = choose(deepcopy(genes)) # 选择
crossedGenes = cross(chosenGenes) # 交叉
genes = mergeGenes(genes, crossedGenes) # 复制交叉至子代种群
genes = vary(genes) # under construction
# sort genes with respect to chooseProb
key = lambda gene: gene.fit
genes.sort(reverse=True, key=key) # 以fit对种群排序
print('\r\n')
print('data:', genes[0].data)
print('fit:', genes[0].fit)
genes[0].plot() # 画出来
if DEBUG:
print("START")
gene = Gene()
print(gene.data)
gene.moveRandSubPathLeft()
print(gene.data)
print("FINISH")
三、数据集和显示的结果图
3.1 数据集

3.2 求解结果

VRPTW的求解结果: