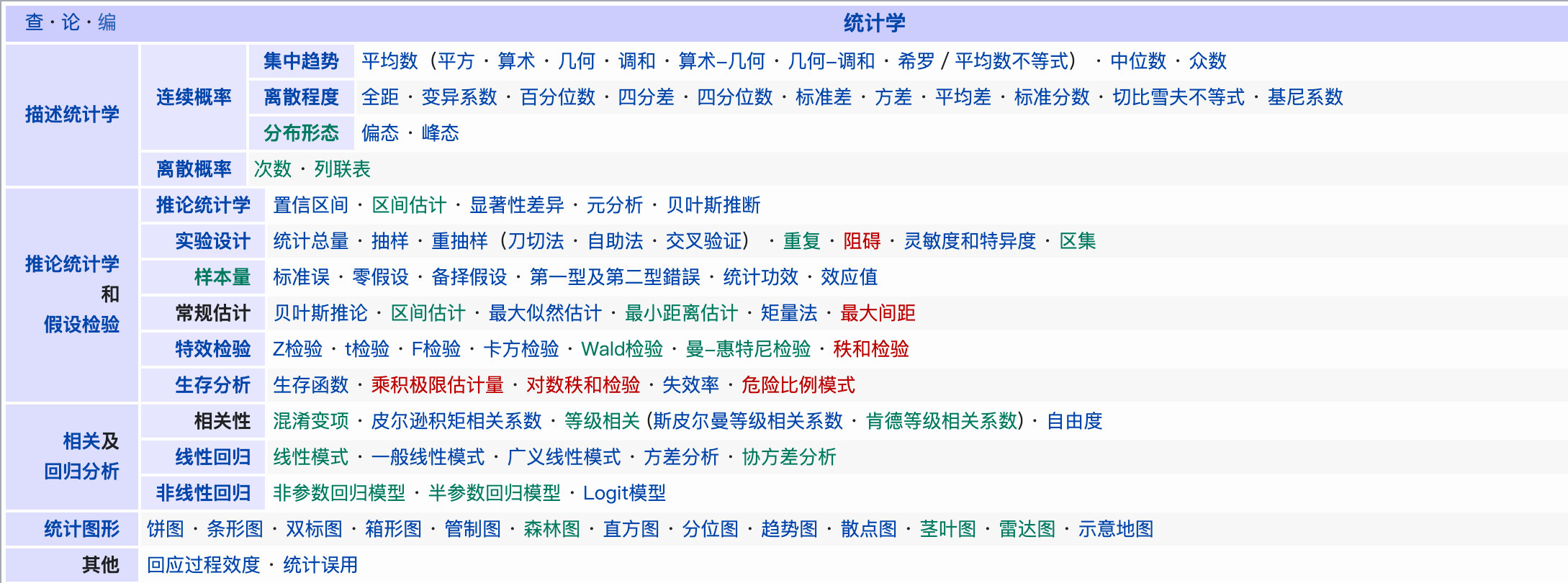
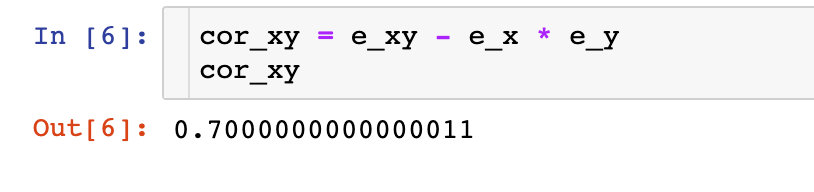
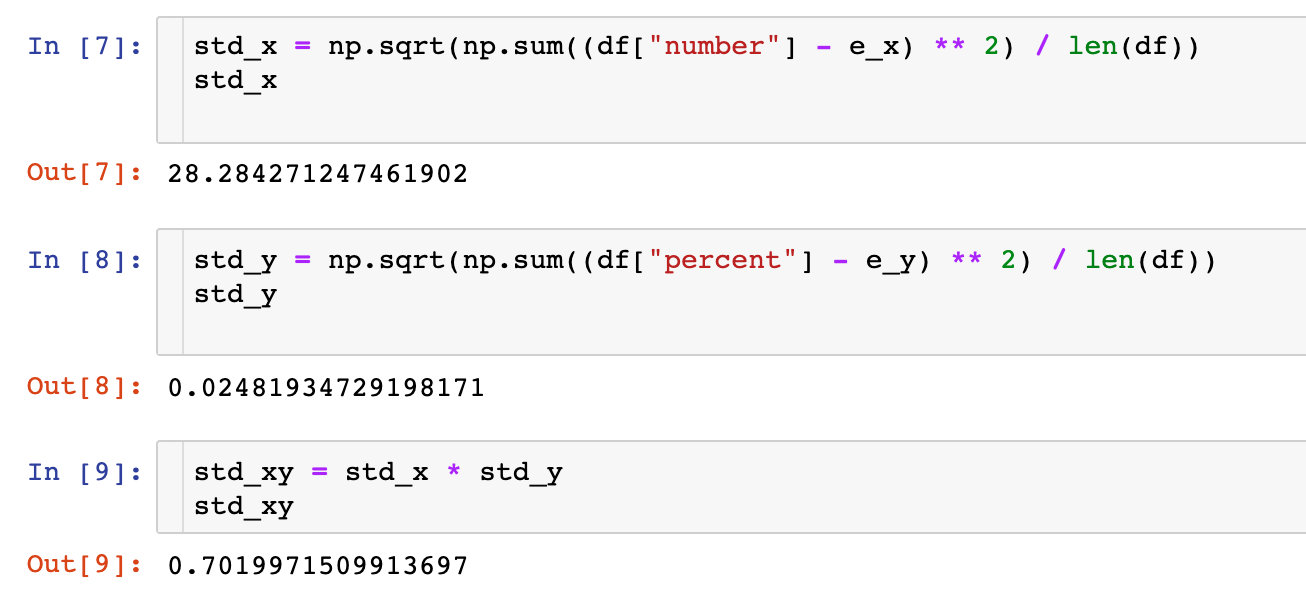
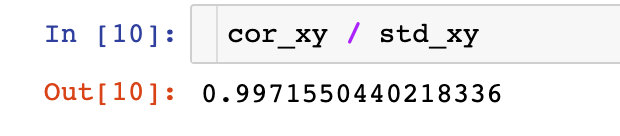
ρ
x
,
y
=
cov
(
x
,
y
)
σ
x
σ
y
=
E
[
(
x
−
μ
x
,
y
−
μ
y
)
]
σ
x
σ
y
\rho_{x, y}=\frac{\operatorname{cov}(\boldsymbol{x}, \boldsymbol{y})}{\sigma_{x} \sigma_{y}}=\frac{E\left[\left(\boldsymbol{x}-\mu_{x}, \boldsymbol{y}-\mu_{y}\right)\right]}{\sigma_{x} \sigma_{y}}
ρx,y=σxσycov(x,y)=σxσyE[(x−μx,y−μy)]
或者为:
ρ
X
,
Y
=
E
(
X
Y
)
−
E
(
X
)
E
(
Y
)
E
(
X
2
)
−
(
E
(
X
)
)
2
E
(
Y
2
)
−
(
E
(
Y
)
)
2
\rho_{X, Y}=\frac{E(X Y)-E(X) E(Y)}{\sqrt{E\left(X^{2}\right)-(E(X))^{2}} \sqrt{E\left(Y^{2}\right)-(E(Y))^{2}}}
ρX,Y=E(X2)−(E(X))2E(Y2)−(E(Y))2E(XY)−E(X)E(Y)
样本的Person相关系数用字母r表示,用来度量两个变量间的线性关系,计算公式为:
r
(
X
,
Y
)
=
Cov
(
X
,
Y
)
Var
[
X
]
Var
[
Y
]
r(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}[X] \operatorname{Var}[Y]}}
r(X,Y)=Var[X]Var[Y]Cov(X,Y)
ρ
=
∑
i
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
∑
i
(
x
i
−
x
ˉ
)
2
∑
i
(
y
i
−
y
ˉ
)
2
\rho=\frac{\sum_{i}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sqrt{\sum_{i}\left(x_{i}-\bar{x}\right)^{2} \sum_{i}\left(y_{i}-\bar{y}\right)^{2}}}
ρ=∑i(xi−xˉ)2∑i(yi−yˉ)2∑i(xi−xˉ)(yi−yˉ)
ρ
=
1
−
6
∑
d
i
2
n
(
n
2
−
1
)
\rho=1-\frac{6 \sum d_{i}^{2}}{n\left(n^{2}-1\right)}
ρ=1−n(n2−1)6∑di2
其中,n表示数据点的个数,
d
i
d_i
di表示数据点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的秩次
(
r
x
i
,
r
y
i
)
(r_{xi},r_{yi})
(rxi,ryi)的差值:
d
i
=
r
x
i
−
r
y
i
d_i=r_{xi}-r_{yi}
di=rxi−ryi
ρ
s
=
ρ
r
x
,
r
y
=
cov
(
r
x
,
r
y
)
σ
r
x
σ
r
y
\rho_{s}=\rho_{r_{x}, r_{y}}=\frac{\operatorname{cov}\left(r_{x}, r_{y}\right)}{\sigma_{r_{x}} \sigma_{r_{y}}}
ρs=ρrx,ry=σrxσrycov(rx,ry)
其中:
r
x
r_x
rx表示变量x转换后的秩次。从上面的定义能够看出来,Spearman 相关系数实际上就是对数据做了秩次变换后的 Pearson 相关系数
import random
# 模拟一份数据:5个类+1个特征
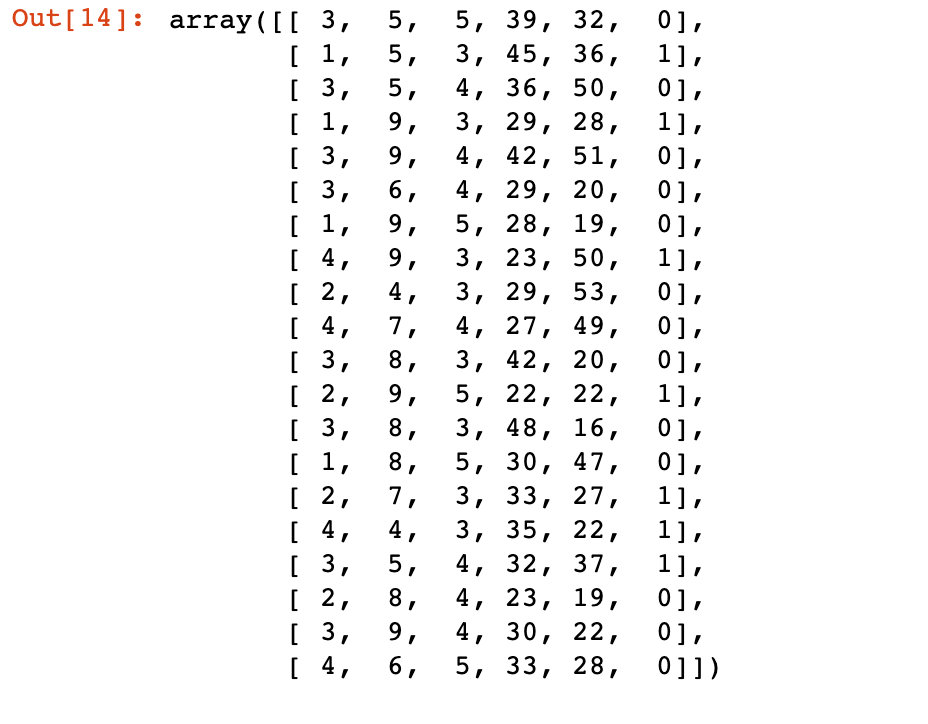
df1 = pd.DataFrame({"A":np.random.randint(1,5,20),"B":np.random.randint(4,10,20),"C":np.random.randint(3,6,20),"D":np.random.randint(22,50,20),"E":np.random.randint(15,60,20),"cat":np.random.randint(0,2,20),},index=list(range(20)))
df2 = np.array(df1)
2、计算特征和类的均值
# 计算数据中特征和类的平均值defcalcMean(x,y):"""
作用:计算特征和类的平均值
参数:
x:类的数据
y:特征的数据
返回值:特征和类的平均值
"""
x_sum =sum(x)
y_sum =sum(y)
n =len(x)
x_mean =float(x_sum)/ n
y_mean =float(y_sum)/ n
return x_mean,y_mean # 返回均值
3、计算pearson系数
defcalcPearson(x,y):
x_mean, y_mean = calcMean(x,y)# 调用上面的函数返回均值
n =len(x)
sumTop =0.0
sumBottom =0.0
x_pow =0.0
y_pow =0.0# 计算协方差for i inrange(n):
sumTop +=(x[i]- x_mean)*(y[i]- y_mean)# 计算标准差for i inrange(n):
x_pow += math.pow(x[i]- x_mean,2)for i inrange(n):
y_pow += math.pow(y[i]- y_mean ,2)
sumBottom = np.sqrt(x_pow * y_pow)
p = sumTop / sumBottom # 协方差 / 标准差return p
4、计算每个属性的贡献度
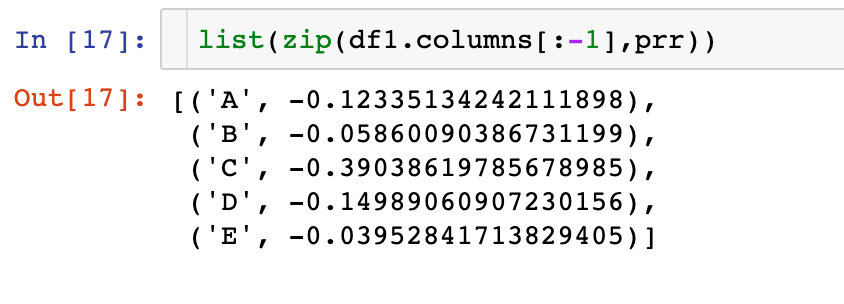
defcalcAttribute(dataSet):
prr =[]# 空列表待追加数据
n,m = np.shape(dataSet)# 获取行数和列数
x =[0]* n # 初始化特征x和类别向量y
y =[0]* n
for i inrange(n):
y[i]= dataSet[i][m-1]# 得到全部的类别向量for j inrange(m-1):for k inrange(n):
x[k]= dataSet[k][j]
prr.append(calcPearson(x,y))# 计算每个特征和类别y的相关系数,存入列表return prr