前言
支持向量机优化的目标
通俗解释︰找到一个条线(w和b ),使得离该线最近的点能够最远
在机器学习中要明白算法要做什么,把实际问题转化为数学问题
,在数学问题上进行求解和优化。
一、SVM支持向量机
SVM支持向量机要解决的问题:
什么样的决策边界才是最好的?
分类的边界越宽越好,如下图右图优于左图。
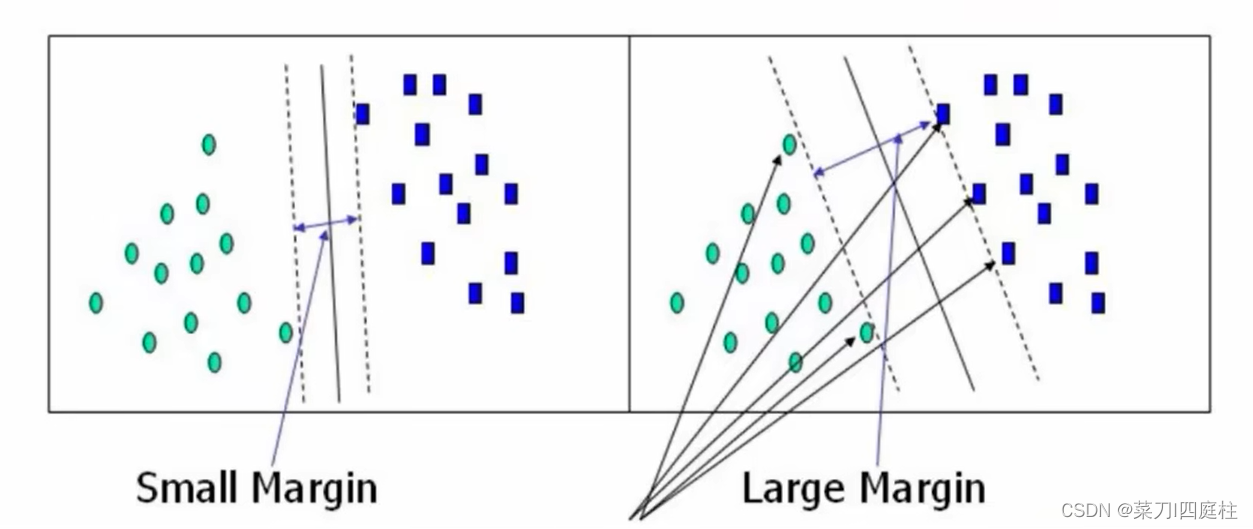
间隔与支持向量
数据集:(X1,Y1),(X2,Y2)…(Xn,Yn)
Y为样本的类别:当X为正例时候Y=+1当X为负例时候Y= -1
决策方程:y(x)=wTX+b
y(xi)>0 ⟺ yi=+1
==> y(xi)<0 ⟺ yi=-1 ==> yiy(xi)>0
要使分类的边界越宽,及求得一个w,b使得下式最大(可以看成是求距离公式)
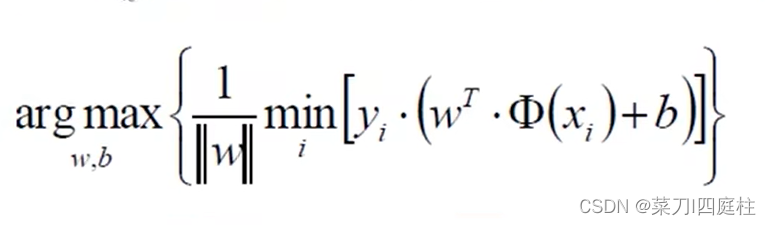
对于决策方程(w,b)可以通过放缩使得其结果值|Y|>=1
及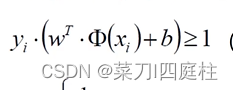 当该式(约束条件)取得最小时,记为1,所以只需考虑求以下最大值
当该式(约束条件)取得最小时,记为1,所以只需考虑求以下最大值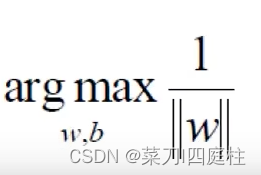
将求极大值问题转化为求极小值问题:

这就是支持向量机的基本型
二、对偶问题
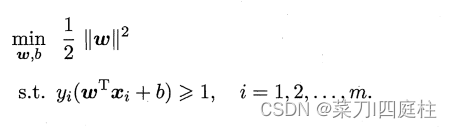
对上式使用拉格朗日乘子法可得到其“对偶问题”.具体来说,对式(6.6)的每条约束添加拉格朗日乘子αi≥0,则该问题的拉格朗日函数可写为
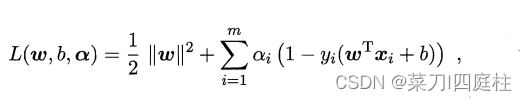
其中α = (α1; α2; . . . ; αm).令L(ω,b, α)对ω和b的偏导为零可得

带入方程后得到(外交约束条件):
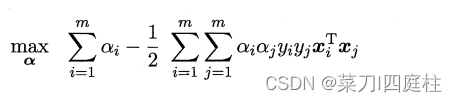
解出α后,求出ω与b即可得到模型
从对偶问题解出的α是式中的拉格朗日乘子,它恰对应着训练样本(xi,yi)、注意到式中有不等式约束,因此上述过程需满足KKT条件,即要求

于是;对任意训练样本(xi,yi),总有αi=0或yi f(xi) = 1.若αi= 0,则该样本将不会在式的求和中出现,也就不会对f(x)有任何影响;若αi > 0,则必有yif(xi) = 1,所对应的样本点位于最大间隔边界上,是一个支持向量.这显示出支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需保留,最终模型仅与支持向量有关.
三.python代码实现
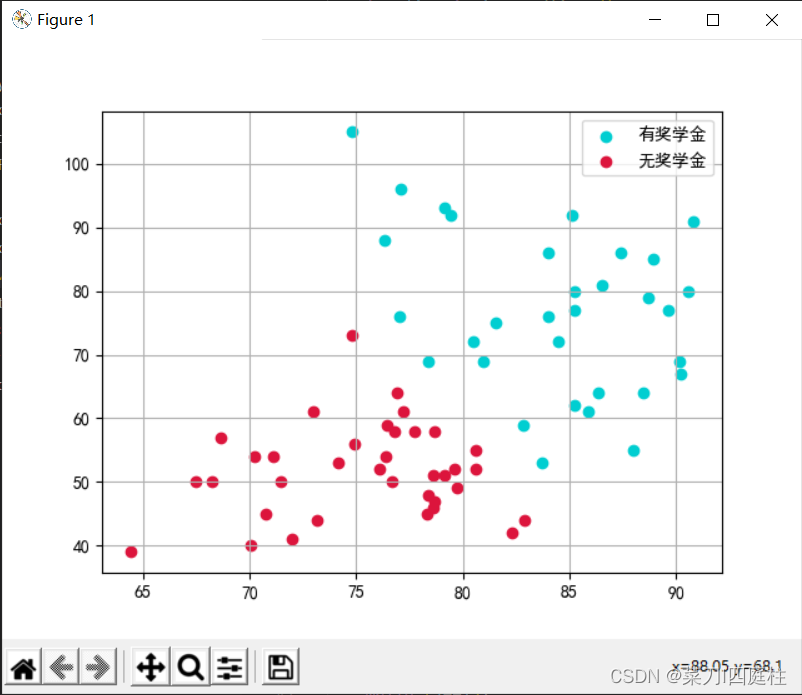
仍使用之前奖学金的数据集,数据集如下
分别代表卷面成绩,综测分,有无奖学金(1代表有,-1代表无)
数据集散点图如下:
from numpy import *
import matplotlib.pyplot as plt
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
def loadDataSet(filename): # 读取数据
dataMat = []
labelMat = []
data1 = []
data2 = []
data3 = []
data4 = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(' ')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append(float(lineArr[2]))
lineArr[0] = float(lineArr[0])
lineArr[1] = float(lineArr[1])
lineArr[2] = float(lineArr[2])
if lineArr[2] == 1:
data1.append((lineArr[0]))
data2.append((lineArr[1]))
else:
data3.append((lineArr[0]))
data4.append((lineArr[1]))
x_1 = data1
y_1 = data2
x_2 = data3
y_2 = data4
colors1 = '#00CED1'
colors2 = '#DC143C'
plt.scatter(x_1, y_1, c=colors1, label='有奖学金')
plt.scatter(x_2, y_2, c=colors2, label='无奖学金')
plt.legend()
plt.grid("on")
plt.show()
return dataMat, labelMat # 返回数据特征和数据类别
def selectJrand(i,m): #在0-m中随机选择一个不是i的整数
j=i
while (j==i):
j=int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L): #保证a在L和H范围内(L <= a <= H)
if aj>H:
aj=H
if L>aj:
aj=L
return aj
def kernelTrans(X, A, kTup): #核函数,输入参数,X:支持向量的特征树;A:某一行特征数据;kTup:('lin',k1)核函数的类型和参数
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': #线性函数
K = X * A.T
elif kTup[0]=='rbf': # 径向基函数(radial bias function)
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #返回生成的结果
else:
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
#定义类,方便存储数据
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # 存储各类参数
self.X = dataMatIn #数据特征
self.labelMat = classLabels #数据类别
self.C = C #软间隔参数C,参数越大,非线性拟合能力越强
self.tol = toler #停止阀值
self.m = shape(dataMatIn)[0] #数据行数
self.alphas = mat(zeros((self.m,1)))
self.b = 0 #初始设为0
self.eCache = mat(zeros((self.m,2))) #缓存
self.K = mat(zeros((self.m,self.m))) #核函数的计算结果
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k): #计算Ek(参考《统计学习方法》p127公式7.105)
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
#随机选取aj,并返回其E值
def selectJ(i, oS, Ei):
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0] #返回矩阵中的非零位置的行数
if (len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE): #返回步长最大的aj
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k): #更新os数据
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
#首先检验ai是否满足KKT条件,如果不满足,随机选择aj进行优化,更新ai,aj,b值
def innerL(i, oS): #输入参数i和所有参数数据
Ei = calcEk(oS, i) #计算E值
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)): #检验这行数据是否符合KKT条件 参考《统计学习方法》p128公式7.111-113
j,Ej = selectJ(i, oS, Ei) #随机选取aj,并返回其E值
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]): #以下代码的公式参考《统计学习方法》p126
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H:
print("L==H")
return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #参考《统计学习方法》p127公式7.107
if eta >= 0:
print("eta>=0")
return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta #参考《统计学习方法》p127公式7.106
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L) #参考《统计学习方法》p127公式7.108
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < oS.tol): #alpha变化大小阀值(自己设定)
print("j not moving enough")
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#参考《统计学习方法》p127公式7.109
updateEk(oS, i) #更新数据
#以下求解b的过程,参考《统计学习方法》p129公式7.114-7.116
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]<oS.C):
oS.b = b1
elif (0 < oS.alphas[j]<oS.C):
oS.b = b2
else:
oS.b = (b1 + b2)/2.0
return 1
else:
return 0
#SMO函数,用于快速求解出alpha
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #输入参数:数据特征,数据类别,参数C,阀值toler,最大迭代次数,核函数(默认线性核)
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet:
for i in range(oS.m): #遍历所有数据
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)) #显示第多少次迭代,那行特征数据使alpha发生了改变,这次改变了多少次alpha
iter += 1
else:
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs: #遍历非边界的数据
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
def testRbf(data_train,data_test):
dataArr,labelArr = loadDataSet(data_train) #读取训练数据
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', 1.3)) #通过SMO算法得到b和alpha
datMat=mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas)[0] #选取不为0数据的行数(也就是支持向量)
sVs=datMat[svInd] #支持向量的特征数据
labelSV = labelMat[svInd] #支持向量的类别(1或-1)
print("there are %d Support Vectors" % shape(sVs)[0]) #打印出共有多少的支持向量
m,n = shape(datMat) #训练数据的行列数
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', 1.3)) #将支持向量转化为核函数
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b #这一行的预测结果(代码来源于《统计学习方法》p133里面最后用于预测的公式)注意最后确定的分离平面只有那些支持向量决定。
if sign(predict)!=sign(labelArr[i]): #sign函数 -1 if x < 0, 0 if x==0, 1 if x > 0
errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m)) #打印出错误率
dataArr_test,labelArr_test = loadDataSet(data_test) #读取测试数据
errorCount_test = 0
datMat_test=mat(dataArr_test)
labelMat = mat(labelArr_test).transpose()
m,n = shape(datMat_test)
for i in range(m): #在测试数据上检验错误率
kernelEval = kernelTrans(sVs,datMat_test[i,:],('rbf', 1.3))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr_test[i]):
errorCount_test += 1
print("the test error rate is: %f" % (float(errorCount_test)/m))
if __name__=='__main__':
filename_traindata='./ch5/grade_train.txt'
filename_testdata='./ch5/grade_test.txt'
testRbf(filename_traindata,filename_testdata)
实验结果

五.实验总结
1.实验的训练错误率与测试错误率结果可以看出,由于数据本身就存在很强的线性关系,可以很容易找到我们所需要的向量将其分割开。
2.我们一直假设训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面能将不同类的样本完全划分开。然而在现实任务中往往很难确定合适的核函数使得训练样本在特征空间中线性可分,也很难断定这个貌似线性可分的结果不是由于过拟合造成的。缓解该问题的一个办法是允许支持向量机在一些样本上出错。为此,要引入“软间隔”的概念:
参考文献
参考博客链接: http://t.csdn.cn/AzHPd
b站视频链接: 1小时候教会你svm支持向量机