憨批的语义分割7——基于resnet模型的segnet讲解(划分斑马线)
学习前言
好好学习呀。

模型部分
什么是Segnet模型
Segnet模型是一个比较基础的语义分割模型,其结构比较简单,在说其结构之前,我们先讲一下convolutional Encoder-Decoder的结构。
其主要结构与自编码(Autoencoder)类似,通过编码解码复原图片上每一个点所属的类别。
下图主要是说明利用卷积层编码与解码的过程。

segnet模型与上述模型类似。
其主要的过程就是,其利用Encoder中提取了多次特征的f4进行处理,利用Decoder进行多次上采样Upsampling2D。最后得到一个具有一定hw的filter数量为n_classes的图层。
什么是Resnet模型
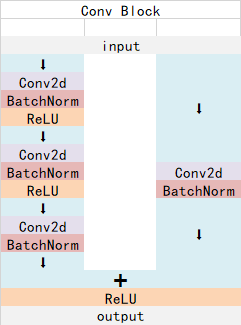
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
Conv Block的结构如下:
Identity Block的结构如下:

这两个都是残差网络结构。
总的网络结构如下:

segnet模型的代码实现
segnet模型的代码分为两部分。
1、主干模型resnet。
该部分用于特征提取,实际上就是常规的resnet结构,想要了解resnet结构的朋友们可以看看我的另一篇博客神经网络学习小记录20——ResNet50模型的复现详解:
import keras
from keras.models import *
from keras.layers import *
from keras import layers
import keras.backend as K
IMAGE_ORDERING = 'channels_last'
def one_side_pad( x ):
x = ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING)(x)
if IMAGE_ORDERING == 'channels_first':
x = Lambda(lambda x : x[: , : , :-1 , :-1 ] )(x)
elif IMAGE_ORDERING == 'channels_last':
x = Lambda(lambda x : x[: , :-1 , :-1 , : ] )(x)
return x
def identity_block(input_tensor, kernel_size, filters, stage, block):
filters1, filters2, filters3 = filters
if IMAGE_ORDERING == 'channels_last':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 1x1压缩
x = Conv2D(filters1, (1, 1) , data_format=IMAGE_ORDERING , name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
# 3x3提取特征
x = Conv2D(filters2, kernel_size , data_format=IMAGE_ORDERING ,
padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
# 1x1扩张特征
x = Conv2D(filters3 , (1, 1), data_format=IMAGE_ORDERING , name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
# 残差网络
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
# 与identity_block最大差距为,其可以减少wh,进行压缩
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
filters1, filters2, filters3 = filters
if IMAGE_ORDERING == 'channels_last':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# 1x1压缩
x = Conv2D(filters1, (1, 1) , data_format=IMAGE_ORDERING , strides=strides,
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
# 3x3提取特征
x = Conv2D(filters2, kernel_size , data_format=IMAGE_ORDERING , padding='same',
name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
# 1x1扩张特征
x = Conv2D(filters3, (1, 1) , data_format=IMAGE_ORDERING , name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
# 1x1扩张特征
shortcut = Conv2D(filters3, (1, 1) , data_format=IMAGE_ORDERING , strides=strides,
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(axis=bn_axis, name=bn_name_base + '1')(shortcut)
# add
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
def get_resnet50_encoder(input_height=224 , input_width=224 , pretrained='imagenet' ,
include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None,
classes=1000):
assert input_height%32 == 0
assert input_width%32 == 0
if IMAGE_ORDERING == 'channels_first':
img_input = Input(shape=(3,input_height,input_width))
elif IMAGE_ORDERING == 'channels_last':
img_input = Input(shape=(input_height,input_width , 3 ))
if IMAGE_ORDERING == 'channels_last':
bn_axis = 3
else:
bn_axis = 1
x = ZeroPadding2D((3, 3), data_format=IMAGE_ORDERING)(img_input)
x = Conv2D(64, (7, 7), data_format=IMAGE_ORDERING, strides=(2, 2), name='conv1')(x)
# f1是hw方向压缩一次的结果
f1 = x
x = BatchNormalization(axis=bn_axis, name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3) , data_format=IMAGE_ORDERING , strides=(2, 2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# f2是hw方向压缩两次的结果
f2 = one_side_pad(x )
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# f3是hw方向压缩三次的结果
f3 = x
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# f4是hw方向压缩四次的结果
f4 = x
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
# f5是hw方向压缩五次的结果
f5 = x
x = AveragePooling2D((7, 7) , data_format=IMAGE_ORDERING , name='avg_pool')(x)
return img_input , [f1 , f2 , f3 , f4 , f5 ]
2、segnet的Decoder解码部分
这一部分对应着上面segnet模型中的解码部分。
其关键就是把获得的特征重新映射到比较大的图中的每一个像素点,用于每一个像素点的分类。
from keras.models import *
from keras.layers import *
from nets.resnet50 import get_resnet50_encoder
IMAGE_ORDERING = 'channels_last'
def segnet_decoder( f , n_classes , n_up=3 ):
assert n_up >= 2
o = f
o = ( ZeroPadding2D( (1,1) , data_format=IMAGE_ORDERING ))(o)
o = ( Conv2D(512, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = ( BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/8
o = ( UpSampling2D( (2,2), data_format=IMAGE_ORDERING))(o)
o = ( ZeroPadding2D( (1,1), data_format=IMAGE_ORDERING))(o)
o = ( Conv2D( 256, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = ( BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/4
for _ in range(n_up-2):
o = ( UpSampling2D((2,2) , data_format=IMAGE_ORDERING ) )(o)
o = ( ZeroPadding2D((1,1) , data_format=IMAGE_ORDERING ))(o)
o = ( Conv2D( 128 , (3, 3), padding='valid' , data_format=IMAGE_ORDERING ))(o)
o = ( BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/4
o = ( UpSampling2D((2,2) , data_format=IMAGE_ORDERING ))(o)
o = ( ZeroPadding2D((1,1) , data_format=IMAGE_ORDERING ))(o)
o = ( Conv2D( 64 , (3, 3), padding='valid' , data_format=IMAGE_ORDERING ))(o)
o = ( BatchNormalization())(o)
# 此时输出为h_input/2,w_input/2,nclasses
o = Conv2D( n_classes , (3, 3) , padding='same', data_format=IMAGE_ORDERING )( o )
return o
def _segnet( n_classes , encoder , input_height=416, input_width=608 , encoder_level=3):
# encoder通过主干网络
img_input , levels = encoder( input_height=input_height , input_width=input_width )
# 获取hw压缩四次后的结果
feat = levels[encoder_level]
# 将特征传入segnet网络
o = segnet_decoder(feat, n_classes, n_up=3 )
# 将结果进行reshape
o = Reshape((int(input_height/2)*int(input_width/2), -1))(o)
o = Softmax()(o)
model = Model(img_input,o)
return model
def resnet50_segnet( n_classes , input_height=416, input_width=608 , encoder_level=3):
model = _segnet( n_classes , get_resnet50_encoder , input_height=input_height, input_width=input_width , encoder_level=encoder_level)
model.model_name = "resnet50_segnet"
return model
代码测试
将上面两个代码分别保存为resnet50.py和segnet.py。按照如下方式存储:

此时我们运行test.py的代码:
from nets.segnet import resnet50_segnet
model = resnet50_segnet(n_classes=2,input_height=416, input_width=416)
model.summary()
如果没有出错的话就会得到如下的结果:

训练部分
训练的是什么
虽然把代码贴上来大家就会点运行然后就可以训练自己的模型,但是我还是想要大家知道,语义分割模型训练的是什么。
1、训练文件详解
这个要从训练文件讲起。
语义分割模型训练的文件分为两部分。
第一部分是原图,像这样:

第二部分标签,像这样:

当你们看到这个标签的时候你们会说,我靠,你给我看的什么辣鸡,全黑的算什么标签,其实并不是这样的,这个标签看起来全黑,但是实际上在斑马线的部分其RGB三个通道的值都是1。
其实给你们换一个图你们就可以更明显的看到了。
这是voc数据集中语义分割的训练集中的一幅图:

这是它的标签。

为什么这里的标签看起来就清楚的多呢,因为在voc中,其一共需要分21类,所以火车的RGB的值可能都大于10了,当然看得见。
所以,在训练集中,如果像本文一样分两类,那么背景的RGB就是000,斑马线的RGB就是111,如果分多类,那么还会存在222,333,444这样的。这说明其属于不同的类。
2、LOSS函数的组成
关于loss函数的组成我们需要看两个loss函数的组成部分,第一个是预测结果。
# 此时输出为h_input/2,w_input/2,nclasses
o = Conv2D( n_classes , (3, 3) , padding='same', data_format=IMAGE_ORDERING )( o )
# 将结果进行reshape
o = Reshape((int(input_height/2)*int(input_width/2), -1))(o)
o = Softmax()(o)
model = Model(img_input,o)
其首先利用filter为n_classes的卷积核进行卷积,此时输出为h_input/2,w_input/2,nclasses,对应着每一个hw像素点上的种类。
之后利用Softmax估计属于每一个种类的概率。
其最后预测y_pre其实就是每一个像素点属于哪一个种类的概率。
第二个是真实值,真实值是这样处理的。
# 从文件中读取图像
img = Image.open(r".\dataset2\png" + '/' + name)
img = img.resize((int(WIDTH/2),int(HEIGHT/2)))
img = np.array(img)
seg_labels = np.zeros((int(HEIGHT/2),int(WIDTH/2),NCLASSES))
for c in range(NCLASSES):
seg_labels[: , : , c ] = (img[:,:,0] == c ).astype(int)
seg_labels = np.reshape(seg_labels, (-1,NCLASSES))
Y_train.append(seg_labels)
其将png图先进行resize,resize后其大小与预测y_pre的hw相同,然后读取每一个像素点属于什么种类,并存入。
其最后真实y_true其实就是每一个像素点确实属于哪个种类。
最后loss函数的组成就是y_true和y_pre的交叉熵。
训练代码
大家可以在我的github上下载完整的代码。
https://github.com/bubbliiiing/Semantic-Segmentation
数据集的链接为:
链接:https://pan.baidu.com/s/1uzwqLaCXcWe06xEXk1ROWw
提取码:pp6w
1、文件存放方式
如图所示:

其中img和img_out是测试文件。
2、训练文件
训练文件如下:
from nets.segnet import resnet50_segnet
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from PIL import Image
import keras
from keras import backend as K
import numpy as np
NCLASSES = 2
HEIGHT = 416
WIDTH = 416
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for _ in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = Image.open(r".\dataset2\jpg" + '/' + name)
img = img.resize((WIDTH,HEIGHT))
img = np.array(img)
img = img/255
X_train.append(img)
name = (lines[i].split(';')[1]).replace("\n", "")
# 从文件中读取图像
img = Image.open(r".\dataset2\png" + '/' + name)
img = img.resize((int(WIDTH/2),int(HEIGHT/2)))
img = np.array(img)
seg_labels = np.zeros((int(HEIGHT/2),int(WIDTH/2),NCLASSES))
for c in range(NCLASSES):
seg_labels[: , : , c ] = (img[:,:,0] == c ).astype(int)
seg_labels = np.reshape(seg_labels, (-1,NCLASSES))
Y_train.append(seg_labels)
# 读完一个周期后重新开始
i = (i+1) % n
yield (np.array(X_train),np.array(Y_train))
def loss(y_true, y_pred):
crossloss = K.binary_crossentropy(y_true,y_pred)
loss = 4 * K.sum(crossloss)/HEIGHT/WIDTH
return loss
if __name__ == "__main__":
log_dir = "logs/"
# 获取model
model = resnet50_segnet(n_classes=NCLASSES,input_height=HEIGHT, input_width=WIDTH)
pretrained_url = "https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5"
weights_path = keras.utils.get_file( pretrained_url.split("/")[-1] , pretrained_url )
model.load_weights(weights_path,by_name=True)
# model.summary()
# 打开数据集的txt
with open(r".\dataset2\train.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 保存的方式,3世代保存一次
checkpoint_period = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=True,
save_best_only=True,
period=1
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
trainable_layer = 142
for i in range(trainable_layer):
model.layers[i].trainable = False
print('freeze the first {} layers of total {} layers.'.format(trainable_layer, len(model.layers)))
# 交叉熵
model.compile(loss = loss,
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
batch_size = 2
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=10,
initial_epoch=0,
callbacks=[checkpoint_period, reduce_lr])
model.save_weights(log_dir+'middle1.h5')
for i in range(len(model.layers)):
model.layers[i].trainable = True
# 交叉熵
model.compile(loss = loss,
optimizer = Adam(lr=1e-4),
metrics = ['accuracy'])
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=20,
initial_epoch=10,
callbacks=[checkpoint_period, reduce_lr])
model.save_weights(log_dir+'last1.h5')
3、预测文件
预测文件如下:
from nets.segnet import resnet50_segnet
from PIL import Image
import numpy as np
import random
import os
import copy
random.seed(0)
class_colors = [[0,0,0],[0,255,0]]
NCLASSES = 2
HEIGHT = 416
WIDTH = 416
model = resnet50_segnet(n_classes=NCLASSES,input_height=HEIGHT, input_width=WIDTH)
model.load_weights("logs/ep014-loss0.049-val_loss0.075.h5")
imgs = os.listdir("./img")
for jpg in imgs:
img = Image.open("./img/"+jpg)
old_img = copy.deepcopy(img)
orininal_h = np.array(img).shape[0]
orininal_w = np.array(img).shape[1]
img = img.resize((WIDTH,HEIGHT))
img = np.array(img)
img = img/255
img = img.reshape(-1,HEIGHT,WIDTH,3)
pr = model.predict(img)[0]
pr = pr.reshape((int(HEIGHT/2), int(WIDTH/2), NCLASSES)).argmax(axis=-1)
seg_img = np.zeros((int(HEIGHT/2), int(WIDTH/2),3))
colors = class_colors
for c in range(NCLASSES):
seg_img[:,:,0] += ( (pr[:,: ] == c )*( colors[c][0] )).astype('uint8')
seg_img[:,:,1] += ((pr[:,: ] == c )*( colors[c][1] )).astype('uint8')
seg_img[:,:,2] += ((pr[:,: ] == c )*( colors[c][2] )).astype('uint8')
seg_img = Image.fromarray(np.uint8(seg_img)).resize((orininal_w,orininal_h))
image = Image.blend(old_img,seg_img,0.3)
image.save("./img_out/"+jpg)
训练结果
原图:

处理后:
