主要是利用
s
i
n
(
2
π
x
)
sin(2\pi x)
sin(2πx)函数产生样本,其中
x
x
x均匀分布在
[
0
,
1
]
[0, 1]
[0,1]之间,对于每一个目标值
t
=
s
i
n
(
2
π
x
)
t=sin(2\pi x)
t=sin(2πx)增加一个
0
0
0均值,方差为
0.25
0.25
0.25的高斯噪声。
defget_data(
x_range:(float,float)=(0,1),
sample_num:int=10,
base_func=lambda x: np.sin(2* np.pi * x),
noise_scale=0.25,)->"pd.DataFrame":
X = np.linspace(x_range[0], x_range[1], num=sample_num)
Y = base_func(X)+ np.random.normal(scale=noise_scale, size=X.shape)
data = pd.DataFrame(data=np.dstack((X, Y))[0], columns=["X","Y"])return data
2、利用高阶多项式函数拟合曲线(不带惩罚项)
利用训练集合,对于每个新的
x
^
\hat{x}
x^,预测目标值
t
^
\hat{t}
t^。采用多项式函数进行学习,即利用式
(
1
)
(1)
(1)来确定参数
w
w
w,假设阶数
m
m
m已知。
y
(
x
,
w
)
=
w
0
+
w
1
x
+
⋯
+
w
m
x
m
=
∑
i
=
0
m
w
i
x
i
(1)
y(x, w) = w_0 + w_1x + \dots + w_mx^m = \sum_{i = 0}^{m}w_ix^i \tag{1}
y(x,w)=w0+w1x+⋯+wmxm=i=0∑mwixi(1)
采用最小二乘法,即建立误差函数来测量每个样本点目标值
t
t
t与预测函数
y
(
x
,
w
)
y(x, w)
y(x,w)之间的误差,误差函数即式
(
2
)
(2)
(2)
E
(
w
)
=
1
2
∑
i
=
1
N
{
y
(
x
i
,
w
)
−
t
i
}
2
(2)
E(\bold{w}) = \frac{1}{2} \sum_{i = 1}^{N} \{y(x_i, \bold{w}) - t_i\}^2 \tag{2}
E(w)=21i=1∑N{y(xi,w)−ti}2(2)
将上式写成矩阵形式如式
(
3
)
(3)
(3)
E
(
w
)
=
1
2
(
X
w
−
T
)
′
(
X
w
−
T
)
(3)
E(\bold{w}) = \frac{1}{2} (\bold{Xw} - \bold{T})'(\bold{Xw} - \bold{T})\tag{3}
E(w)=21(Xw−T)′(Xw−T)(3)
其中
X
=
[
1
x
1
⋯
x
1
m
1
x
2
⋯
x
2
m
⋮
⋮
⋱
⋮
1
x
N
⋯
x
N
m
]
,
w
=
[
w
0
w
1
⋮
w
m
]
,
T
=
[
t
1
t
2
⋮
t
N
]
\bold{X} = \left[ \begin{matrix} 1 & x_1 & \cdots & x_1^m \\ 1 & x_2 & \cdots & x_2^m \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_N & \cdots & x_N^m \\ \end{matrix} \right], \bold{w} = \left[ \begin{matrix} w_0 \\ w_1 \\ \vdots \\ w_m \end{matrix} \right], \bold{T} = \left[ \begin{matrix} t_1 \\ t_2 \\ \vdots \\ t_N \end{matrix} \right]
X=⎣⎢⎢⎢⎡11⋮1x1x2⋮xN⋯⋯⋱⋯x1mx2m⋮xNm⎦⎥⎥⎥⎤,w=⎣⎢⎢⎢⎡w0w1⋮wm⎦⎥⎥⎥⎤,T=⎣⎢⎢⎢⎡t1t2⋮tN⎦⎥⎥⎥⎤ 通过将上式求导我们可以得到式
(
4
)
(4)
(4)
∂
E
∂
w
=
X
′
X
w
−
X
′
T
(4)
\cfrac{\partial E}{\partial \bold{w}} = \bold{X'Xw} - \bold{X'T} \tag{4}
∂w∂E=X′Xw−X′T(4)
令
∂
E
∂
w
=
0
\cfrac{\partial E}{\partial \bold{w}}=0
∂w∂E=0 我们有式
(
5
)
(5)
(5)即为
w
∗
\bold{w^*}
w∗
w
∗
=
(
X
′
X
)
−
1
X
′
T
(5)
\bold{w^*} = (\bold{X'X})^{-1}\bold{X'T} \tag{5}
w∗=(X′X)−1X′T(5)
在不带惩罚项的多项式拟合曲线时,在参数多时
w
∗
\bold{w}^*
w∗具有较大的绝对值,本质就是发生了过拟合。对于这种过拟合,我们可以通过在优化目标函数式
(
3
)
(3)
(3)中增加
w
\bold{w}
w的惩罚项,因此我们得到了式
(
6
)
(6)
(6)。
E
~
(
w
)
=
1
2
∑
i
=
1
N
{
y
(
x
i
,
w
)
−
t
i
}
2
+
λ
2
∣
∣
w
∣
∣
2
(6)
\widetilde{E}(\bold{w}) = \frac{1}{2} \sum_{i=1}^{N} \{y(x_i, \bold{w}) - t_i\}^2 + \cfrac{\lambda}{2}|| \bold{w} || ^ 2 \tag{6}
E(w)=21i=1∑N{y(xi,w)−ti}2+2λ∣∣w∣∣2(6)
同样我们可以将式
(
6
)
(6)
(6)写成矩阵形式, 我们得到式
(
7
)
(7)
(7)
E
~
(
w
)
=
1
2
[
(
X
w
−
T
)
′
(
X
w
−
T
)
+
λ
w
′
w
]
(7)
\widetilde{E}(\bold{w}) = \frac{1}{2}[(\bold{Xw} - \bold{T})'(\bold{Xw} - \bold{T}) + \lambda \bold{w'w}]\tag{7}
E(w)=21[(Xw−T)′(Xw−T)+λw′w](7)
对式
(
7
)
(7)
(7)求导我们得到式
(
8
)
(8)
(8)
∂
E
~
∂
w
=
X
′
X
w
−
X
′
T
+
λ
w
(8)
\cfrac{\partial \widetilde{E}}{\partial \bold{w}} = \bold{X'Xw} - \bold{X'T} + \lambda\bold{w} \tag{8}
∂w∂E=X′Xw−X′T+λw(8)
令
∂
E
~
∂
w
=
0
\cfrac{\partial \widetilde{E}}{\partial \bold{w}} = 0
∂w∂E=0 我们得到
w
∗
\bold{w^*}
w∗即式
(
9
)
(9)
(9),其中
I
\bold{I}
I为单位阵。
w
∗
=
(
X
′
X
+
λ
I
)
−
1
X
′
T
(9)
\bold{w^*} = (\bold{X'X} + \lambda\bold{I})^{-1}\bold{X'T}\tag{9}
w∗=(X′X+λI)−1X′T(9)
对于
f
(
x
)
f(\bold{x})
f(x)如果在
x
i
\bold{x_i}
xi点可微且有定义,我们知道顺着梯度
∇
f
(
x
i
)
\nabla f(\bold{x_i})
∇f(xi)为增长最快的方向,因此梯度的反方向
−
∇
f
(
x
i
)
-\nabla f(\bold{x_i})
−∇f(xi) 即为下降最快的方向。因而如果有式
(
10
)
(10)
(10)对于
α
>
0
\alpha > 0
α>0 成立,
x
i
+
1
=
x
i
−
α
∇
f
(
x
i
)
(10)
\bold{x_{i+1}}= \bold{x_i} - \alpha \nabla f(\bold{x_i}) \tag{10}
xi+1=xi−α∇f(xi)(10)
那么对于序列
x
0
,
x
1
,
…
\bold{x_0}, \bold{x_1}, \dots
x0,x1,… 我们有
f
(
x
0
)
≥
f
(
x
1
)
≥
…
f(\bold{x_0}) \ge f(\bold{x_1}) \ge \dots
f(x0)≥f(x1)≥…
因此,如果顺利我们可以得到一个
f
(
x
n
)
f(\bold{x_n})
f(xn) 收敛到期望的最小值,对于此次实验很大可能性可以收敛到最小值。
defgradient_descent_fit(x_matrix, t_vec, lambda_penalty, w_vec_0, learning_rate=0.1, delta=1e-6):
loss_0 = calc_loss(x_matrix, t_vec, lambda_penalty, w_vec_0)
k =0
w = w_vec_0
whileTrue:
w_ = w - learning_rate * calc_derivative(x_matrix, t_vec, lambda_penalty, w)
loss = calc_loss(x_matrix, t_vec, lambda_penalty, w_)if np.abs(loss - loss_0)< delta:breakelse:
k +=1if loss > loss_0:
learning_rate *=0.5
loss_0 = loss
w = w_
return k, w
5、共轭梯度法求解最优解
共轭梯度法解决的主要是形如
A
x
=
b
\bold{Ax} = \bold{b}
Ax=b的线性方程组解的问题,其中
A
\bold{A}
A必须是对称的、正定的。大概来说,共轭梯度下降就是在解空间的每一个维度分别取求解最优解的,每一维单独去做的时候不会影响到其他维,这与梯度下降方法,每次都选泽梯度的反方向去迭代,梯度下降不能保障每次在每个维度上都是靠近最优解的,这就是共轭梯度优于梯度下降的原因。
对于第 k 步的残差
r
k
=
b
−
A
x
k
\bold{r_k = b - Ax_k}
rk=b−Axk,我们根据残差去构造下一步的搜索方向
p
k
\bold{p_k}
pk,初始时我们令
p
0
=
r
0
\bold{p_0 = r_0}
p0=r0。然后利用
G
r
a
m
−
S
c
h
m
i
d
t
Gram-Schmidt
Gram−Schmidt方法依次构造互相共轭的搜素方向
p
k
\bold{p_k}
pk,具体构造的时候需要先得到第 k+1 步的残差,即
r
k
+
1
=
r
k
−
α
k
A
p
k
\bold{r_{k+1} = r_k - \alpha_kAp_k}
rk+1=rk−αkApk,其中
α
k
\alpha_k
αk如后面的式
(
11
)
(11)
(11)。
根据第 k+1 步的残差构造下一步的搜索方向
p
k
+
1
=
r
k
+
1
+
β
k
+
1
p
k
\bold{p_{k+1} = r_{k+1} + \beta_{k+1}p_k}
pk+1=rk+1+βk+1pk,其中
β
k
+
1
=
r
k
+
1
T
r
k
+
1
r
k
T
r
k
\beta_{k+1} = \bold{\cfrac{r_{k+1}^Tr_{k+1}}{r_k^Tr_k}}
βk+1=rkTrkrk+1Trk+1。
然后可以得到
x
k
+
1
=
x
k
+
α
k
p
k
\bold{x_{k+1} = x_k + \alpha_kp_k}
xk+1=xk+αkpk,其中
α
k
=
p
k
T
(
b
−
A
x
k
)
p
k
T
A
p
k
=
p
k
T
r
k
p
k
T
A
p
k
\alpha_k = \cfrac{\bold{p_k}^T(\bold{b} - \bold{Ax_k})}{\bold{p_k}^T\bold{Ap_k}} = \cfrac{\bold{p_k}^T\bold{r_k}}{{\bold{p_k}^T\bold{Ap_k}}}
αk=pkTApkpkT(b−Axk)=pkTApkpkTrk
对于第 k 步的残差
r
k
=
b
−
A
x
\bold{r_k} = \bold{b} - \bold{Ax}
rk=b−Ax,
r
k
\bold{r_k}
rk为
x
=
x
k
\bold{x} = \bold{x_k}
x=xk时的梯度反方向。由于我们仍然需要保证
p
k
\bold{p_k}
pk 彼此共轭。因此我们通过当前的残差和之前所有的搜索方向来构建
p
k
\bold{p_k}
pk,得到式
(
11
)
(11)
(11)
p
k
=
r
k
−
∑
i
<
k
p
i
T
A
r
k
p
i
T
A
p
i
p
i
(11)
\bold{p_k} = \bold{r_k} - \sum_{i < k}\cfrac{\bold{p_i}^T\bold{Ar_k}}{\bold{p_i}^T\bold{Ap_i}}\bold{p_i}\tag{11}
pk=rk−i<k∑piTApipiTArkpi(11)
进而通过当前的搜索方向
p
k
\bold{p_k}
pk得到下一步优化解
x
k
+
1
=
x
k
+
α
k
p
k
\bold{x_{k+1}} = \bold{x_k} + \alpha_k\bold{p_k}
xk+1=xk+αkpk,其中
α
k
=
p
k
T
(
b
−
A
x
k
)
p
k
T
A
p
k
=
p
k
T
r
k
p
k
T
A
p
k
\alpha_k = \cfrac{\bold{p_k}^T(\bold{b} - \bold{Ax_k})}{\bold{p_k}^T\bold{Ap_k}} = \cfrac{\bold{p_k}^T\bold{r_k}}{{\bold{p_k}^T\bold{Ap_k}}}
αk=pkTApkpkT(b−Axk)=pkTApkpkTrk
求解的方法就是我们先猜一个解
x
0
\bold{x_0}
x0,然后取梯度的反方向
p
0
=
b
−
A
x
\bold{p_0} = \bold{b} - \bold{Ax}
p0=b−Ax,在 n 维空间的基中
p
0
\bold{p_0}
p0要与其与的基共轭并且为初始残差。
(
X
′
X
+
λ
I
)
w
∗
=
X
′
T
(12)
(\bold{X'X} + \lambda\bold{I})\bold{w^*} = \bold{X'T}\tag{12}
(X′X+λI)w∗=X′T(12)
令
{
A
=
X
′
X
+
λ
I
b
=
X
′
T
(13)
\left\{ \begin{array}{lr} \bold{A} = \bold{X'X} + \lambda\bold{I} & \\ \bold{b} = \bold{X'T} \end{array} \right.\tag{13}
{A=X′X+λIb=X′T(13)
defswitch_deri_func_for_conjugate_gradient(x_matrix, t_vec, lambda_penalty, w_vec):
A = x_matrix.T @ x_matrix - lambda_penalty * np.identity(len(x_matrix.T))
x = w_vec
b = x_matrix.T @ t_vec
return A, x, b
通过共轭梯度下降法求解
A
x
=
b
Ax=b
Ax=b
defconjugate_gradient_fit(A, x_0, b, delta=1e-6):
x = x_0
r_0 = b - A @ x
p = r_0
k =0whileTrue:
alpha =(r_0.T @ r_0)/(p.T @ A @ p)
x = x + alpha * p
r = r_0 - alpha * A @ p
if r_0.T @ r_0 < delta:break
beta =(r.T @ r)/(r_0.T @ r_0)
p = r + beta * p
r_0 = r
k +=1return k, x
解得
x
x
x,并记录迭代次数
k
k
k
四、实验结果分析
1、不带惩罚项的解析解
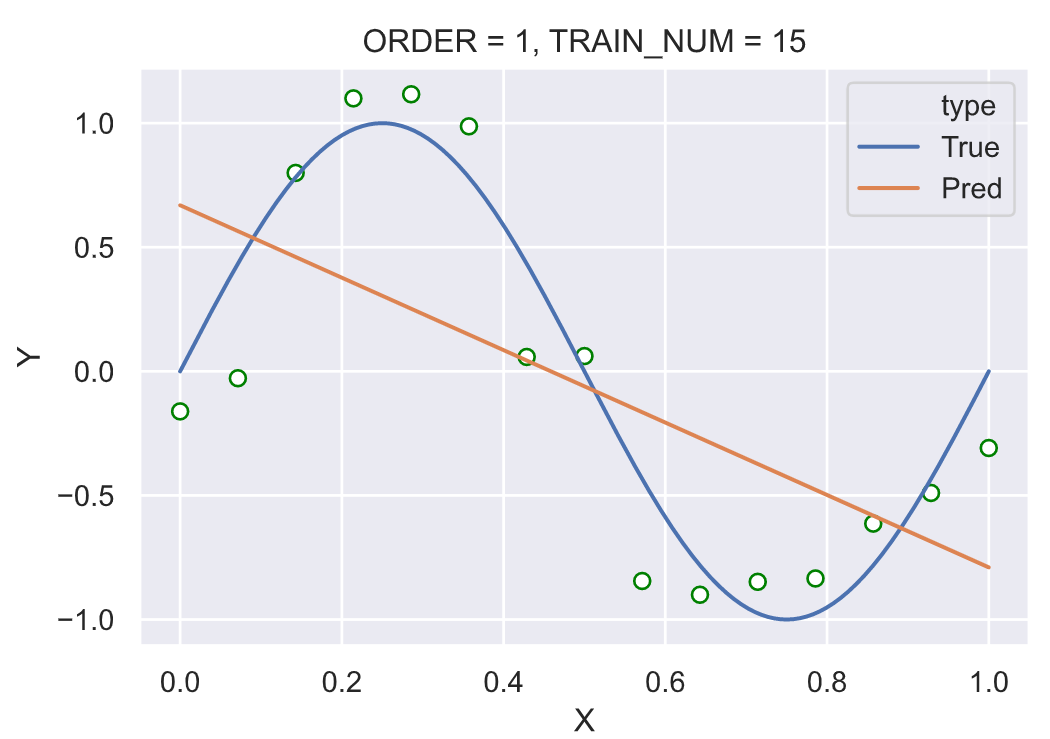
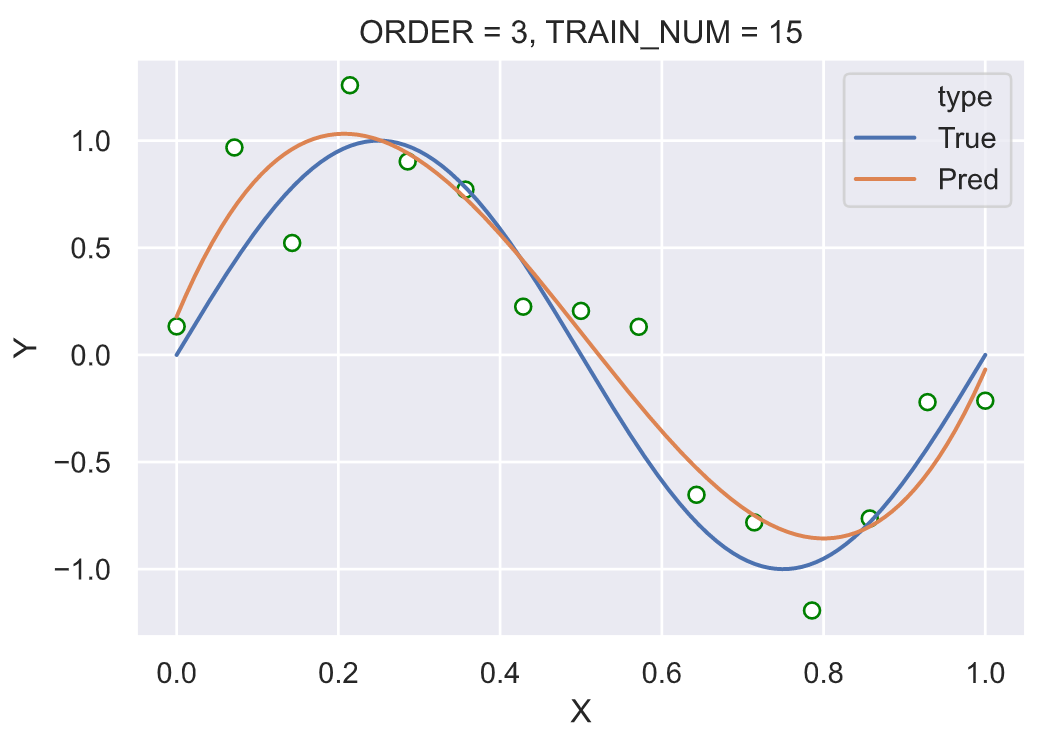
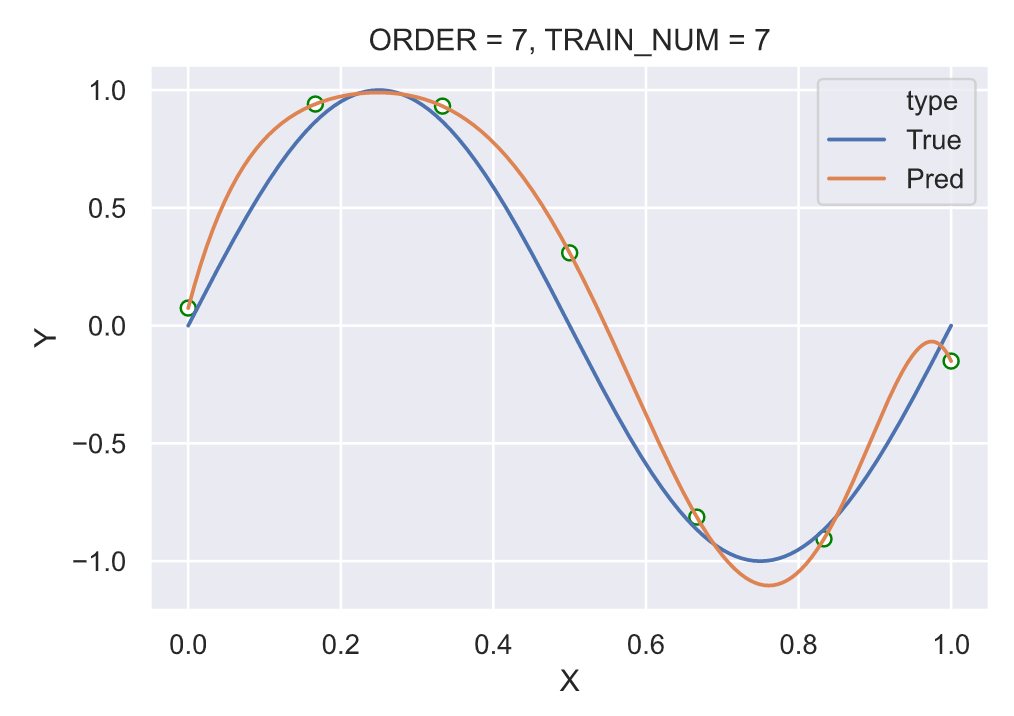
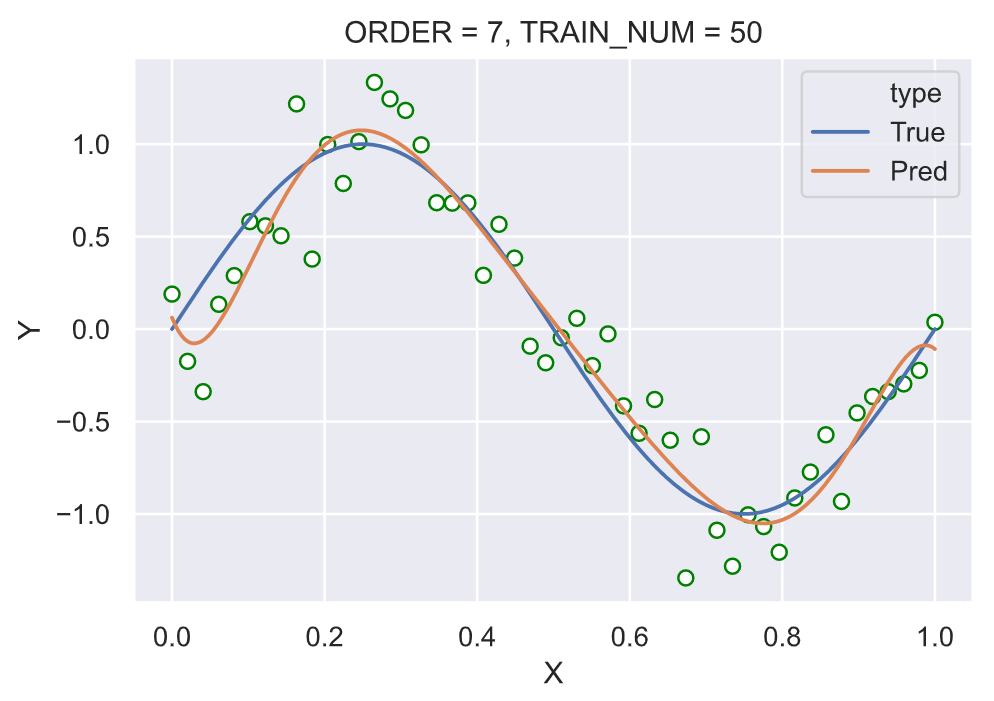
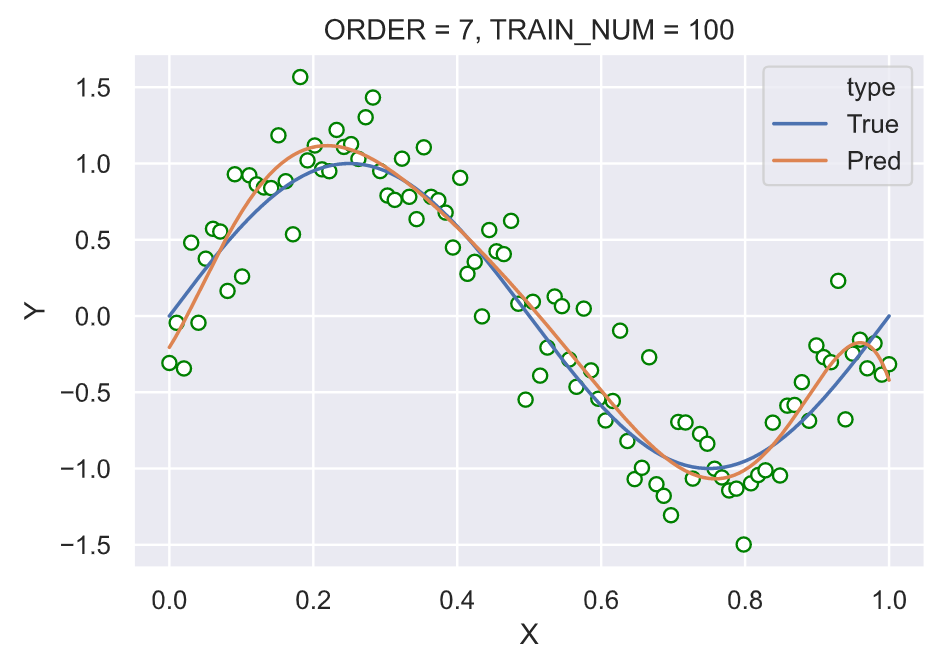
固定训练样本的大小为 15,分别使用不同多项式阶数,测试:
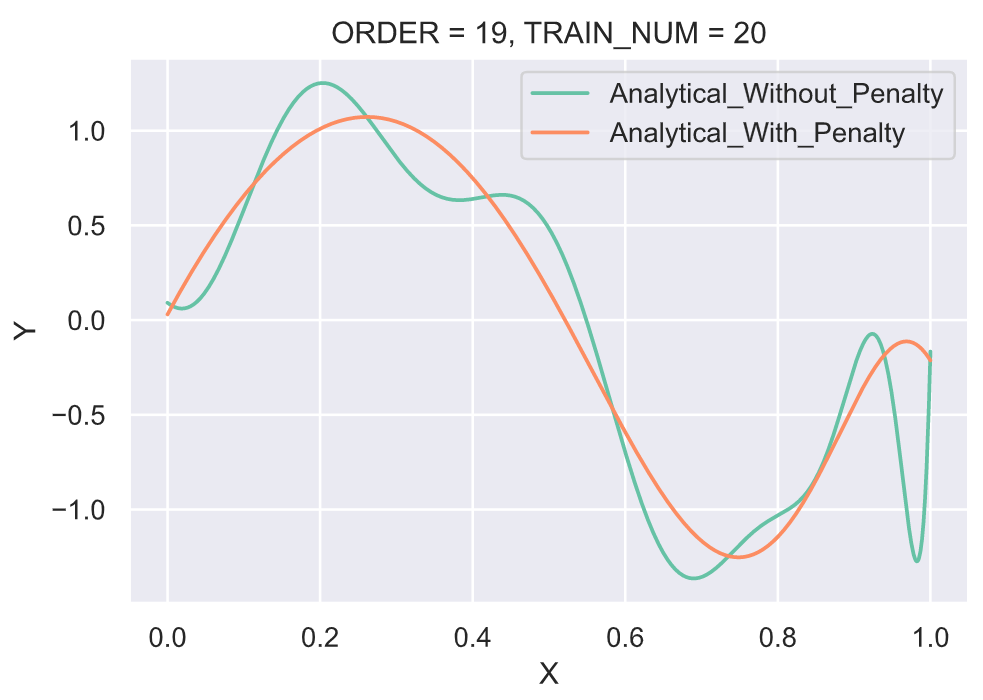
我们可以看到在固定训练样本的大小之后,在多项式阶数为 3 时的拟合效果已经很好。继续提高多项式的阶数,尤其在阶数为 14 的时候曲线“完美的”经过了所有的节点,这种剧烈的震荡并没有很好的拟合真实的背后的函数
s
i
n
(
2
π
x
)
sin(2\pi x)
sin(2πx),反而将所有噪声均很好的拟合,即表现出来一种过拟合的情况。
其出现过拟合的本质原因是,在阶数过大的情况下,模型的复杂度和拟合的能力都增强,因此可以通过过大或者过小的系数来实现震荡以拟合所有的数据点,以至于甚至拟合了所有的噪声。在这里由于我们的数据样本大小只有 15,所以在阶数为 14 的时候,其对应的系数向量
w
\bold{w}
w恰好有唯一解,因此可以穿过所有的样本点。
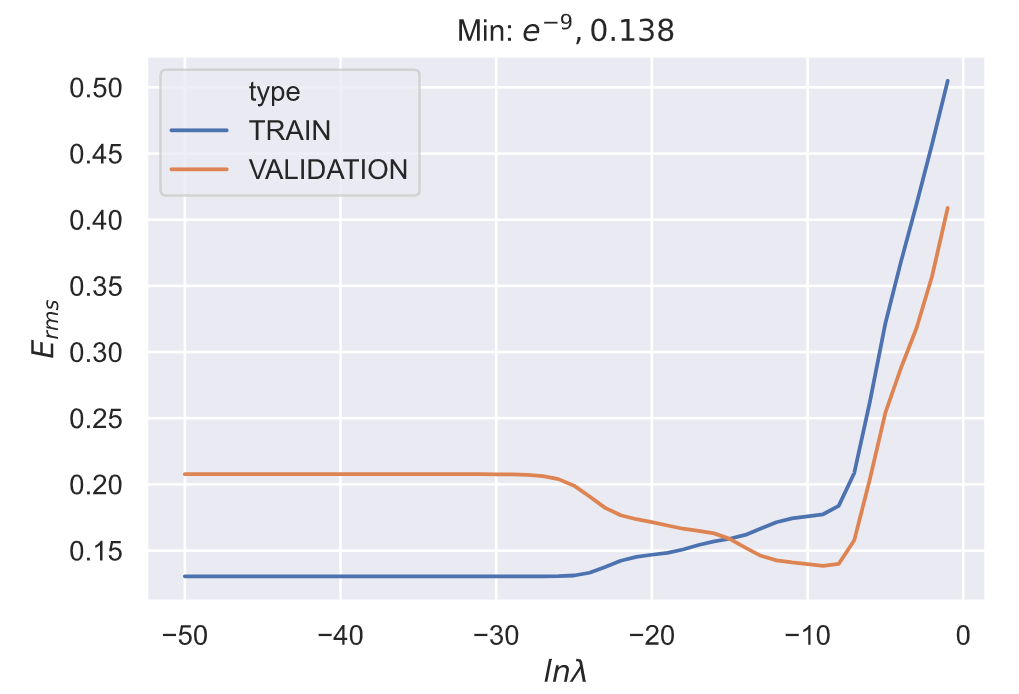
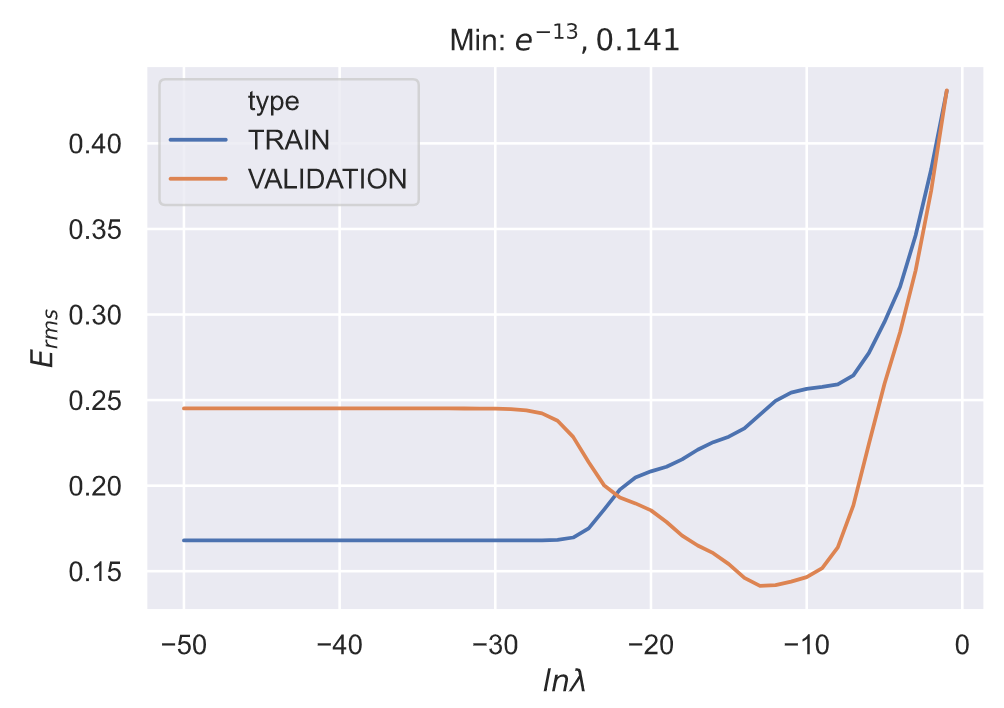
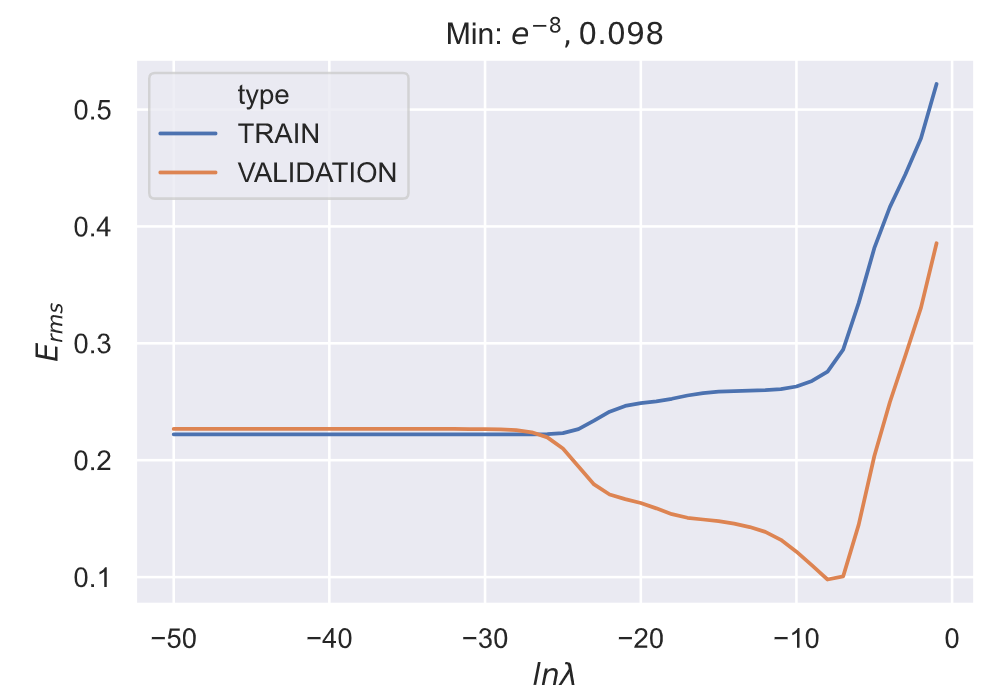
观察上面的四张图, 我们可以发现对于超参数
λ
\lambda
λ的选择,在
(
e
−
50
,
e
−
30
)
(e^{-50}, e^{-30})
(e−50,e−30)左右保持一种相对稳定的错误率;但是在
(
e
−
30
,
e
−
5
)
(e^{-30}, e^{-5})
(e−30,e−5)错误率有一个明显的下降,所以下面在下面的完整 100 次实验中我们可以看到最佳参数的分布区间也大都在这个范围内;在大于
e
−
5
e^{-5}
e−5的区间内,错误率有一个急剧的升高。
对于不同训练集,超参数
λ
\lambda
λ的选择不同。 因此每生成新训练集,则通过带惩罚项的解析解计算出当前的
b
e
s
t
_
l
a
m
b
d
a
best\_lambda
best_lambda,用于带惩罚项的解析解、梯度下降和共轭梯度下降。
一般来说,最佳的超参数范围在
(
e
−
10
,
e
−
6
)
(e^{-10}, e^{-6})
(e−10,e−6)之间。
比较是否带惩罚项的拟合曲线
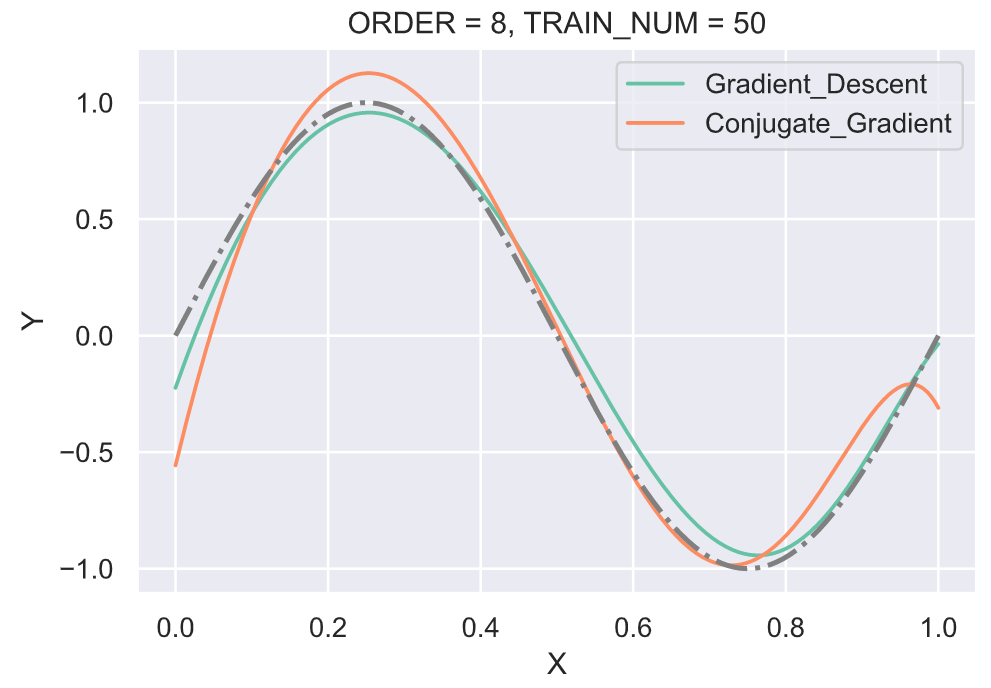
3、优化解
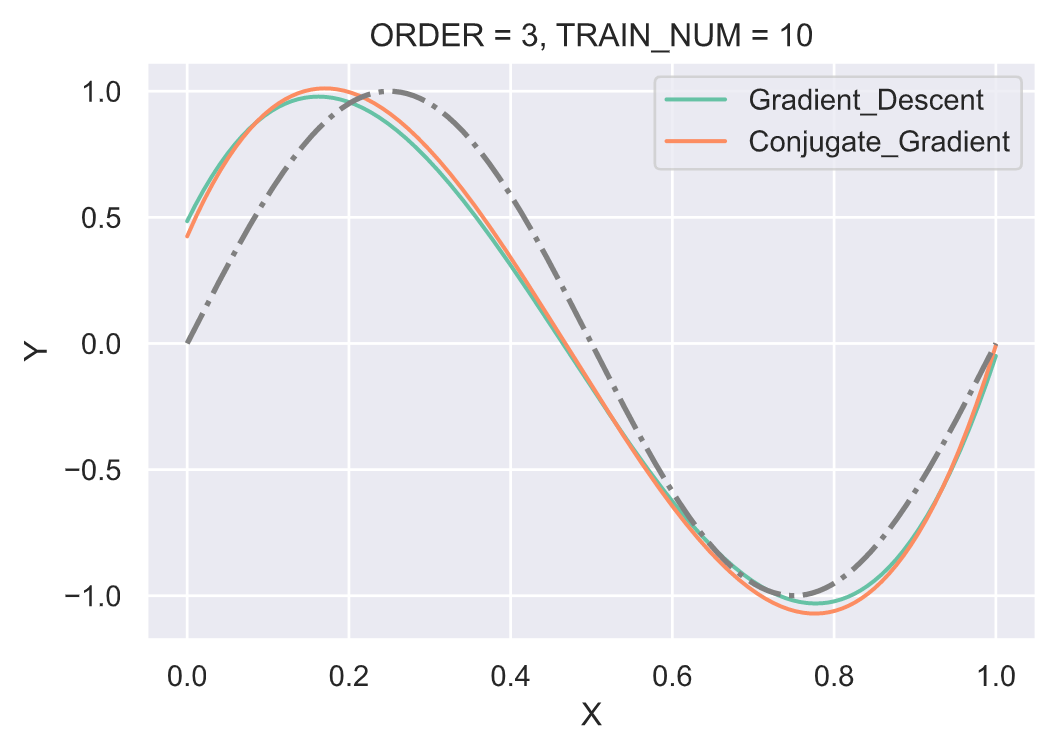
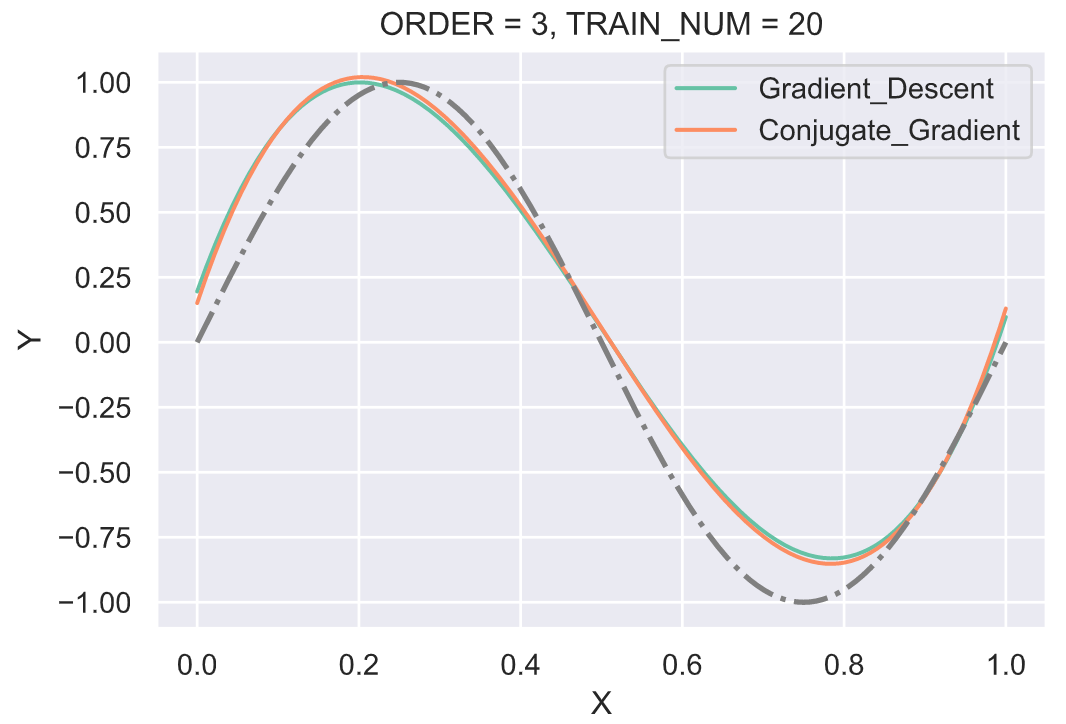
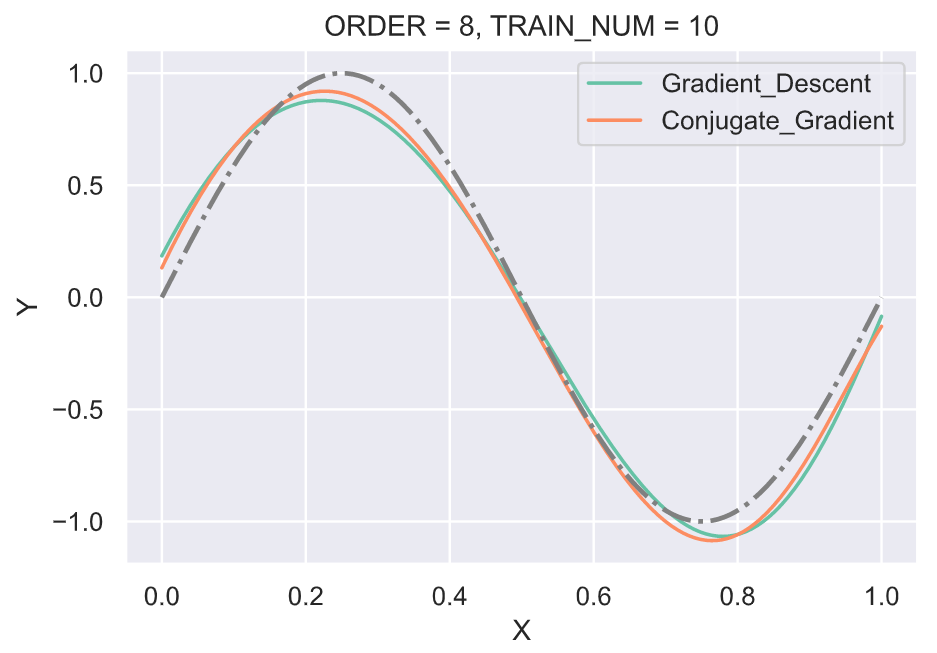
实验利用梯度下降(Gradient descent)和共轭梯度法(Conjugate gradient)两种方法来求优化解。由于该问题是有解析解存在,并且在之前的实验报告部分已经列出,所以在此处直接利用上面的解析解进行对比。此处使用的学习率固定为
l
e
a
r
n
i
n
g
_
r
a
t
e
=
0.01
learning\_rate = 0.01
learning_rate=0.01,停止的精度要求为
1
×
1
0
−
6
1 \times 10 ^ {-6}
1×10−6。