前几天学习爬虫,总结如下:
一、 Request
1. get函数初介绍
r = request.get(URL, params, **kawarg)
- params :额外的参数,字典或者字节流格式, 可选
- **kawarg: 12个控制访问的参数。
返回的r是包含服务器资源的Response对象
2. response 对象
属性:
| 属性 |
说明 |
| r,status_code |
HTTP请求的返回状态,200表示正常 |
| r.text |
HTTP相应的字符串形式 |
| r. enconding |
HTTPheader中猜测的相应内容编码方式 |
| r.apparent_encoding |
从内容中分析出的相应内容编码方式 |
| r.content |
HTTP相应内容的二进制形式 |
两种编码方式 encoding 和apparent_encoding区别:
encoding 就是提取header中charset 字段信息
apparent_encoding根据内容分析编码方式,更加准确
3. Request库异常
| 异常 |
说明 |
| request.ConnectionError |
网络连接错误异常,如DNS查询失败,拒绝连接等。 |
| request.HTTPErrot |
HTTP错误异常 |
| request.URLRequired |
URL缺失异常 |
| requests.TooManyRedirects |
超过最大重定向次数,产生重定向异常 |
| requests.ConnextTimeout |
连接远程服务器超时异常 |
| requests.Timeout |
请求URL超时,产生超时异常 |
根据Response库提供函数确定异常,比如r.raise_for_status(),判断返回内容是否正常,如果不是返回200,说明产生异常requests.HTTPError
4. 通用代码框架
import requests
def getHTMLTexxt(url):
try:
r = request.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
5. Request库七个主要方法
| 方法 |
说明 |
| requests.request() |
构造一个请求,支撑以下各个方法的基础方法 |
| request.get() |
获取HTML网页的主要方法,对应于HTTP的GET方法 |
| request.head() |
获取HTML网页头信息的方法 |
| request.post() |
获取网页提交POST请求的方法 |
| request.put() |
向HTML网页提交PUT请求的方法 |
| request.patch() |
向HTML网页提价局部修改请求 |
| request.delete() |
向HTML页面提交删除请求 |

PATCH和PUT的区别:
假设URL位置有一组USERInfo,包括UserID, UsserName等20个字段。
采用PATCH,只是向URL提交UserName的局部更新
采用PUT,必须将所有20个字段一并提交到URL,未提交字段将会被删除。
r = requests.head("http://www.baidu.com")
r.headers
r.text
payload = {'key1':'value1','key2':'value2'}
r = request.post{'http://httpbin.org/post', data = payload}
r.text
post根据用户提交的内容不同,在服务器上进行相关的整理。

其他的六种方法都是基于requset方法直接封装起来的。
6. 控制访问参数
request.request(method, url, ** kwargs)
**kwargs::控制访问的参数,均为可选项
- params:字典或字节序列,作为参数增加到url中

- data: 字典,字节序列或文件对象,作为Request内容

我们提交的data会放在URL对应的地方作为数据存储。
- json 作为Request的内容, 和data很像,会把数据赋值到服务器的json域
- headers: 字典,HTTP定制头

request函数共13个访问控制参数:

request.get函数有12个访问控制参数,request.head有13个,post, get, put patch, delete他们的访问控制参数都几乎和上面相同。
二、Robots协议
网站根目录下robots.txt, 不提供robots就是指可以无限制的爬取
三、beautifulSoup
对文件内容进行树形解析。
from bs4 import BeautifulSoup
import bs4
1. 解析器
| 解析器 |
使用方法 |
条件 |
| bs4的HTML解析器 |
BeautiSoup(mk,‘heml.parser’) |
安装bs4库 |
| lxml的HTML解析器 |
BeautifulSoup(mk,‘lxml’) |
pip install lxml |
| lxml的xml解析器 |
BeautiSoup(mk,‘xml’) |
pop instal lxml |
| html5lib的解析器 |
BeautifulSoup(mk,‘html5lib’ |
pip install html5lib |
2. beautifulSoup库的基本元素
| 基本元素 |
说明 |
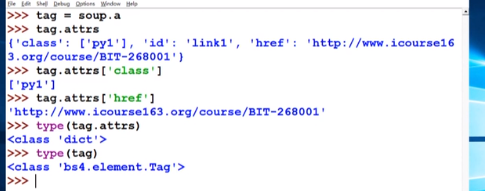
| Tag |
标签,最基本的信息组织单元,用<> </>表示开头结尾 |
| Name |
标签的名字,比如 … 的名字为‘p’ |
| Attribute |
标签树形,字典形式,格式:.attrs |
| NavigableString |
标签内非属性字符串,<>…</>中字符串 |
| Commet |
标签内字符串的注释部分 |
3. 遍历

| 属性 |
说明 |
| .contents |
子节点的列表,将的所有儿子节点存入列表 |
| .childrens |
子节点的迭代类型, 与.contents类似, 用于循环遍历儿子节点 |
| .descentants |
|

| 属性 |
说明 |
| .parent |
节点的父亲标签 |
| .parents |
节点先辈标签的迭代类型,用于循环遍历先辈节点 |

| 属性 |
说明 |
| .next_sibling |
返回HTML文本顺序的下一个平行节点标签 |
| .previous_sibling |
返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings |
迭代类型,返回按照HTML顺序的后续所有平行节点标签 |
| .previous_siblings |
迭代类型,返回按照HTML文本顺序的前序所有平行节点标签 |


4. 信息标记三种类型
- XML, 标签
- json, 有类型的键值对
- yaml , 无类型的键值对 ,通过缩进表达所属关系



三种信息形式的比较
XML Internet上信息交互和传递
Json 移动应用云端和节点的信息通信,无注释
YAML 各类系统的配置文件,有注释易读
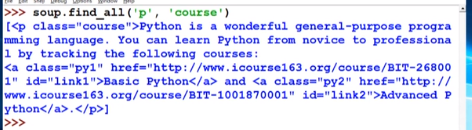
5. find_all函数
<>.find_all(name, attrs, recursive, string, **kwags)
返回一个列表类型,存储查找的结果
name: 对标签名臣的检索字符串
attrs:对标签属性值进行检索
recursive: 是否对子孙全部检索,默认为TRUE
string: <>…</>中字符串区域的检索字符串



(…)等价于 .find_all(…)
(…)等价于 soup.find_all(…)
扩展方法
| 方法 |
说明 |
| <.find()> |
搜索只返回一个类型,字符串类型,参数和find_all相同 |
| <>.find_parents() |
在先辈节点中搜索,返回列表类型 |
| <>.find_parent() |
在先辈节点返回一个结果,字符串类型 |
| <>.find_next_siblings() |
后续平行节点中搜索,返回列表类型 |
| <>.find_next_sibling() |
后续平行节点中搜索一个结果,返回字符串 |
| <>.find_previous_siblings() |
前序平行节点中搜索,返回列表类型 |
| <>.find_previous_sibling() |
前序平行节点中搜索一个结果 |
四、正则表达式
1. 常用的操作符


raw string类型(原生字符串类型),表示为:r’text’
原生的字符串就是不包含转义符的字符串。
2. 主要功能函数
| 函数 |
说明 |
| re.search() |
在字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() |
从一个字符串的开始位置起匹配正则表达式,返回match 对象 |
| re.findall() |
搜索字符串,列表类型返回全部匹配的字符串 |
| re.spilit() |
讲一个字符串按照正则表达式匹配结果进行分割,返回类表类型 |
| re.finditer() |
搜索字符串,返回一个匹配结果的跌打类型,每个迭代元素是match元素 |
| re.sub() |
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
- re.search(pattern, string, flags = 0)
- flag: 正则表达式使用时的控制标记
- re.I re.IGNORECASE 忽略正则表达式大小写
- re.M re.MULTILINE 正则表达式中的^操作符可以将给定字符串的每行当做匹配开始
- re.S re.DOTALL 正则表达式中的操作符能匹配所有字符,默认匹配除换行外所有字符。
match = re.search(r'[1-9]\d{5}','BIT 100081')
Iif match:
print(match.group(0))
>>> 100081
- re,match(pattern, string, flags = 0)
match = re.match(r'[1-9]\d{5}','BIT 100081')
if match:
match.group(0)
>>>输出为空
match = re.match(r'[1-9]\d{5}','100081 BIT')
if match:
match.group(0)
>>>100081
- re.findall(pattern, string, flags = 0)
ls = re.findall(r'[1-9]\d{5}','BIT 100081 198788HU')
ls
>>>['100081','198788']
- re.split(pattern, string, maxsplit = 0, flags = 0)
- maxsplit :最大分隔数,如果数值小于匹配结果,剩余的部分作为最后一个元素输出
re.split(r'[1-9]\d{5}','BIT100081 519878HU', maxsplit = 1)
>>['BIT',' 519879HU']
- re.finditer(pattern, string, flags = 0)
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084')
if m:
print(m.group(0))
- re.sub(pattern, repl, string, count = 0, flags = 0)
- 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
- repl: 替换匹配字符串的字符串
- string 带匹配的字符串
- count 匹配的最大替换次数
re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TSU100084')
>> 'BIT:zipcode TSU:zipcode'
3. 等价写法
rst = re.search(r’[1-9]\d{5}’,‘BIT 100081’)
等价于
pat = re.compile(r’[1-9]\d{5}’)
rst = pat.search(‘BIT 100081’)
函数式用法是一次性操作
面向对象的写法,用于编译后的多次操作
regex = re.compile(pattern, flags = 0)

对于之前的写法只是去掉了pattern对象
4. match对象
type(match)
<class '-src.SRE_Match'>
| 属性 |
说明 |
| .string |
带匹配的文本 |
| .re |
匹配时的pattern对象 |
| .pos |
正则表达式搜索文本的开始位置 |
| .endpos |
正则表达式搜索文本的结束位置 |
| 方法 |
说明 |
| .group(0) |
获得匹配后的字符串 |
| .start() |
匹配字符串在原始字符串的开始位置 |
| ,end() |
匹配字符串在原始字符串的结束位置 |
| .span() |
返回(.start(), .end() |
match 对象是返回一次的结果,如果想获得所有的匹配结果,可以使用finditer()

5. 贪婪匹配和最小匹配
re库默认使用贪婪匹配,即输出匹配最长的子串
如何输出最小匹配呢?
当我们看到一个操作符匹配结果有不同长度的时候,可以在后边加一个问号,返回最小结果。
match = re.search(r'PY.*N','PYANBNCNDN')
match.group(0)
>>>'PYANBNCNDN'
match = re.search(r'PY.*?N','PYANBNCNDN')
match.group(0)
>>> 'PYAN'
| 操作符 |
说明 |
| *? |
前一个字符0次货无限次扩展,最小匹配 |
| +? |
前一个字符1次或多次扩展,最小匹配 |
| ?? |
前一个字符0次或1次扩展,最小匹配 |
| {m,n}? |
前一个字符m到n次,包含n, 最小匹配 |
五、scrapy

- spider middleware
- 目的: 对请求和爬取项再处理
- 功能:修改丢弃,新增请求或者爬取项
- 用户可以编写配置代码
- scrapy 命令行格式
scrapy [options][args]

-
工程目录

-
yield关键字
生成器是一个不断产生值的函数
包含yield语句的函数就是一个生成器
生成器每次产生一个值,函数被冻结,唤醒后在产生一个值

如果N = 1M, 10M, 100M
普通写法占用很大的存储空间,并且相应速度慢
和我们之前学习的Request库不是一个方法
class scarpy.http.Request()
Request对象表示一个HTTP请求
由spider生成,由Downloader执行

class scrapy.http.Response()
Response对象表示一个HTTP相应
由Downloader生成,由Spider处理

class scrapy.item.Item()
Item 对象表示一个从HTML页面中提取的信息内容
由spider生成,由Item Pipeline 处理
Item 类似字典类型,可以按照字典类型操作
- 爬虫提取信息的方法
- spider 模块可以使用的方法
- Beautiful Soup
- lxml
- re
- Xpath Selector
- CSS Selector
- 编写步骤
- 建立工程和spider模块
scrapy startproject BaiduStocks
cd BaiduStocks
scrapy genspider stocks baidu.com
进一步修改spiders/stocks.py文件
- 编写spider
修改配配stacks.py文件
修改对返回页面的处理
修改对新增URL爬取请求的处理
- 编写pipelines
配置pipelines.py文件
定义对爬取项(Scraped Item)的处理类
配置ITEM_PIPELINES选项
- 使用crawl命令执行程序。
也可以进行优化
