import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.io as sio
from scipy.optimize import minimize
from sklearn.metrics import classification_report#这个包是评价报告
scipy中的loadmat官网地址:https://docs.scipy.org/doc/scipy/reference/generated/scipy.io.loadmat.html#scipy.io.loadmat
简单来说就是mat文件中的每一行是构成一个图片的像素强度矩阵,将每一行转化为20*20的矩阵既可以正确读取该图片。

path = 'E:\吴恩达\Machine_Learning_AndrewNg-master\Machine_Learning_AndrewNg-master\machine-learning-ex3\ex3data1.mat'
data = sio.loadmat(path)#loadmat返回的结果是一个字典,其中变量名字作为keys,内部矩阵作为对应的values
data.keys()#查看存储的变量
dict_keys(['__header__', '__version__', '__globals__', 'X', 'y'])
注意!!!
在这里应当注意:
- 本次计算使用的是array,并未使用矩阵计算,由于假设函数hypoth计算结果的shape为(n,),故(y_read).shape应为(n,)形式;若(y_read).shape为(n,1),当hypoth*y_read时,因y_read为二维数组,hypoth为一维数组,此时会触发数组的广播机制,使结果的shape变为(n,n)。
- 虽然两者的计算结果对该模型计算时的结果未产生影响(主要是由于costFunction中的np.mean()使得最终的结果一致,若改用np.sum()/len(y)来求均值就可以发现出错)但是在中间的一些过程产生了影响,可尝试输出costFunction的unreg_first和unreg_second的shape,可知差别。
计算时若有一维数组(n,)使用,则计算时统一使用一维数组,切勿一维数组和二维数组混用(n,m),使用np.dot()时除外,使用np.dot二维与一维数组得到的是标量,二维与二维是数组ndarray。
x_read = data['X']
y_read = data['y']
y_read = y_read.ravel()
x_read_insert = np.insert(x_read,0,1,axis=1)
#c,s=np.unique(b,return_index=True) 去除数组中的重复数字,并进行排序之后输出
#return_index=True,默认为False。True时表示返回新列表元素在旧列表中的位置,并以列表形式储存在s中
np.unique(y_read)#(查看标签)
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=uint8)
plt.imshow(x_read[-6,:].reshape(20,20),cmap='gray_r')#查看训练数据中的第0行的图形
lam =1
theta = np.zeros(x_read_insert.shape[1])
#假设函数
def hypoth(theta,x):
z = x.dot(theta)
return 1/(1+np.exp(-z))
hypoth(theta,x_read_insert)#尝试能否正常运行
array([0.5, 0.5, 0.5, ..., 0.5, 0.5, 0.5])
带有正则化的损失函数:
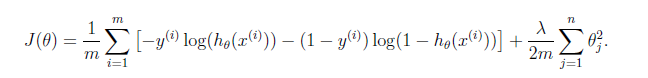
#带有正则化的损失函数,lam为λ:正则化系数
def costFunction(theta,x,y,lam):
#未正则化部分
unreg_first = (-y)*np.log(hypoth(theta,x))
unreg_second = (1-y)*np.log(1-hypoth(theta,x))
unreg = np.mean(unreg_first - unreg_second)
#正则化部分(对theta0不进行正则化)
reg = (lam/(2*x.shape[0])*np.sum(np.power(theta[1:],2)))
return unreg + reg
costFunction(theta,x_read_insert,y_read,lam)
-17.051420641776012
带有正则化的梯度函数:
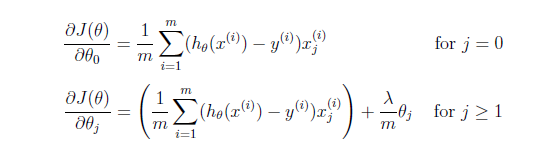
#带有正则化的梯度函数
def gdReg(theta,x,y,lam):
unreg = x.T.dot(hypoth(theta,x)-y)/x.shape[0]
theta_0 = theta
theta_0[0] = 0 #将theta0改为0,即对theta0不考虑正则化
reg = (lam/x.shape[0])*theta_0
return unreg + reg
def one_vs_all(x, y,lam):
y_read_label = np.unique(y)#去除重复数字,并排序
params = x.shape[1]#theta的维度(数量)
all_theta = np.zeros((len(y_read_label),params))#用来存储最终计算出来的theta值
for num in range(len(y_read_label)):#在标签中遍历
theta = np.zeros(params)
y_i = np.array([1 if label_hypo == y_read_label[num] else 0 for label_hypo in y])#若y中的值与标签相同,记作1,否则记作0。多类分类的思想!!将其中一个看作1,其余视为0。
fmin = minimize(fun=costFunction, x0=theta, args=(x, y_i, lam), method='TNC', jac=gdReg)
all_theta[num,:] = fmin.x#将计算出的theta储存到all_theta中
return all_theta
theta_all_final = one_vs_all(x_read_insert,y_read,lam)
def predict(theta,x):
hy = hypoth(theta,x)
p = np.argmax(hy,axis = 1) +1#argmax索引是从0开始的,而我们的是从1开始的
return p
y_predic= predict(theta_all_final.T,x_read_insert)
y_predic.shape
(5000,)
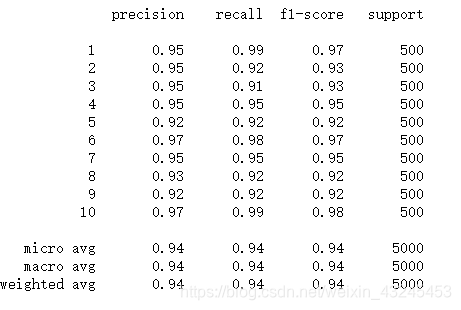
print(classification_report(y_read, y_predic))
尝试识别自己写的数字
from PIL import Image
mg1 =Image.open(r'E:\1.png')
def pre_own(theta,x):
hy = hypoth(theta,x)
p = np.argmax(hy)+1
return p
L = mg1.convert('L')#将图片转化为灰度
mg = np.array(L)
mg.shape
(20, 20)
plt.imshow(mg,cmap='gray_r')
own_mg = np.concatenate([np.array([1]),mg.ravel()])#在原数组前添加1
own_mg.shape
(401,)
num_own = pre_own(theta_all_final.T,own_mg)
E:\Users\in\Anaconda3\lib\site-packages\ipykernel_launcher.py:4: RuntimeWarning: overflow encountered in exp
after removing the cwd from sys.path.
num_own
4
虽然训练数据精确度挺高,但是我自己写的这么好为啥子都认不出来??????????