导读
本系列将持续更新50个matplotlib可视化示例,主要参考Selva Prabhakaran 在MachineLearning Plus上发布的博文:Python可视化50图 。
定义
关联图是查看两个事物之间关系 的图像,它能够展示出一个事物随着另一个事物是如何变化的。关联图的类型有:折线图,散点图,相关矩阵 等。
关联图
散点图
散点图
测试
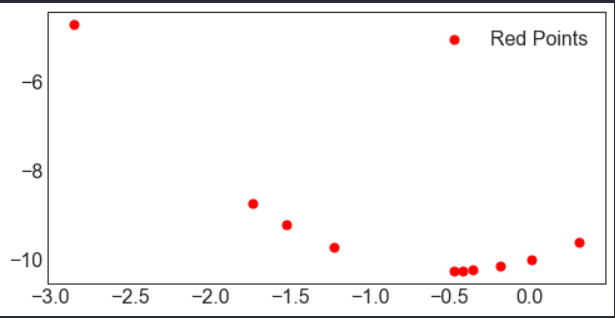
import numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as sns#绘制超简单的散点图:变量x1与x2的关系 #定义数据 10 ) #取随机数 2 - 10 #确定画布 - 当只有一个图的时候,不是必须存在 8 ,4 ))#绘图 #横坐标,纵坐标 50 #数据点的尺寸大小 "red" #数据点的颜色 "Red Points" #装饰图形 #显示图例 #让图形显示
result
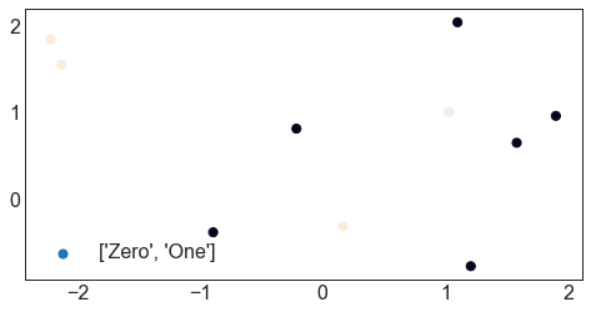
# 除了两列X之外,还有标签y的存在 # 在机器学习中,经常使用标签y作为颜色来观察两种类别的分布的需求 10 ,2 ) # 10行,2列的数据集 0 ,0 ,1 ,1 ,0 ,1 ,0 ,1 ,0 ,0 ])"red" ,"black" ] # 确立颜色列表 "Zero" ,"One" ] # 确立标签的类别列表 for i in range(X.shape[1 ]):0 ],1 ],# 在标签中存在几种类别,就需要循环几次,一次画一个颜色的点
result
实战
数据
# 导入数据 "https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv" )# 探索数据
标签
midwest['category' ]
category
# 提取标签中的类别 'category' ]) # 去掉所有重复的项 # 查看使用的标签,如下图
categories
颜色
用于创建颜色的十号光谱,在 matplotlib 中,有众多光谱供我们选择:https://matplotlib.org/stable/tutorials/colors/colormaps.html 。可以在plt.cm.tab10()中输入任意浮点数,来提取出一种颜色。光谱tab10中总共只有十种颜色,如果输入的浮点数比较接近,会返回类似的颜色。这种颜色会以元祖的形式返回,表示为四个浮点数组成的RGBA色彩空间或者三个浮点数组成的RGB色彩空间中的随机色彩。
color1 = plt.cm.tab10(5.2 )# 四个浮点数组成的一个颜色
color1
绘图
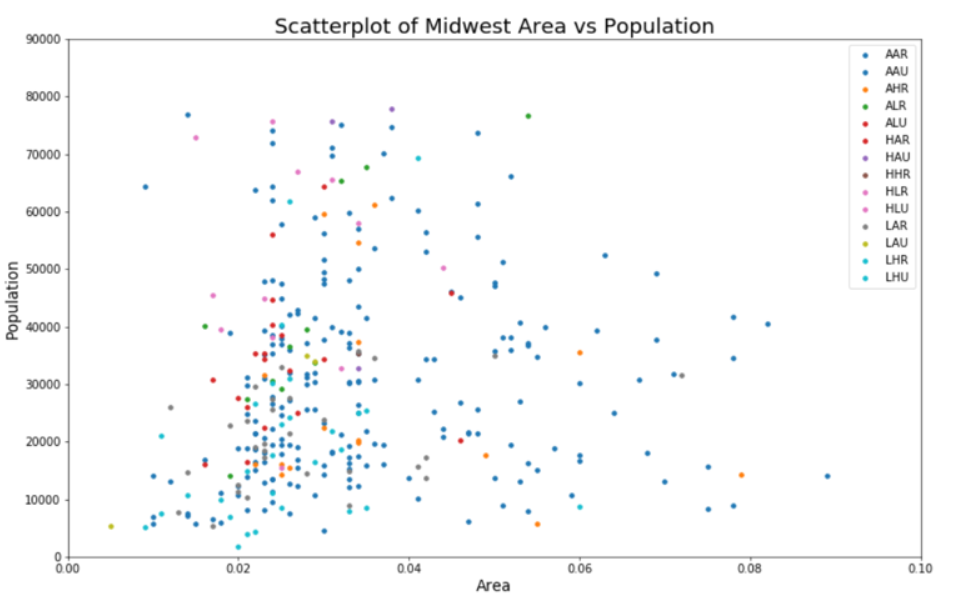
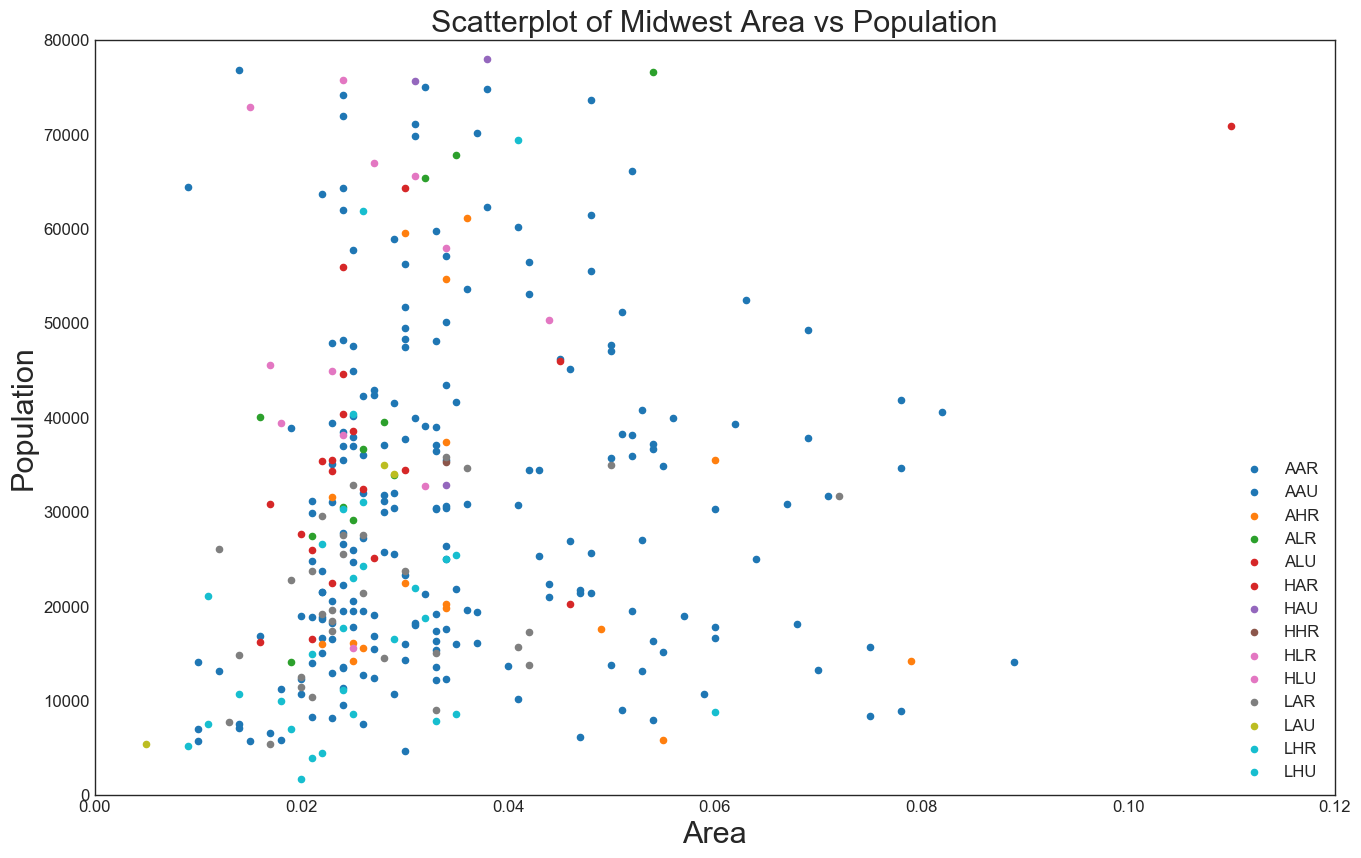
# 预设图像的各种属性 22 ; med = 16 ; small = 12 'axes.titlesize' : large, # 子图上的标题字体大小 'legend.fontsize' : med, # 图例的字体大小 'figure.figsize' : (16 , 10 ), # 图像的画布大小 'axes.labelsize' : med, # 标签的字体大小 'xtick.labelsize' : med, # x轴上的标尺的字体大小 'ytick.labelsize' : med, # y轴上的标尺的字体大小 'figure.titlesize' : large} # 整个画布的标题字体大小 # 设定各种各样的默认属性 'seaborn-whitegrid' ) # 设定整体风格 "white" ) # 设定整体背景风格 # 准备标签列表和颜色列表 'category' ])-1 )) for i in range(len(categories))]# 建立画布 16 , 10 ) # 绘图尺寸 100 # 图像分辨率 'w' # 图像的背景颜色,设置为白色,默认也是白色 'k' # 图像的边框颜色,设置为黑色,默认也是黑色 # 循环绘图 for i, category in enumerate(categories):'area' , 'poptotal' , 20 , c=np.array(colors[i]).reshape(1 ,-1 ), label=str(category))# 对图像进行装饰 # plt.gca() 获取当前的子图,如果当前没有任何子图的话,就创建一个新的子图 0 , 0.12 ), ylim=(0 , 80000 )) # 控制横纵坐标的范围 12 ) # 坐标轴上的标尺的字的大小 12 )'Population' ,fontsize=22 ) # 坐标轴上的标题和字体大小 'Area' ,fontsize=22 )"Scatterplot of Midwest Area vs Population" , fontsize=22 ) # 整个图像的标题和字体的大小 12 ) # 图例的字体大小
result
欢迎Star -> 学习目录 <- 点击跳转
国内链接 -> 学习目录 <- 点击跳转