目录
多表查询概述
一、多表关系
1.一对多(多对一)
2.多对多
3.一对一
二、多表查询概述
1.内连接
1.1、隐式连接
1.2、显示连接
2.外连接
1、左外连接
2、右外连接
3.自连接
4.联合查询
5.子查询
5.1、按照查询结果
5.1.1、标量子查询(通俗来说就像函数的返回值为一个结果值)
5.1.2、列子查询
5.1.3、行子查询
编辑
5.1.4、行子查询
5.1.5、表子查询
5.2、按照位置
5.2.1、where之后
5.2.2、from之后
5.2.3、select之后
总结
多表查询概述
在实际的项目开发中,在进行数据表结构设计的时候,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间很多都是相关联的,所以各个表结构之间也存在着一定的关系。
一、多表关系
1.一对多(多对一)
场景选择:每个公司都有很多不同的部门,他们之间各司其职,一个研发部门只管搞研发的工 作,每个部门有着多个员工,这就是典型的一对多的模型。
数据准备:
# 员工表和部门表
CREATE TABLE dept_test(
id INT COMMENT '部门编号',
name VARCHAR(20) UNIQUE COMMENT '部门名称'
);
INSERT INTO dept_test(id,name) VALUE (1,'研发部'),(2,'市场营销部'),(3,'测试部'),(4,'运维部'),(5,'人事部'),(6,'美工部');
CREATE TABLE emp_test(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
name VARCHAR(20) COMMENT '员工姓名',
age TINYINT COMMENT '员工年龄',
job VARCHAR(10) COMMENT '员工岗位',
dept_id INT COMMENT '员工所属部门'
);
INSERT INTO emp_test(id,name,age,job,dept_id) VALUES (1,'张三',21,'Java开发',1),
(2,'李四',25,'测试岗',3),
(3,'翠花',18,'测试岗',3),
(4,'麻子',20,'运维岗',4),
(5,'秦始皇',120,'嵌入式开发',1),
(6,'老子',18,'老总',5),
(7,'小妖怪',21,'PPT',6);
注意:一般情况下为了保证我们的数据的一致性和完整性,一般都需要添加外键约束

2.多对多
场景选择:最常见的就是学生与课程表之间的关系,每个学生都有着多门课程,每门课程又可以 供不同学生选择。
数据准备:
# 课程表与学生表
# 创建学生表
CREATE TABLE students (
student_id INT PRIMARY KEY COMMENT '主键',
student_name VARCHAR(50) COMMENT '学生姓名',
student_number char(3) UNIQUE NOT NULL COMMENT '学号'
);
INSERT INTO students(student_id, student_name, student_number) VALUES(1,'张三','201'),
(2,'李四','202'),
(3,'王五','203'),
(4,'翠花','204'),
(5,'小妖怪','205');
# 创建课程表
CREATE TABLE courses (
course_id INT PRIMARY KEY COMMENT '主键',
course_name VARCHAR(50) UNIQUE COMMENT '课程名称'
);
INSERT INTO courses(course_id, course_name) VALUES(1,'人工智能'),
(2,'java'),
(3,'php'),
(4,'spark'),
(5,'hadoop');
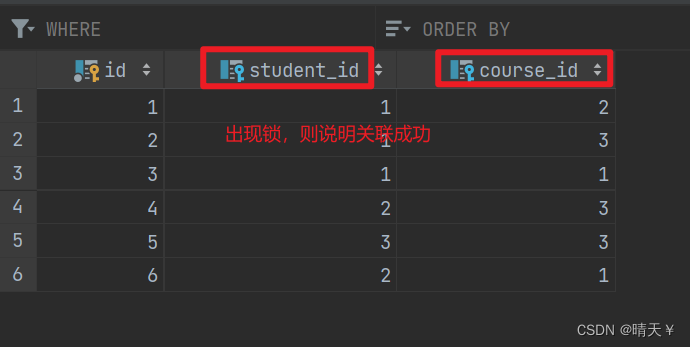
结果展示:

进行关联:
3.一对一
场景选择:多用于单表的拆分,将一张表的基础字段放在一张表中,其他的详情字段放在另一张 表中,从而提升效率,比如说:如果叫我们描述一个人,我们能从它的身体的基本信息来描述(身高,体重,姓名,年龄),也可以使用受教育信息(小学,中学,大学)等等。
数据准备:
# 一对一的操作
CREATE TABLE tb_user(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '姓名',
age INT COMMENT '年龄',
gender CHAR(1) COMMENT '1:男 0:女'
) COMMENT '用户基本信息';
CREATE TABLE tb_user_edu(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
degree VARCHAR(20) COMMENT '学历',
major VARCHAR(50) COMMENT '专业',
userid INT UNIQUE COMMENT '用户ID',
CONSTRAINT fk_user_id FOREIGN KEY (userid) REFERENCES tb_user(id)
)COMMENT '用户教育信息表';
二、多表查询概述
数据准备:
CREATE TABLE dept_query(
id INT PRIMARY KEY COMMENT '部门编号',
name VARCHAR(20) UNIQUE COMMENT '部门名称'
);
INSERT INTO dept_query(id,name) VALUE (1,'研发部'),(2,'市场营销部'),(3,'测试部'),(4,'运维部'),(5,'人事部'),(6,'美工部');
# 创建我们的员工表
create table if not exists emp_query(
id int auto_increment primary key comment '主键',
name varchar(50) not null comment '员工姓名',
age int comment '员工年龄',
job varchar(30) comment '员工的职位',
salary int default 2000 comment '员工薪资',
entry_date date comment '员工入职时间',
manage_id int comment '直属领导编号',
dept_id int comment '所属部门ID'
)comment '员工表';
insert into emp_query(id,name,age,job,salary,entry_date,manage_id,dept_id) values(1,'李星云',21,'开发',15000,'2012-8-12',2,1),
(2,'袁天罡',300,'老总',200000,'2000-2-10',null,5),
(3,'姬如雪',19,'测试',6000,'2019-5-12',8,3),
(4,'上官',25,'运维',8000,'2008-10-1',2,4),
(5,'张子凡',21,'开发',9000,'2018-8-29',10,1),
(6,'倾国倾城',28,'销售',3000,'2015-8-30',5,2),
(7,'温涛',31,'测试',5000,'2005-8-12',2,3),
(8,'女帝',29,'经理',18000,'2007-8-12',1,5),
(9,'李嗣源',41,'测试',12000,'2000-3-12',2,3),
(10,'李淳风',31,'人事顾问',15000,'2005-8-12',null,5);

笛卡尔积:集合A和集合B组合的所有情况,在多表查询时,就是为了消除多余的、无效的笛卡尔积

1.内连接
内连接相当于查询A、B两个集合之间的交集
1.1、隐式连接
语法:select 字段列表 from 表1,表2 where 条件;
1.2、显示连接
语法:select 字段列表 from 表1 [inner] join 表2 on 连接条件;
# 内连接:隐式连接和显式连接
SELECT * from emp_query,dept_query where emp_query.dept_id = dept_query.id;
# 显示连接
SELECT * FROM emp_query INNER JOIN dept_query ON emp_query.dept_id=dept_query.id;
# 起别名省略的写法
SELECT * FROM emp_query e JOIN dept_query d ON e.dept_id=d.id;
结果展示:三种写法都是一样的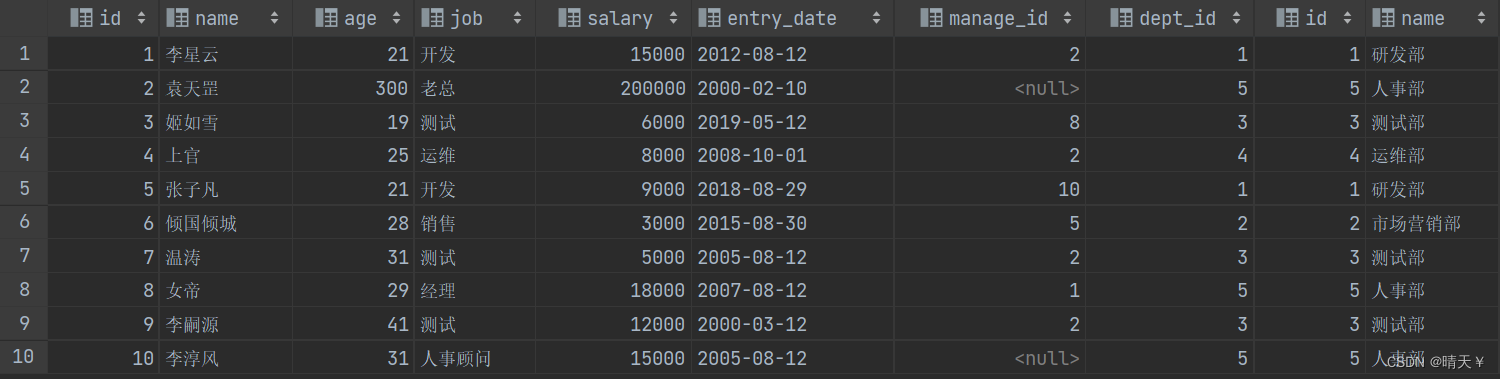
2.外连接
顾名思义就是左连接就是左表中的数据信息全部保留,且包含表1和表2交集部分,右连接相反,但其实左右连接可以相互转换,这不就是把表左右调换吗?
1、左外连接
语法:select 字段列表 from 表1 left [outer] join 表2 on 条件...;
2、右外连接
语法:select 字段列表 from 表1 right [outer] join 表2 on 条件...;
代码:
# 左右连接
SELECT * FROM emp_query e left join dept_query d on d.id = e.dept_id;
SELECT * FROM emp_query e right join dept_query d on d.id = e.dept_id;
左连接的效果
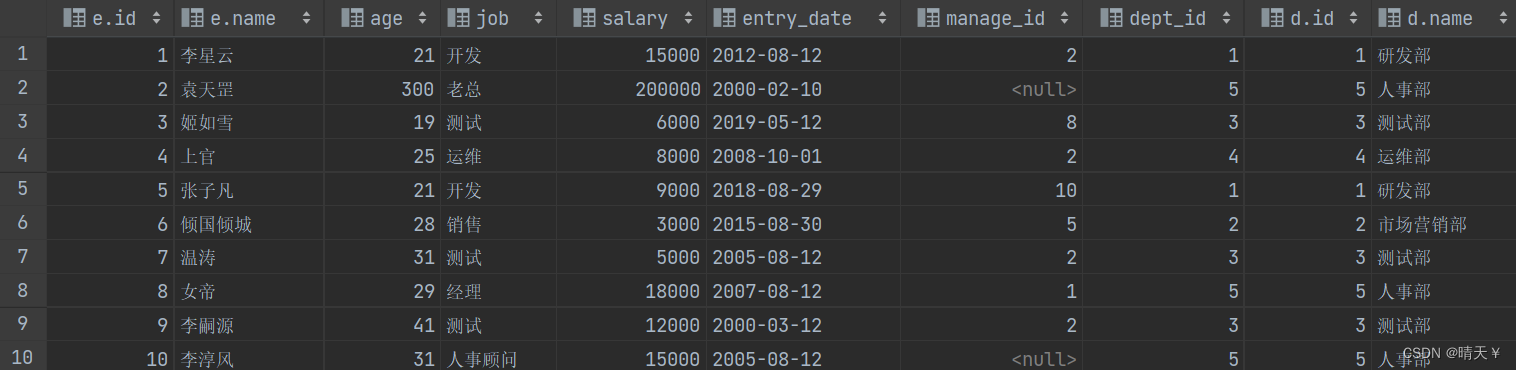
右连接的效果

3.自连接
子查询连接,是通过一张表查询出我们的关联信息,比如一张表中存在着一个领导层,通过一张表中的人物关系查询其上层领导。
语法:select 字段列表 from 表A 别名a 表B 别名b on 条件....;
注意:自查询可以是内连接查询,也可以是外连接查询,但是一定要起别名,一定要,否则你怎么辨认。
实例:查询人物层次的领导关系,比如李星云的上层领导是谁?
观察以下几个操作
SELECT temp1.name '员工' FROM emp_query temp1 JOIN emp_query temp2 ON temp2.manage_id=temp1.id;

SELECT temp2.name '员工' FROM emp_query temp1 JOIN emp_query temp2 ON temp2.manage_id=temp1.id;

SELECT temp1.name '员工',temp2.name '领导' FROM emp_query temp1 JOIN emp_query temp2 ON temp2.manage_id=temp1.id;

可以查看出我们的的执行是先从join后边的表找出对应的关系,采用从后往前推的思想。
SELECT temp2.name '员工',temp1.name '领导' FROM emp_query temp1 JOIN emp_query temp2 ON temp2.manage_id=temp1.id;
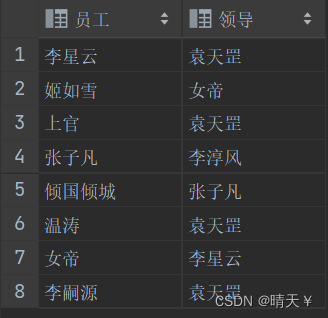
4.联合查询
关键字:
union all:啥也不管,直接合并
union : 去重
联合查询也就是把两张表的查询结果拼接起来,需求:将公司人员大于35的的员工和薪资低于8000的员工查询出来
# 联合查询:也就是将查询结果拼接在一起(union union all)
SELECT * FROM emp_query WHERE age > 30
UNION ALL
SELECT * FROM emp_query WHERE salary < 12000;
使用union all来用
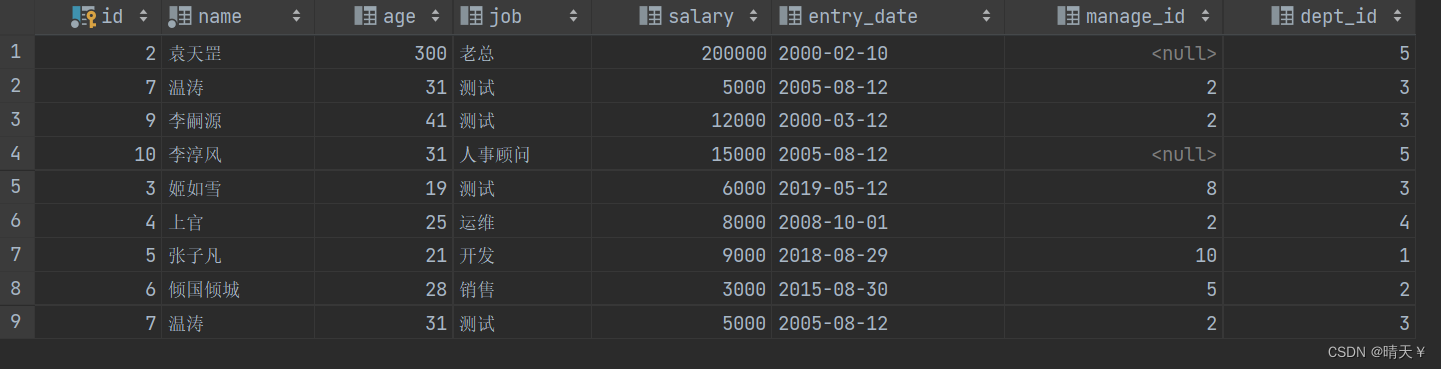
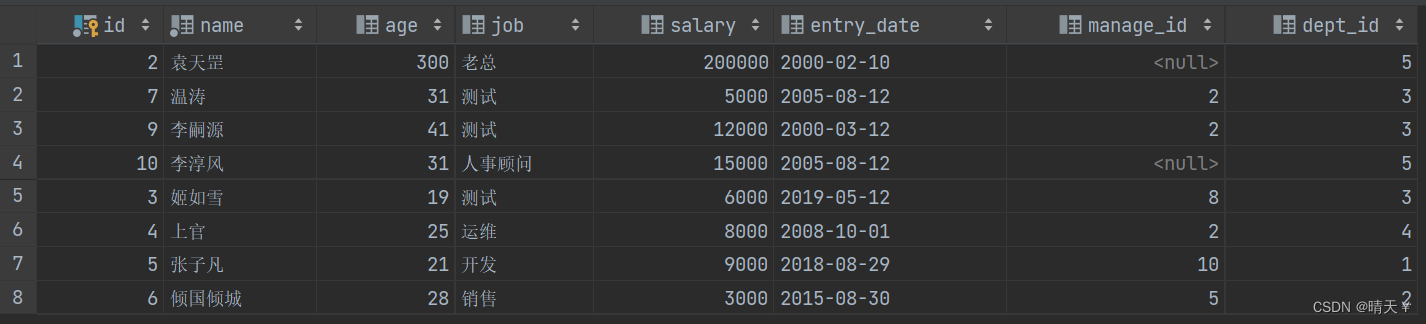
使用union,很显然name没有重复的了
SELECT * FROM emp_query WHERE age > 30
UNION
SELECT * FROM emp_query WHERE salary < 12000;
5.子查询
5.1、按照查询结果
5.1.1、标量子查询(通俗来说就像函数的返回值为一个结果值)
子查询结果为单个值(数字、字符串、日期),最简单的形式,常用到的操作符:= <> > >= < <=
| 在MySQL中,<> 运算符用于比较两个值是否不相等。它返回一个布尔值,如果两个值不相等,则返回 TRUE;如果两个值相等,则返回 FALSE。 例如,以下示例中的查询将返回 "True",因为 10 不等于 5: ```sql
SELECT 10 <> 5;
``` 另一个示例中的查询将返回 "False",因为 2 等于 2: ```sql
SELECT 2 <> 2;
``` 因此,<> 运算符通常用于比较两个值是否不相等,并在条件表达式中使用。 |
# 查询开发部门所有员工的所有信息
/* 子查询:标量子查询
1、查询研发部门中所有员工的所有信息
*/
# a.获取部门编号:
SELECT id FROM dept_query WHERE name = '研发部';
# b.查询部门为研发部(编号为1)的所有员工信息
SELECT * FROM emp_query WHERE dept_id = 1;
# 合并
SELECT * FROM emp_query WHERE dept_id = (SELECT id FROM dept_query where name = '研发部');
结果展示:

5.1.2、列子查询
子查询的结果返回是一列(可以是多行),常用到的操作符:IN,NOT IN,ANY,SOME,ALL
| 操作符 |
描述 |
| IN |
在指定的综合范围内多选一 |
| NOT IN |
不在指定的范围 |
| ANY |
子查询返回列表中,有任一一个满足即可 |
| SOME |
与ANY等同,使用SOME的地方都能使用到ANY |
| ALL |
子查询返回列表的所有值都必须要满足 |
5.1.3、行子查询
子查询返回的结果是一行(可以是多列),常用的操作符:= <> IN NOT IN
# 1、查询“研发部”和“市场营销部”的所有员工信息
# 列查询(子查询返回的结果是一个列值)
# a.获取“研发部”和“市场营销部”的编号
SELECT id FROM dept_query WHERE name IN('研发部','市场营销部');
# b.查询研发部门和市场营销部门的所有员工信息
SELECT * FROM emp_query WHERE dept_id IN (1,2);
# 合并
SELECT * FROM emp_query WHERE dept_id IN (SELECT id FROM dept_query WHERE name IN('研发部','市场营销部'));
查询结果:

# 2、查询比研发部任意一名员工工资都高的所有员工信息,即满足一个即可
# 3、查询比“研发部”其中任何人工资都高的所有员工信息
SELECT * FROM emp_query WHERE salary > ALL(SELECT salary FROM emp_query WHERE dept_id = (SELECT id FROM dept_query WHERE name = '研发部'));
# a.获取研发部工资的列信息
SELECT salary FROM emp_query WHERE dept_id = (SELECT id FROM dept_query WHERE name = '研发部');
结果:
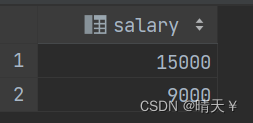
# b.获取比研发部任意一名员工工资都高的所有员工信息
SELECT * FROM emp_query WHERE salary > ANY(SELECT salary FROM emp_query WHERE dept_id = (SELECT id FROM dept_query WHERE name = '研发部'));
# SOME 和 ANY的效果相同
SELECT * FROM emp_query WHERE salary > SOME(SELECT salary FROM emp_query WHERE dept_id = (SELECT id FROM dept_query WHERE name = '研发部'));
结果:

# 3、查询比“研发部”其中任意一个人工资都高的所有员工信息
# 3、查询比“研发部”其中任何人工资都高的所有员工信息
SELECT * FROM emp_query WHERE salary > ALL(SELECT salary FROM emp_query WHERE dept_id = (SELECT id FROM dept_query WHERE name = '研发部'));
结果:

5.1.4、行子查询
子查询的结果是一行(可以是多列),这种查询称为行子查询,常用的操作符:= <> IN NOT IN
# 查询与“李星云”薪资及直属领导相同的员工信息
-- 行子查询:子查询的返回结果为一行(可以是多列)
-- 查询与“李星云”薪资及直属领导相同的员工信息
-- a.查询李星云的薪资和直属领导的编号
SELECT salary,manage_id FROM emp_query WHERE name = '李星云';
-- b.查询所有人薪资为15000,领导编号为2的员工信息
SELECT * FROM emp_query WHERE (salary,manage_id) = (15000,2);
-- 合并
SELECT * FROM emp_query WHERE (salary,manage_id) = (SELECT salary,manage_id FROM emp_query WHERE name = '李星云');
结果:

5.1.5、表子查询
子查询返回的结果是多行多列,常用操作符:IN
# 查询入职时间是2008-3-13后的所有员工信息及其部门的信息
-- 表子查询
-- 查询入职时间是2008-3-13后的所有员工信息及其部门的信息
-- a.查询入职时间在2008-3-13后的所有员工信息
SELECT * FROM emp_query WHERE entry_date > '2015-3-13';
-- 查询这部分员工对应的部门信息
SELECT * FROM (SELECT * FROM emp_query WHERE entry_date > '2015-3-13') tmp LEFT JOIN dept_query ON tmp.dept_id = dept_query.id;
结果:

5.2、按照位置
5.2.1、where之后
5.2.2、from之后
5.2.3、select之后
注:以上的实例中都有体现
总结
本次记录的是MySQL表之间的关系,以及查询方式的详解,下期讲的则是一些相关的练习题。