CV计算机视觉核心03-初步认识机器学习(线性回归模型、梯度下降法、区分一下回归模型和分类模型、线性回归模型解决数字识别问题(没有使用auto grad)、逻辑回归模型(sigmoid函数)、如何使用自动梯度计算、auto grad使用的注意事项、作业:线性回归模型解决数字图像分类问题(使用auto grad))
本节内容:
一、第一个可训练的模型,线性回归模型。
二、线性回归模型解决数字识别问题。
三、逻辑回归模型。
基本概念监督学习、非监督学习、模型参数
如何用经验来学习解决问题?
两种思路:
1、监督学习:凡是需要标注数据的方法。(分类、分割…)
2、非监督学习(是未来):凡是不需要人工标注数据的学习方法。(数据量太大,人工无法完成标注,用一定规则作为“监督”,不需要人打标签。)
模型参数:指的是完成该模型所必须要的已知量。
计算机视觉问题:
image => get feature(各种特征:Hog、LBP、直方图,投影特征等) => model判断(欧式距离、直接做差、线性回归模型) => 结果。
以案例来引出我们需要完成的内容:
我们还是以10张图片识别问题,特征投影特征,V[ v1,v2,v3,…,v6]的6维向量。我们用以下方程式来判别类别:
y = W * V = w1v1 + w2v2 + w3v3 + … + w6v6
此时:若要y输出正确的类别,需要求出特征的W权值。
该如何求解W呢?
一共有4种方法(列方程组(消元法)、最小二乘法(最小平方函数)、极大似然估计、算法法(只有前面几种方法实在不能使用的时候使用算法法,因此算法法是最终的方法,前几种方法是可以求得确切的结果的。)),我们先来看最直观的一种:列方程组。
列方程组:
这里V特征是可以提前获得的,比如投影特征。
下图的方程是一个6元1次方程组,可以使用消元法求解。
w1v11 + w2v12 + w3v13 + … + w6v16 = y0预测值 = 我们希望是0(理想值)
…
…
w1v101 + w2v102 + w3v103 + … + w6v106 = y9预测值 = 我们希望是9(理想值)

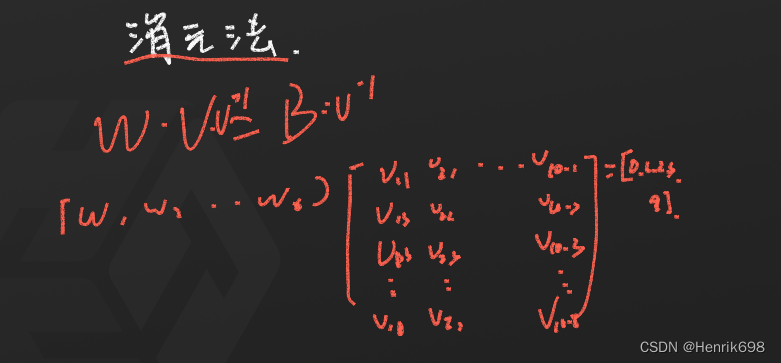
这里会存在一个问题,我们有多少个样本,就需要列出多少个方程,因此这种手动求解的方式不太适用。
最小二乘法
怎么办呢?
这里我们构造一个二次函数,然后求这个函数的最小值,二次函数总会有一个最小值的。

求这个最小值,跟我们解上面的那多个方程有什么关系呢?
我们的目标是让y的输出和v特征对应起来,即y要符合我们的理想值。
因此y预测值减去y理想值(下图的方差),这样会形成一个2次函数。
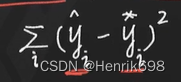
这个二次函数总会有一个最小值。求到了最小值,那么就是说明求到了最近似的值。如果最小值求出来是0(理想状态下求出来应该是0),则y预测值就是y理想值。因此我们可以求出理想状态下对应的W。因此我们只需求导数即可。
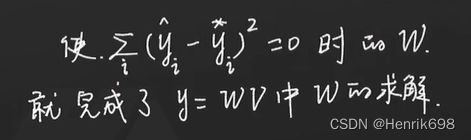
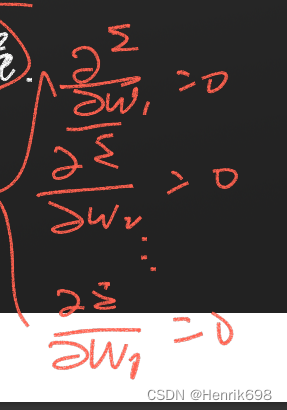
我们可以注意到下面的公式,每一项都是大于等于0的,那我们如何求最小值呢?
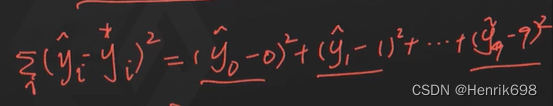
通过对W求偏导数,让这个偏导数 = 0,解出这个偏导值。

有几个wj就是几个方程,把1000,10000个方程组,转成了6个方程(不管样本是10000又或是1000000也好,我就将原来的消元法的10000个方程,转化为6个方程了),我们只需解决这6个方程即可,因为有6个特征V对应6个权值W,对权值求导,有6个权值,就求6个方程即可。


上面这种方法就是最小二乘法(也就是最小平方函数)。
极大似然估计法MLE(Maximum Likelihood Estimate)
估计出当前事件发生概率最大时,对应的概率密度函数中的参数是多少?概率密度函数中的参数是与我们模型中的参数是一致的。
当前事件指的是:y预测值与理想值y之间误差为0的时候。通常我们希望误差符合一个正太分布(均值为0,方差为σ)。正太分布的方程怎么写,正太分布的概率密度函数P如何写?
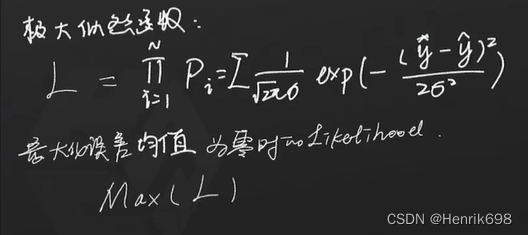
什么时候正太分布方程取到最大值呢?就是上图中的y预测值减y真实值为0的时候,L正太分布方程可以取到最大值。
对L概率密度函数取log:
也就是log(a*b) = loga + logb

我们要求的是Max(logL),即最大值logL,按照上图的公式,如果要求logL最大值,那么就需要下图红括号那部分求最小值,因为后半部分是二次函数,肯定有最小值。因为前半部分是单调递增的,因此只有减后半部为最小值,这个logL才能取到最大值。

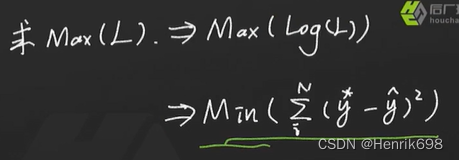
极大似然估计有几个参数就有几个方程。有六个参数(特征)就有六个方程,因为求导是针对特征的权值w。
上面提到的极大似然估计MLE、最小二乘法和消元法都需要求解方程组,那么有没有不需要求解方程组的方法呢?
答:有,算法求解w。
但是在工业界,尽量能用上面的三种方法就用这三种,因为这三种方法是可以求得解析解(即确切的值),解析解永远是最准确的。只有样本量过多,特征过多的时候,实在不得已用算法的方法。因此算法方法就是终极方法。
一、第一个可训练的模型,线性回归模型。
算法求解W,线性回归模型
线性模型指的是y = w * v^T,其中y与v特征向量存在线性关系。
回归的过程:此外通过给定参数,求解方程的过程就是回归的过程,最终这些参数点都会回归到这个方程上,这个方程是一个连续的方程,这种回归模型多用于预测。
步骤:
1、先令w = w0
2、把w0带入到model输出,即y0 = model(w0,v) = w0 * v
3、观察模型输出与期望值差,即设立一个Loss函数,这里希望模型参数的更新,这个差值越来越小,这样我们的更新w才有意义。
4、如果输出值与期望值相同,求解完成。
5、如果不同,以一定规则R更新w,w1 = R(w0) = w0 - σL/σw0 *lr。
6、把w1带入model,得到模型输出。
7、转到第3步。

上面的步骤有两个关键:
1、如何观察输出与期望差?定义目标函数(损失函数)Loss Function:(y预测-y真实)^2 。
2、更新w的规则如何定义?梯度下降。
为什么梯度下降能使得Loss减小?
梯度下降法:
梯度定义:
因变量随着自变量变化的速度,y随x的变化的速度。
自变量朝着负梯度方向改变的时候,y值会减小,x会朝着-dy/dx反方向减小。

梯度计算:
y = f(x)
y0 = f(x0)
当:x1 = x0 + △x
y1 = y0 + g * △x 其中g为梯度。
要使y1 < y0,即函数值y下降,梯度下降。
则 g △x < 0
则 △x = -g *a (a>0,a就是lr学习率)。
此时,g △x = g (-g *a) = -ag^2 < 0
结论,若要使y的值减小(下降),只需要让x朝着-g的方向变化。
即:x1 = x0 - g *a


则算法中的更新公式可以写为:

例子:
先是解析方法:
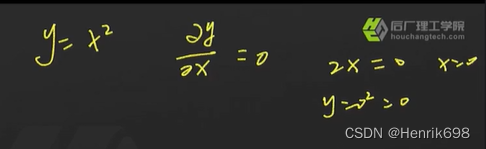
算法:
lr学习率为0.1。
先令x0 = 5,则y0 = 25
x1 = 4,则y1 = 16
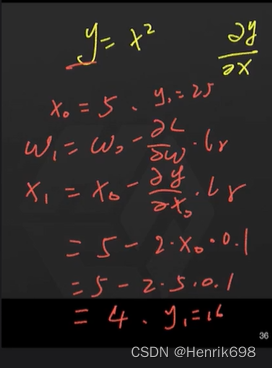
x2 = 3.2,则y2 = 10.24
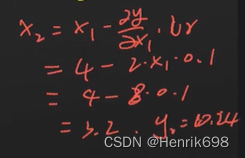
x3 …
x4
…
发现y最后不在下降了,就开始震荡了。
该模型总结:
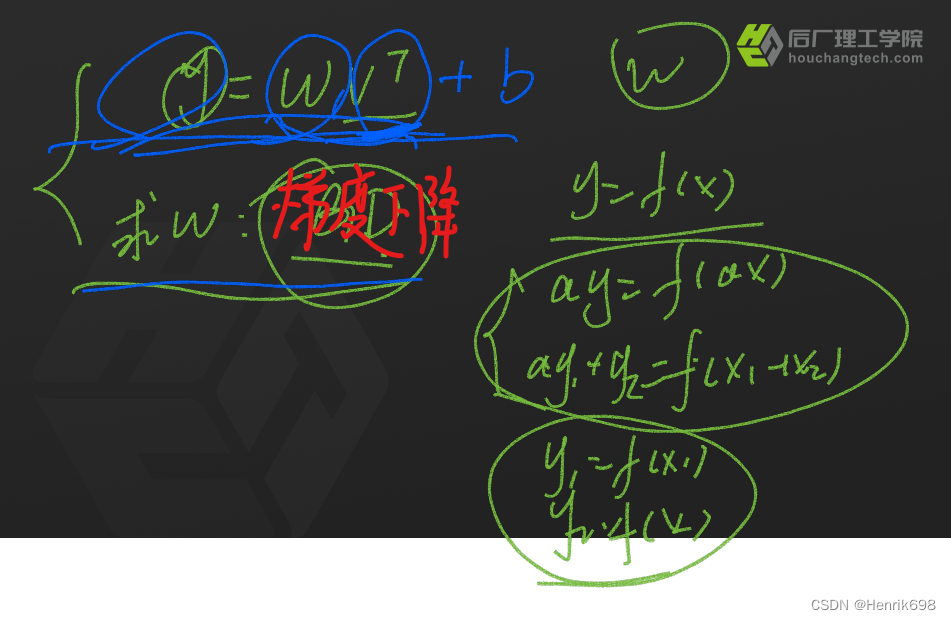
这里需要区分一下回归模型和分类模型:
回归模型:
通过给定参数,求解方程的过程就是回归的过程,最终这些参数点都会回归到这个方程上,这个方程是一个连续的方程,这种回归模型多用于预测。

分类模型:
线性回归做分类:将回归求解的方程,按照不同区间进行分段,不同区间为不同类型。
二、线性回归模型解决数字识别问题(没有使用auto grad)。
这里基本是原始的写法进行编写代码:
#coding:utf-8
# code for week2,recognize_computer_vision.py
# houchangligong,zhaomingming,20200520,
import torch
from itertools import product
def generate_data():
# 本函数生成0-9,10个数字的图片矩阵
image_data=[]
num_0 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,1,0,0,1,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_0)
num_1 = torch.tensor(
[[0,0,0,1,0,0],
[0,0,1,1,0,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,1,1,1,0],
[0,0,0,0,0,0]])
image_data.append(num_1)
num_2 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,0,1,0,0],
[0,0,1,0,0,0],
[0,1,1,1,1,0],
[0,0,0,0,0,0]])
image_data.append(num_2)
num_3 = torch.tensor(
[[0,0,1,1,0,0],
[0,0,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_3)
num_4 = torch.tensor(
[
[0,0,0,0,1,0],
[0,0,0,1,1,0],
[0,0,1,0,1,0],
[0,1,1,1,1,1],
[0,0,0,0,1,0],
[0,0,0,0,0,0]])
image_data.append(num_4)
num_5 = torch.tensor(
[
[0,1,1,1,0,0],
[0,1,0,0,0,0],
[0,1,1,1,0,0],
[0,0,0,0,1,0],
[0,1,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_5)
num_6 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,0,0],
[0,1,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_6)
num_7 = torch.tensor(
[
[0,1,1,1,1,0],
[0,0,0,0,1,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,0,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_7)
num_8 = torch.tensor(
[[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,1,0,0,1,0],
[0,0,1,1,0,0],
[0,0,0,0,0,0]])
image_data.append(num_8)
num_9 = torch.tensor(
[[0,0,1,1,1,0],
[0,1,0,0,1,0],
[0,0,1,1,1,0],
[0,1,0,0,1,0],
[0,0,0,0,1,0],
[0,0,0,0,0,0]])
image_data.append(num_9)
image_label=[0,1,2,3,4,5,6,7,8,9]
return image_data,image_label
def get_feature(x):
feature = [0,0,0,0]
# 下面添加提取图像x的特征feature的函数代码,这里只是定义函数:
def get_shadow(x,dim):
feature =torch.sum(x,dim)
feature = feature.float()
# 归一化,使得区间在0-1之间
for i in range(0,feature.shape[0]):
feature[i]=feature[i]/sum(feature)
#将feature结构调整为[1,6]
feature = feature.view(1,6)
return feature
#这里dim=0,是垂直投影:
feature = get_shadow(x,0)
# import pdb
# pdb.set_trace()
# print(feature)
return feature
#model函数:需要传入参数feature和weights
def model(feature,weights):
y=-1
# 下面添加对feature进行决策的代码,判定出feature 属于[0,1,2,3,...9]哪个类别
#import pdb
#pdb.set_trace()
# feature是[1,6]的,因此需要在feature末尾增加一个tensor[1,1],使得其达到[7,7]
# 通过[1,6]和[1,1]的进行拼接处理,使得达到[1,7]
# 其中最后一个是bias偏置的意思
feature = torch.cat((feature,torch.tensor(1.0).view(1,1)),1)
#.mm表示的是矩阵的乘法:feature[1,7]乘以weights[7,1],就得到y[1,1]
# y = w1*x1 + w2*x2 + w3*x3 + w4*x4 + w5*x5 + w6*x6 + w7
# y = W * X + b
y = feature.mm(weights)
return y
def train_model(image_data,image_label,weights):
for epoch in range(0,3000):
loss = 0
#for i in range(0,len(image_data)):
for i in range(0,5):
#print(image_label[i])
#y = model(get_feature(image_data[i]),weights)
feature = get_feature(image_data[i])
y = model(feature,weights)
# 定义loss
# 观察模型输出y 与 期望值image_label的差距
# mse:
loss += 0.5*(y.item()-image_label[i])**2
#print("loss=%s"%(loss))
#weights =
# 更新公式
# w = w - (y-y1)*x*lr
# w1 = w1 - (y^ - y*)*x1*lr
# w2 = w2 - (y^ - y*)*x2*lr
#...
feature=feature.view(6)
# 这里表示负梯度
lr = 0.05
#w为[7,1]
#w1:
weights[0,0] = weights[0,0]- (y.item()-image_label[i])*feature[0]*lr
weights[1,0] = weights[1,0]- (y.item()-image_label[i])*feature[1]*lr
weights[2,0] = weights[2,0]- (y.item()-image_label[i])*feature[2]*lr
weights[3,0] = weights[3,0]- (y.item()-image_label[i])*feature[3]*lr
weights[4,0] = weights[4,0]- (y.item()-image_label[i])*feature[4]*lr
weights[5,0] = weights[5,0]- (y.item()-image_label[i])*feature[5]*lr
#w7:这里w7前没有x项,w7是偏置项
weights[6,0] = weights[6,0]- (y.item()-image_label[i])*lr
# import pdb
# pdb.set_trace()
#epoch表示训练一代,一代是训练了5个数据集:
print("epoch=%s,loss=%s,weights=%s"%(epoch,loss,weights.view(7)))
loss=0
#import pdb
#pdb.set_trace()
return weights
if __name__=="__main__":
# generate w_0
# 随机生成7个w,结构是[7,1]
weights = torch.rand(7,1)
# 这个是用于打断点:
# import pdb
# pdb.set_trace()
#调用generate_data()生成数据集和标签:
image_data,image_label = generate_data()
# 打印出0的图像
print("数字0对应的图片是:")
print(image_data[0])
print("-"*20)
# 打印出8的图像
print("数字8对应的图片是:")
print(image_data[8])
print("-"*20)
# 对模型进行训练:
weights=train_model(image_data,image_label,weights)
#训练后获得weight,对每张图片进行识别
print("对每张图片进行识别")
for i in range(0,5):
#获得5张图片
x=image_data[i]
#import pdb
#pdb.set_trace()
#对当前图片提取特征
feature=get_feature(x)
# 对提取到得特征进行分类,使用训练好的权值。
y = model(feature,weights)
#打印出分类结果
print("图像[%s]得分类结果是:[%s],它得特征是[%s]"%(i,y,feature))

三、逻辑回归模型(sigmoid函数)。
如何学习一个新模型:(三方面)
1、先看使用模型的方法:模型公式。y=wx+b。
2、再看模型的参数。w,b,要对模型中的x进行回归,预测y,就必须依赖w和b。
3、看模型求解方法。梯度下降。
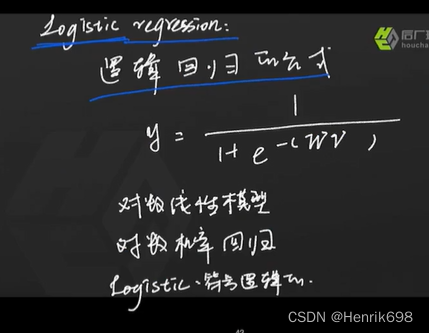
Logistic regression:
1、先看使用模型的方法:模型公式。
下图中逻辑回归公式中的 wv = wx+b。
逻辑回归公式中就包含一个线性模型。
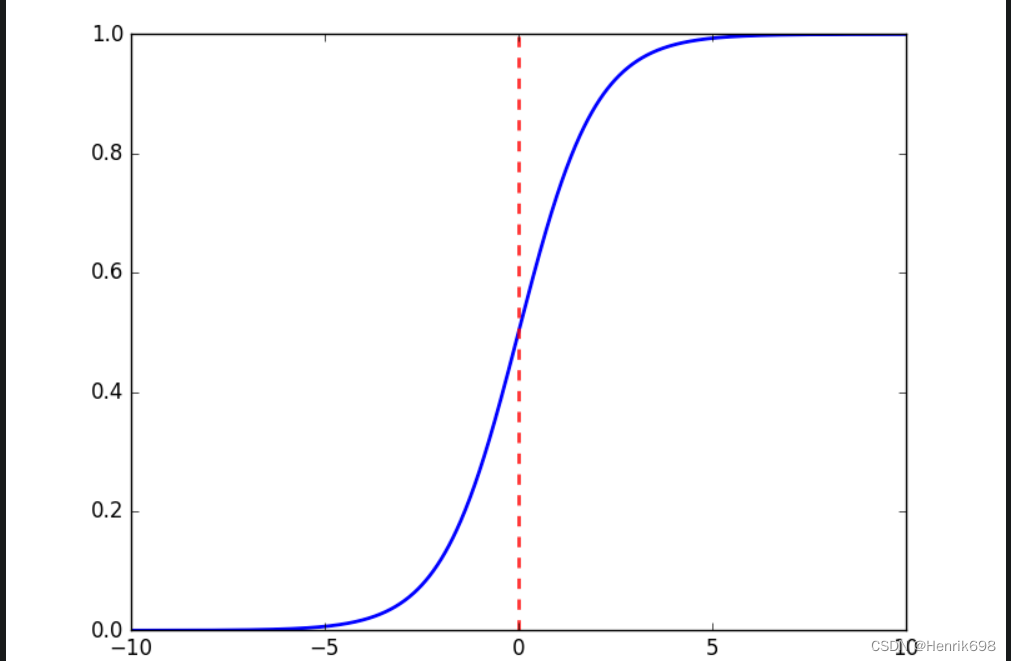
其中就是1/(1+e^-x) = sigmoid函数,将x替换成wx+b,就成为了逻辑回归公式了。
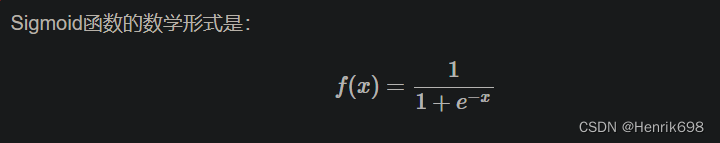
2、再看模型的参数。
逻辑回归模型有哪些参数呢?
其参数与线性回归模型参数是一样的。
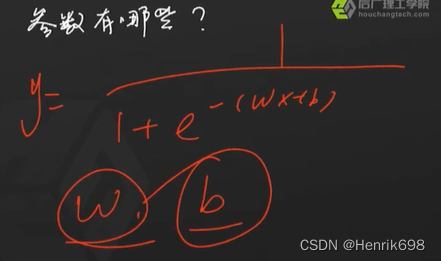
3、看模型求解方法。
(1)定义Loss Function。
交叉熵 p(1-p),p代表的就是输出y。
(2)算法思维更新参数。
how to use auto grad如何使用自动梯度计算
案例:
#coding:utf-8
import torch
# 当x 是一个维度的时候
print("%s%s"%("-"*20,"当x是1x1的时候"))
x = torch.ones(1,1,requires_grad = True)
y = (x+2)*(x+2)*3
y.backward()
print('x.grad:',x.grad)
print("%s%s"%("-"*20,"当x是1x2的时候"))
x = torch.ones(1,2,requires_grad = True)
y = (x+2)*(x+2)*3
z = y.sum()
z.backward()
print('x.grad:',x.grad)
import pdb
# continue c 继续执行程序,直到下一个断点或调用点
# next n 执行下一行
# 回车 重复上一条命令
pdb.set_trace()
# 如何把autograd用到我们线性模型中
x = torch.rand(10,1)
print("%s%s"%("-"*20,"把autograd用到我们线性模型中"))
w = torch.ones(1,10,requires_grad = True)
w_init= w.data
label=100
for i in range(1,50):
y = (w.mm(x))**2
loss = (y-label)*(y-label)
loss.backward()
#w.data = w.data - w.grad.data*0.1
#print("loss=%s,w.requires_grad:[%s],w=[%s]"%(loss.data,w.requires_grad,w.grad))
print("y=%s,loss=%s"%(y,loss.data))
# 梯度更新写法一,use tensor.data
#w.data = w.data - w.grad.data*0.1
#w.grad.data = torch.zeros(1,10)
# 梯度更新写法二,use torch.no_grad()
with torch.no_grad():
w -= w.grad*0.0001
print('w:',w)
w.grad.zero_()
#pdb.set_trace()
#w.data = w.data - w.grad.data*0.1
#w.grad.data = torch.zeros(1,10)
print("*"*20)
print("model:y= wx")
print("w_init =%s"%(w_init))
print("y_init =%s"%(w_init.mm(x)))
print("y的目标值是%s"%(label))
print("经过梯度下降算法训练后:")
print("w=%s"%(w.data))
print("y=wx=%s"%(y.data))
auto grad使用的注意事项
import torch
a = torch.tensor(2.0,requires_grad=True)
b = a.exp() #b = e^2
b.backward()
print('b:',b)
print(b.is_leaf)
# 叶子节点,是需要将导数保存下来的。梯度计算过程中的继承图将梯度保存在a.grad中。
print('a:',a)
print(a.is_leaf)
print('a.grad:',a.grad) #这里y=e^x的导数y′=e^x
input = torch.ones([3,3],requires_grad=False)
w1 = torch.tensor(2.0,requires_grad = True)
w2 = torch.tensor(3.0,requires_grad = False)
w3 = torch.tensor(3.0,requires_grad = True)
l1 = input * w1
l2 = l1+w2
l3 = l1*w3
l4 = l2*l3
#w为了求出loss,l4矩阵求一个均值,获得一个数值
loss = l4.mean()
print(w1)
#发现.data后打印,是不带requires_grad=True
print(w1.data)
#这里是只取数据。这样好处是只对数据做操作,对继承图中的requires_grad不受影响。

print(w1.data,w1.grad,w1.grad_fn)

print(l1.data)
print(l1.is_leaf)
print(l2.is_leaf)
print(w1.is_leaf)
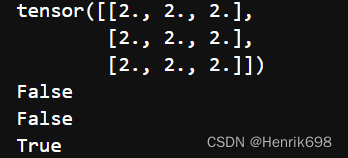
print(l1.grad)

print(l1.grad_fn)
#这的grad_fn中的fn表示function的意思。
#l1 = input * w1
#因此下面打印出来的是MulBackward0...
#可以看到是乘法。

#是一个MeanBackward,继承图都有记录。
print(loss)

print(loss.data,loss.grad,loss.grad_fn)

loss.backward()
#这里w2.grad之所以为none,是因为我们设置了requires_grad = False
print(w1.grad,w2.grad,w3.grad)

使用auto grad注意事项:
1、叶子张量 leaf tensor:反向传播时,只保留属性requires_grad和is_leaf为真的张量得导数。
2、requires_grad为真,is_leaf为假时,此张量得导数作为中间结果用于计算叶子张量得导师。
3、requires_grad is False,is_leaf is False,次张量参与导数计算
a = torch.ones([2,2],requires_grad=True)
print(a.is_leaf)

b = a+2
print(b.is_leaf)

4、因为b不是用户创建的,是通过计算生成的
5、叶子张量的作用:节省内存或者显存
6、叶子节点的grad_fn都为空
7、非叶子节点点grad_fn都不为空
8、果我们想保留中间变量的导数,该怎么操作?
8.0.1、通过使用tensor.retain_grad()
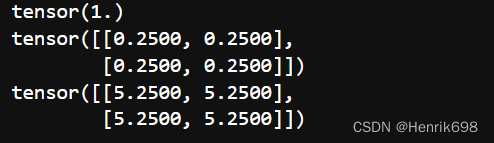
loss = l4.mean()
#设置一下,保存一下中间节点的梯度信息
l1.retain_grad()
l4.retain_grad()
loss.retain_grad()
#这里还需注意的是继承图建立好后只能backward()一次,不能backward两次。
loss.backward()
print(loss.grad)
print(l4.grad)
print(l1.grad)
9、如果我们只想进行debug,只需要输出中间变量的导数信息,而不需要保存他们,我们还可以使用tensor.register_hook,如下
loss2 = l4.mean()
l1.register_hook(lambda grad:print("l1 grad:",grad))
l4.register_hook(lambda grad:print("l4 grad",grad))
loss2.register_hook(lambda grad:print("loss grad:",grad))
#在backward的过程中,就通过register_hook,获取到梯度,我们通过lambda表达式直接打印出来梯度信息。
loss2.backward()
#这我们在打印一下loss2.grad,发现这里又是none,register_hook是不保存梯度信息的,只是在backward过程中获得到这个梯度信息而已,结束backward,梯度信息也就释放掉了。
print(loss2.grad)
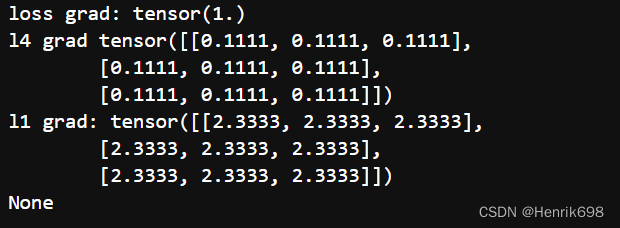
10、可以看到,是先打印loss的grade,后打印l4,l1的grade。
11、并且在最后print(loss2.grad)得时候打印出了none
12、这说明loss.grad在print完之后,就被清除掉了
13、pytorch 中,Hook的作用非常大
14、inplace 操作:inplace operation
15、在不更改变量的内存地址的情况下,直接修改变量的值。就叫inplace操作
a = torch.tensor([3.0,1.0])
print(id(a))
#这里需要注意的是在继承图中是不允许这样赋值的。
#exp是高等数学里以自然常数e为底的指数函数
a = a.exp() # 不是inplace,可以通过id查看是否内存地址一致。
print(id(a))
b=[1,2]
print(id(b))
b[0]=10# 是inplace
print(id(b))

16、以上id有变化的不属于inplace操作,id没有变化的,才是inplace操作
17、pytorch 怎么监测tensor发生了inplace操作?通过tensor._version
a = torch.tensor([1.0,3.0],requires_grad=True)
b = a+2
print(b._version)
loss = (b * b).mean()
b[0] = 1000.0
print(b._version)
# loss.backward()
# print(loss._version)

RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [2]], which is output 0 of AddBackward0, is at version 1; expected version 0 instead.
18、每次tensor进行inplace时,_version的值就会加1,在正向传播过程中,求导系统记录的b的version是0,但是反向传播过程中,求导系统发现b的version变成了
19、对于requires_grad=True的叶子节点的值,在求梯度之前,是不允许修改的。
20、类似一下应用:
RuntimeError: leaf variable has been moved into the graph interior
a = 0
a = torch.tensor([10.,5.,2.,3.],requires_grad=True)
print(a,a.is_leaf)
print(a,id(a))

# a[:]=0
# a.add_(10.)
print(a,a.is_leaf,a.requires_grad)
print(a,id(a))

loss3 = (a*a).mean()
loss3.backward()
21、在使用a[:]=0时,实际上是用inplace操作把一个叶子节点变成了非叶子节点了,这样的话,导数就不会被保存了,就变成none了。
22、也就是说,在backward之前,我们要想修改叶子节点,必须按照一定的规则
23、方法一
a = torch.tensor([10.,5.,2.,3.],requires_grad=True)
print(a,a.is_leaf,id(a))
#方法1:操作a的data
a.data.fill_(5.)
print(a,a.is_leaf,id(a))
loss5 = (a*a).mean()
loss5.backward()
print(a.grad)

24、方法二
a = torch.tensor([10.,5.,2.,3.],requires_grad=True)
print(a,a.is_leaf)
#方法2:这里是设置不需要grad:
with torch.no_grad():
a[:]=10.
print(a,a.is_leaf)
loss = (a*a).mean()
loss.backward()
print(a.grad)

25、这里,第一种方法用fill来修改,第二种方法用with torch.no_grad()来修改,其实都是找到了一个变量,这个变量与a共享了内存,但这个变量得requires_grad是False
26、比如,a.data.fill_(5.)时,a.data就是这个中间变量,不但与a共享了内存,而且这个变量是不需要requires_grad的
27、with torch.no_grad() 是不进行grad相关操作。
作业:线性回归模型解决数字图像分类问题(使用auto grad)
手动实现线性回归模型解决数字图像分类问题:
这里我们使用auto grad
# coding:utf-8
# code for week3
import torch
from torch.autograd import Variable as V
def generate_data():
# 本函数生成0-9,10个数字的图片矩阵
image_data = []
num_0 = torch.tensor(
[[0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_0)
num_1 = torch.tensor(
[[0, 0, 0, 1, 0, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 1, 1, 1, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_1)
num_2 = torch.tensor(
[[0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 1, 1, 1, 1, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_2)
num_3 = torch.tensor(
[[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_3)
num_4 = torch.tensor(
[
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 1, 1, 0],
[0, 0, 1, 0, 1, 0],
[0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_4)
num_5 = torch.tensor(
[
[0, 1, 1, 1, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_5)
num_6 = torch.tensor(
[[0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_6)
num_7 = torch.tensor(
[
[0, 1, 1, 1, 1, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_7)
num_8 = torch.tensor(
[[0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_8)
num_9 = torch.tensor(
[[0, 0, 1, 1, 1, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 1, 1, 1, 0],
[0, 1, 0, 0, 1, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0]])
image_data.append(num_9)
image_label = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
return image_data, image_label
def get_feature(x, dim):
# 下面添加提取图像x的特征feature的代码
Heigh = x.shape[0]
feature = torch.sum(x, dim)
feature = feature.float()
feat_dim = feature.shape[0]
# 归一化
for i in range(0, feat_dim):
feature[i] = feature[i] / sum(feature)
feature = feature.view(1, Heigh)
return feature
def train_model(weights, learning_rate, iters, num_data, image_data, image_label):
for epoch in range(iters):
loss = 0
for i in range(0, num_data):
feature = get_feature(image_data[i], 1)
y_pred = linear_model(feature, weights)
loss += 0.5 * (y_pred - image_label[i])**2
# 自动计算梯度
loss.backward()
# 更新参数,原来的weight的data值减去训练后weight.grad.data*lr。
weights.data.sub_(learning_rate * weights.grad.data)
# 梯度清零,不清零梯度会累加
weights.grad.data.zero_()
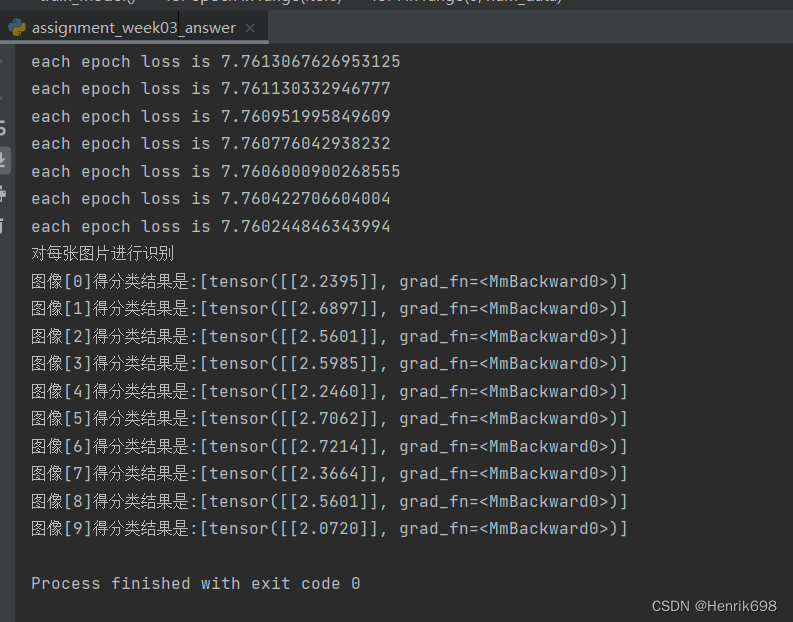
print('each epoch loss is {}'.format(loss.item()))
return weights
def linear_model(feature, weights):
y = -1
# y = w1*x1 + w2*x2 +...+ w6*x6
feature = torch.cat((feature, torch.tensor(1.0).view(1,1)), 1)
y = feature.mm(weights)
return y
if __name__ == "__main__":
#1、生成数据集和标签
image_data, image_label = generate_data()
num_sample = len(image_data) #样本数据的长度,样本个数。
num_feat = 6 #特征数为5
#2、随机的初始化参数
#生成7行1列的weight。初始化的weight
weights = torch.rand(num_feat + 1, 1, requires_grad=True)
# 学习率
learning_rate = 0.0005
iters = 5000
num_data = 6
# 训练好的weight
new_weights = train_model(weights, learning_rate, iters, num_data, image_data, image_label)
print("对每张图片进行识别")
for i in range(0, num_sample):
x = image_data[i]
# 对当前图片提取特征
dim = 0
feature = get_feature(x, dim)
# 对提取到得特征进行分类
y = linear_model(feature, weights)
# 打印出分类结果
print("图像[%s]得分类结果是:[%s]" % (i, y))
发现分类效果不好: