1.背景
最近参加了一个评测,是关于新闻个性化推荐。说白了就是给你一个人的浏览记录,预测他下一次的浏览记录。花了一周时间写了一个集成系统,可以一键推荐新闻,但是准确率比较不理想,所以发到这里希望大家给与一些建议。用到的分词部分的代码借用的jieba分词。数据集和代码在下面会给出。
2.数据集
一共五个字段,以tab隔开。分别是user编号,news编号,时间编号,新闻标题,对应当前月份的日(3就是3号)
3.代码部分
先来看下演示图
(1)算法说明
举个例子简单说明下算法,其实也比较简单,不妥的地方希望大家指正。我们有如下一条数据
5738936 100649879 1394550848 MH370航班假护照乘客身份查明(更新) 11
5738936这名用户在11号看了“MH370航班假护照乘客...”这条新闻。我们通过jieba找出11号的热点词如下。
失联 311 三周年 马方 偷渡客 隐形 护照 吉隆坡 航班 护照者
我们发现“航班”、“护照”这两个keywords出现在新闻里。于是我们就推荐5738936这名用户,11号出现“航班”、“护照”的其它新闻。同时我们对推荐集做了处理,比如说5738936浏览过的新闻不会出现,热度非常低的新闻不会出现等。
(2)使用方法
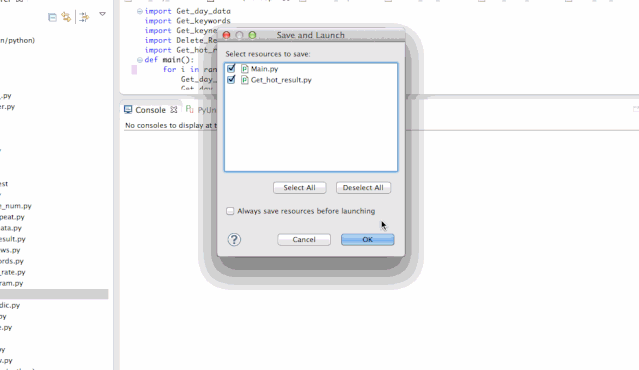
整个系统采用一键式启动,使用起来非常方便。首先建立一个test文件夹,然后在test里新建三个文件夹,注意命名要和图中的统一,因为新闻是有时效的,每一天要去分开来计算,要存储每一天的内容做成文档。test文档如下图,就可以自动生成。(下面的github链接提供了完整的test文档结构)
使用的时候,要先在Global_param.py中设置好test文件夹的路径参数。一切设置完毕,只要找到wordSplite_test包下面的main()函数,运行程序即可。
Global_param中设置参数说明:
number_jieba:控制提取关键词的数量
number_day:从第一天开始,要预测的天数
hot_rate:预测集预测的新闻热度,数值越大热度越高
(3)代码流程
首先我们从main()看起。
import Get_day_data
import Get_keywords
import Get_keynews
import Delete_Repeat
import Get_hot_result
import Global_param
def main():
for i in range(1,Global_param.number_day):
Get_day_data.TransforData(i)
Get_day_data.TransforDataset(i)
Get_keywords.Get_keywords(i)
Get_keynews.Get_keynews(i)
Delete_Repeat.Delete_Repeat()
Get_hot_result.get_hot_result(Global_param.hot_rate)
main()
1.首先Get_day_data.TransforData(i)函数,找到最后一次浏览的是第i天的新闻的用户行为,存放在test/train_lastday_set目录下。
2.Get_day_data.TransforDataset(i)函数,区分每一天的新闻,存放在test/train_date_set1目录下
3.Get_keywords.Get_keywords(i)函数,调用jieba库,挑出每一天最火的keywords,存放在test/key_words下
4.Get_keynews.Get_keynews(i)函数,通过每一个用户最后一次浏览的新闻,比对看有没有出现当天的热门keywords。如果出现,就推荐当天包含这个keywords的其它新闻。循环Global_param.number_day天,生成test/result.txt文件
5. Delete_Repeat.Delete_Repeat()函数,去除result中的重复项,生成test/result_no_repeat.txt
6.Get_hot_result.get_hot_result(Global_param.hot_rate)函数,因为上面生成的result_no_repeat函数可能出现,每个用户推荐过多的情况,影响准确率。所以用这个函数控制数量,每个用户只推荐新闻热度相对高的候选项。
最终结果集
test/result_no_repeat_hot.txt
注意:test下的result.txt文件每执行一次程序要手动清空,其它文件都是自动生成不用处理。
项目地址:https://github.com/X-Brain/News-Recommend-System(src文件夹下是代码,test下是数据、和文档结构)
----------------------------------
来自5年后的补充:
故事的背景是这样滴
14年的时候,我还在读研究生,那时候机器学习还算不上是一个重要的计算机学科,如果能顺嘴说一说TF-IDF、Collaborative Filtering这种算法(虽然现在听起来很naive),在当时基本上就是技术潮男一般的存在,在五道口咖啡厅能横着“骗项目”、“骗钱”。
我因为当时正好在微创业,当时准备做一个智能猎头的项目,用算法去给每个程序员的能力打分,再把程序员推送给合适的公司应聘,然后给B端猎头公司做ToB服务(当时这个理念有点太geek,不过现在有些PAI的客户确实把这种事做起来了,我很欣慰)。
这其中涉及到很多文本分析和推荐相关的技术,于是我就自己开发了一套新闻推荐系统锤炼相关技术,从网上爬了真实的新闻数据,并把这个项目开源。
https://github.com/X-Brain/News-Recommend-System
项目动图:
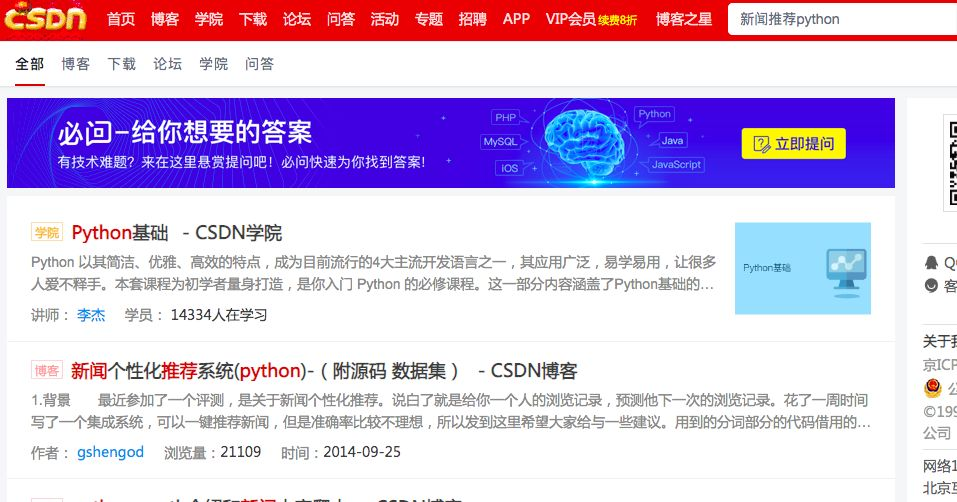
还成了相关项目的搜索头条:
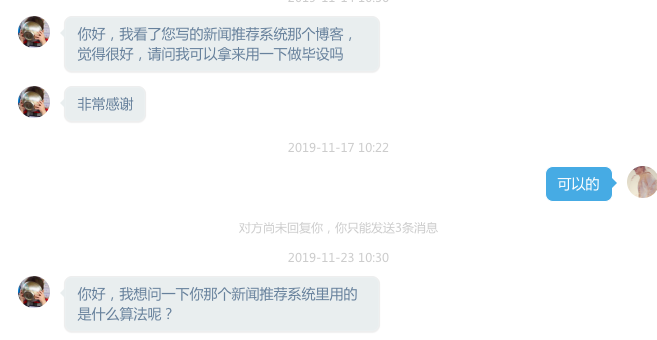
成了毕设热门项目
万万没想到,我的无心之举没想到成就了很多在校同学。每年毕设季都能收到非常多的来自同学们的私信,大致是下面这种。
也有很多同学在我的微信公众号留言,想交流这个项目。所以我想还是有必要跟大家把这个项目好好介绍下,因为这个项目虽然目前来看技术比较老,但是作为本科生毕设项目还是OK的,而且吃透后会给同学们很多收获。
技术点拆解
做这个项目一定要动手去做,去读代码,不要直接拿过来用。最核心的几个技术点我列一下:
1.crawler爬虫
做训练要有数据,可以在网上找下相关的爬虫开源项目,直接爬搜狐、新浪这样的网站。他们有反扒机制,如何破解这种机制是大家要掌握的。
2.分词
做文本分析一定要用到分词,我在项目里用的是jieba分词,14年的时候这个项目还是在比较初级阶段,现在应该好很多,大家可以看看有啥新功能。比如词性提取,新闻推荐系统建议只提取名词性相关的词语做TF-IDF。
3.算法
在项目里用了协同过滤和TF-IDF,这两个算法我是自己实现的,基本上是机器学习里最简单的算法,用的好像是hashtable的方式--具体想不起来了。虽然有很多开源版本,但是我建议有能力的同学这两个算法要自己写。我在做TF-IDF的时候有大量中间计算结果需要先落盘到硬盘上,这个主要是当时我的电脑内存太小,貌似只有1个G,所以没办法把所有计算压到内存做,现在大家可以试试全部内存计算的方式。
4.架构设计
其实前面三点,对于目前的本科同学应该都不难,因为现在网上的资料很多。真正要学习的是架构设计,因为一个推荐系统不光只有原子化的算法还要有一个好的设计把算法结果串起来。要思考哪些功能可以抽象成util或者tools这种工具包,比如统计、排序等功能。哪些计算中间结果可以在多个模块复用?
如何优化这个项目
这个项目是14年的老项目,算法更新迭代很快,那如何在这个基础上优化呢?
1.从词到主题
在整个项目里,我是基于每个人过去浏览的新闻中的关键词进行推荐。关键词的上一级是主题,能不能给每个用户喜爱的主题打标,基于主题推荐。比如现在的项目里可以抽象出用户A喜欢 费德勒、乔丹、跑步这样的关键词,那么能不能向上抽象一层,显示出用户A喜欢体育并且推送体育相关的新闻。
2.增加排序模型
现在的推荐系统只有召回没有排序,也就是说可以基于协同过滤或者TF-IDF计算出每个用户潜在的喜欢的文章,但是并不能确定这些文章哪个是用户最喜欢,哪个是第二喜欢。如果可以基于文本做特征提取,并且使用逻辑回归等排序算法训练出排序模型,那么推荐的准确率会大大增加。
这一点我在后续的很多项目做了类似的工作,比如:
https://blog.csdn.net/buptgshengod/article/details/40541949
总结
羡慕大家现在毕设就能接触到推荐系统,在我毕业那个年代还是比较少见的,给大家的建议就是一定要自己动手,能自己写的模块尽量自己写~还有就是,这个项目比较简单,可能只适合本科生,研究生同学建议搞点更高深的。这篇文章我会加到新闻推荐那个项目介绍的博客后面,方便以后更多的同学看到。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)