一、Posix信号量
1.概述
信号量是一种用于提供不同进程间或一个给定进程的不同线程间同步手段的原语。三种类型的信号量:
- Posix有名信号量:使用
Posix IPC名字标识,可用于进程或线程间的同步。
- Posix基于内存的信号量:存放在共享内存区中,可用于进程或线程间的同步。
- System V信号量:在内核中维护,可用于进程或线程间的同步。
只考虑不同进程间的同步。首先考虑二值信号量: 其值或为0或为1的信号量。如下图所示:
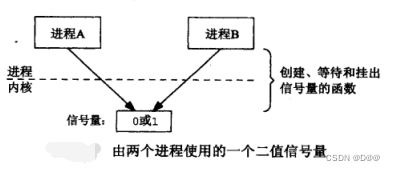
图中画出该信号量是由内核来维护的(对于SystemV信号量是正确的),其值可以是0或1。 Posix信号量不必在内核中维护。
Posix信号量是由可能与文件系统中的路径名对应的名字来标识的。因此,下图是Posix有名信号量的更为实际的图示。
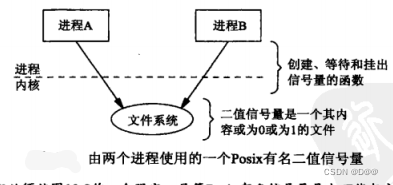
一个进程可以在某个信号量上执行的三种操作:
-
创建:调用者指定初始值,二值信号量,通常是1或0。
-
等待:测试信号量值,小于或等于0,阻塞;大于0将将其减1。(while(semaphore_value<=0) ; semaphore--;)
-
挂出:将信号量的值加1。若有一些进程阻塞着等待该信号量的值变为大于0,其中一个进程现在就可能被唤醒。考虑到访问同一信号量的其他进程,挂出操作也必须是原子的。(semaphore_value++)。
没有使用其值仅为0或1的二值信号量,这种信号量称为计数信号量,二值信号量可用互斥目的,就像互斥锁一样,如下所示:

信号量初始化为1,sem_wait调用等待其值变为大于0,然后将它减1,sem_post调用则将其值加1(从0变为1),然后唤醒阻塞在sem_wait调用中等待该信号量的任何线程。
除可以像互斥锁那样使用外,信号量还有一个互斥锁没有提供的特性:互斥锁必须总是由锁住它的线程解锁,信号量的挂出却不必由执行过它的等待操作的同一线程执行。
使用两个二值信号量和生产者-消费者问题的一个简化版本提供展示这种特性的一个例子。
下展示了往某个共享缓冲区中放置 一个条目的一 个生产者以及取走该条 目的一个消费者。为简单起见,假设该缓冲区只容纳一个条目。

下图显示生产者和消费者伪代码:

步骤:
-
生产者初始化缓冲区和两个信号量。
-
假设消费者接着运行 。 它阻塞在sem_wait调用中,因为get的值为0。
-
一 段时间后生产者接着运行:
- 当它调用sem_wait后,put的值由1减为0, 于是生产者往缓冲区中放宽 一 个条目,然后它调用sem_post, 把get的值由0增为1。
- 既然有一个线程(即消费者)阻塞在该信号量上等待其值变为正数,该线程将被标记成准备好运行。
- 但是假设生产者继续运行,生产者随后会阻塞在for循环顶部的
sem_wait调用中,因为put的值为0。生产者必须等待到消费者腾空缓冲区。
-
消费者从set_wait调用中返回,将get信号量的值由1减为0。然后处理缓冲区中的数据,然后调用sem_post,把put的值由0增为1。既然有一个线程(生产者)阻塞在该信号量上等待其值变为正数,该线程将被标记成准备好运行。但是假设消费者继续运行,消费者随后会阻塞在for循环顶部的sem_wait调用中,因为get的值为0。
-
生产者从sem_wait调用中返回,把数据放入缓冲区中,上述情形循环继续。若每次调用sem_post时,即使当时有一个进程正在等待并随后被标记成准各好运行,调用者也继续运行。是调用者继续运行还是刚变成准备好状态的线程运行无关紧要。
信号量、互斥锁和条件变量之间的三个差异:
-
互斥锁必须总是由给它上锁的线程解锁,信号量的挂出却不必由执行过它的等待操作的同一 线程执行。
-
互斥锁要么被锁住,要么被解开(二值状态,类似于二值信号量)。
-
既然信号量有一个与之关联的状态(它的计数值),则信号量挂出操作总是被记住。
-
当向条件变量发送信号时,如果没有线程等待在该条件变量上,那么该信号将丢失。
二、.Posix提供两种信号量:有名信号量和基于内存的信号量
POSIX信号量有两种形式,差异在于创建和销 毁的形式上:
-
命名的:命名信号量可以通过名字访问,因此可以被任何已知它们名字的进程中的 线程使用。
-
未命名的:未命名信号量只存在于内存中,并要求能使用 信号量的进程必须可以访问内存。意味着只能应用在同一进程中的线 程,或者不同进程中已经映射相同内存内容到它们的地址空间中的线程。
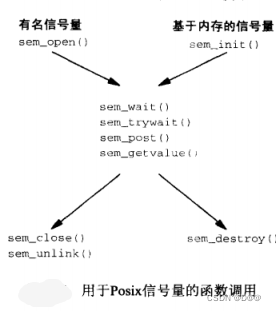
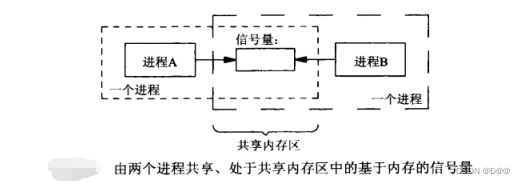
下图显示某个进程由两个线程共享一个Posix基于内存的信号量。
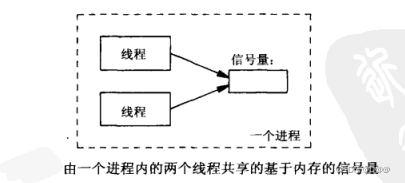
下图显示某个共享内存区中由两个进程共享的一个Posix基于内存的信号量。
三、命名信号量
要使用命名信号量必须要使用下列函数:
-
sem_open()函数打开或者创建一个信号量并返回一个句柄以供后继调用使用,如果这个调用会创建信号量的话还会对所创建的信号量进行初始化。
-
sem_post(sem)和 sem_wait(sem)函数分别递增和递减一个信号量值。
-
sem_getvalue()函数获取一个信号量的当前值。
-
sem_close()函数删除调用进程与它之前打开的一个信号量之间的关联关系
-
sem_unlink())函数删除一个信号量名字并将其标记为在所有进程关闭该信号量时删除该信号量。
1.sem_open和sem_close函数
//创建一个新的命名信号量或者使用一个现有信号量
//使用现有信号量,只需指定两个参数:信号量的名字和oflag参数的0值。
#include<semaphore.h>
sem_t *sem_open(const char *name,int oflag,../*mode_t mode,unsigned int value*/);
//返回值:若成功,返回指向信号量的指针;若出错,返回SEM_FAILED
-
oflag参数有O_CREAT标志集时,若命名信号量不存在,则创建新的;若存在被利用。指定O_CREAT需提供额为两个参数。
-
mode参数指定谁可以访问信号量,取值和打开文件的权限位相同,赋值给信号量的权限可以被调用者的文件创建屏蔽字修改。只有读和写访问要紧,但是打开一个现有信号量不允许指定模式。实现经常为读和写打开信号量。
-
value参数用来指定信号量1的初始值,取值范围为0~SEM_VALUE_MAX。
-
确保创建的是信号量,可以设置参数为O_CREAT|O_EXCL,若信号量已经存在,会导致sem_open失败。
//释放任何信号量相关资源
#include <semaphore.h>
int sem_close(sem_t *sem);
//进程没有首先调用sem_close而退出,那么内核将自动关闭任何打开的信号量。
//返回值:若成功,返回0;若出错,返回-1
例:创建有名信号量,运行命令行选项指定独占创建的-e和指定1一个初始值的-i。
int main(int argc, char **argv)
{
int c, flags;
sem_t *sem;
unsigned int value;
flags = O_RDWR | O_CREAT;
value = 1;
while ( (c = getopt(argc, argv, "ei:")) != -1) {
switch (c) {
case 'e':
flags |= O_EXCL;
break;
case 'i':
value = atoi(optarg);
break;
}
}
if (optind != argc - 1)
err_quit("usage: semcreate [ -e ] [ -i initalvalue ] <name>");
sem = sem_open(argv[optind], flags, FILE_MODE, value);
sem_close(sem);
exit(0);
}
2.sem_unlink函数
//来销毁一个命名信号量。
#include <semaphore.h>
int sem_unlink(const char *name);
//如果没有打开的信号量引用,则该信号量会被销毁。否则,销毁将延迟到最后一个打开的引用关闭。
// 返回值:若成功,返回0;若出错,返回-1
例:删除一个有名信号量名字。
int main(int argc, char **argv)
{
if (argc != 2)
err_quit("usage: semunlink <name>");
em_unlink(argv[1]);
exit(0);
}
3.sem_wait函数
//来实现信号量的减1操作
#include <semaphore.h>
int sem_trywait(sem_t *sem);
int sem_wait(sem_t *sem);
//两个函数的返回值:若成功,返回0;若出错则,返回-1
-
使用sem_wait函数时,如果信号量是0则会发生阻塞,,直到成功使用信号量减1或被信号中断才返回。
-
sem_trywait函数可以避免阻塞,调用此函数时,如果信号量为0,则不会阻塞,而是返回-1并且将errno置为EAGAIN。
下列函数是sem_wait函数的一个变体,允许调用者为被阻塞的时间指定一个限制。
//阻塞一段确定的时间。
#include <semaphore.h>
#include <time.h>
int sem_timedwait(sem_t *restrict sem, const struct timespec *restrict tsptr);
//放弃等待信号量时,用tsptr指定绝对时间,超时是基于CLOCK_REALTIME时钟的。
//信号量可以立即减1,则超时不重要了,尽管指定是过去某个时间,信号量减1操作仍然会成功。
//超时到期并且信号量计数没能减1,此函数将返回-1且errno设置为ETIMEFOUT。
//返回值:若成功,返回0;若出错,返回−1
例:打开一个信号量,调用sem_wait(信号量的当前值小于或等于0,则阻塞结束阻塞信号量减1)。
int main(int argc, char **argv)
{
sem_t *sem;
int val;
if (argc != 2)
err_quit("usage: semwait <name>");
sem = sem_open(argv[1], 0);
Sem_wait(sem);
Sem_getvalue(sem, &val);
printf("pid %ld has semaphore, value = %d\n", (long) getpid(), val);
pause(); /* blocks until killed */
exit(0);
}
5.sem_post函数
//使信号量值增1
#include <semaphore.h>
int sem_post(sem_t *sem);
//调用此函数时,在调用sem_wait(或者sem_timedwait)中发生进程阻塞,那么进程会被唤醒并且被sem_post增1的信号量计数会再次被sem_wait(或者sem_timedwait)减1。
//返回值:若成功,返回0;若出错,返回−1
例:挂出有名信号量,然后取得并输出该信号量的值。
int main(int argc, char **argv)
{
sem_t *sem;
int val;
if (argc != 2)
err_quit("usage: sempost <name>");
sem = sem_open(argv[1], 0);
Sem_post(sem);
Sem_getvalue(sem, &val);
printf("value = %d\n", val);
exit(0);
}
6.sem_getvalue函数
//来检索信号量值。
#include <semaphore.h>
int sem_getvalue(sem_t *restrict sem, int *restrict valp);
//成功valp指向的整数值将包含信号量值。
//注:试图使用刚读出的值信号量的值可能改变了,除非使用额外的同步机制来避免这种竞争。否则此函数只能用于调式。
//返回值:若成功,返回0;若出错,返回−1
//例:获取POSIX信号量值
#include <semaphore.h>
#include "tlpi_hdr.h"
int main(int argc, char *argv[])
{
sem_t *sem;
if (argc < 2 || strcmp(argv[1], "--help") == 0)
usageErr("%s sem-name\n", argv[0]);
sem = sem_open(argv[1], 0);
if (sem == SEM_FAILED)
errExit("sem_open");
if (sem_wait(sem) == -1)
errExit("sem_wait");
printf("%ld sem_wait() succeeded\n", (long) getpid());
exit(EXIT_SUCCESS);
}
四、生产者-消费者问题
解决生产者-消费者问题方案:
1.消费者在生产者完成后启动的,使用单个**互斥锁(同步各个生产者)**就能解决问题。
2.消费者在生产者完成前启动,解决同步问题使用一个互斥锁(同步各个生产者)加上一个条件变量及其互斥锁(同步生产者和消费者)。
对生产者-消费者问题进行扩展:
把共享缓冲区用作一个环绕缓冲区:生产者填写最后一项([buff[NBUFF-1])后,回过来填写第一项([buff[0]),消费者也这么做。这时增加了同步问题。即生产者不能走到消费者的前面。仍然假设生产者和消费者都是线程,也可为进程,前提存在某种在进程间共享缓冲区的方法。
当缓冲区作为一个环形缓冲区考虑,必须由代码维持以下三个条件:
-
当缓冲区为空时,消费者不能试图从其中去除一个条目。
-
当缓冲区填满时,生产者不能试图往其中放置一个条目。
-
共享变量可能描述缓冲区的当前状态,因此生产者和消费者的所有缓冲区操作都必须保护起来,避免竞争状态。
下面的信号量的方案展示了三种不同类型的信号量:
-
名为mutex的二值信号量保护两个临界区:一个是往缓冲区中插入一个数据条目(生产者执行),另一个从共享缓冲区中移走一个数据条目(消费者执行)。用互斥锁的二值信号量初始化为1。
-
名为nempty的计数信号量统计共享缓冲区中的空槽位数。该信号量初始化为缓冲区中的槽位数(NBUFF)。
-
名为nstored的计数信号量统计共享缓冲区中已填写的槽位数。该信号量初始化为0,因为缓冲区开始是空的。
下图展示了程序完成初始化时缓冲区及两个计算信号量的状态。未用的数组元素标以阴影。
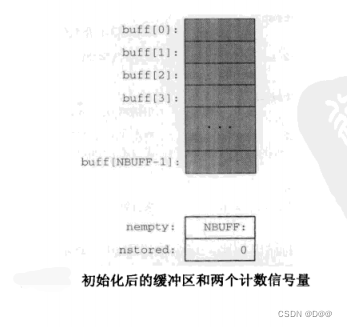
例子中,生产者只是把 0~(NLOOP-1) 存放到共享缓冲区中(buff[0]= 0,buff[1]= 1, 等等),并把该缓冲区用作一 个环绕缓冲区。
消费者从该缓冲区取出这些整数,井验证它们是正确的,若有错误则输出到标准输出上。
下图展示了在生产者往共享缓冲区放置了3个条目之后,但在消息者从该缓冲区取走其中任何条目之前该缓冲区和两个计数信号量的状态。

接着假设消费者从缓冲区中移走一个条目,如下图所示:

#define NBUFF 10
#define SEM_MUTEX "mutex" /* t这些是px_ipc_name()的参数*/
#define SEM_NEMPTY "nempty"
#define SEM_NSTORED "nstored"
int nitems; /* 生产者和消费者只读*/
/* 生产者和消费者共享的数据*/
struct {
int buff[NBUFF];
sem_t *mutex, *nempty, *nstored;
} shared;
void *produce(void *), *consume(void *);
int main(int argc, char **argv)
{
pthread_t tid_produce, tid_consume;
if (argc != 2)
err_quit("usage: prodcons1 <#items>");
nitems = atoi(argv[1]);
/* 创建三个信号量*/
shared.mutex = sem_open(Px_ipc_name(SEM_MUTEX), O_CREAT | O_EXCL,
FILE_MODE, 1);
shared.nempty =sem_open(Px_ipc_name(SEM_NEMPTY), O_CREAT | O_EXCL,
FILE_MODE, NBUFF);
shared.nstored = sem_open(Px_ipc_name(SEM_NSTORED), O_CREAT | O_EXCL,
FILE_MODE, 0);
/* 创建一个生产者线程和一个消费者线程 */
set_concurrency(2);
pthread_create(&tid_produce, NULL, produce, NULL);
pthread_create(&tid_consume, NULL, consume, NULL);
/* 等待两个线程 */
pthread_join(tid_produce, NULL);
pthread_join(tid_consume, NULL);
/* 移除信号灯 */
sem_unlink(px_ipc_name(SEM_MUTEX));
sem_unlink(px_ipc_name(SEM_NEMPTY));
sem_unlink(px_ipc_name(SEM_NSTORED));
exit(0);
}
/* 包括prodcon*/
void * produce(void *arg)
{
int i;
for (i = 0; i < nitems; i++) {
Sem_wait(shared.nempty); /*等待至少1个空插槽 */
Sem_wait(shared.mutex);
shared.buff[i % NBUFF] = i; /* 将i存储到循环缓冲区 */
Sem_post(shared.mutex);
Sem_post(shared.nstored); /* 又存储了1个项目 */
}
return(NULL);
}
void * consume(void *arg)
{
int i;
for (i = 0; i < nitems; i++) {
Sem_wait(shared.nstored); /* 等待至少1个存储项 */
Sem_wait(shared.mutex);
if (shared.buff[i % NBUFF] != i)
printf("buff[%d] = %d\n", i, shared.buff[i % NBUFF]);
Sem_post(shared.mutex);
Sem_post(shared.nempty); /* 还有1个空插槽 */
}
return(NULL);
}
如果错误的对换了消费者函数中sem_wait调用的顺序,将会产生死锁。生产者在等待mutex信号量,但是消费者却持有该信号量并在等待nstored信号量然而生产者只有获取了mutex信号量才能挂出nstored信号量。
五、未命名信号量
**未命名信号量(也被称为基于内存的信号量)**是连续为sem_t并存储在应用程序分配的内存中的变量。通过将这个信号量放在由几个进程或者线程共享的内存区域中就能使得这个信号量对这些进程或者线程可用。
操作未命名信号量所使用的函数与操作命名信号量使用的函数是一样的(sem_wait()、sem_post()以及 sem_getvalue()等)。此外,还需要用到另外两个函数。
- sem_init()对一个信号量进行初始化并通知系统该信号量会在在进程间共享还是在单个进程中的线程间共享。
- sem_destroy(sem)函数销毁一个信号量。
这些函数不应该被应用到命名信号量上。
未命名与命名信号量对比:
使用未命名信号量之后就无需为信号量创建一个名字了,这种做法在下列情况中是比较有用的
1.sem_init函数
//创建未命名的信号量
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
//pshared参数表明是否在多个进程中使用信号量,若是设置成非0值。
//需要声明一个sem_t类型的变量并把它的地址传递给sem_init来实现初始化。
//value:指定了信号量的初始值。
//要在两个进程之间使用信号量,需要确保sem参数指向两个进程之间共享的内存范围。
// 返回值:若成功,返回0;若出错,返回−1
2.sem_destroy函数
//丢弃未命名的信号量
#include <semaphore.h>
int sem_destroy(sem_t *sem);
//调用此函数后,不能再使用任何带有sem的信号量函数,除非通过调用sem_init重新初始化它。
//返回值:若成功,返回0;若出错,返回−1
例:将上面的生产者-消费者例子转换成使用基于内存的信号量。
#include "unpipc.h"
#define NBUFF 10
int nitems; /*生产者和消费者只读 */
struct { /* 生产者和消费者共享的数据 */
int buff[NBUFF];
sem_t mutex, nempty, nstored; /* 信号量,而不是指针*/
} shared;
void *produce(void *), *consume(void *);
int
main(int argc, char **argv)
{
pthread_t tid_produce, tid_consume;
if (argc != 2)
err_quit("usage: prodcons2 <#items>");
nitems = atoi(argv[1]);
/* 4初始化三个信号量*/
Sem_init(&shared.mutex, 0, 1);
Sem_init(&shared.nempty, 0, NBUFF);
Sem_init(&shared.nstored, 0, 0);
Set_concurrency(2);
Pthread_create(&tid_produce, NULL, produce, NULL);
Pthread_create(&tid_consume, NULL, consume, NULL);
Pthread_join(tid_produce, NULL);
Pthread_join(tid_consume, NULL);
Sem_destroy(&shared.mutex);
Sem_destroy(&shared.nempty);
Sem_destroy(&shared.nstored);
exit(0);
}
void *produce(void *arg)
{
int i;
for (i = 0; i < nitems; i++) {
sem_wait(&shared.nempty); /* 等待至少1个空插槽 */
sem_wait(&shared.mutex);
shared.buff[i % NBUFF] = i; /*将i存储到循环缓冲区 */
sem_post(&shared.mutex);
sem_post(&shared.nstored); /*又存储了1个项目 */
}
return(NULL);
}
void * consume(void *arg)
{
int i;
for (i = 0; i < nitems; i++) {
sem_wait(&shared.nstored); /*等待至少1个存储项*/
sem_wait(&shared.mutex);
if (shared.buff[i % NBUFF] != i)
printf("buff[%d] = %d\n", i, shared.buff[i % NBUFF]);
sem_post(&shared.mutex);
sem_post(&shared.nempty); /* 还有1个空插槽 */
}
return(NULL);
}
六、多个生产者、单个消费者
下列是允许多个生产者和单个消费者。
#define NBUFF 10
#define MAXNTHREADS 100
int nitems, nproducers; /*生产者和消费者只读 */
struct { /* 生产者和消费者共享的数据 */
int buff[NBUFF];
int nput;
int nputval;
sem_t mutex, nempty, nstored; /* 信号量,而不是指针*/
} shared;
void *produce(void *), *consume(void *);
int main(int argc, char **argv)
{
int i, count[MAXNTHREADS];
pthread_t tid_produce[MAXNTHREADS], tid_consume;
//新命令行参数
if (argc != 3)
err_quit("usage: prodcons3 <#items> <#producers>");
nitems = atoi(argv[1]);
nproducers = min(atoi(argv[2]), MAXNTHREADS);
/* 初始化三个信号量*/
sem_init(&shared.mutex, 0, 1);
sem_init(&shared.nempty, 0, NBUFF);
sem_init(&shared.nstored, 0, 0);
/* 创建所有生产者和一个消费者 */
set_concurrency(nproducers + 1);
for (i = 0; i < nproducers; i++) {
count[i] = 0;
pthread_create(&tid_produce[i], NULL, produce, &count[i]);
}
pthread_create(&tid_consume, NULL, consume, NULL);
/*等待所有生产者和消费者*/
for (i = 0; i < nproducers; i++) {
pthread_join(tid_produce[i], NULL);
printf("count[%d] = %d\n", i, count[i]);
}
pthread_join(tid_consume, NULL);
em_destroy(&shared.mutex);
em_destroy(&shared.nempty);
sem_destroy(&shared.nstored);
exit(0);
}
//生产者执行函数
void *produce(void *arg)
{
for ( ; ; ) {
em_wait(&shared.nempty); /* 等待至少1个空插槽 */
em_wait(&shared.mutex);
//生产者线程间的互斥
if (shared.nput >= nitems) {
em_post(&shared.nempty);
em_post(&shared.mutex);
return(NULL); /* 全部完成 */
}
shared.buff[shared.nput % NBUFF] = shared.nputval;
shared.nput++;
shared.nputval++;
em_post(&shared.mutex);
em_post(&shared.nstored); /* 又存储了1个项目*/
*((int *) arg) += 1;
}
}
// 消费者使用,验证缓冲区每个项都是正确的,检查到错误就输出一个消息
void *consume(void *arg)
{
int i;
for (i = 0; i < nitems; i++) {
sem_wait(&shared.nstored); /* 等待至少1个存储项*/
sem_wait(&shared.mutex);
if (shared.buff[i % NBUFF] != i)
printf("error: buff[%d] = %d\n", i, shared.buff[i % NBUFF]);
sem_post(&shared.mutex);
sem_post(&shared.nempty); /* 还有1个空插槽 */
}
return(NULL);
}
七、多个生产者,多个消费者
多个生产者和消费者,具有多少个消费者是否有意义决定于具体应用,例:
- 把IP地址转换成对应主机名。
- 读出UDP数据报,对它们进行操作后把结果写入某个数据库的程序。
#define NBUFF 10
#define MAXNTHREADS 100
int nitems, nproducers, nconsumers; //只读
struct { /* 生产者和消费者共享的数据 */
int buff[NBUFF];
int nput; /* 项目编号: 0, 1, 2, ... */
int nputval; /* 要存储在buff中的值[] */
int nget; /* 项目编号: 0, 1, 2, ... */
int ngetval; /*从buff[]获取的值*/
sem_t mutex, nempty, nstored; /* 信号量,而不是指针*/
} shared;
void *produce(void *), *consume(void *);
int main(int argc, char **argv)
{
int i, prodcount[MAXNTHREADS], conscount[MAXNTHREADS];
//tid_produce:保存消费者线程ID;tid_consume:保存消费者处理的条目数
pthread_t tid_produce[MAXNTHREADS], tid_consume[MAXNTHREADS];
//增设一个新的命令行选项,由它指定待创建消费者线程的总数。
if (argc != 4)
err_quit("usage: prodcons4 <#items> <#producers> <#consumers>");
nitems = atoi(argv[1]);
nproducers = min(atoi(argv[2]), MAXNTHREADS);
nconsumers = min(atoi(argv[3]), MAXNTHREADS);
/* 初始化三个信号量 */
sem_init(&shared.mutex, 0, 1);
sem_init(&shared.nempty, 0, NBUFF);
sem_init(&shared.nstored, 0, 0);
/* 创建所有生产者和所有消费者 */
set_concurrency(nproducers + nconsumers);
for (i = 0; i < nproducers; i++) {
prodcount[i] = 0;
pthread_create(&tid_produce[i], NULL, produce, &prodcount[i]);
}
for (i = 0; i < nconsumers; i++) {
conscount[i] = 0;
pthread_create(&tid_consume[i], NULL, consume, &conscount[i]);
}
/* 等待所有生产者和消费者 */
for (i = 0; i < nproducers; i++) {
pthread_join(tid_produce[i], NULL);
printf("producer count[%d] = %d\n", i, prodcount[i]);
}
for (i = 0; i < nconsumers; i++) {
pthread_join(tid_consume[i], NULL);
printf("consumer count[%d] = %d\n", i, conscount[i]);
}
sem_destroy(&shared.mutex);
sem_destroy(&shared.nempty);
sem_destroy(&shared.nstored);
exit(0);
}
/* 生产者 */
void *produce(void *arg)
{
for ( ; ; ) {
sm_wait(&shared.nempty); /* 等待至少1个空插槽 */
sem_wait(&shared.mutex);
if (shared.nput >= nitems) {
sem_post(&shared.nstored); /* 让消费者终止 */
sem_post(&shared.nempty);
sem_post(&shared.mutex);
return(NULL); /* 全部完成 */
}
shared.buff[shared.nput % NBUFF] = shared.nputval;
shared.nput++;
shared.nputval++;
sem_post(&shared.mutex);
sem_post(&shared.nstored); /*又存储了1个项目*/
*((int *) arg) += 1;
}
}
//消费者
void *consume(void *arg)
{
int i;
for ( ; ; ) {
sem_wait(&shared.nstored); /* 等待至少1个存储项 */
sem_wait(&shared.mutex);
if (shared.nget >= nitems) {
sem_post(&shared.nstored);
sem_post(&shared.mutex);
return(NULL); /*全部完成 */
}
i = shared.nget % NBUFF;
if (shared.buff[i] != shared.ngetval)
printf("error: buff[%d] = %d\n", i, shared.buff[i]);
shared.nget++;
shared.ngetval++;
sem_post(&shared.mutex);
sem_post(&shared.nempty); //还有1个空插槽
*((int *) arg) += 1;
}
}
八、多个缓冲区
处理典型程序中,有如下循环:
while((n>=read(fdin,buff,BUFFSIZE))>0){
write(fdout,buff,0);
}
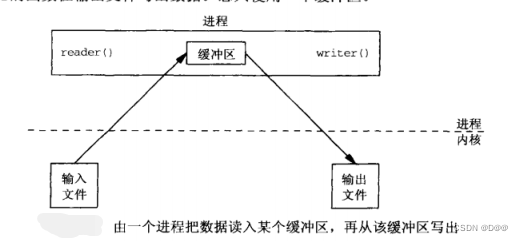
下图展示了实现这种操作的一种方法,reader的函数从输入文件读入数据,write函数输出文件写出数据。总共使用一个缓冲区。
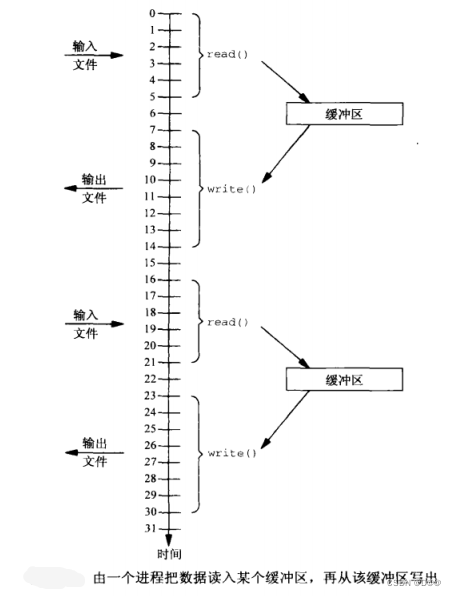
下图显示整个操作的时间线图:读操作5个时间单位写操作7个单位时间,读和写出来之间2个单位时间。
把应用修改成在两个线程间分割读写操作,两个线程自动共享一个全局缓冲区,如下图所示:
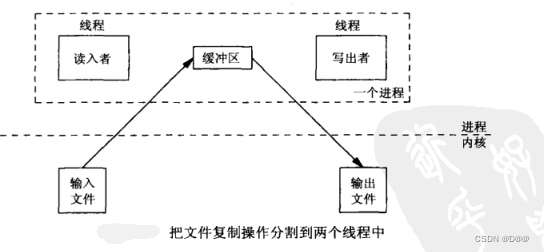
读写两个线程操作完毕后,需要通知各方,下图给出这种操作的时间线图:

上面把读和写分隔成两个线程中并不影响整个操作所需时间,没有任何速度优势,只是把整个操作分割到两个线程中。
由于使用一个缓冲区中时间线图忽略了许多细微点,如检测出对一个文件的顺序读后就为读进程执行对下一个磁盘的异步超前读、可以改善执行这种类型操作所花的称为"时钟时间"的实际时间量。还好忽略了其他进程对读入这线程和写出者线程的影响及内核调度算法的效果。
这时可以把文件复制应用修改成使用两个线程和两个缓冲区。经典的双缓冲区方案:
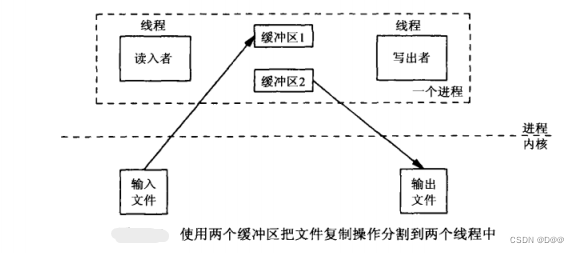
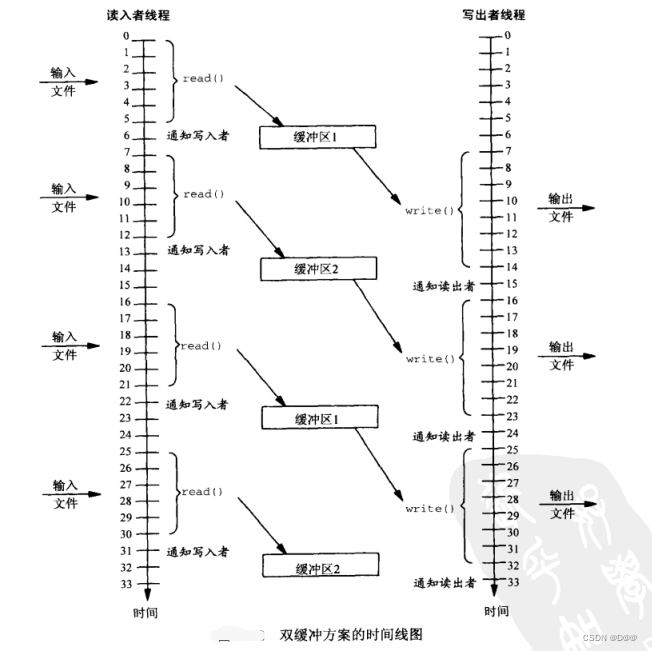
下图显示双缓冲区方案的时间线图:
-
双缓冲区所花费的总时钟时间几乎只有单缓冲区的一半。
-
双缓冲区写操作现在是尽可能快的发生每两个写操作间仅有2个单位时间作为分隔。而一个缓冲区和改成双线程有9个单位时间分隔。
-
这种情况有助于像磁带驱动器这样的设备,这些设备尽可能快写入数据的条件下会动作得更快(鱼贯模式)。
例:双缓冲区仅仅是生产者-消费者问题中的一个特例,处理任意数量的缓冲区,而不是双缓冲区。
#define NBUFF 8
struct { /* 生产者和消费者共享的数据 */
struct {
char data[BUFFSIZE]; /* 缓冲器 */
ssize_t n; /*缓冲区中的字节数*/
} buff[NBUFF]; /* 这些缓冲区计数的NBUFF */
sem_t mutex, nempty, nstored; /* 信号量,而不是指针*/
} shared;
int fd; /* 要复制到标准输出的输入文件 */
void *produce(void *), *consume(void *);
int main(int argc, char **argv)
{
pthread_t tid_produce, tid_consume;
if (argc != 2)
err_quit("usage: mycat2 <pathname>");
fd = Open(argv[1], O_RDONLY);
/*初始化三个信号量*/
Sem_init(&shared.mutex, 0, 1);
Sem_init(&shared.nempty, 0, NBUFF);
Sem_init(&shared.nstored, 0, 0);
/* 一个生产者线程,一个消费者线程*/
Set_concurrency(2);
Pthread_create(&tid_produce, NULL, produce, NULL); /* 读卡器线程 */
Pthread_create(&tid_consume, NULL, consume, NULL); /* 编写器线程 */
Pthread_join(tid_produce, NULL);
Pthread_join(tid_consume, NULL);
Sem_destroy(&shared.mutex);
Sem_destroy(&shared.nempty);
Sem_destroy(&shared.nstored);
exit(0);
}
//生产者
void *produce(void *arg)
{
int i;
for (i = 0; ; ) {
Sem_wait(&shared.nempty); /*等待至少1个空插槽*/
Sem_wait(&shared.mutex);
/*临界区域 */
Sem_post(&shared.mutex);
shared.buff[i].n = Read(fd, shared.buff[i].data, BUFFSIZE);
if (shared.buff[i].n == 0) {
Sem_post(&shared.nstored); /* 又存储了1个项目*/
return(NULL);
}
if (++i >= NBUFF)
i = 0; /*循环缓冲器 */
Sem_post(&shared.nstored); /*又存储了1个项目 */
}
}
void *consume(void *arg)
{
int i;
for (i = 0; ; ) {
Sem_wait(&shared.nstored); /*等待至少1个存储项 */
Sem_wait(&shared.mutex);
/*临界区域*/
Sem_post(&shared.mutex);
if (shared.buff[i].n == 0)
return(NULL);
Write(STDOUT_FILENO, shared.buff[i].data, shared.buff[i].n);
if (++i >= NBUFF)
i = 0; /* 循环缓冲器*/
sem_post(&shared.nempty); /*还有1个空插槽*/
}
}
九、进程间共享信号量
-
进程间共享基于内存信号量的规则:信号量本身(地址作为sem_init第一个参数的sem_t数据类型变量)必须驻留在由所有希望共享它的进程所共享的内存区中而且sem_init的第二个参数必须为1。
-
至于有名信号量,不同进程总是能够访问一个有名信号量,只要在调用sem_open时指定相同的名字就行。即使对于某个给定名字的sem_open调用在每个调用进程中可能返回不同的指针,使用该指针的信号量函数所引用的任然是同一个有名信号量。
-
在sem_open返回指向某个sem_t数据类型变量的指针后接着调用fork会怎么样?Posix.1表示在父进程中打开的任何信号量仍在子进程中打开。意味着下面代码正确。
sem_t *mutex;
mutex = sem_open(Px_ipc_name(NAME),O_CREAT|O_EXCL,FILE_MODE,0);
if((childpid = fork())==0){
...
sem_wait(mutex):
...
}
...
sem_post(mutex);
...
十、信号量的限制
-
SEM_NSEMS_MAX : 这是一个进程能够拥有的 POSIX 信号量的最大数目。
-
SEM_VALUE_MAX :这是一个 POSIX 信号量值能够取的最大值。信号量的取值可以为 0 到这个限制之间的任意一个值。
十一、Posix不同方法实现有名信号量
-
使用FIFO实现信号量。
-
使用内存映射I/O实现信号量。
-
使用System V信号量实现Posix信号量。
十二、POSIX 信号量与 System V 信号量比较
优点:
-
POSIX IPC 接口更加简单并且与传统的 UNIX 文件模型更加一致
-
POSIX IPC 对象是引用计数的,这样就简化了确定何时删除一个 IPC 对象的工作。
-
POSIX 命名信号量消除了 System V 信号量存在的初始化问题(首先,进程 B 在一个未初始化的信号量(即其值是一个任意值)上执行了一个 semop()。其次,进程 A 中的 semctl()调用覆盖了进程 B 所做出的变更)。
-
将一个 POSIX 未命名信号量与动态分配的内存对象关联起来更加简单:只需要将信号量嵌入到对象中即可。
-
在高度频繁地争夺信号量的场景中,那么 POSIX 信号量的性能与System V 信号量的性能是类似的。但在争夺信号量不那么频繁的场景中,POSIX 信号量的性能要比 System V 信号量好很多。POSIX 在这种场景中之所以能够做得更好是因为它们的实现方式只有在发生争夺的时候才需要执行系统调用,而 System V 信号量操作则不管是否发生争夺都需要执行系统调用。
缺点:
- POSIX 信号量的可移植性稍差
- POSIX 信号量不支持 System V 信号量中的撤销特性。
十三、POSIX 信号量与 Pthreads 互斥体