安装cuda8.0之前安装好nvidia的显卡驱动,下载好cuda8.0版本的,网址:https://developer.nvidia.com/cuda-80-ga2-download-archive.
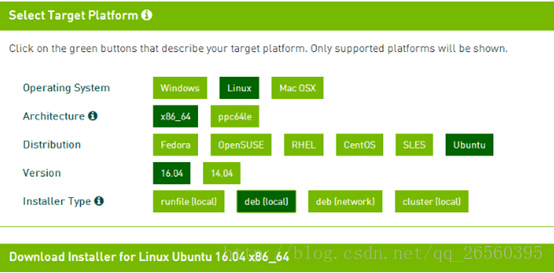
1.1
安装命令:
sudo dpkg -i cuda-repo-ubuntu1604-8-0-rc_8.0.27-1_amd64.deb
sudo apt-get update
sudo apt-get install cuda#出现问题手敲
1.2
可降级可不降级,根据情况而定:
ubuntu的gcc编译器是5.4.0,然而cuda8.0不支持5.0以上的编译器,因此需要降级,把编译器版本降到4.9:
在terminal中执行:
sudo apt-get install gcc-4.9 gcc-5 g++-4.9 g++-5
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 20
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 10
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 20
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 10
sudo update-alternatives --install /usr/bin/cc cc /usr/bin/gcc 30
sudo update-alternatives --set cc /usr/bin/gcc
sudo update-alternatives --install /usr/bin/c++ c++ /usr/bin/g++ 30
sudo update-alternatives --set c++ /usr/bin/g++
1.3添加环境变量
执行命令:
sudo gedit /etc/profile
添加内容如下:
PATH=/usr/local/cuda-8.0/bin:$PATH
export PATH
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:/lib
保存并退出
然后使之立刻生效
执行命令:
source /etc/profile
1.4添加lib库路径
执行命令:
sudo gedit /etc/ld.so.conf.d/cuda.conf
添加如下内容:
/usr/local/cuda-8.0/lib64
保存并退出
然后使之立刻生效
执行命令:
sudo ldconfig
1.5验证安装:先重启
执行命令:
nvcc -V
2接下来是安装cudnn:
首先在https://developer.nvidia.com/cudnn官网上下载(注意版本,必须是5.1)
2.1解压:
tar zxvf cudnn-8.0-linux-x64-v5.1.tgz
2.2然后执行
cd cuda
sudo cp lib64/lib* /usr/local/cuda/lib64/
sudo cp include/cudnn.h /usr/local/cuda/include/
2.3会出现cuda这个文件夹,更新链接。
cd /usr/local/cuda/lib64/
sudo rm -rf libcudnn.so libcudnn.so.5
sudo ln -s libcudnn.so.5.1.10 libcudnn.so.5
sudo ln -s libcudnn.so.5 libcudnn.so
3-cuda8.0和cudnn5.1V就装好了,然后就是安装pyenv和pyenv install anaconda2/3,再pip install tensorflow/pytorch等等.参考我的其他博客。
借鉴:https://www.cnblogs.com/xujianqing/p/6142963.html
http://blog.csdn.net/binglel/article/details/70230276