在概率密度估计过程中,如果我们队随机变量的分布是已知的,那么可以直接使用参数估计的方法进行估计,如最大似然估计方法。
然而在实际情况中,随机变量的参数是未知的,因此需要进行非参数估计.核密度估计是非参数估计的一种方法,也就是大家经常听见的parzen 窗方法了.
本文主要介绍 非参数估计的过程以及 parzen窗方法估计概率密度的过程.
非参数估计
过程

如图1所示,对于一个未知的概率密度函数
p
(
x
)
p(x)
p(x),某一个随机变量
x
x
x落在区域
R
R
R里的概率可以表示成如下形式:
P
=
∫
R
P
(
x
′
)
d
x
′
(1)
P = \int_{R} P(x^{'}) dx^{'} \tag{1}
P=∫RP(x′)dx′(1)
如果
R
R
R足够窄,我们可以用
P
P
P来表示
p
(
x
)
p(x)
p(x)的一个平均后的结果。假设我们现在有
n
n
n个样本,
且他们服从独立同分布,那么
n
n
n个样本中的
k
k
k个落在区域
R
R
R中的概率可以表示成下面的公式:
P
k
=
C
n
k
P
k
(
1
−
P
)
n
−
k
(2)
P_k = C_n^k P^k (1-P)^{n-k} \tag{2}
Pk=CnkPk(1−P)n−k (2)
由上面的公式我们可以得到
k
k
k的期望为:
E
(
k
)
=
n
⋅
P
(3)
E(k) = n \cdot P \tag{3}
E(k)=n⋅P (3)
同时,当
n
n
n足够大时,我们可以近似地认为
k
n
\frac{k}{n}
nk可以作为
P
P
P的一个近似值。
然后,假设
n
n
n足够大,
R
R
R足够小,并且假设
p
(
x
)
p(x)
p(x)是连续的,那么我们可以得到:
∫
R
P
(
x
′
)
d
x
′
≈
p
(
x
)
⋅
V
(4)
\int_{R} P(x^{'}) dx^{'} \approx p(x) \cdot V \tag{4}
∫RP(x′)dx′≈p(x)⋅V (4)
其中
x
x
x是区域
R
R
R中的一个点,
V
V
V是
R
R
R的面积(体积),结合上述4个式子,得:
p
(
x
)
V
=
∫
R
p
(
x
′
)
d
x
′
=
P
=
E
(
k
)
n
(5)
p(x)V = \int_{R} p(x^{'}) dx^{'} = P = \frac{E(k)}{n} \tag{5}
p(x)V=∫Rp(x′)dx′=P=nE(k)(5)
∴
p
(
x
)
=
E
(
k
)
n
⋅
V
≈
k
n
⋅
V
(6)
\therefore p(x) = \frac{E(k)}{n \cdot V} \approx \frac{k}{n \cdot V} \tag{6}
∴p(x)=n⋅VE(k)≈n⋅Vk (6)
因此,某一小区域内的概率密度函数就可以用上述公式表示了。
问题
我们再看一下公式(6):
p
(
x
)
≈
k
/
n
V
≈
P
V
=
∫
R
p
(
x
′
)
d
x
′
∫
R
d
x
′
(7)
p(x) \approx \frac{k/n}{V} \approx \frac{P}{V} = \frac{\int_{R} p(x^{'})d{x^{'}}}{\int_{R}dx{'}} \tag{7}
p(x)≈Vk/n≈VP=∫Rdx′∫Rp(x′)dx′ (7)
显然我们估计的这个概率密度是一个平滑的结果,即当
V
V
V选择的越大,估计的结果和真实结果相比就越平滑;因此看起来我们需要把
V
V
V设置的小一点,然而如果我们把
V
V
V选择的过小,也会出现问题:太小的
V
V
V会导致这块小区域里面没有一个点落在里面,因此就会得到该点的概率密度为0;另外,假设刚好有一个点落在了这个小区域里,那由于V过于小,我们计算得到的概率密度可能也会趋近于无穷,两个结果对于我们来说都是没有太大意义的.
从 实际的角度来看,我们获取的数据量一定是有限的,因此体积
V
V
V不可能取到无穷小,我们可以总结下,使用非参数概率密度估计有以下两方面限制,且是不可避免的:
- 在有限数据下,使用非参数估计方法计算的概率密度一定是真实概率密度平滑后的结果.
- 在有限数据下,体积趋于无穷小计算的概率密度没有意义.
从 理论的角度来看,我们希望知道如果有无限多的采样数据,那么上述两个限制条件应该怎样克服?假设我们使用下面的方法来估计点
x
x
x 处的概率密度: 构造一系列包含
x
x
x 的区域
R
1
,
R
2
,
.
.
.
R
n
R_1, R_2, ... R_n
R1,R2,...Rn, 其中
R
1
R_1
R1 中包含一个样本,
R
n
R_n
Rn中包含
n
n
n 个样本.则:
p
n
(
x
)
=
k
n
/
n
V
n
(8)
p_n(x) = \frac{k_n / n}{V_n} \tag{8}
pn(x)=Vnkn/n(8)
其中
p
n
(
x
)
p_n(x)
pn(x)表示第
n
n
n次估计结果,如果要求
p
n
(
x
)
p_n(x)
pn(x)能够收敛到
p
(
x
)
p(x)
p(x),则需要满足下面三个条件:
-
lim
n
→
∞
V
n
=
0
\lim_{n \rightarrow \infty} V_n = 0
limn→∞Vn=0
-
lim
n
→
∞
k
n
=
∞
\lim_{n \rightarrow \infty} k_n = \infty
limn→∞kn=∞
-
lim
n
→
∞
k
n
/
n
=
0
\lim_{n \rightarrow \infty} k_n / n = 0
limn→∞kn/n=0
parzen窗法
原理
假设
R
n
R_n
Rn是一个
d
d
d维的超立方体(hypercube),且其边长为
h
h
h, 那么我们可以用如下公式表示
V
n
V_n
Vn:
V
n
=
h
n
d
(9)
V_n = h_n^d \tag{9}
Vn=hnd(9)
然后我们再定义一个窗函数(window function):
φ
(
u
)
=
{
1
∣
u
j
∣
≤
1
/
2
0
o
t
h
e
r
w
i
s
e
(10)
\varphi (u) = \begin{cases} 1 \quad |u_j| \leq 1/2 \\ 0 \quad otherwise \end{cases} \quad \tag{10}
φ(u)={1∣uj∣≤1/20otherwise(10)
φ
\varphi
φ 定义了一个以圆点为中心的单位超立方体,这样我们就可以用
φ
\varphi
φ来表示体积
V
V
V内的样本个数:
k
n
=
∑
i
=
1
n
φ
(
x
−
x
i
h
n
)
(11)
k_n = \sum_{i=1}^{n} \varphi(\frac{x - x_i}{h_n}) \tag{11}
kn=i=1∑nφ(hnx−xi)(11)
好了,有了
k
n
k_n
kn和
V
n
V_n
Vn,直接把他们带入公式(6),我们可以得到parzen窗法的计算公式:
p
n
(
x
)
=
1
n
∑
i
=
1
n
1
V
n
φ
(
x
−
x
i
h
n
)
(12)
p_n(x) = \frac{1}{n} \sum_{i=1}^{n} \frac{1}{V_n} \varphi(\frac{x - x_i}{h_n}) \tag{12}
pn(x)=n1i=1∑nVn1φ(hnx−xi)(12)
我们发现这个
φ
\varphi
φ不仅可以是上述的单位超立方体的形式,只要其满足如下两个约束就可以,因此也就出现了各种各样更能表现样本属性的窗函数,比如用的非常多的高斯窗.
-
φ
(
x
)
≥
0
\varphi(x) \geq 0
φ(x)≥0
-
∫
φ
(
u
)
d
u
=
1
\int \varphi(u)du = 1
∫φ(u)du=1
解释
网上经常会见到这样的解释: 某一点的概率密度是其他样本点在这一点的概率密度分布的平均值.还有这样一张图:

上面一句话可以这样解释:
我们定义核函数:
δ
(
x
)
=
1
V
n
φ
(
x
h
n
)
(13)
\delta(x) = \frac{1}{V_n} \varphi(\frac{x}{h_n}) \tag{13}
δ(x)=Vn1φ(hnx)(13)
那么某一点
x
x
x的概率密度可以用如下函数来表示:
p
n
(
x
)
=
1
n
∑
i
=
1
n
δ
n
(
x
−
x
i
)
(14)
p_n(x) = \frac{1}{n} \sum_{i=1}^{n} \delta_{n}(x - x_i) \tag{14}
pn(x)=n1i=1∑nδn(x−xi)(14)
从公式(13)(14)我们可以看出,当
h
n
h_n
hn很大的时候,
δ
n
(
x
)
\delta_n(x)
δn(x)就是一个 矮胖的函数,由公式(14)将每个样本点在点
x
x
x处的贡献取平均之后,点
x
x
x处的概率密度就是一个非常平滑的结果; 当
h
n
h_n
hn太小的时候,
δ
n
(
x
)
\delta_n(x)
δn(x)就是一个 高瘦的函数,由公式(14)将每个样本点在点
x
x
x处的贡献取平均之后,点
x
x
x处的概率密度就是一个受噪声影响非常大的值,因此估计的概率密度平滑性就很差,反而和真实值差的很远.这两点和1.2节总结的两点缺陷正好吻合.
仿真实验
如下我做了两个仿真
- 第一个是生成了均值是0,方差是2的服从高斯分布的数据,分别使用bandwidth为0.1, 1, 5三个值进行估计
- 第二个是生成了100个服从高斯混合分布的数据,分别是均值为0,方差为1以及均值为5,方差为1的两个高斯混合模型,两者相互独立。
这里核函数选的是高斯核。
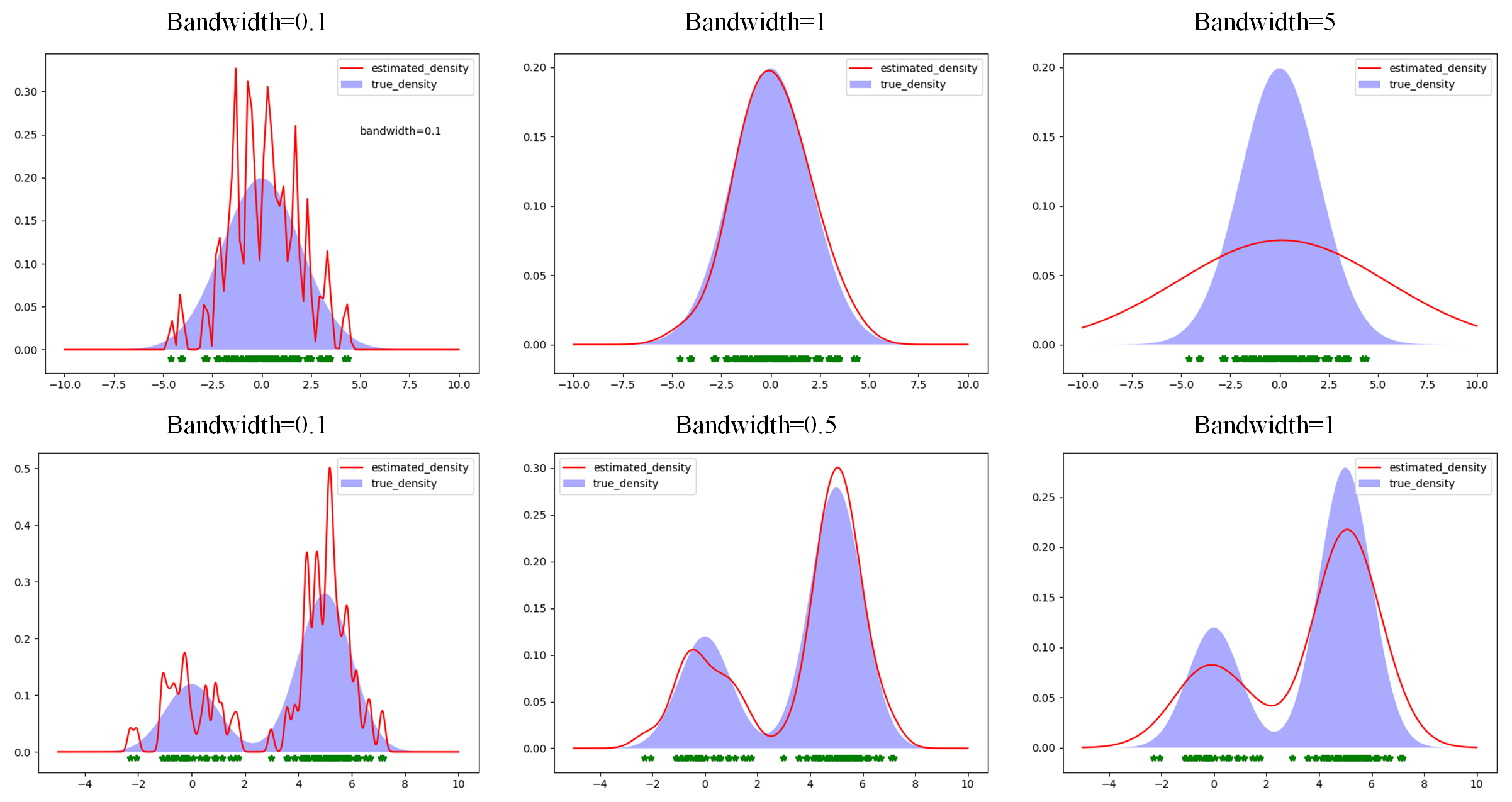
可以很明显得看到估计的概率密度是如何受到bandwidth影响的,当bandwidth选择的太小,则估计的密度函数受到噪声影响很大,这种结果是不能用的;当bandwidth选择过大,则估计的概率密度又太过于平滑。总之,无论bandwidth过大还是过小,其结果都和实际情况相差的很远,因此合理地选择bandwidth是很重要的。
下面是高斯混合分布密度估计的代码。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.neighbors.kde import KernelDensity
from scipy.stats import norm
if __name__ == "__main__":
np.random.seed(1)
x = np.concatenate((np.random.normal(0, 1, int(0.3*100)), np.random.normal(5, 1, int(0.7*100))))[:, np.newaxis]
plot_x = np.linspace(-5, 10, 1000)[:, np.newaxis]
true_dens = 0.3*norm(0, 1).pdf(plot_x) + 0.7*norm(5, 1).pdf(plot_x)
log_dens = KernelDensity(bandwidth=1).fit(x).score_samples(plot_x)
plt.figure(),
plt.fill(plot_x, true_dens, fc='#AAAAFF', label='true_density')
plt.plot(plot_x, np.exp(log_dens), 'r', label='estimated_density')
for _ in range(x.shape[0]):
plt.plot(x[:, 0], np.zeros(x.shape[0])-0.01, 'g*')
plt.legend()
plt.show()
参考资料
[1.] sklearn:Simple 1D Kernel Density Estimation
[2.] Richard O. Duda, Peter E. Hart, and David G. Stork. 2000. Pattern Classification (2nd Edition). Wiley-Interscience, New York, NY, USA.
[3. ]Kernel density estimation
[4.] 边肇祺, 张学工, 2000. 模式识别. 清华大学出版社.