难度:⭐️⭐️(递归)/⭐️⭐️⭐️⭐️(迭代)
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]

返回 true 。
方法1:递归(自上而下)

class Solution {
public:
int height(TreeNode* root) {
if (root == NULL) {
return 0;
} else {
return max(height(root->left), height(root->right)) + 1;
}
}
bool isBalanced(TreeNode* root) {
if (root == NULL) {
return true;
} else {
return abs(height(root->left) - height(root->right)) <= 1 && isBalanced(root->left) && isBalanced(root->right);
}
}
};

方法2:递归(自下而上)

class Solution {
public:
int height(TreeNode* root) {
if (root == NULL) {
return 0;
}
int leftHeight = height(root->left);
int rightHeight = height(root->right);
if (leftHeight == -1 || rightHeight == -1 || abs(leftHeight - rightHeight) > 1) {
return -1;
} else {
return max(leftHeight, rightHeight) + 1;
}
}
bool isBalanced(TreeNode* root) {
return height(root) >= 0;
}
};

方法3:迭代(自上而下)
在104.二叉树的最大深度 (opens new window)中我们可以使用层序遍历来求深度,但是就不能直接用层序遍历来求高度了,这就体现出求高度和求深度的不同。
本题的迭代方式可以先定义一个函数,专门用来求高度。
这个函数通过栈模拟的后序遍历找每一个节点的高度(其实是通过求传入节点为根节点的最大深度来求的高度)
代码如下:
// cur节点的最大深度,就是cur的高度
int getDepth(TreeNode* cur) {
stack<TreeNode*> st;
if (cur != NULL) st.push(cur);
int depth = 0; // 记录深度
int result = 0;
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
st.push(node); // 中
st.push(NULL);
depth++;
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
} else {
st.pop();
node = st.top();
st.pop();
depth--;
}
result = result > depth ? result : depth;
}
return result;
}
然后再用栈来模拟后序遍历,遍历每一个节点的时候,再去判断左右孩子的高度是否符合,代码如下:
bool isBalanced(TreeNode* root) {
stack<TreeNode*> st;
if (root == NULL) return true;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
if (abs(getDepth(node->left) - getDepth(node->right)) > 1) { // 判断左右孩子高度是否符合
return false;
}
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return true;
}
整体代码如下:
class Solution {
private:
int getDepth(TreeNode* cur) {
stack<TreeNode*> st;
if (cur != NULL) st.push(cur);
int depth = 0; // 记录深度
int result = 0;
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
st.push(node); // 中
st.push(NULL);
depth++;
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
} else {
st.pop();
node = st.top();
st.pop();
depth--;
}
result = result > depth ? result : depth;
}
return result;
}
public:
bool isBalanced(TreeNode* root) {
stack<TreeNode*> st;
if (root == NULL) return true;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
if (abs(getDepth(node->left) - getDepth(node->right)) > 1) {
return false;
}
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return true;
}
};
当然此题用迭代法,其实效率很低,因为没有很好的模拟回溯的过程,所以迭代法有很多重复的计算。
虽然理论上所有的递归都可以用迭代来实现,但是有的场景难度可能比较大。
例如:都知道回溯法其实就是递归,但是很少人用迭代的方式去实现回溯算法!
因为对于回溯算法已经是非常复杂的递归了,如果再用迭代的话,就是自己给自己找麻烦,效率也并不一定高。
时间复杂度:平均O(nlogn) 最坏O(n2) 空间O(n)
实现代码:递归(自上而下)/递归(自下而上)/迭代(自上而下)
难度:⭐️⭐️⭐️
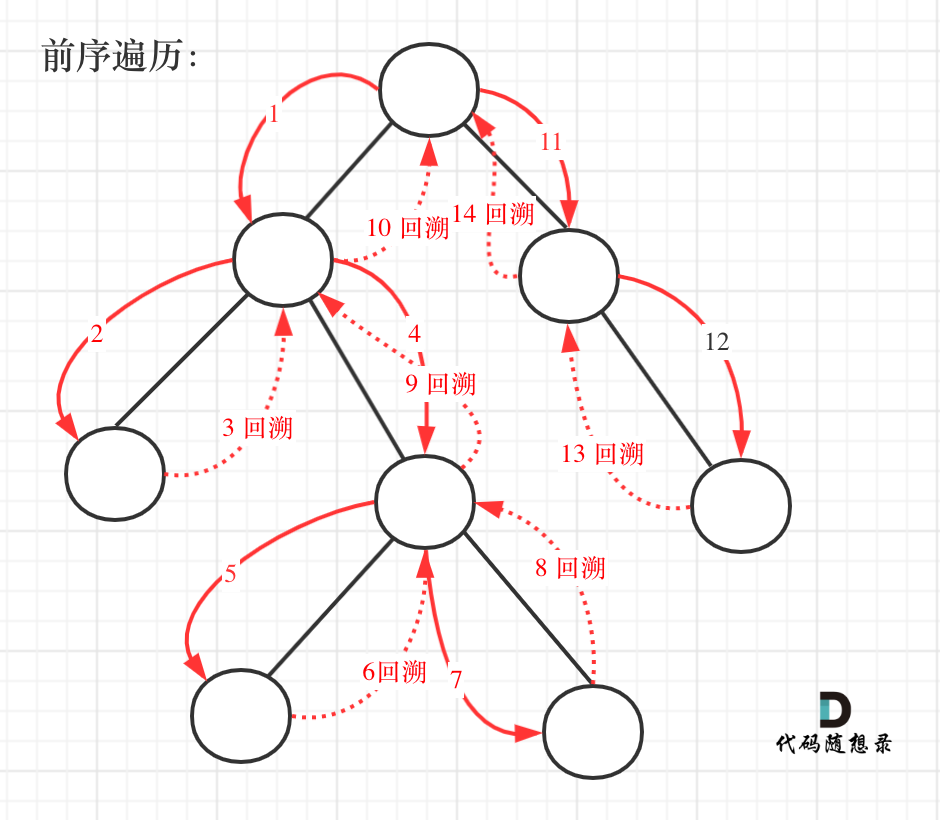
代码:递归+回溯/迭代(前序)/迭代(层序)
难度:⭐️⭐️
计算给定二叉树的所有左叶子之和。
示例:

思路:
左叶子的明确定义:节点A的左孩子不为空,且左孩子的左右孩子都为空(说明是叶子节点),那么A节点的左孩子为左叶子节点
那么判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。
如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子,判断代码如下:
if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {
左叶子节点处理逻辑
}
平时我们解二叉树的题目时,已经习惯了通过节点的左右孩子判断本节点的属性,而本题我们要通过节点的父节点判断本节点的属性。
代码:递归/迭代(前序一路遍历到底)/迭代(前序每次遍历时放入左右孩子)
难度:⭐️⭐️(迭代)/⭐️⭐️⭐️(递归)
给定一个二叉树,在树的最后一行找到最左边的值。
示例 1:

递归终止条件:
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。
代码如下:
if (root->left == NULL && root->right == NULL) {
if (depth > maxDepth) {
maxDepth = depth; // 更新最大深度
result = root->val; // 最大深度最左面的数值
}
return;
}
代码:迭代/递归
难度:⭐️⭐️
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22,

返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先 (opens new window)中介绍)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示:
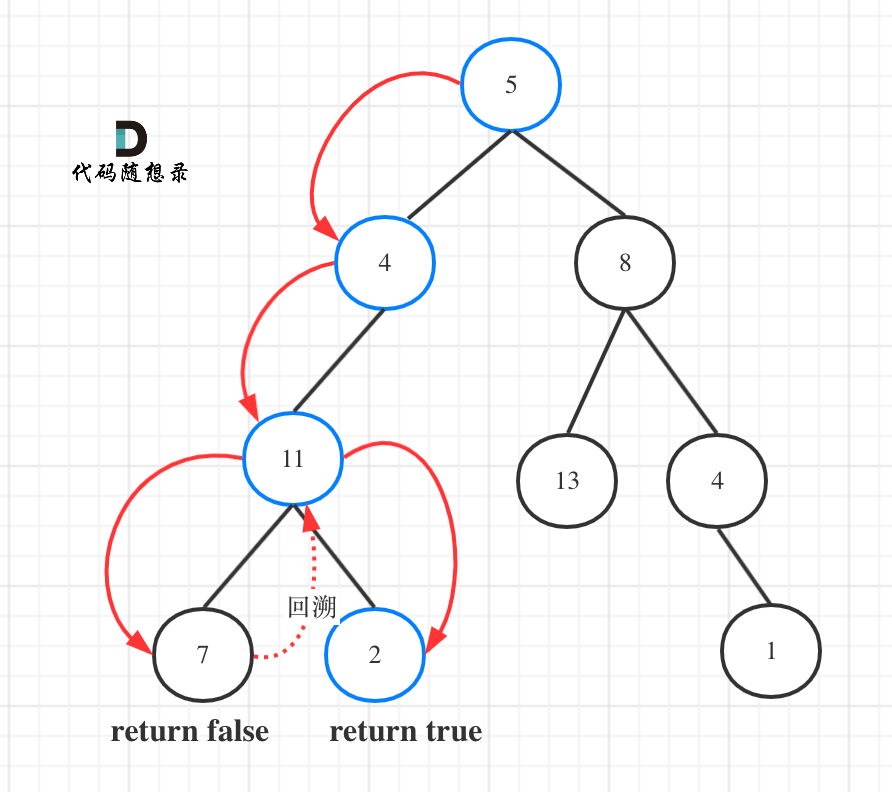
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
所以代码如下:
bool traversal(treenode* cur, int count) // 注意函数的返回类型
代码:递归/迭代
难度:⭐️⭐️⭐️⭐️
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22,
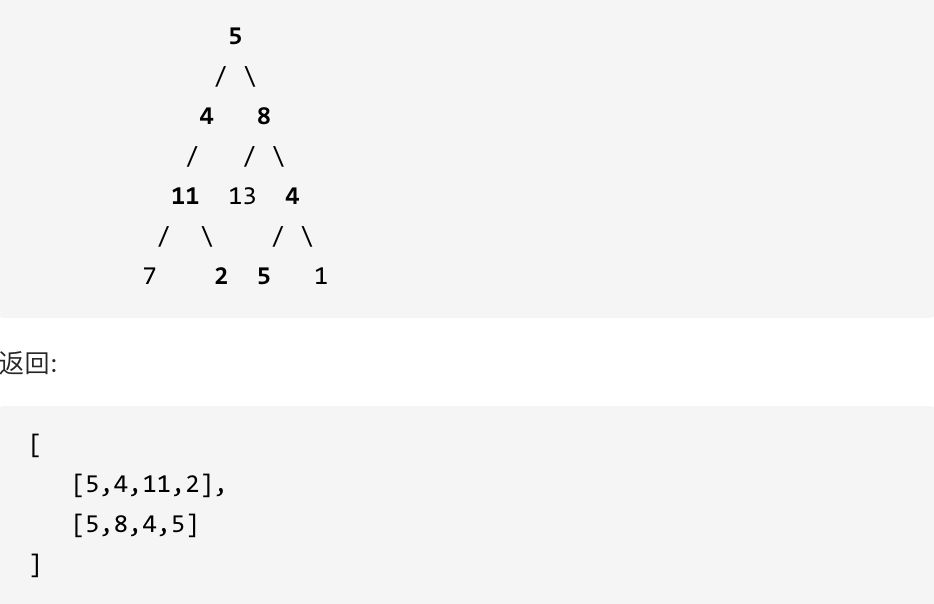
代码:递归/迭代
难度:⭐️⭐️⭐️⭐️
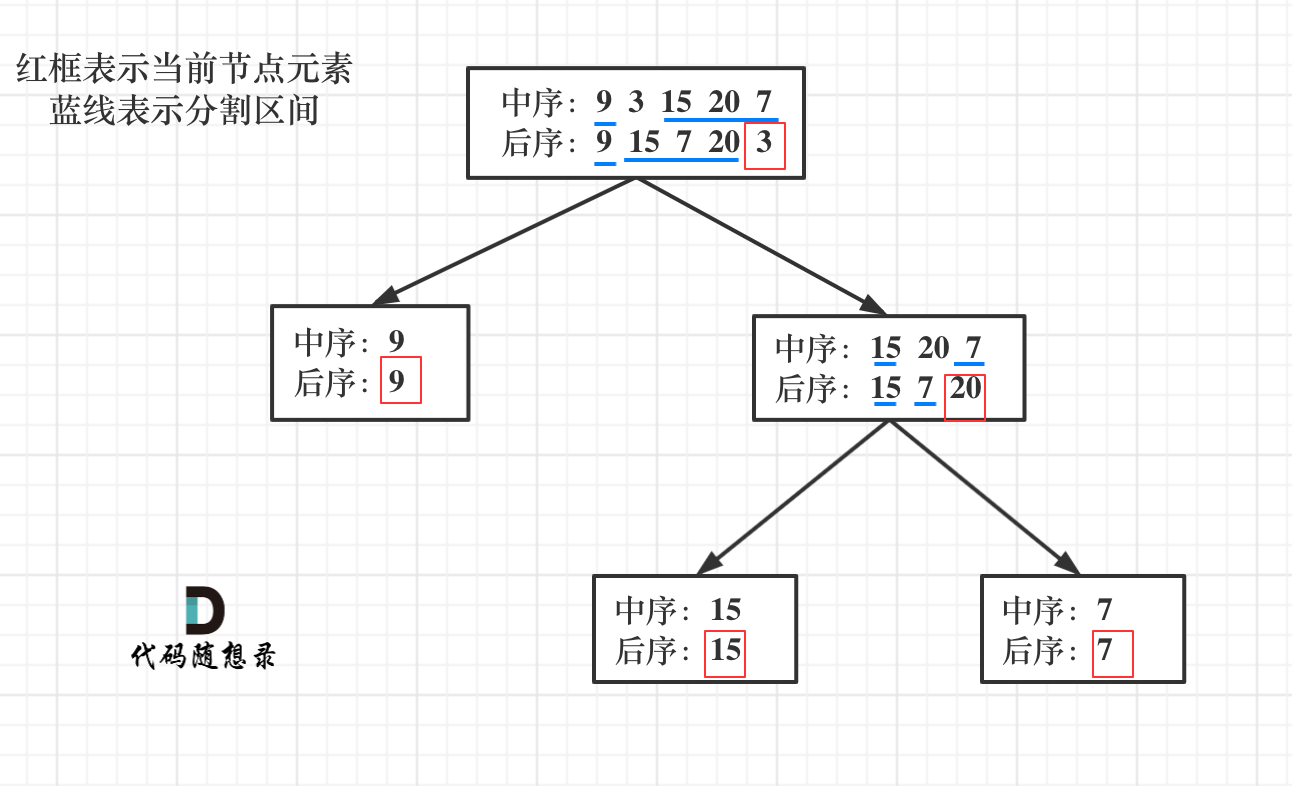
那么代码应该怎么写呢?
说到一层一层切割,就应该想到了递归。
来看一下一共分几步:
-
第一步:如果数组大小为零的话,说明是空节点了。
-
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
-
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
-
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
-
第五步:切割后序数组,切成后序左数组和后序右数组
-
第六步:递归处理左区间和右区间
代码:递归(数组)/递归(数组索引)/递归(数组索引+哈希)
难度:⭐️⭐️⭐️⭐️
根据一棵树的前序遍历与中序遍历构造二叉树。
注意: 你可以假设树中没有重复的元素。
例如,给出
前序遍历 preorder = [3,9,20,15,7] 中序遍历 inorder = [9,3,15,20,7] 返回如下的二叉树:

本题和106是一样的道理。
我就直接给出代码了。
代码:递归(数组索引+哈希)
前序和中序可以唯一确定一棵二叉树。
后序和中序可以唯一确定一棵二叉树。
那么前序和后序可不可以唯一确定一棵二叉树呢?
前序和后序不能唯一确定一棵二叉树!,因为没有中序遍历无法确定左右部分,也就是无法分割。
举一个例子:
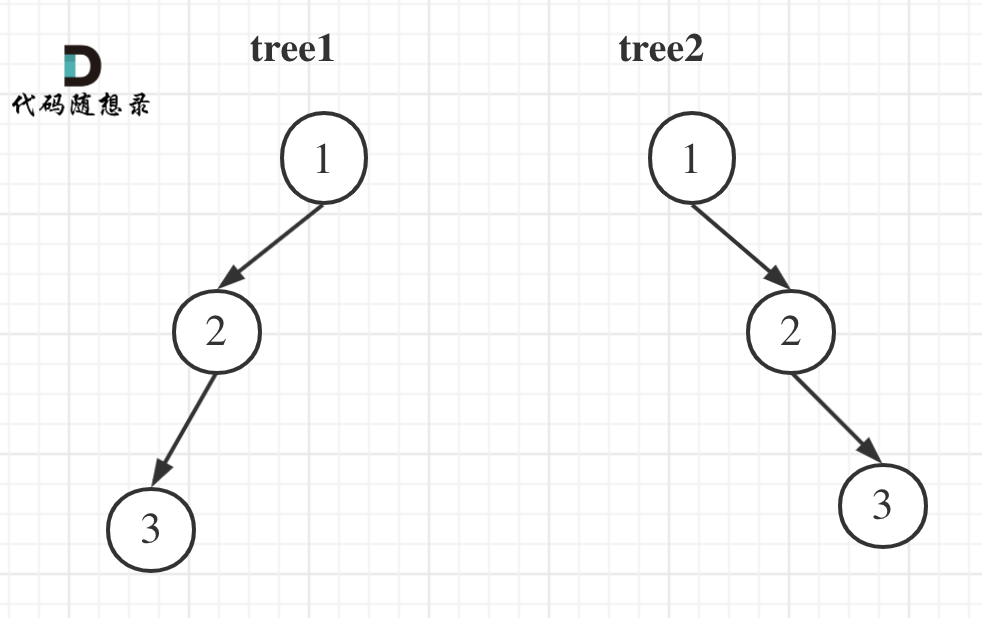
tree1 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
所以前序和后序不能唯一确定一棵二叉树!
代码:递归(数组索引+哈希表)
难度:⭐️⭐️⭐️
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :

提示:
给定的数组的大小在 [1, 1000] 之间。
这道题整体思路和上一道构造二叉树的题目类似。
代码:递归/单调栈(待补充)
难度:⭐️⭐️⭐️
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:

注意: 合并必须从两个树的根节点开始。
代码:递归/迭代/递归(指针的指针)
难度:⭐️
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,

在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
这就决定了,二叉搜索树,递归遍历和迭代遍历和普通二叉树都不一样。
代码:递归/迭代
难度:⭐️⭐️⭐️
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。

要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。
这道题目比较容易陷入两个陷阱:
不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。
写出了类似这样的代码:
if (root->val > root->left->val && root->val < root->right->val) {
return true;
} else {
return false;
}
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。所以以上代码的判断逻辑是错误的。
例如: [10,5,15,null,null,6,20] 这个case:
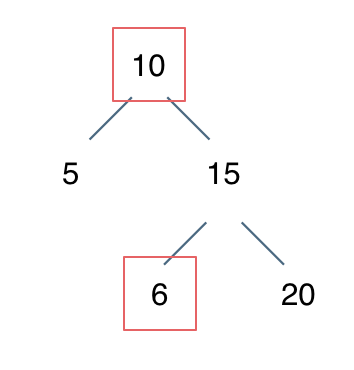
节点10大于左节点5,小于右节点15,但右子树里出现了一个6 这就不符合了!
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值。
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?文中会解答。
如果测试数据中有 longlong的最小值,怎么办?
不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
代码如下:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};
最后这份代码看上去整洁一些,思路也清晰。
代码:递归/递归+数组/迭代
难度:⭐️⭐️
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
示例:

提示:树中至少有 2 个节点。
代码:递归+数组/递归+双指针/迭代+双指针
难度:⭐️⭐️(迭代/递归)/⭐️⭐️⭐️(morris)
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
假定 BST 有如下定义:
- 结点左子树中所含结点的值小于等于当前结点的值
- 结点右子树中所含结点的值大于等于当前结点的值
- 左子树和右子树都是二叉搜索树
例如:
给定 BST [1,null,2,2],

返回[2].
提示:如果众数超过1个,不需考虑输出顺序
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
既然是搜索树,它中序遍历就是有序的。
如图:
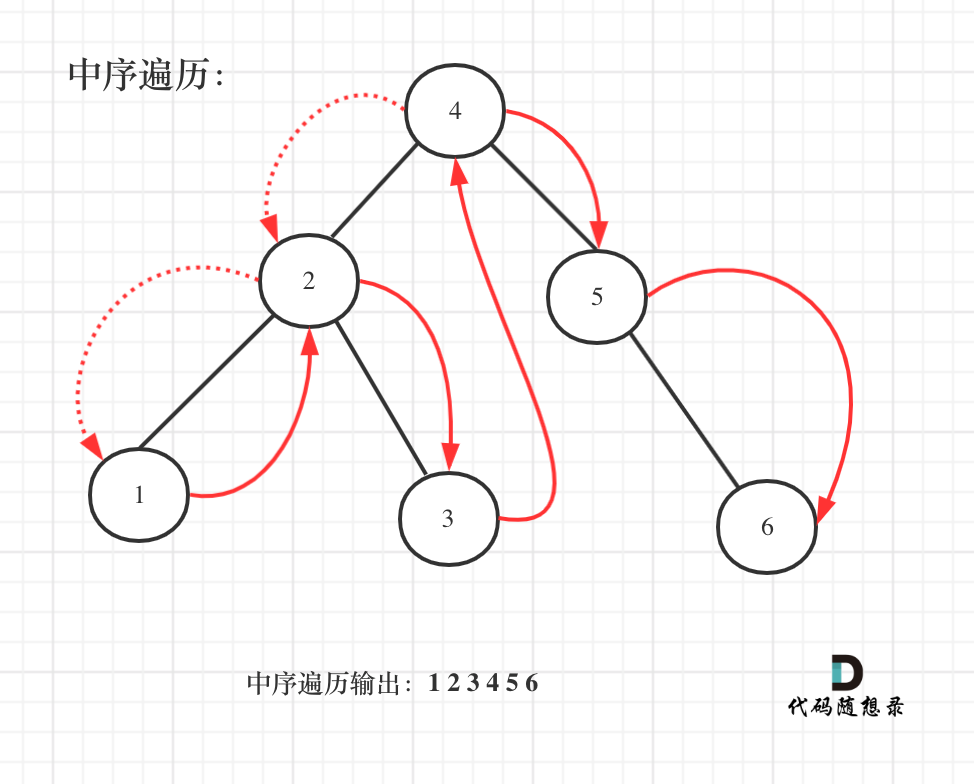
代码:递归+哈希/递归+双指针/迭代+双指针/迭代+morris+双指针
补充:morris时间复杂度为O(n)推导

以下为推理过程概述: 1.对于左右一边倒的二叉搜索树,很容易求得时间复杂度为O(n)
2.对于均匀分布的二叉搜索树(类似完全二叉树),倒数第二层有n/4个节点,Morris遍历时最多往下遍历一层(左子树的最右结点);倒数第三层有n/8个节点,Morris遍历时最多往下遍历两层(左子树最右结点),以此类推。。
所以morris遍历predecessor这部分的总时间复杂度: T(n)=(n/4)*1 +(n/8)2+...+1(logn) 令n=n/2 T(n/2)=(n/8)*1 +(n/16)2+...+(1/2)(logn) 两式相减,得 T(n/2)=(n/4)1 +(n/8)1+(n/16)1+...+(1)1-(1/2)(logn) =[(n/4)(1-(1/2)^(logn -1)]/(1-1/2) -(1/2)(logn) =n/2 - (1/2)(logn) =O(n)

实际上,画出全部遍历predecessor轨迹后可以发现,每个节点最多被一条遍历轨迹覆盖(这条轨迹会遍历两次,即第一次和第二次经过middle结点时,都会向下遍历一次),因此morris遍历predecessor总时间复杂度<O(2n)=O(n)。
难度:⭐️⭐️⭐️⭐️
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
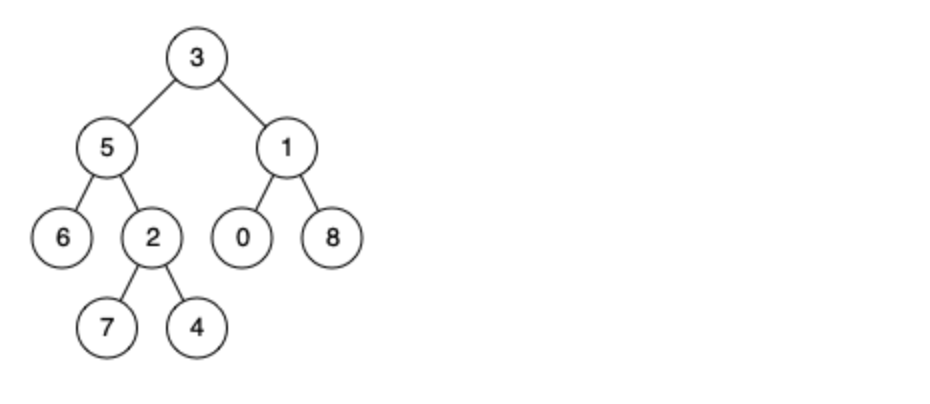
示例 1: 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出: 3 解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
示例 2: 输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出: 5 解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了。
那么二叉树如何可以自底向上查找呢?
回溯啊,二叉树回溯的过程就是从低到上。
后序遍历(左右中)就是天然的回溯过程,可以根据左右子树的返回值,来处理中节点的逻辑。
接下来就看如何判断一个节点是节点q和节点p的公共祖先呢。
首先最容易想到的一个情况:如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。 即情况一:

判断逻辑是 如果递归遍历遇到q,就将q返回,遇到p 就将p返回,那么如果 左右子树的返回值都不为空,说明此时的中节点,一定是q 和p 的最近祖先。
那么有录友可能疑惑,会不会左子树 遇到q 返回,右子树也遇到q返回,这样并没有找到 q 和p的最近祖先。
这么想的录友,要审题了,题目强调:二叉树节点数值是不重复的,而且一定存在 q 和 p。
但是很多人容易忽略一个情况,就是节点本身p(q),它拥有一个子孙节点q(p)。 情况二:

其实情况一 和 情况二 代码实现过程都是一样的,也可以说,实现情况一的逻辑,顺便包含了情况二。
因为遇到 q 或者 p 就返回,这样也包含了 q 或者 p 本身就是 公共祖先的情况。
这一点是很多录友容易忽略的,在下面的代码讲解中,可以再去体会。
代码:递归+回溯/递归+哈希表
难度:⭐️⭐️
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
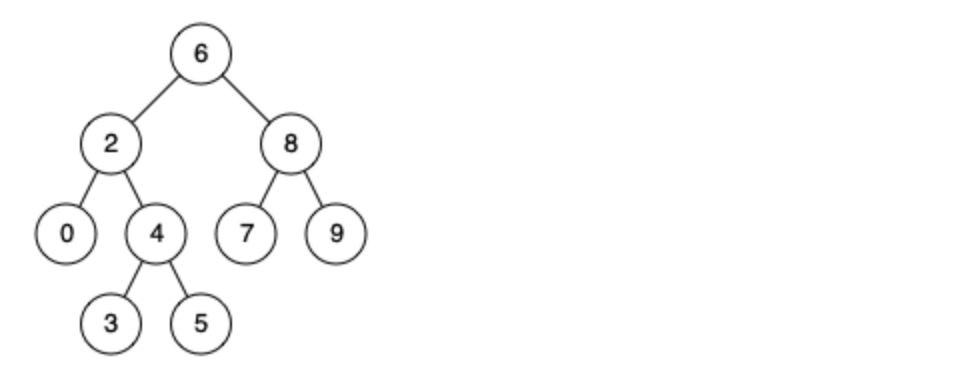
示例 1:
- 输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
- 输出: 6
- 解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
- 输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
- 输出: 2
- 解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
做过二叉树:公共祖先问题 (opens new window)题目的同学应该知道,利用回溯从底向上搜索,遇到一个节点的左子树里有p,右子树里有q,那么当前节点就是最近公共祖先。
那么本题是二叉搜索树,二叉搜索树是有序的,那得好好利用一下这个特点。
在有序树里,如果判断一个节点的左子树里有p,右子树里有q呢?
因为是有序树,所有 如果 中间节点是 q 和 p 的公共祖先,那么 中节点的数组 一定是在 [p, q]区间的。即 中节点 > p && 中节点 < q 或者 中节点 > q && 中节点 < p。
那么只要从上到下去遍历,遇到 cur节点是数值在[p, q]区间中则一定可以说明该节点cur就是q 和 p的公共祖先。 那问题来了,一定是最近公共祖先吗?
如图,我们从根节点搜索,第一次遇到 cur节点是数值在[p, q]区间中,即 节点5,此时可以说明 p 和 q 一定分别存在于 节点 5的左子树,和右子树中。
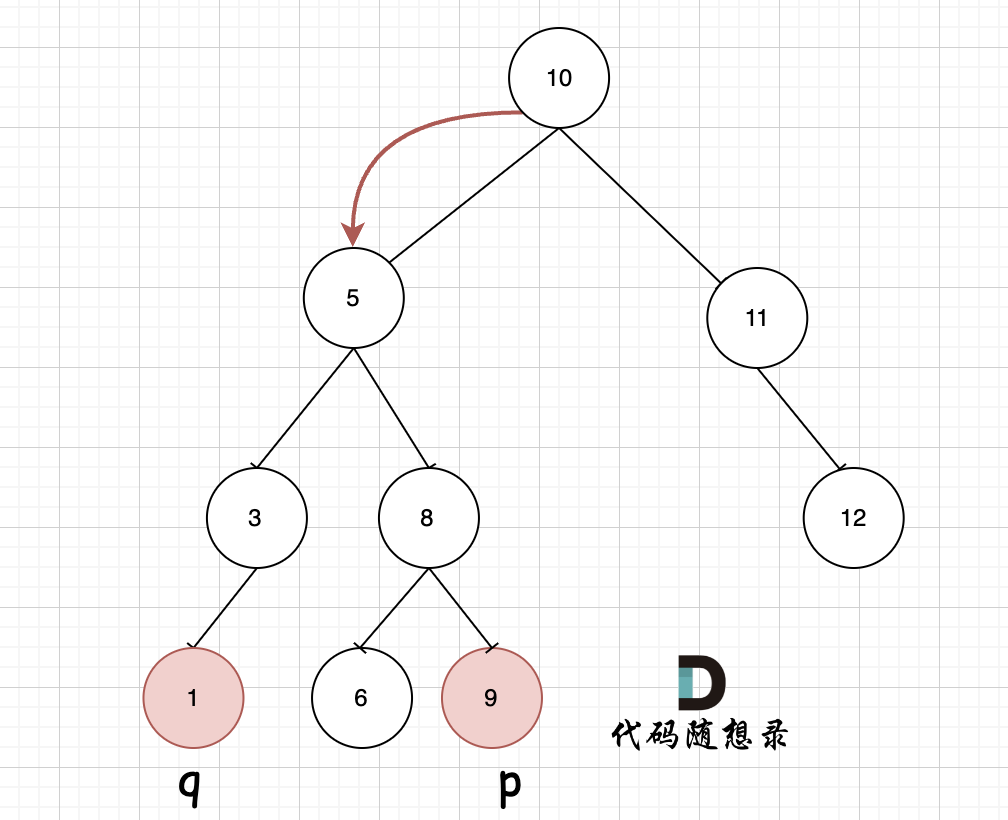
此时节点5是不是最近公共祖先? 如果 从节点5继续向左遍历,那么将错过成为q的祖先, 如果从节点5继续向右遍历则错过成为p的祖先。
所以当我们从上向下去递归遍历,第一次遇到 cur节点是数值在[p, q]区间中,那么cur就是 p和q的最近公共祖先。
理解这一点,本题就很好解了。
而递归遍历顺序,本题就不涉及到 前中后序了(这里没有中节点的处理逻辑,遍历顺序无所谓了)。
如图所示:p为节点6,q为节点9
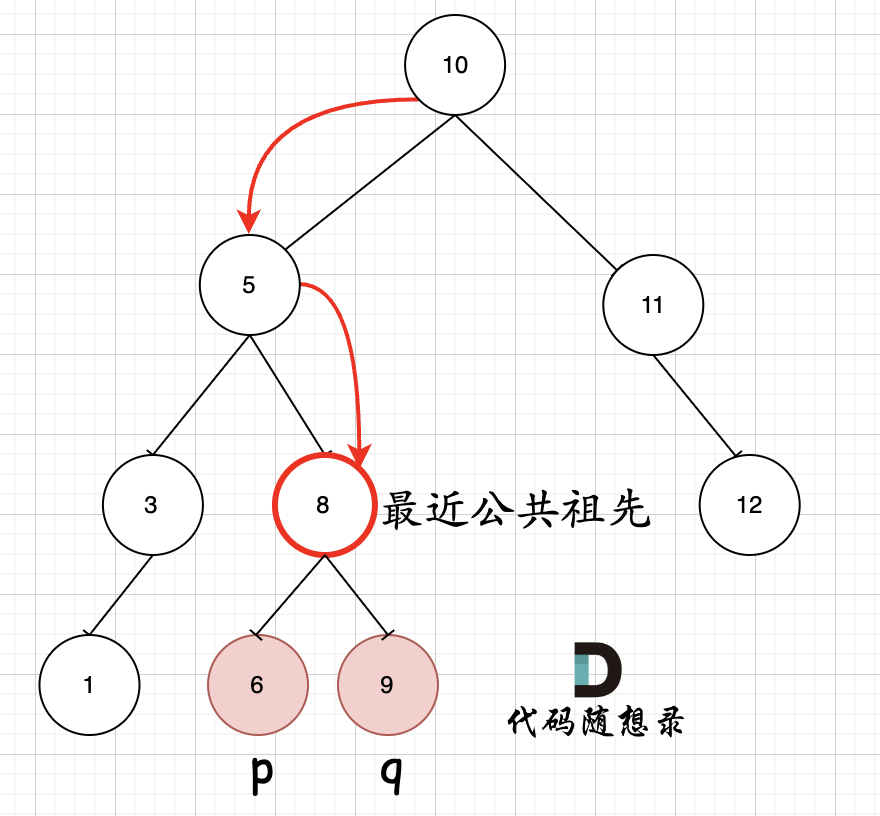
可以看出直接按照指定的方向,就可以找到节点8,为最近公共祖先,而且不需要遍历整棵树,找到结果直接返回!
代码:递归/迭代
难度:⭐️
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据保证,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。

提示:
- 给定的树上的节点数介于 0 和 10^4 之间
- 每个节点都有一个唯一整数值,取值范围从 0 到 10^8
- -10^8 <= val <= 10^8
- 新值和原始二叉搜索树中的任意节点值都不同
这道题目其实是一道简单题目,但是题目中的提示:有多种有效的插入方式,还可以重构二叉搜索树,一下子吓退了不少人,瞬间感觉题目复杂了很多。
其实可以不考虑题目中提示所说的改变树的结构的插入方式。
如下演示视频中可以看出:只要按照二叉搜索树的规则去遍历,遇到空节点就插入节点就可以了。

例如插入元素10 ,需要找到末尾节点插入便可,一样的道理来插入元素15,插入元素0,插入元素6,需要调整二叉树的结构么? 并不需要。。
只要遍历二叉搜索树,找到空节点 插入元素就可以了,那么这道题其实就简单了。
接下来就是遍历二叉搜索树的过程了。
代码:递归/迭代+双指针
难度:⭐️⭐️⭐️⭐️(拼接子树)/⭐️⭐️⭐️⭐️⭐️(交换节点后删除)
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
首先找到需要删除的节点; 如果找到了,删除它。 说明: 要求算法时间复杂度为 O(h),h 为树的高度。
示例:

方法1:拼接子树
这里就把二叉搜索树中删除节点遇到的情况都搞清楚。
有以下五种情况:
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了
- 找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
第五种情况有点难以理解,看下面动画:

动画中的二叉搜索树中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。
将删除节点(元素7)的左孩子放到删除节点(元素7)的右子树的最左面节点(元素8)的左孩子上,就是把5为根节点的子树移到了8的左孩子的位置。
要删除的节点(元素7)的右孩子(元素9)为新的根节点。.
这样就完成删除元素7的逻辑,最好动手画一个图,尝试删除一个节点试试。
方法2:交换节点后删除
这里我在介绍一种通用的删除,普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),用交换值的操作来删除目标节点。
代码中目标节点(要删除的节点)被操作了两次:
- 第一次是和目标节点的右子树最左面节点交换。
- 第二次直接被NULL覆盖了。
思路有点绕,感兴趣的同学可以画图自己理解一下。
代码如下:(关键部分已经注释)
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return root;
if (root->val == key) {
if (root->right == nullptr) { // 这里第二次操作目标值:最终删除的作用
return root->left;
}
TreeNode *cur = root->right;
while (cur->left) {
cur = cur->left;
}
swap(root->val, cur->val); // 这里第一次操作目标值:交换目标值其右子树最左面节点。
}
root->left = deleteNode(root->left, key);
root->right = deleteNode(root->right, key);
return root;
}
};
这个代码是简短一些,思路也巧妙,但是不太好想,实操性不强,推荐第一种写法!
//注:力扣官方题解中提供了另一种交换节点的思路,只需要交换一次(root和root->right's leftmost node),然后直接调用deleteNode(root->right, leftmost node->val)巧妙的将其删除(包含了如果leftmost node包含右孩子时的裁剪处理),这种方法不需要将root一直swap到叶子节点,只需要swap一次到root->right's leftmost node即可(无需考虑其是否包含右孩子)。具体代码见下方:递归+交换节点。
代码:递归+拼接子树/递归+交换节点/迭代+拼接子树/迭代+交换节点
难度:⭐️⭐️⭐️
给定一个二叉搜索树,同时给定最小边界L 和最大边界 R。通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) 。你可能需要改变树的根节点,所以结果应当返回修剪好的二叉搜索树的新的根节点。


直接想法就是:递归处理,然后遇到 root->val < low || root->val > high 的时候直接return NULL,一波修改,赶紧利落。
不难写出如下代码:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr || root->val < low || root->val > high) return nullptr;
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
然而[1, 3]区间在二叉搜索树的中可不是单纯的节点3和左孩子节点0就决定的,还要考虑节点0的右子树。
我们在重新关注一下第二个示例,如图:
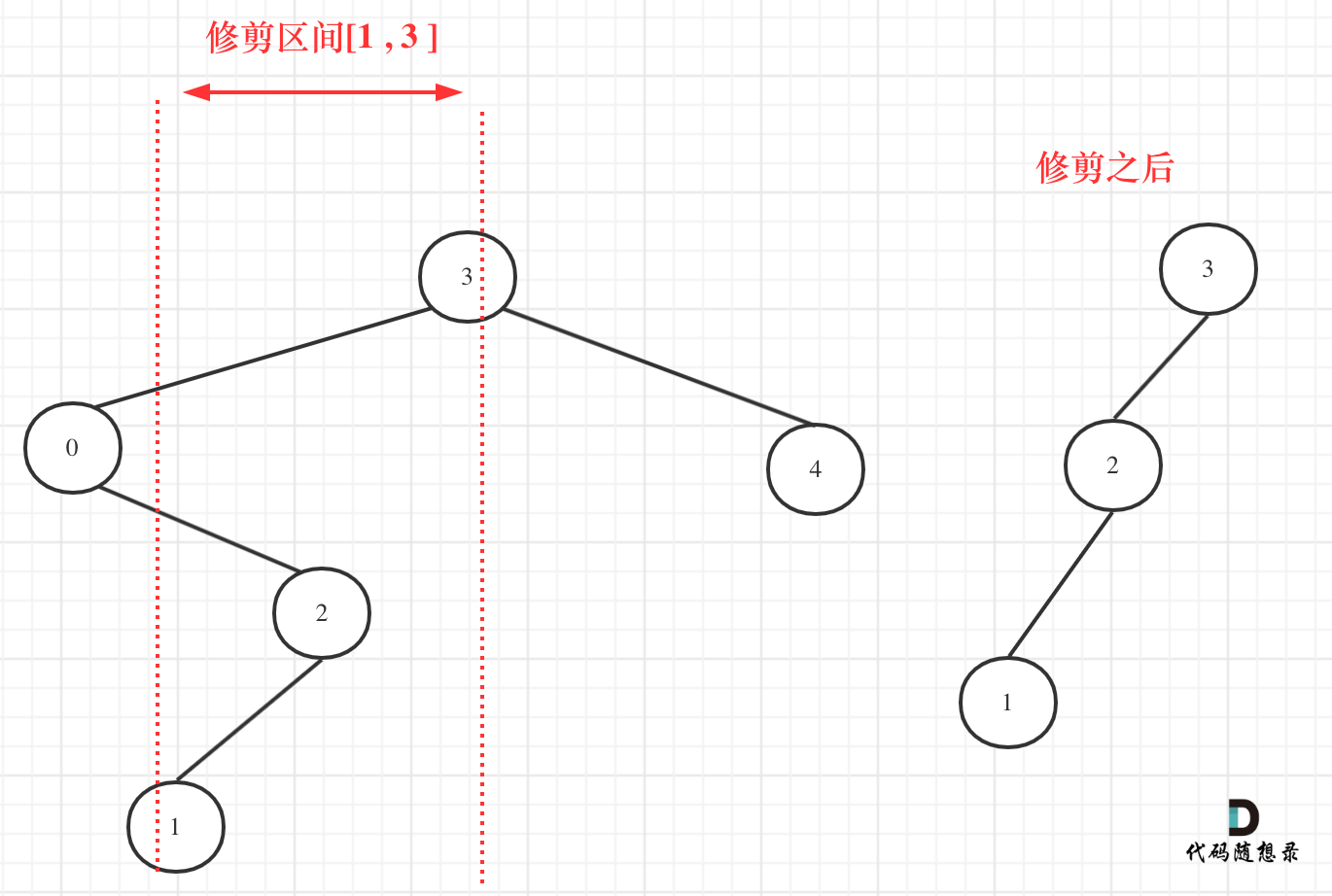
所以以上的代码是不可行的!
从图中可以看出需要重构二叉树,想想是不是本题就有点复杂了。
其实不用重构那么复杂。
在上图中我们发现节点0并不符合区间要求,那么将节点0的右孩子 节点2 直接赋给 节点3的左孩子就可以了(就是把节点0从二叉树中移除),如图:
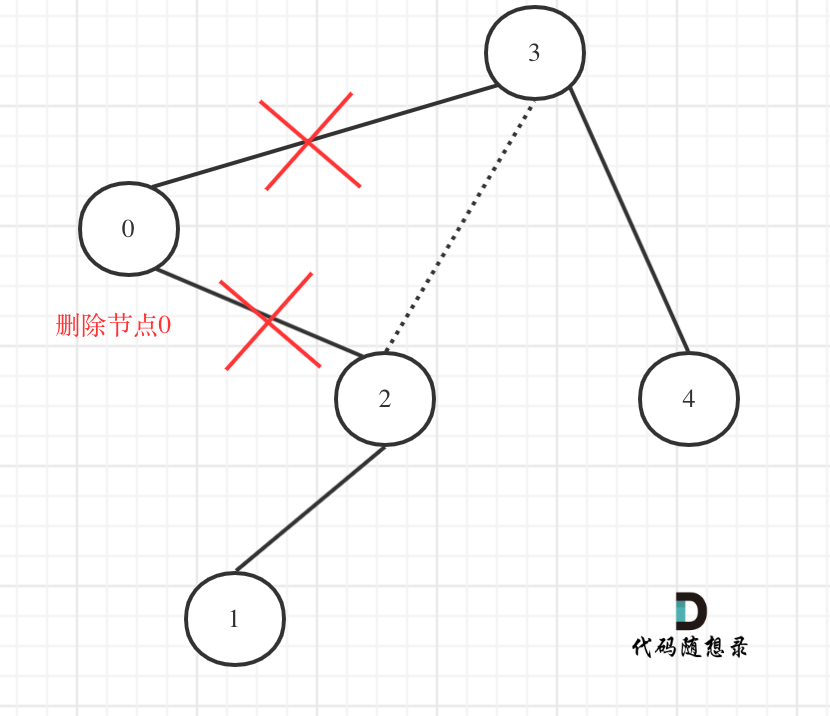
理解了最关键部分了我们再递归三部曲:
这里我们为什么需要返回值呢?
因为是要遍历整棵树,做修改,其实不需要返回值也可以,我们也可以完成修剪(其实就是从二叉树中移除节点)的操作。
但是有返回值,更方便,可以通过递归函数的返回值来移除节点。
这样的做法在二叉树:搜索树中的插入操作 (opens new window)和二叉树:搜索树中的删除操作 (opens new window)中大家已经了解过了。
代码如下:递归/迭代
难度:⭐️
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
示例:

本题其实要比二叉树:构造二叉树登场! (opens new window)和 二叉树:构造一棵最大的二叉树 (opens new window)简单一些,因为有序数组构造二叉搜索树,寻找分割点就比较容易了。
分割点就是数组中间位置的节点。
那么为问题来了,如果数组长度为偶数,中间节点有两个,取哪一个?
取哪一个都可以,只不过构成了不同的平衡二叉搜索树。
例如:输入:[-10,-3,0,5,9]
如下两棵树,都是这个数组的平衡二叉搜索树:
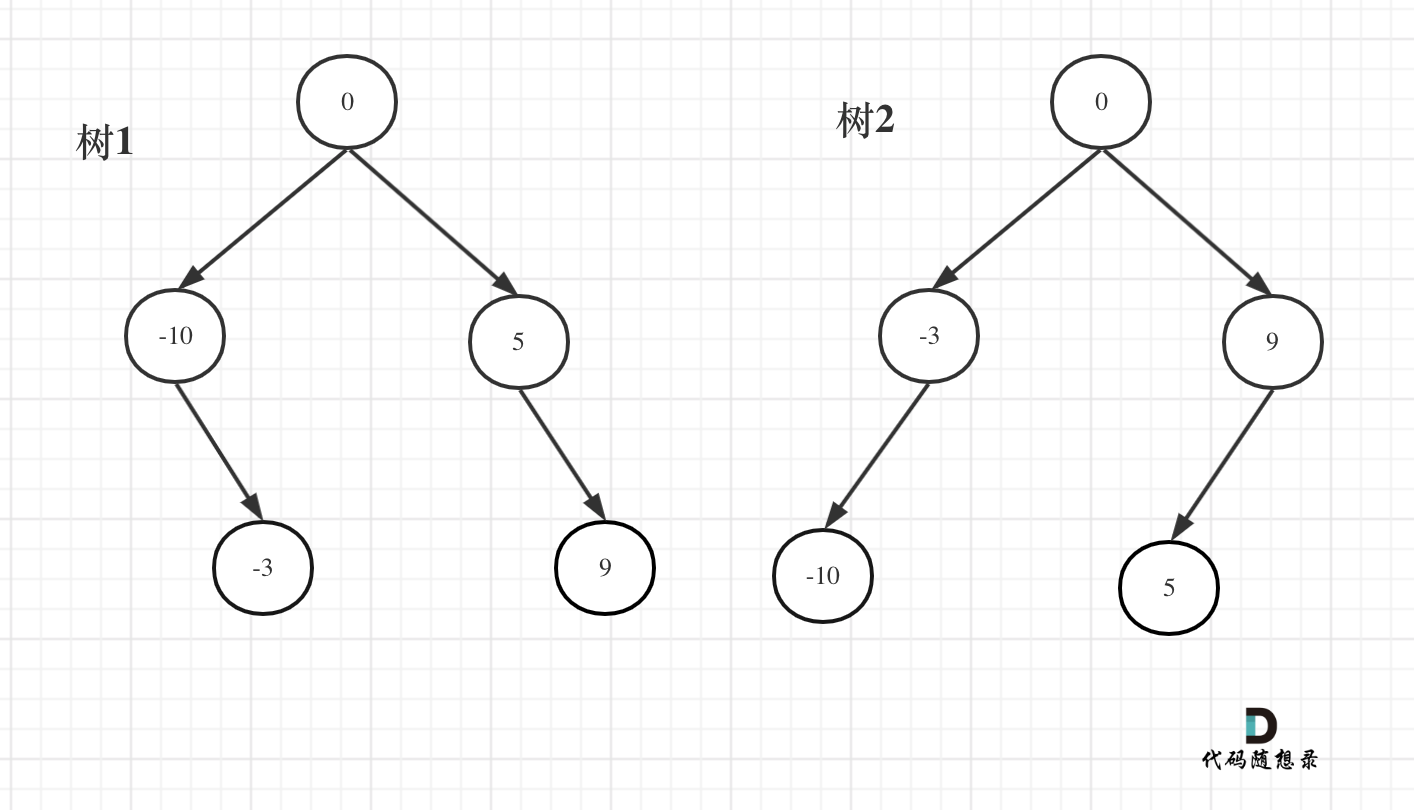
如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了。
代码:递归+前序/递归+中序/迭代
难度:⭐️⭐️
一看到BST就要想到中序遍历,有序数组的累加就很容易了,对应树的遍历过程操作即可
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
节点的左子树仅包含键 小于 节点键的节点。 节点的右子树仅包含键 大于 节点键的节点。 左右子树也必须是二叉搜索树。
示例 1:
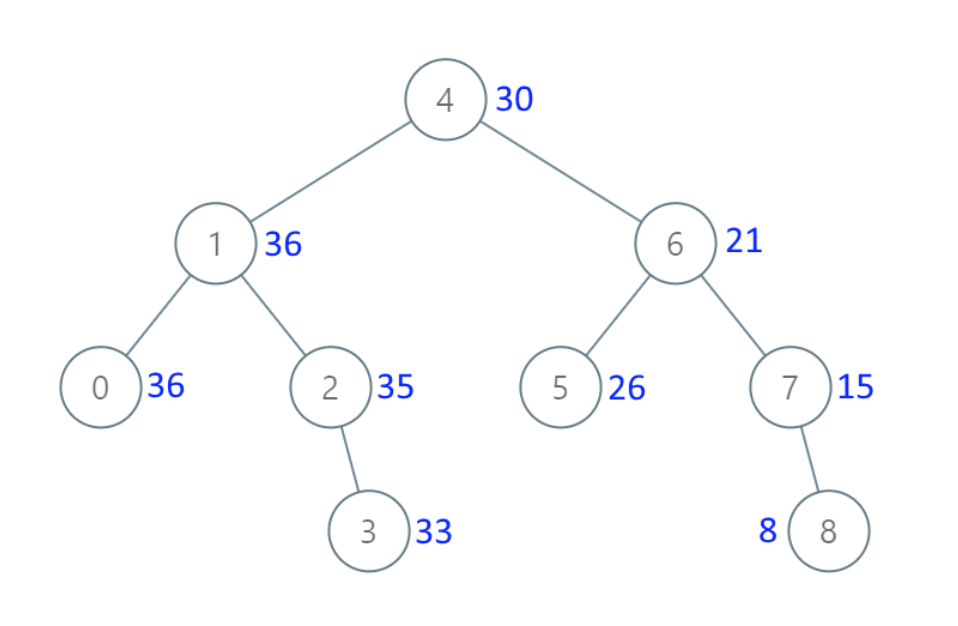
- 输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
- 输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
- 输入:root = [0,null,1]
- 输出:[1,null,1]
示例 3:
- 输入:root = [1,0,2]
- 输出:[3,3,2]
示例 4:
- 输入:root = [3,2,4,1]
- 输出:[7,9,4,10]
提示:
- 树中的节点数介于 0 和 104 之间。
- 每个节点的值介于 -104 和 104 之间。
- 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
一看到累加树,相信很多小伙伴都会疑惑:如何累加?遇到一个节点,然后再遍历其他节点累加?怎么一想这么麻烦呢。
然后再发现这是一棵二叉搜索树,二叉搜索树啊,这是有序的啊。
那么有序的元素如何求累加呢?
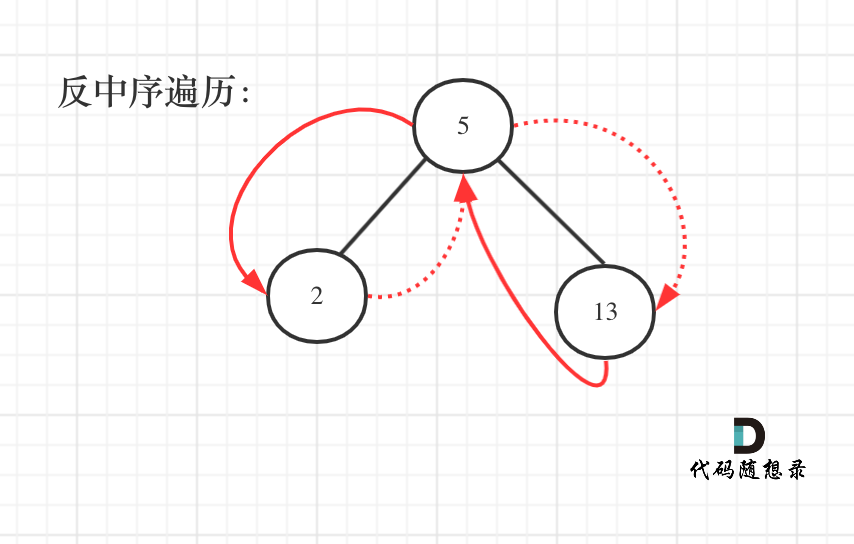
其实这就是一棵树,大家可能看起来有点别扭,换一个角度来看,这就是一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13],是不是感觉这就简单了。
为什么变成数组就是感觉简单了呢?
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
遍历顺序如图所示:
本题依然需要一个pre指针记录当前遍历节点cur的前一个节点,这样才方便做累加。
pre指针的使用技巧,我们在二叉树:搜索树的最小绝对差 (opens new window)和二叉树:我的众数是多少? (opens new window)都提到了,这是常用的操作手段。
这里很明确了,不需要递归函数的返回值做什么操作了,要遍历整棵树。
同时需要定义一个全局变量pre,用来保存cur节点的前一个节点的数值,定义为int型就可以了。
代码:递归/迭代
补充题:
难度:⭐️⭐️
链表相比数组无法随机访问,所以可以利用BST中序遍历为有序数组的特性,依次将遍历到的节点赋值给链表中对应的值。

代码:递归+中序

二叉树终于刷完了,内容量赶上前几章的总和了。。后面的章节也要加油,争取尽快刷完!