
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
原理:
-
数据库有个bin-log二进制文件,记录了所有sql语句。
-
我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
-
让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
-
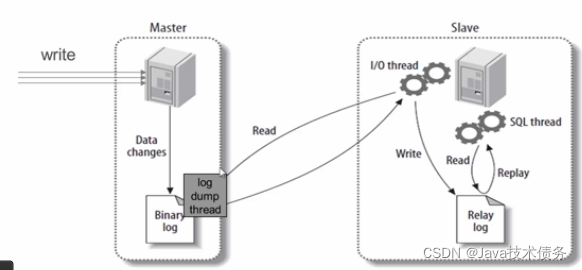
具体需要三个线程来操作:
4.1 binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
4.2 从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
4.3 从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
用途:
1、实施灾备,故障切换
2、读写分离
3、备份、避免数据丢失
条件:
1、主库开启binlog日志
2、主从服务器server-id不同
3、从库服务器能连通主库
方式:
1、同步复制
同步复制,意思是master的变化,必须等待slave-1,slave-2,…,slave-n完成后才能返回。
这样,显然不可取,也不是MYSQL复制的默认设置。比如,在WEB前端页面上,用户增加了条记录,需要等待很长时间。
2、异步复制
如同AJAX请求一样。master只需要完成自己的数据库操作即可。至于slaves是否收到二进制日志,是否完成操作,不用关心。MYSQL的默认设置。
3、半同步复制
master只保证slaves中的一个操作成功,就返回,其他slave不管。
这个功能,是由google为MYSQL引入的。
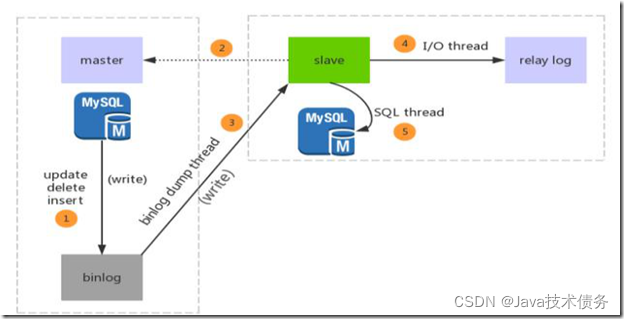
原理步骤:
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
关于MySQL主从同步的一些问题
- master的写操作,slaves被动的进行一样的操作,保持数据一致性,那么slave是否可以主动的进行写操作?
假设slave可以主动的进行写操作,slave又无法通知master,这样就导致了master和slave数据不一致了。因此slave不应该进行写操作,至少是slave上涉及到复制的数据库不可以写。实际上,这里已经揭示了读写分离的概念。
- 主从复制中,可以有N个slave,可是这些slave又不能进行写操作,要他们干嘛?
可以实现数据备份。
类似于高可用的功能,一旦master挂了,可以让slave顶上去,同时slave提升为master。
异地容灾,比如master在北京,地震挂了,那么在上海的slave还可以继续。
主要用于实现scale out,分担负载,可以将读的任务分散到slaves上
- 主从复制中有master,slave1,slave2,…等等这么多MYSQL数据库,那比如一个JAVA WEB应用到底应该连接哪个数据库?
我们在应用程序中可以这样,insert/delete/update这些更新数据库的操作,用connection(for master)进行操作,select用connection(for slaves)进行操作。那我们的应用程序还要完成怎么从slaves选择一个来执行select,例如简单的轮循算法。
这样的话,相当于应用程序完成了SQL语句的路由,而且与MYSQL的主从复制架构非常关联,一旦master挂了,某些slave挂了,那么应用程序就要修改了
- 能不能让应用程序与MYSQL的主从复制架构没有什么太多关系呢?
找一个组件,application program只需要与它打交道,用它来完成MYSQL的代理,实现SQL语句的路由。
mysql proxy并不负责,怎么从众多的slaves挑一个?可以交给另一个组件(比如haproxy)来完成。
这就是所谓的MYSQL READ WRITE SPLITE,MYSQL的读写分离。
- 如果mysql proxy , direct , master他们中的某些挂了怎么办?
总统一般都会弄个副总统,以防不测。同样的,可以给这些关键的节点来个备份。
- 当master的二进制日志每产生一个事件,都需要发往slave,如果我们有N个slave,那是发N次,还是只发一次?
如果只发一次,发给了slave-1,那slave-2,slave-3,…它们怎么办?
显 然,应该发N次。实际上,在MYSQL master内部,维护N个线程,每一个线程负责将二进制日志文件发往对应的slave。master既要负责写操作,还的维护N个线程,负担会很重。可 以这样,slave-1是master的从,slave-1又是slave-2,slave-3,…的主,同时slave-1不再负责select。 slave-1将master的复制线程的负担,转移到自己的身上。这就是所谓的多级复制的概念。
- 当一个select发往mysql proxy,可能这次由slave-2响应,下次由slave-3响应,这样的话,就无法利用查询缓存了。
应该找一个共享式的缓存,比如memcache来解决。将slave-2,slave-3,…这些查询的结果都缓存至mamcache中。
- 随着应用的日益增长,读操作很多,我们可以扩展slave,但是如果master满足不了写操作了,怎么办呢?
scale on ?更好的服务器? 没有最好的,只有更好的,太贵了。。。
scale out ? 主从复制架构已经满足不了。
原因:主库TPS并发高,DDL数量超过slave一个sql线程承受的范围,还有可能与大型的查询造成了所等待,还有网络延迟。(谈到MySQL数据库主从同步延迟原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高;slave的Slave_IO_Running线程会到主库取日志,效率会比较高,slave的Slave_SQL_Running线程将主库的DDL和DML操作都在slave实施。DML和DDL的IO操作是随机的,不是顺序的,因此成本会很高,还可能是slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。有朋友会问:“主库上那个相同的DDL也需要执行10分,为什么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。)
**解决方法一:**最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。
解决方法二:数据放入缓存中,更新数据库后,在预期可能马上用到的情况下,主动刷新缓存。
解决办法三:对于比较重要且必须实时的数据,比如用户刚换密码(密码写入 Master),然后用新密码登录(从 Slaves 读取密码),会造成密码不一致,导致用户短时间内登录出错。所以在这种需要读取实时数据的时候最好从 Master 直接读取,避免 Slaves 数据滞后现象发生。
假设发生了突发事件,master宕机,现在的需求是要将192.168.1.102提升为主库,另外一个为从库
步骤:
1.确保所有的relay log全部更新完毕,在每个从库上执行stop slave io_thread; show processlist;直到看到Has read all relay log,则表示从库更新都执行完毕了
2.登陆所有从库,查看master.info文件,对比选择pos最大的作为新的主库,这里我们选择192.168.1.102为新的主库
3.登陆192.168.1.102,执行stop slave; 并进入数据库目录,删除master.info和relay-log.info文件, 配置my.cnf文件,开启log-bin,如果有
log-slaves-updates和read-only则要注释掉,执行reset master
4.创建用于同步的用户并授权slave,同第五大步骤
5.登录另外一台从库,执行stop slave停止同步
6.根据第七大步骤连接到新的主库
7.执行start slave;
8.修改新的master数据,测试slave是否同步更新
为了减轻数据库的压力,一般会进行数据库的读写分离,实现方法一是通过分析sql语句是insert/select/update/delete中的哪一种,从而对应选择主从,二是通过拦截方法名称的方式来决定主从的,如:save*()、insert*() 形式的方法使用master库,select()开头的使用slave库。
虽然大多数都是从程序里直接实现读写分离的,但对于分布式的部署和水平和垂直分割,一些代理的类似中间件的软件还是挺实用的,如 MySQL Proxy比较。mysql proxy根本没有配置文件, lua脚本就是它的全部,当然lua是相当方便的。
相关配置:
innodb_flush_log_at_trx_commit 和 sync_binlog 是 MySQL 的两个配置参数。它们的配置对于 MySQL 的性能有很大影响(一般为了保证数据的不丢失,会设置为双1,该情形下数据库的性能也是最低的)。
- 1、innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit:是 InnoDB 引擎特有的,ib_logfile的刷新方式( ib_logfile:记录的是redo log和undo log的信息)
取值:0/1/2
innodb_flush_log_at_trx_commit=0,表示每隔一秒把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。也就是说一秒之前的日志都保存在日志缓冲区,也就是内存上,如果机器宕掉,可能丢失1秒的事务数据。
innodb_flush_log_at_trx_commit=1,表示在每次事务提交的时候,都把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。这样的话,数据库对IO的要求就非常高了,如果底层的硬件提供的IOPS比较差,那么MySQL数据库的并发很快就会由于硬件IO的问题而无法提升。
innodb_flush_log_at_trx_commit=2,表示在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘。如果只是MySQL数据库挂掉了,由于文件系统没有问题,那么对应的事务数据并没有丢失。只有在数据库所在的主机操作系统损坏或者突然掉电的情况下,数据库的事务数据可能丢失1秒之类的事务数据。这样的好处,减少了事务数据丢失的概率,而对底层硬件的IO要求也没有那么高(log buffer写到文件系统中,一般只是从log buffer的内存转移的文件系统的内存缓存中,对底层IO没有压力)。
sync_binlog:是MySQL 的二进制日志(binary log)同步到磁盘的频率。
取值:0-N
sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。这个是性能最好的。
sync_binlog=1,当每进行1次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
注:
大多数情况下,对数据的一致性并没有很严格的要求,所以并不会把 sync_binlog 配置成 1. 为了追求高并发,提升性能,可以设置为 100 或直接用 0.
而和 innodb_flush_log_at_trx_commit 一样,对于支付服务这样的应用,还是比较推荐 sync_binlog = 1.

JVM内存泄漏和内存溢出的原因
JVM常用监控工具解释以及使用
Redis 常见面试题(一)
ClickHouse之MaterializeMySQL引擎(十)
三种实现分布式锁的实现与区别
线程池的理解以及使用
号外!号外!
最近面试BAT,整理一份面试资料,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。想获取吗?如果你想提升自己,并且想和优秀的人一起进步,感兴趣的朋友,可以在扫码关注下方公众号。资料在公众号里静静的躺着呢。。。

一键四连,你的offer也四连
————————————————————————————————
本文作者:Java技术债务
原文链接:https://www.cuizb.top/myblog/article/1644849971
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 3.0 CN协议进行许可。转载请署名作者且注明文章出处。