本文章旨在指导如何使用轻量级日志引擎Loki来采集Kubernetes的应用日志,并展示在grafana中。
背景
最近我们公司的项目上了Kubernetes集群,产生的大量应用的日志需要采集起来,便于溯源问题、跟踪问题和及时报警。考虑到ELK那一套框架实在太大了,所以我们采用了更轻量化,更便捷部署和维护的Loki+grafana。
新建Loki服务
这里考虑到Loki服务需要持久化存储数据,我就直接部署在虚拟机了。
$ curl -O -L "https://github.com/grafana/loki/releases/download/v2.7.3/loki-linux-amd64.zip
$ unzip loki-linux-amd64.zip
$ cat /etc/systemd/system/loki.service
[Unit]
Description=loki
After=network.target
[Service]
ExecStart=/data/loki/loki-linux-amd64 \
-config.file=/data/loki/loki-config.yaml &>> /data/loki/logs/loki-3100.log
Restart=on-failure
[Install]
WantedBy=multi-user.target
优化Loki服务的参数
为了避免Loki服务器出现io瓶颈,需要对Loki得参数进行优化。
$ cat loki-config.yaml
auth_enabled: false
server:
http_listen_port: 3100 #如是云服务需打开3100端口
grpc_listen_port: 9096
grpc_server_max_recv_msg_size: 8388608
grpc_server_max_send_msg_size: 8388608
ingester:
lifecycler:
address: 0.0.0.0 #监听地址,可不做修改。
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 0
ingester_client:
remote_timeout: 2m
schema_config:
configs:
- from: 2023-01-29
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 168h
storage_config:
boltdb:
directory: /data/loki/index #自定义boltdb目录(在loki目录下新建data文件来存放)
filesystem:
directory: /data/loki/chunks #自定义filesystem目录(在loki目录下新建data文件来存放)
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
#ngestion_rate_strategy: local
ingestion_rate_mb: 30
ingestion_burst_size_mb: 60
per_stream_rate_limit: 10MB
per_stream_rate_limit_burst: 20MB
max_query_length: 0h
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 180h
# service file
$ cat /etc/systemd/system/loki.service
[Unit]
Description=loki
After=network.target
[Service]
ExecStart=/data/loki/loki-linux-amd64 \
-config.file=/data/loki/loki-config.yaml &>> /data/loki/logs/loki-3100.log
Restart=on-failure
[Install]
WantedBy=multi-user.target
# start loki
sudo systemctl daemon-reload
sudo systemctl enable loki
sudo systemctl start loki
在kubernetes集群部署日志采集器
Loki的日志采集器是promtail,相当于prometheus的node-exporter,充当采集器角色。
这里的日志采集有几种办法:
针对服务器service:可以直接配置service得名字,promtail就能自动采集
针对磁盘日志文件:配置日志文件的目录,或者用通配符匹配目录下的日志文件
这里因为我们的应用没有输出日志到指定的文件,只能去node节点上的docker日志目录采集,
配置如下:
首先创建role和rolebinding:
--- # Clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: promtail-clusterrole
rules:
- apiGroups: [""]
resources:
- nodes
- services
- pods
verbs:
- get
- watch
- list
--- # ServiceAccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: promtail-serviceaccount
namespace: uat
--- # Rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: promtail-clusterrolebinding
subjects:
- kind: ServiceAccount
name: promtail-serviceaccount
namespace: uat
roleRef:
kind: ClusterRole
name: promtail-clusterrole
apiGroup: rbac.authorization.k8s.io
创建configmap:
% cat configmap.yaml
--- # configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: promtail-config
data:
promtail.yaml: |
server:
http_listen_port: 9080
grpc_listen_port: 0
clients:
- url: http://10.x.x.x:3100/loki/api/v1/push # 替换为loki服务的地址
positions:
filename: /tmp/positions.yaml
target_config:
sync_period: 60s
scrape_configs:
- job_name: pod-logs
kubernetes_sd_configs:
- role: pod
pipeline_stages:
- docker: {}
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_node_name
target_label: __host__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
replacement: $1
separator: /
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
target_label: job
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- action: replace
source_labels:
- __meta_kubernetes_pod_container_name
target_label: container
- replacement: /var/log/*$1/*.log # 这里是采集node节点的容器目录的日志
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
创建daemonset格式的资源,以采集每个node上的log。
--- # Daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: promtail-daemonset
spec:
selector:
matchLabels:
name: promtail
template:
metadata:
labels:
name: promtail
spec:
serviceAccount: promtail-serviceaccount
containers:
- name: promtail-container
image: grafana/promtail
args:
- -config.file=/etc/promtail/promtail.yaml
env:
- name: 'HOSTNAME' # needed when using kubernetes_sd_configs
valueFrom:
fieldRef:
fieldPath: 'spec.nodeName'
volumeMounts:
- name: logs
mountPath: /var/log
- name: promtail-config
mountPath: /etc/promtail
- mountPath: /var/lib/docker/containers
name: varlibdockercontainers
readOnly: true
volumes:
- name: logs
hostPath:
path: /var/log/pods
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: promtail-config
configMap:
name: promtail-config
创建后的资源:

将Loki数据源接入Grafana
登陆grafana,新建Loki类型的数据源
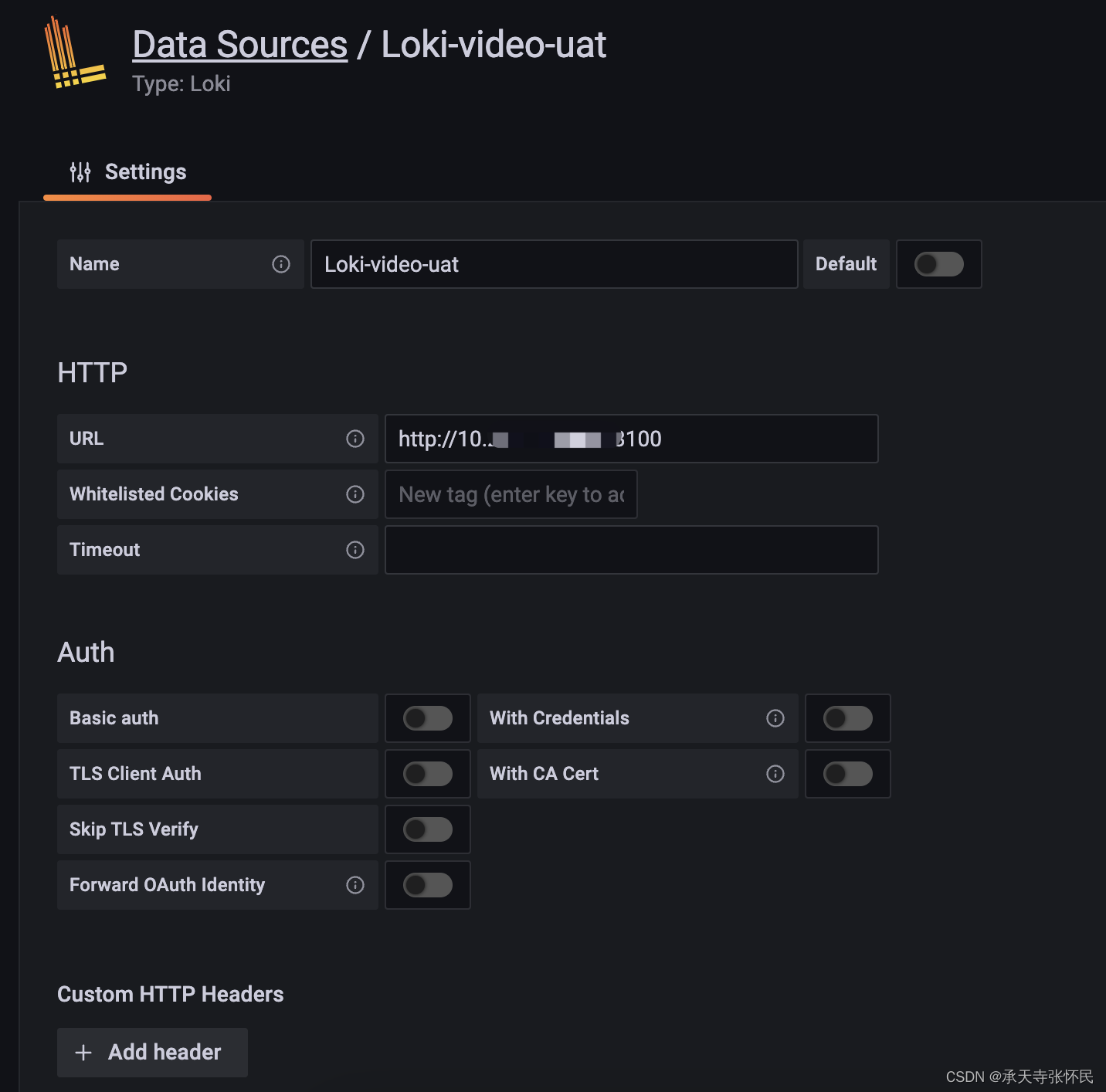
使用Lokiql查询日志
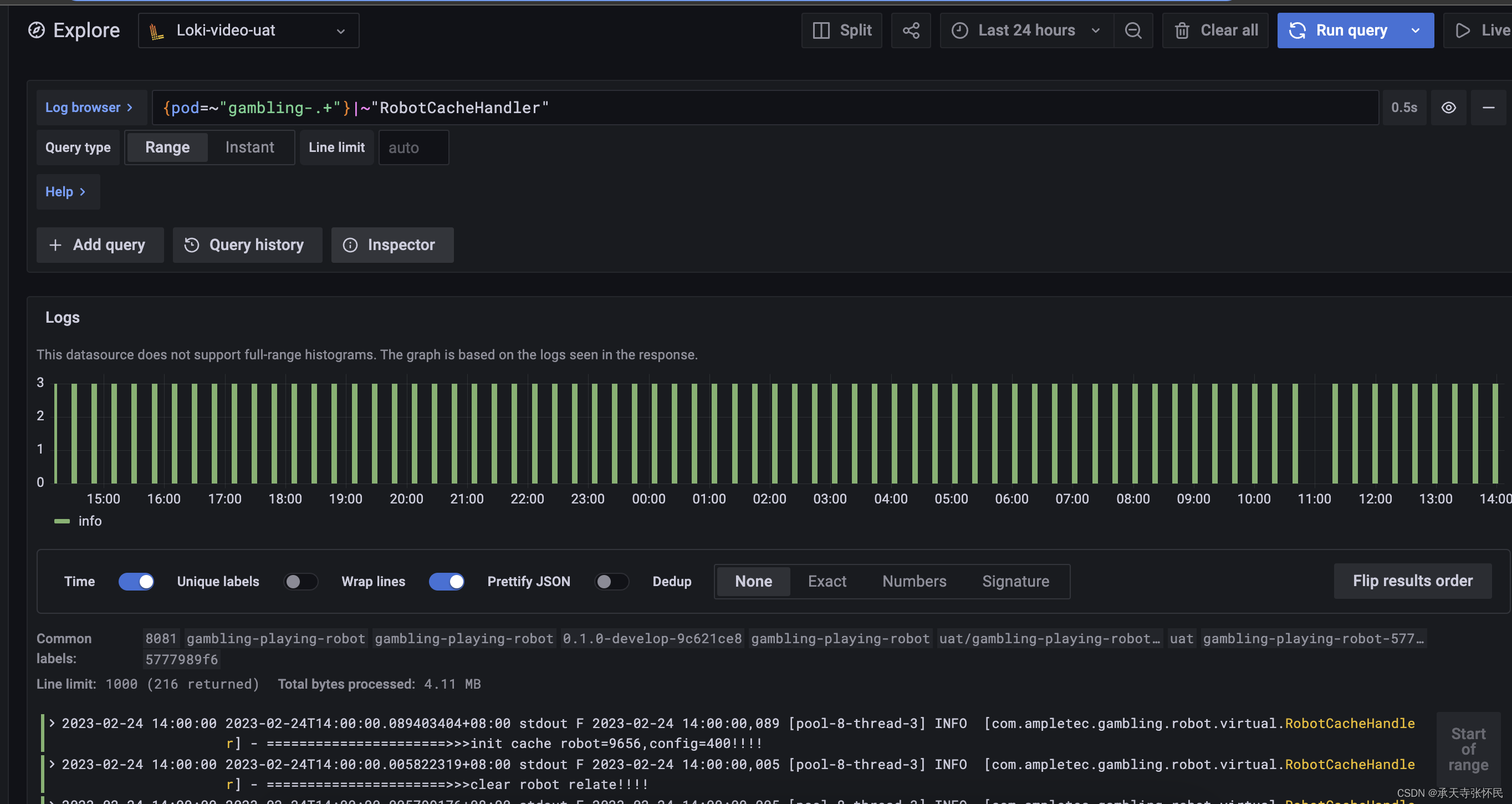
登陆grafana,点击explore,选择刚创建的数据源,点Log Browser
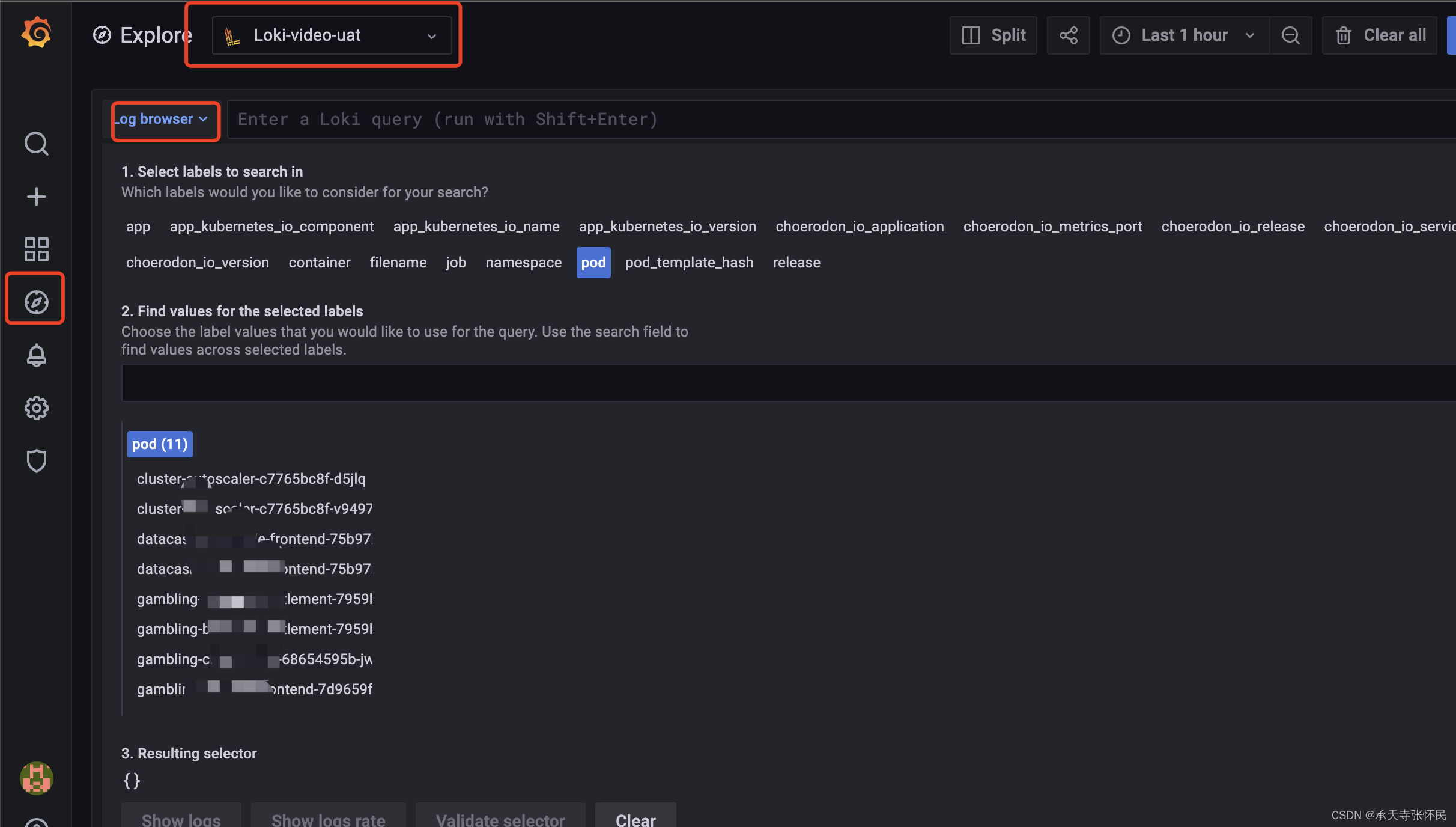
在这里就能看到采集到的每一个pod的日志
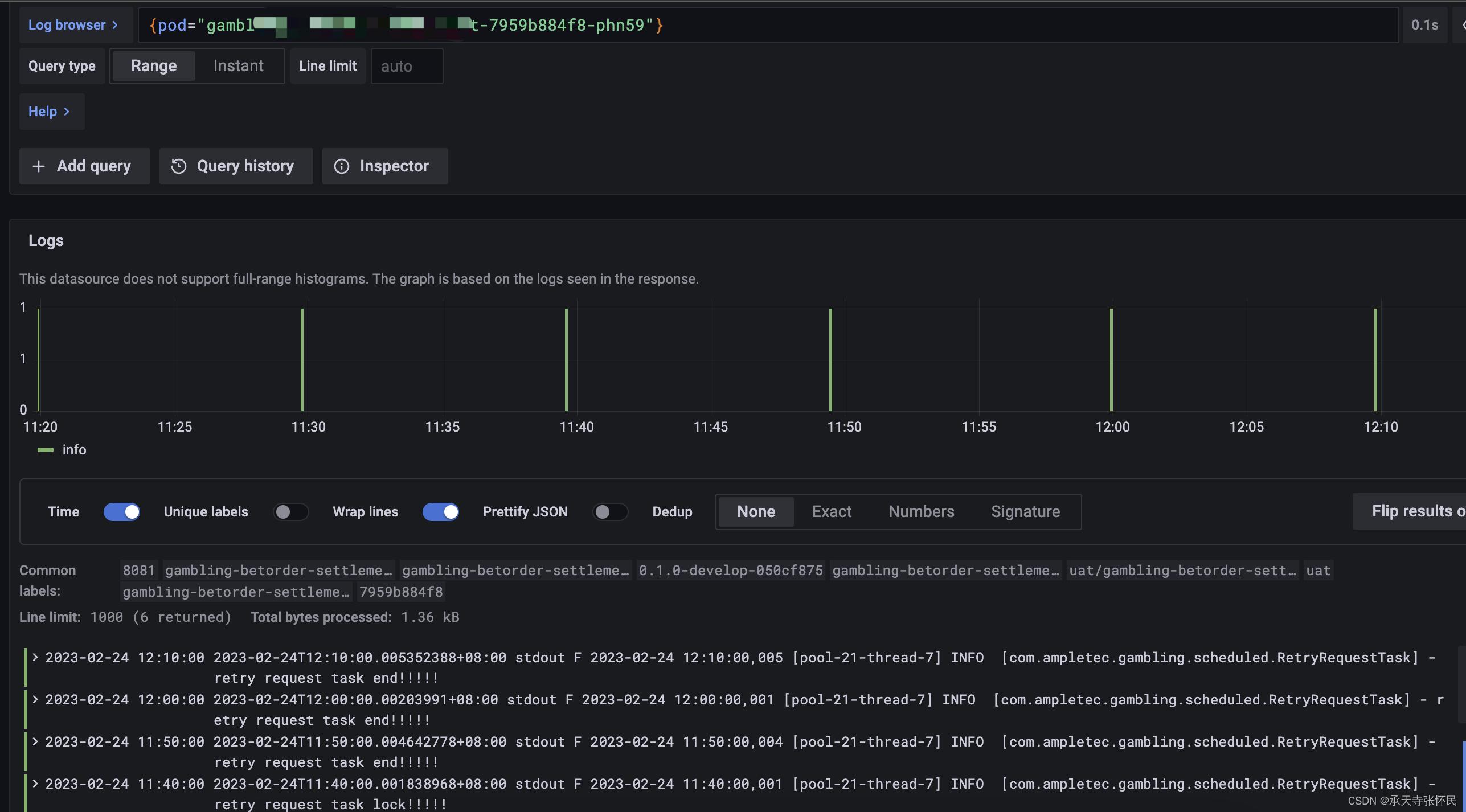
也可以自己写promql查询指定应用的日志:
例如ql:{pod=~“nginx-gateway-.+”},搜索名字为nginx-gateway应用的日志
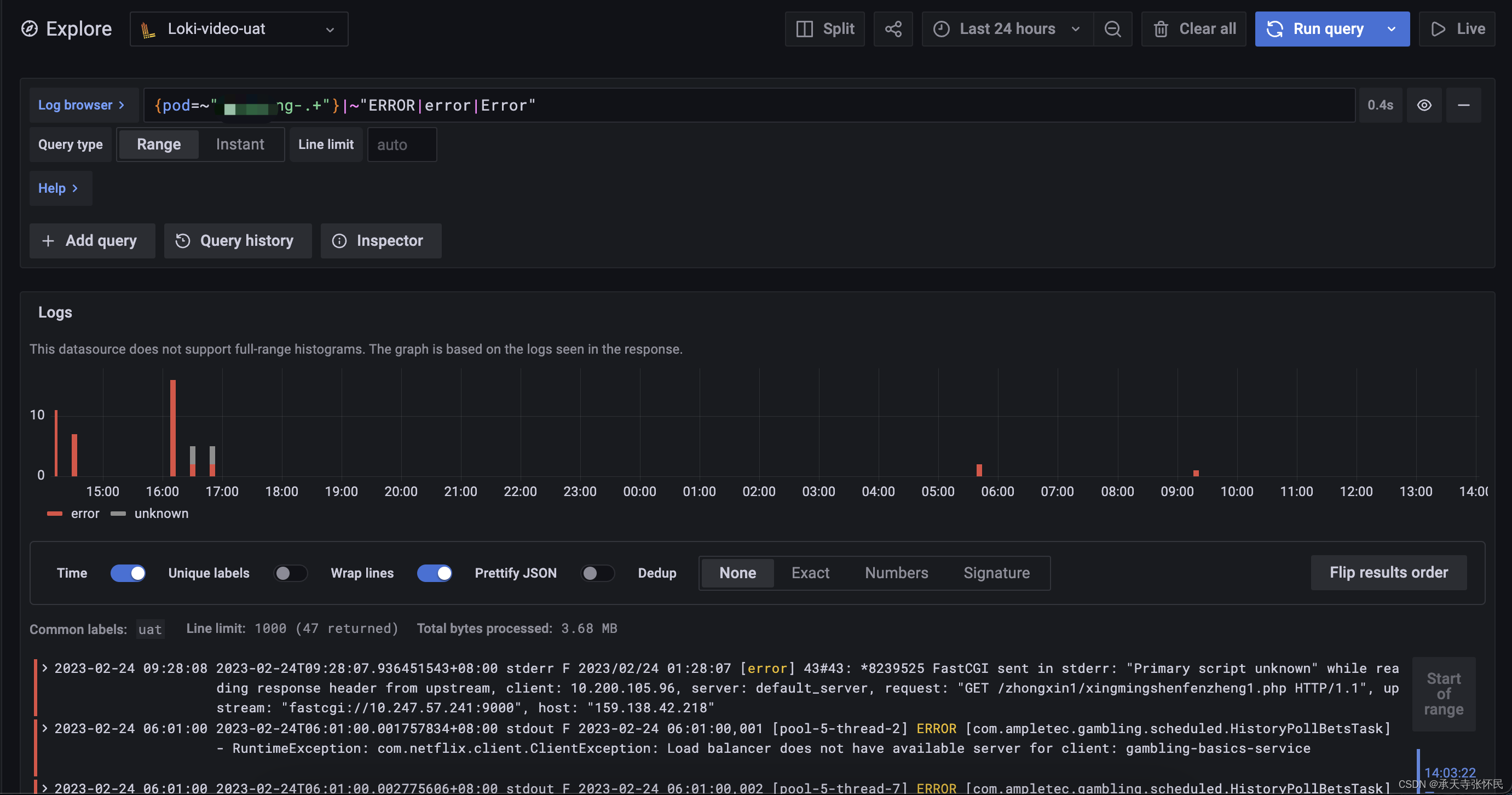
例如ql:搜索应用nginx-gateway近期日志中包含ERROR或error或Error的行
{pod=~"nginx-gateway-.+"}|~"ERROR|error|Error"
例如ql:搜索nginx-gateway-应用中包含关键字“RobotCacheHandler”的日志
{pod=~"nginx-gateway-.+"}|~"RobotCacheHandler"
至此,我们使用Loki+promtail+grafana实现了对K8s集群中应用日志的采集和展示。