题目:Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
中文:深度拉普拉斯金字塔网络,可实现快速,准确的超分辨率

摘要:
- 本文提出了拉普拉斯金字塔超分辨率网络(LapSRN),以逐步重建高分辨率图像的sub-band 残差。在每个金字塔级别,均以粗糙分辨率特征图为输入,预测高频残差。并使用反卷积将其向上采样到更精细的级别。
不需要双三次插值作为预处理步骤,因此大大降低了计算复杂度。使用Charbonnier损失函数在深度监督下训练了提出的LapSRN,并实现了高质量的重建。此外,通过渐进式重构在一次前馈中生成多尺度预测。对基准数据集的大量定量和定性评估表明,该算法在速度和准确性方面均与最新方法相比表现良好。
提出拉普拉斯金字塔网络LapSRN,逐步重建高频残差,提出Charbonnier损失函数,反卷积进行精细上采样。
结论
- 提出了一个拉普拉斯金字塔框架内的深度卷积网络,用于快速且准确的单图像超分辨率。从粗到精的方式逐步预测高频残差。用学习的反卷积层替换预定义的双三次插值。并使用健壮的损失函数优化网络,LapSRN缓解了伪影的问题并降低了计算复杂性。对基准数据集的广泛评估表明,在视觉质量和运行时间方面,所提出的模型与最新的SR算法相比表现良好。
引言
- 近年来,基于示例的SR方法通过学习使用大型图像数据库从LR到HR图像斑块的映射,展示了最新的性能。比如字典学习[37,38],局部线性回归[30,36]和随机森林[26]。
- 董提出(SRCNN)虽然效果很好,但仍然存在三个主要问题。
1、现有的方法先使用类似双三次插值的沙航采样操作将LR图像放大至所需的尺寸,会增加计算成本,并经常导致可见的重建伪像。一些方法尝试使用亚像素卷积[28]或反卷积[8]代替上述的上采样操作,但是由于网络太小,无法学习到复杂的映射。
2、现有的L2损失函数会导致HR结果过于平滑。
3、现有方法是单一尺度,无法生成多个尺度的重建结果。需要针对不同的放大因子训练不同的网络。
- 为了解决这些缺点,我们提出了级联卷积神经网络(CNN)的拉普拉斯金字塔超分辨率网络(LapSRN)。我们的网络将LR图像作为输入,并以从粗到精的方式逐步预测子带残差。在每个级别上,我们首先应用级联的卷积层来提取特征图。然后,我们使用转置卷积层将特征图上采样到更精细的级别。最后,我们使用卷积层来预测子带残差(上采样图像和地面真实HR图像之间的差异)。每个级别的预测残差用于通过上采样和加法运算有效地重建HR图像。虽然拟议的LapSRN由一组级联的子网组成,但我们以端到端的方式(即没有阶段优化)训练具有健壮的Charbonnier损失函数的网络。
为了解决以上问题,提出LapSRN网络,以端到端的方式训练网络。

SRCNN [7],FSRCNN [8],VDSR [17],DRCN [18]和建议的LapSRN的网络体系结构。 红色示卷积层。蓝色箭头是反卷积(上采样)。绿色箭头表示逐元素加法运算符,橙色箭头表示递归层。
1、准确性:直接从LR图像提取特征图,并联合优化具有深卷积层的上采样滤波器,以预测子带残差。Charbonnier损失函数能够处理离群值,所以可以提高性能。模型可以学习复杂映射,并减少了视觉伪像。
2、速度:LapSRN有快速的处理速度和高容量的深度网络,此外我们的方法提供了更好的重建精度。
3、渐进式重建:一次前馈中生成多个中间SR预测。适用于不同倍数的放大。

-
拉普拉斯金字塔:拉普拉斯金字塔已被广泛使用,例如图像融合[4],纹理合成[14],边缘感知过滤[24]和语义分割[11,25]。登顿等提出的LAPGAN[6]与我们的方法最相关,但是,LapSRN与LAPGAN有以下三点区别:
1、首先,LAPGAN是一种生成模型,旨在从随机噪声和样本输入中合成出各种自然图像。相反,我们的LapSRN是一种超分辨率模型,可以根据给定的LR图像预测特定的HR图像。 LAPGAN使用交叉熵损失函数来鼓励输出图像尊重训练数据集的数据分布。相比之下,我们使用Charbonnier惩罚函数对预测与地面真实子带残差的偏差进行惩罚。
2、LAPGAN的子网是独立的(即无权重共享)。结果,网络容量受到每个子网深度的限制。与LAP-GAN不同,LapSRN中每个级别的卷积层都是通过多通道转置卷积层连接的。因此,较高层次的残差图像将由具有较低层次共享特征的更深层网络来预测。较低级别的特征共享增加了精细卷积层的非线性,以学习复杂的映射。而且,LAP-GAN中的子网是独立训练的。另一方面,LapSRN中用于特征提取,上采样和残差预测层的所有卷积滤波器都以端到端,深度监督的方式联合训练。
3、LAPGAN对上采样的图像应用卷积,因此速度取决于HR图像的大小。相反,我们的LapSRN设计通过从LR空间提取特征有效地增加了感受野的大小并加快了速度。我们在补充材料中提供与LAPGAN的比较。
-
对抗训练:SRGAN方法[20]使用感知损失[16]和逼真的SR的对抗损失来优化网络。我们的LapSRN可以轻松扩展到对抗训练框架,但是我们没有做。
3、Deep Laplacian Pyramid Network for SR
- 在本节中,我们将描述所提出的拉普拉斯金字塔网络的设计方法,使用具有深度监督功能的鲁棒损失函数进行的优化以及网络训练的细节。
3.1网络框架
- 网络结构如图所示。模型直接将LR图像作为输入,逐步预测log2 S级的剩余图像,S是缩放因子。例如,网络由3个子网络组成,适用于8倍尺度下的超分辨重建。主要包括2个部分:(1)特征提取;(2)图像重建
-
特征提取:在s级,特征提取分支由d个卷积层和1个反卷积层组成,以2为尺度进行上采样。每个反卷积层的输出连接到2个不同的layers:向下的箭头表示表示每次上采样到一定程度,即将学习到的残差结果输出,得到对应的重构图像,向右的箭头表示同时继续上采样。注意:我们仅仅使用了1个反卷积层,提取粗分辨率下的特征,生成更细分辨率下的特征映射。与现有的特征提取网络相比,计算复杂度降低。注意,低级别的特征表示与高级别的共享,因此可以增加网络的非线性,便于学习复杂的映射。
-
图像重建。在级别s上,输入图像通过反卷积层上采样到尺度2。我们使用双线性核对这一层进行初始化,并允许将其与所有其他层一起进行优化。然后将上采样的图像与特征提取分支中的预测残差图像合并(使用逐元素求和),以生成高分辨率的输出图像。然后将s级别的输出HR图像馈送到级别+1的图像重建分支中。整个网络是一系列的CNN连接,每一级的结构都相似。
3.2 损失函数
- x表示LR图像,θ表示学习到的网络参数,目标是学习到一个映射函数f重建HR图像y’=f(x,θ)。使y’尽可能的接近ground truth。用Rs表示在s级的残差图像,Xs表示上采样之后的LR图像,Ys表示对应的HR图像。s层的目标图像即Ys = Xs+Rs。使用双三次下采样去调整HR图像y在每一层的大小。我们不使用MSE作为损失函数,而是使用一种更加鲁棒性的损失函数(Charbonnier):
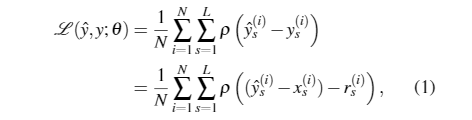
- 其中ρ(x)=√x2+ε2是Charbonnier损失函数(ℓ1范数的可微变量)[3],N是每批中训练样本的数量,L是我们金字塔中的层数。我们根据经验将ε设置为1e−3。
- 在提出的LapSRN中,每个S都有其损失函数和相应的地面真实HR图像。这种多重损失的结构类似于用于分类[21]和边缘检测[34]的深层监督网。在我们的模型中,我们使用了相应级别的HR图像的不同尺度作为监督。深度监督指导网络培训,以预测不同级别的子带残差图像并生成多尺度输出图像。例如,我们的8x模型可以在一次前馈过程中产生2x,4x和8x超分辨率结果。此属性对于资源感知应用程序(例如移动设备或网络应用程序)特别有用。
3.3 具体实施和实验细节
- 在提出的LapSRN中,每个卷积层包含64个3×3大小的滤波器。我们使用He等人的方法初始化卷积滤波器。 [13]。反卷积滤波器的大小为4×4,权重由双线性滤波器初始化。所有卷积层和反卷积层(除其中的构造层外)都跟随有负斜率为0.2的整流线性单元(LReLU)。在应用卷积之前,我们在边界周围填充零,以使所有要素贴图的大小与每个级别的输入相同。卷积滤波器的空间支持较小(3×3)。但是,我们可以实现高非线性度并增加具有深结构的感受野的大小。我们使用Yang等人的91张图像。 [38]和来自伯克利细分数据集[1]的训练集的200张图像作为我们的训练数据。在[17,26]中也使用了相同的训练数据集。在每个训练批次中,我们随机采样64个补丁,大小为128×128。一个epoch具有1000次迭代的反向传播。我们通过三种方式扩充训练数据:(1)缩放:在[0.5,1.0]之间随机缩小。 (2)旋转:将图像随机旋转90°,180°或270°。 (3)翻转:水平或垂直翻转图像的概率为0.5。根据现有方法的协议[7,17],我们使用双三次降采样生成LR训练补丁。我们使用MatConvNet工具箱[31]训练模型。我们将动量参数设置为0.9,权重衰减设置为1e−4。所有层的学习率均初始化为1e−5,每50个周期将学习率降低2倍。
4、实验结果
4.1 模型分析
残差学习:figure 2。为了验证残差学习的效果,我们去掉了图像重建分支,直接对各个层次的HR图像进行预测。如蓝线所示,去掉图像重建分支后,收敛慢,波动大。
Loss函数:figure 2。绿线所示,用L2loss函数代替Charbonnier loss函数后,它需要迭代更多次以达到和SRCNN的性能;且有更多的振铃现象(ringing artifacts)
金字塔结构:table 2。能使性能得到适度的提高
网络深度:table 3。越深性能越好,但是需要和计算速度进行平衡
