步骤1:开通AWS账号
- 需要一个邮箱、一个信用卡账号;
- 有第一年的免费试用,EC2每个月免费试用750小时;
- 注册完成后,得到实例管理平台:
步骤2:开通EC2实例
步骤3:开通网关和安全组,使外部可以访问
在任何一台电脑的浏览器输入云服务器的公网ip xx.xx.xx.xx:5000 都会得到云服务器的响应。(若没有得到响应,检查一下云服务器的安全组,是否增加有规则 0.0.0.0/0的端口TCP:5000 放通)
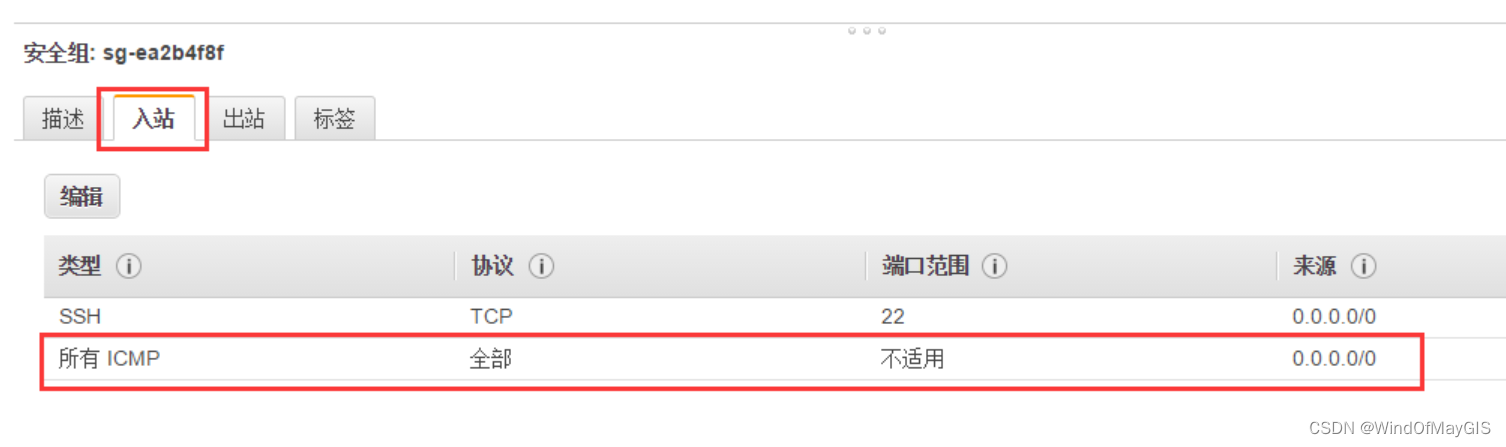
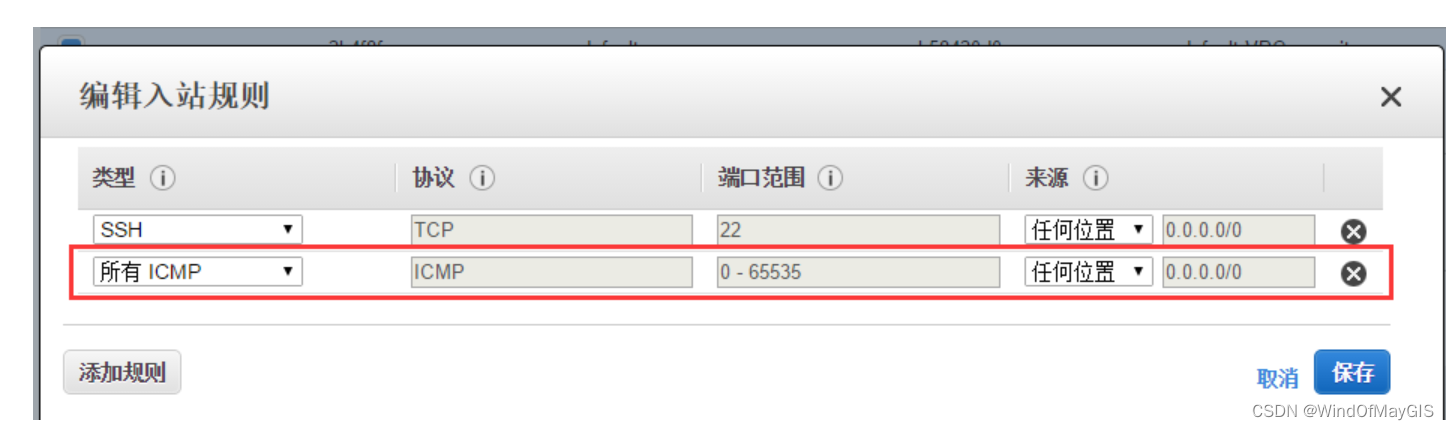
子步骤3.1 开通安全组中的ICMP端口,使之能ping通
- 安全组中需要把入站和出站设置到位
子步骤3.2 开通防火墙的入站和出站协议
- 如果想简单粗暴,直接全部关闭,这种方式存在安全漏洞
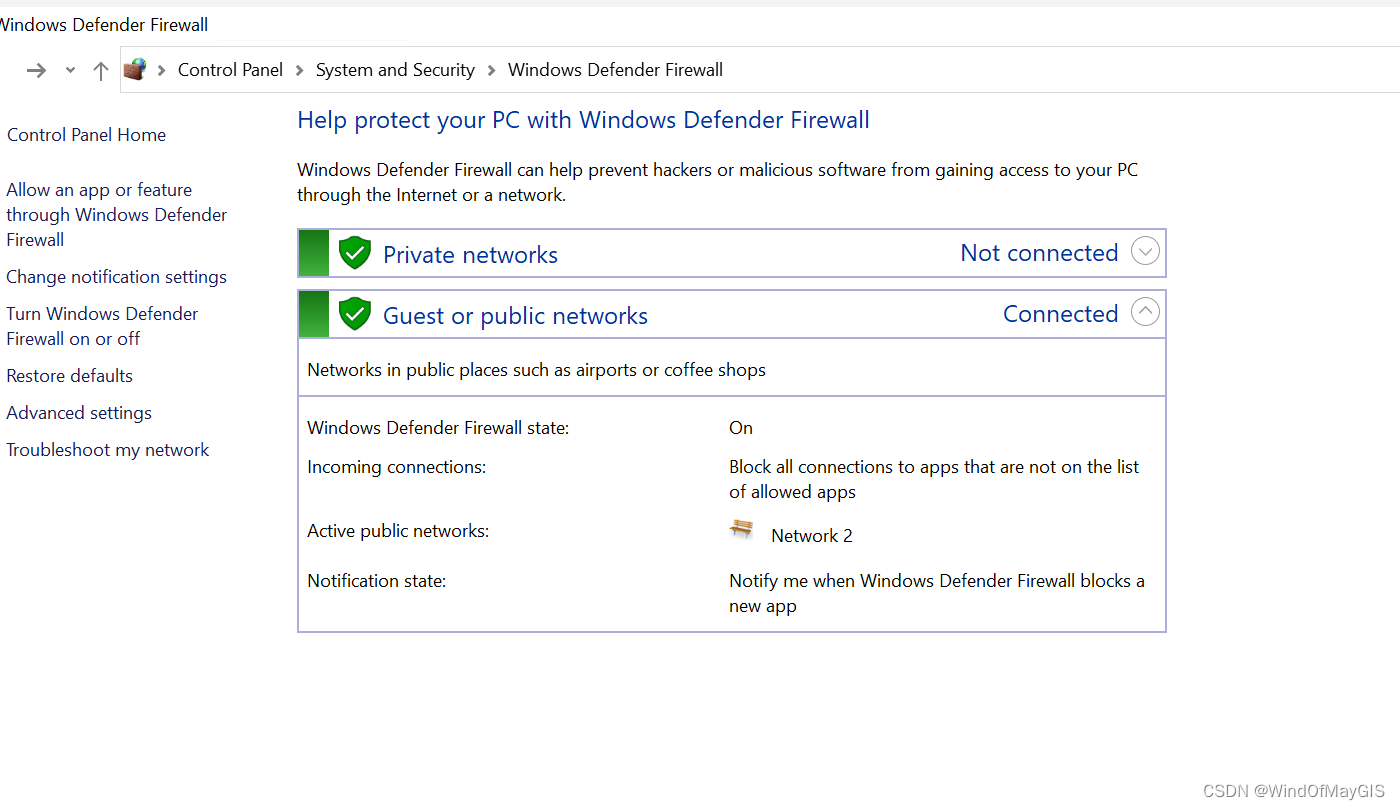
- 开通部分的端口和规则
入站规则中允许ICMP,新建规则
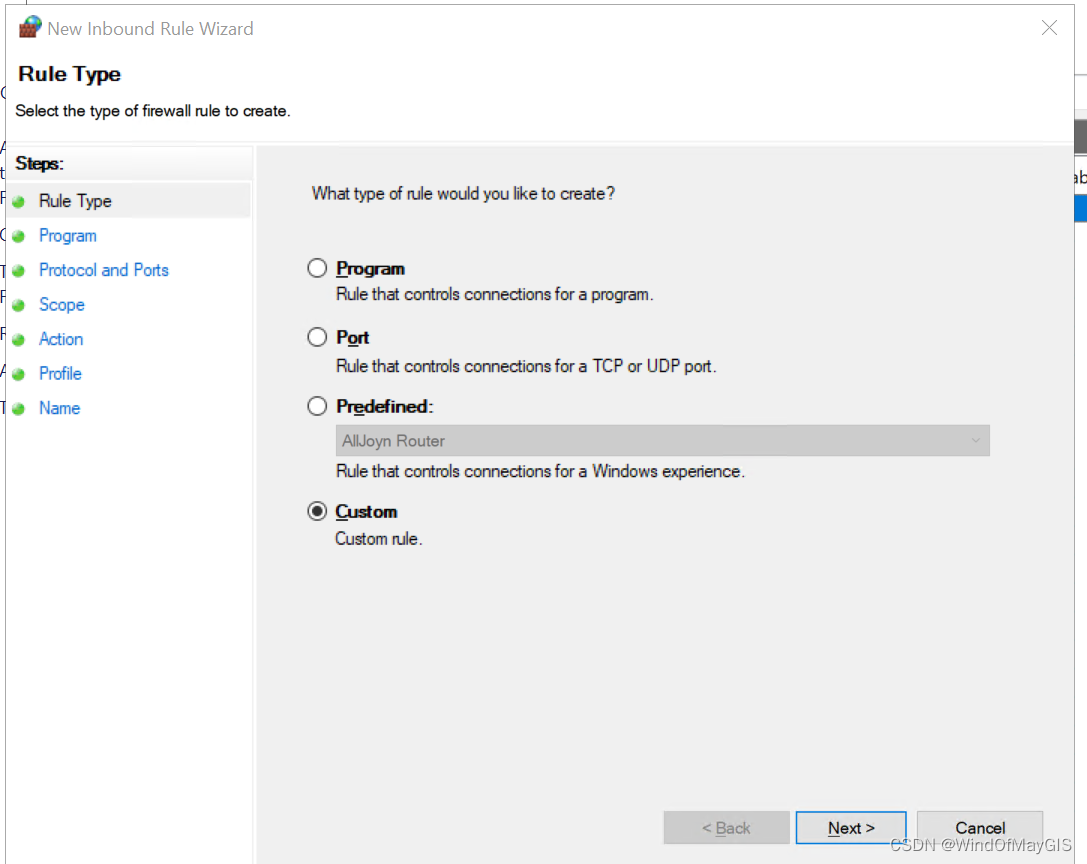
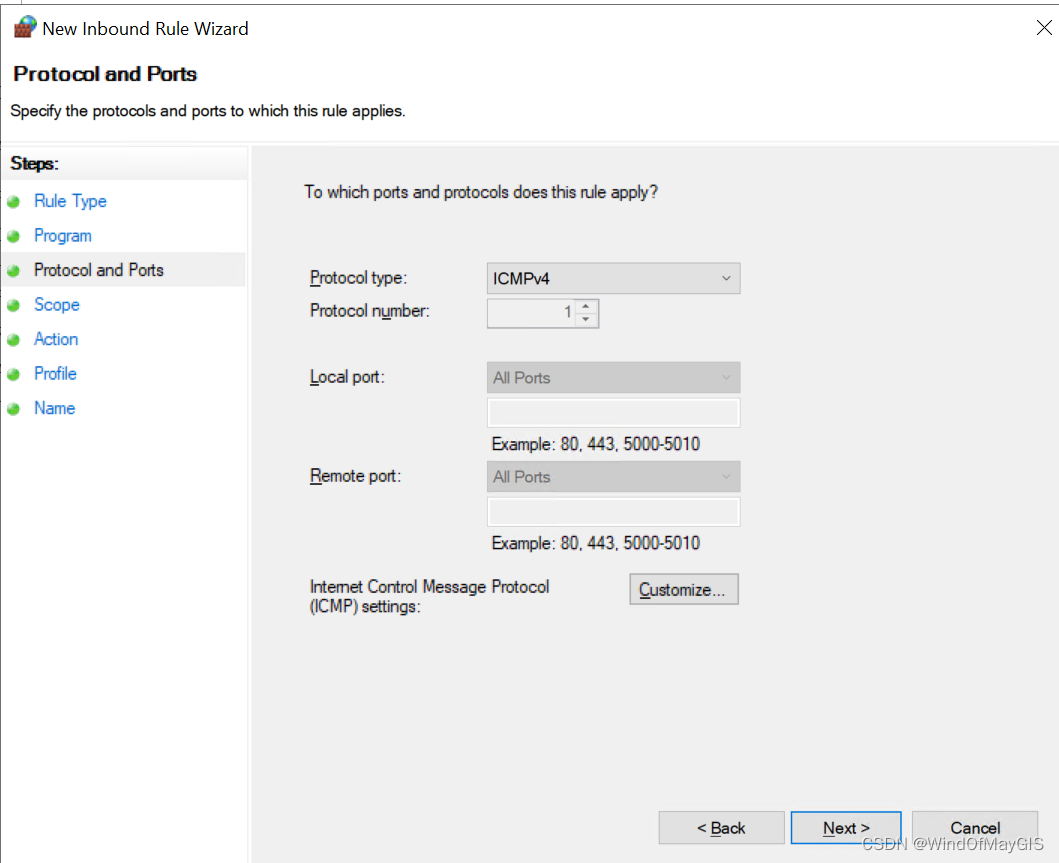
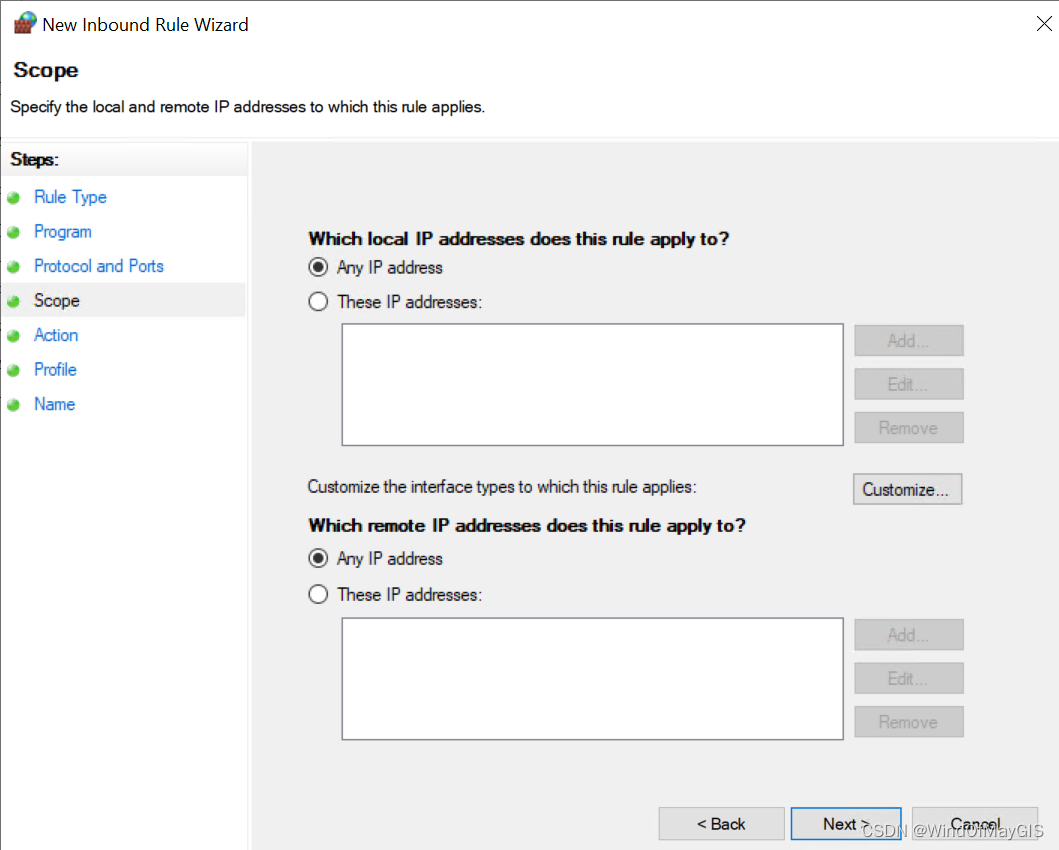
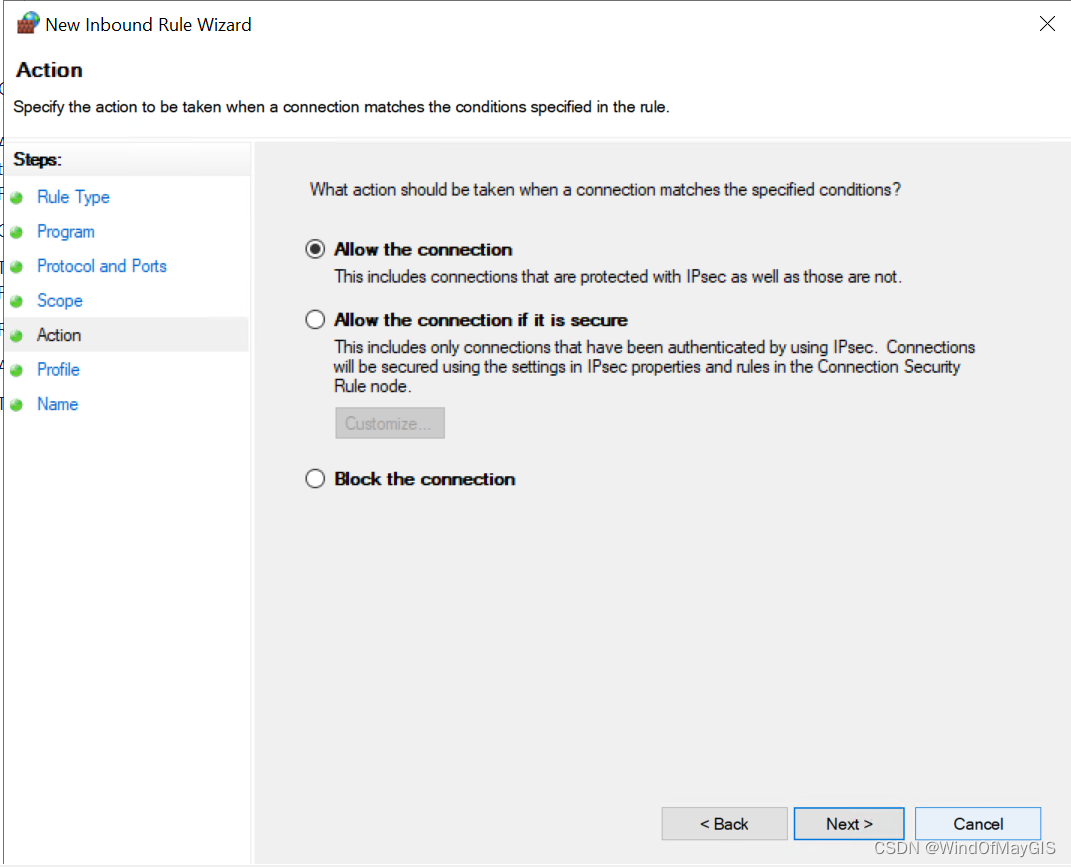
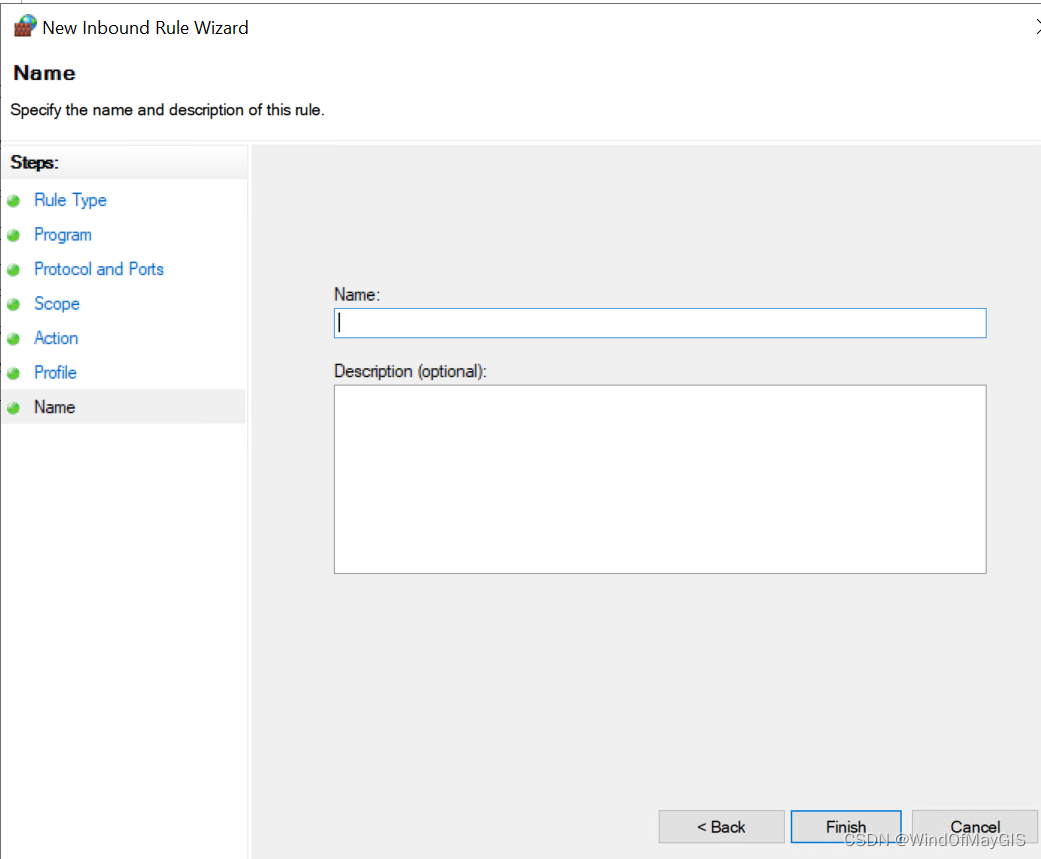
- 开通特定范围的入站和出站端口
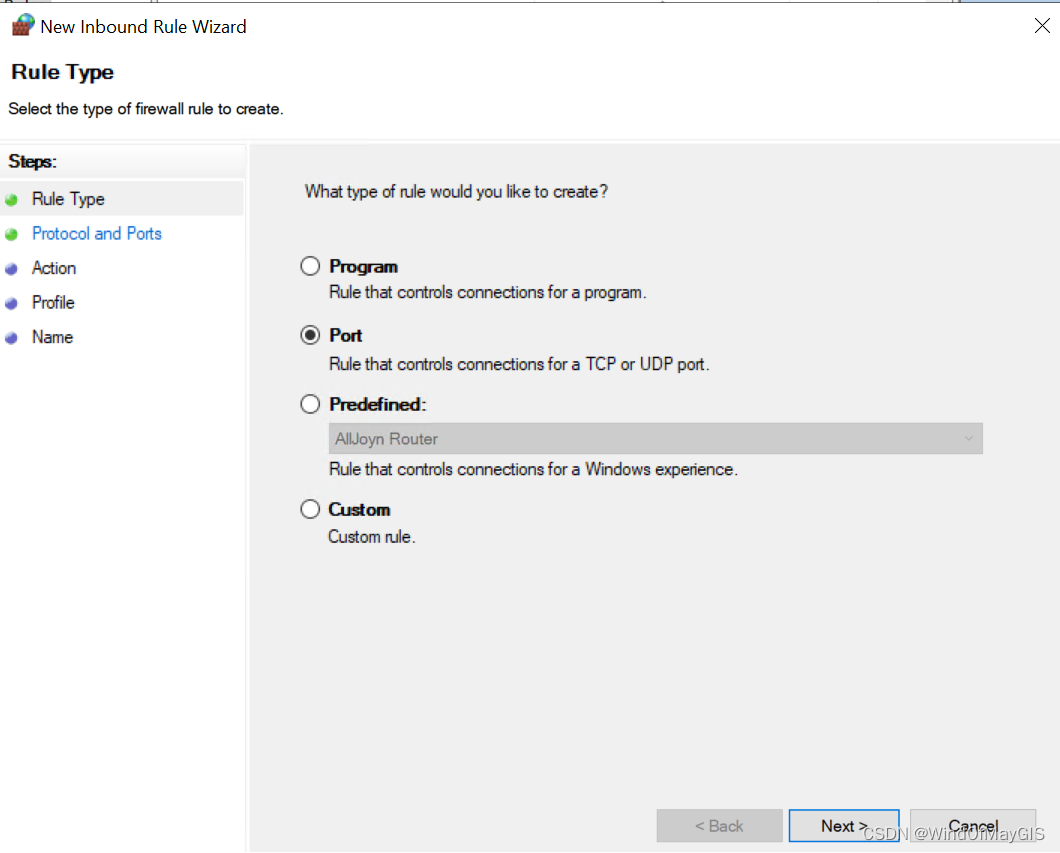
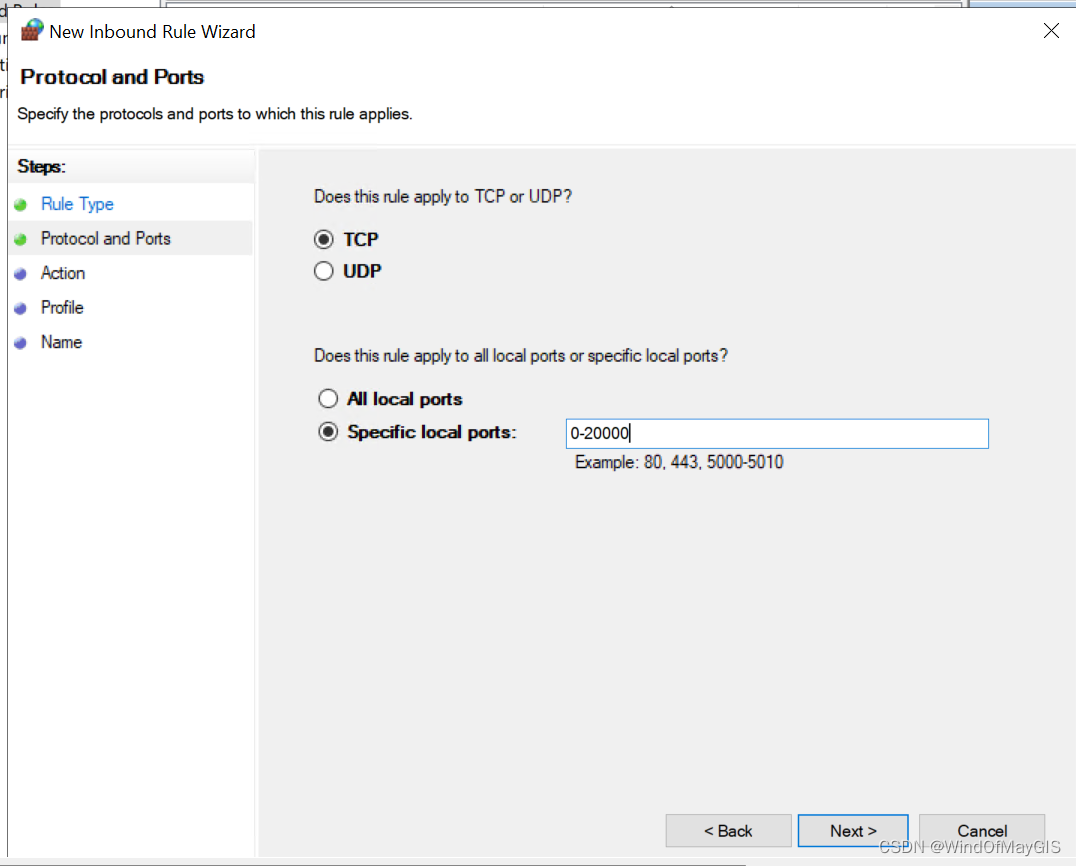
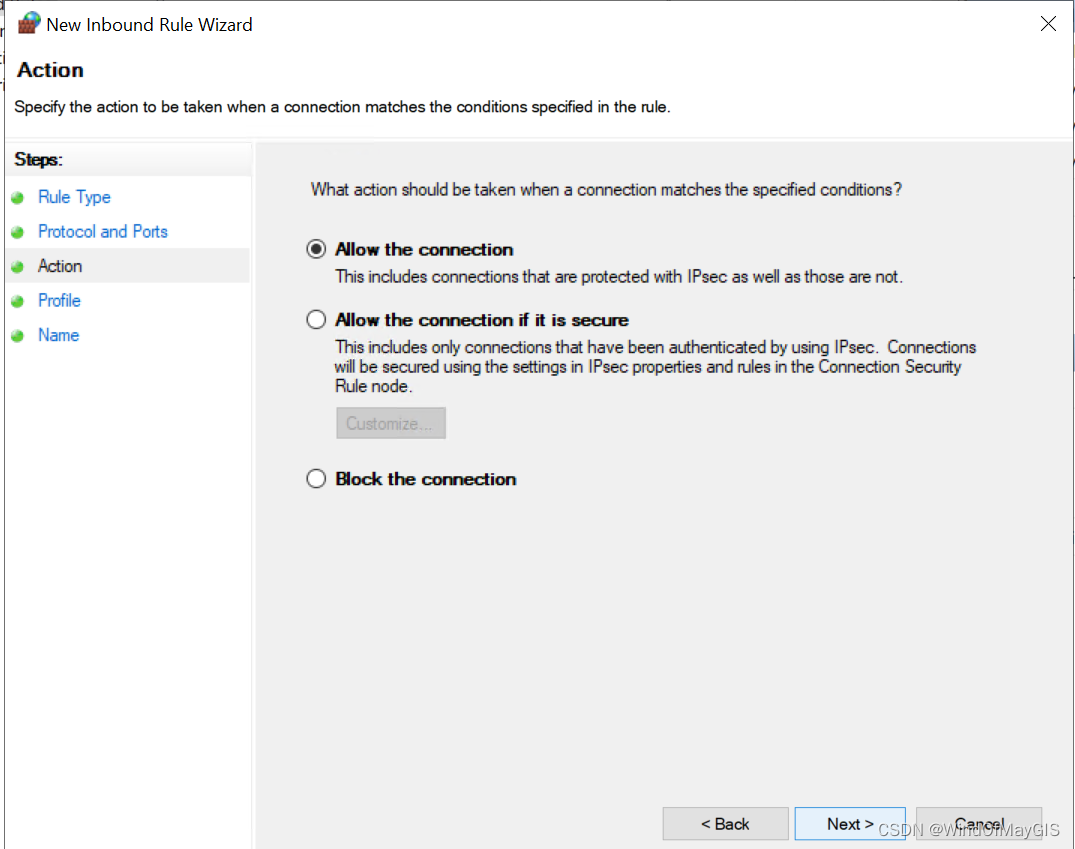
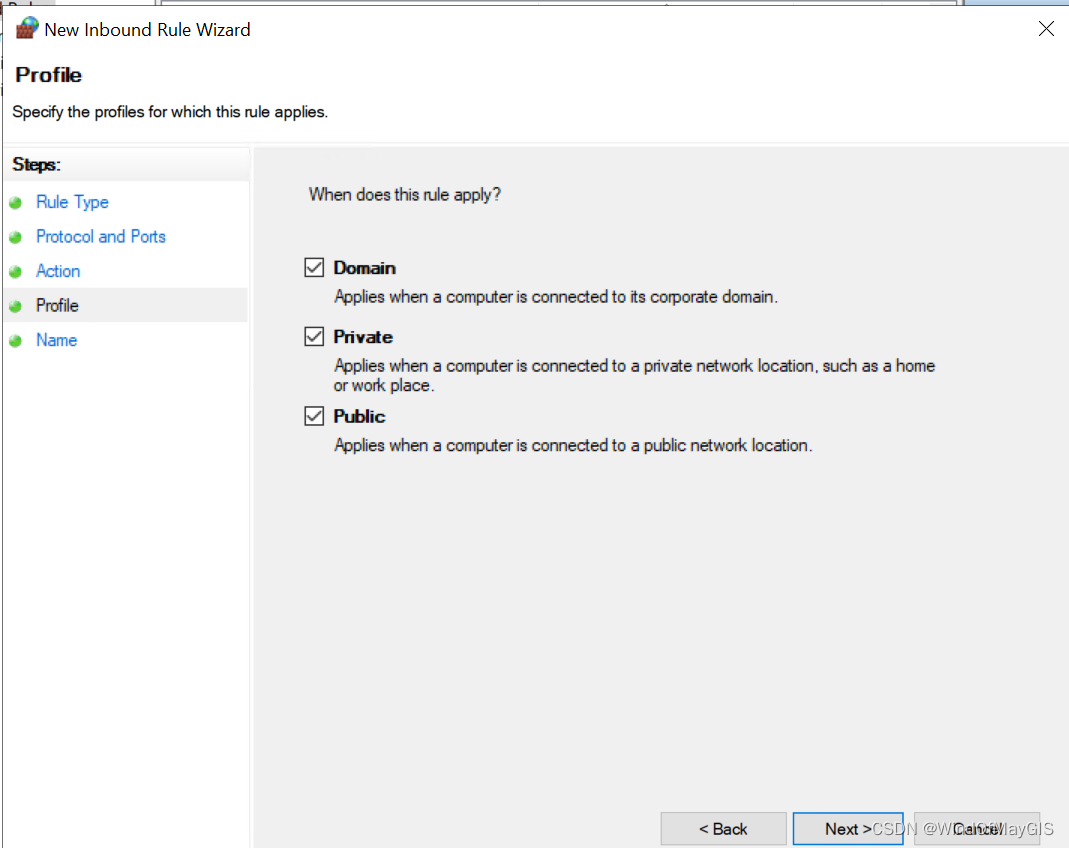

子步骤3.3 打开测试机器的telnet功能
- Telnet是什么?
telnet是teletype network的缩写,现在已成为一个专有名词,表示远程登录协议和方式,分为Telnet客户端和Telnet服务器程序
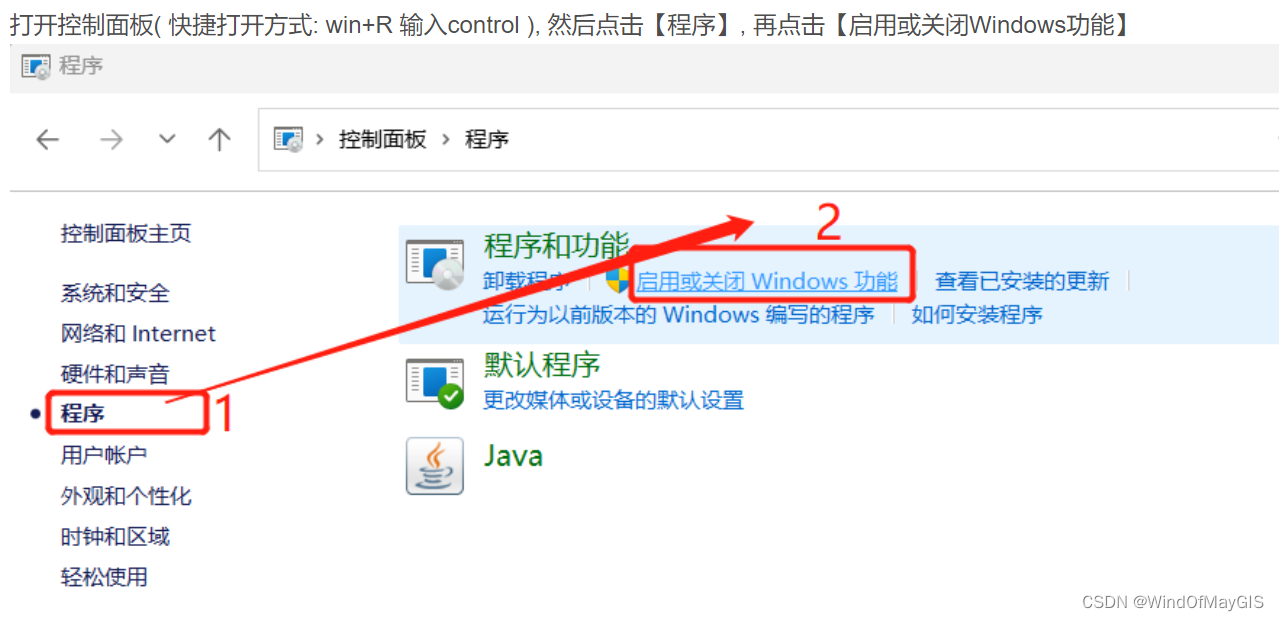
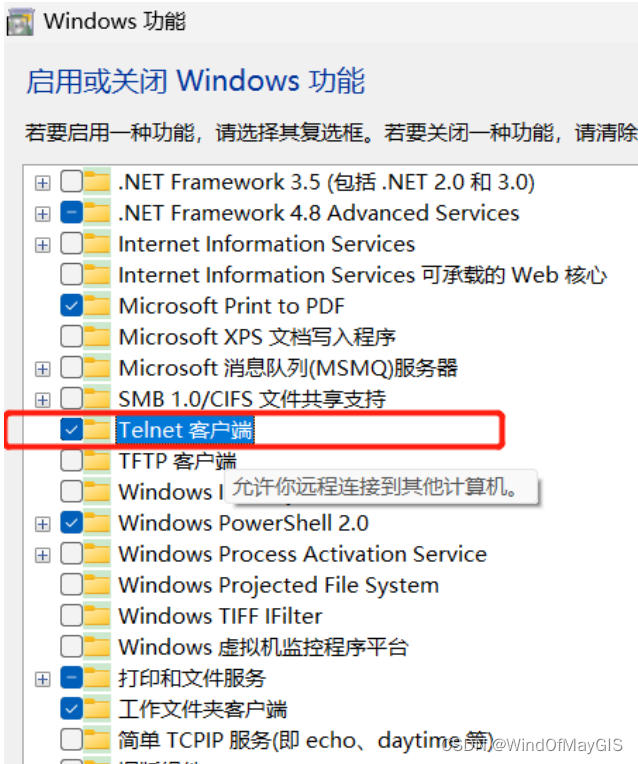
- Telnet的使用
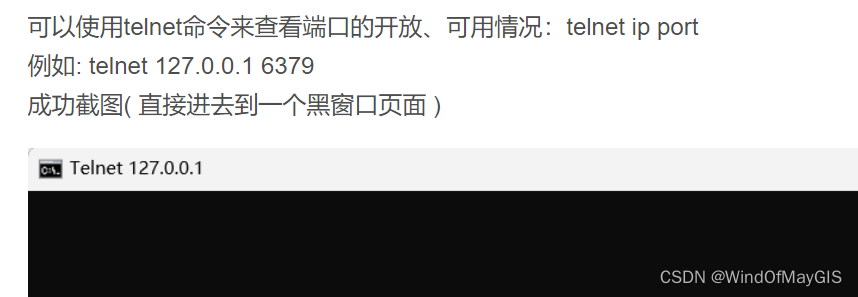
步骤4:Python Anaconda服务、应用服务部署
子步骤4.1:部署anaconda web服务
下载安装anaconda
https://www.anaconda.com/products/distribution
官网下载anaconda即可,jupyter内嵌在anaconda里,安装过程没什么好说的,点点点就完事了,注意这里要勾选上,否则cmd无法直接访问。
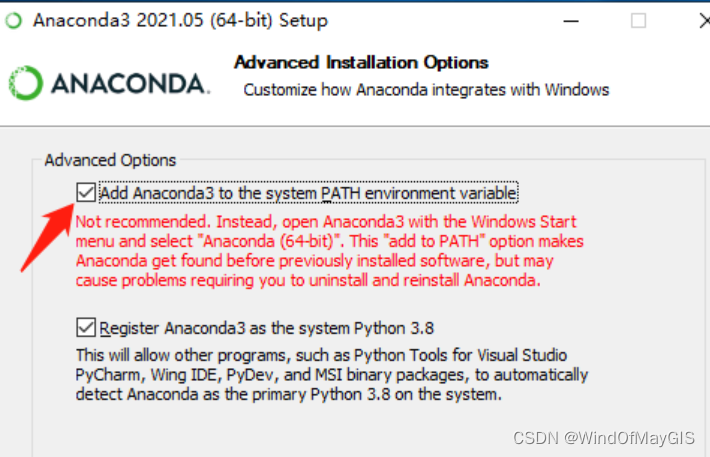
如何配置anaconda,使之可以外网访问
这里非常的重要,也很容易出问题,之前因为一个空格,活生生的改了一晚上,硬是没有找出问题来。具体的配置步骤如下:
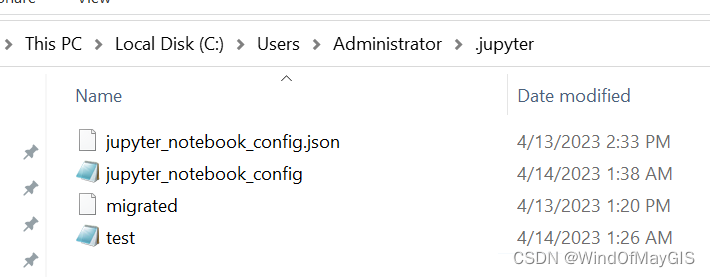
1.在桌面左下角点击开始》Anaconda3》Anaconda Prompt,输入
jupyter notebook --generate-config
得到如下存储地址
2.在Anaconda Prompt输入
ipython
from notebook.auth import passwd
passwd()
回车,然后设置密码,写两遍(输入时看不见且不显示*号)
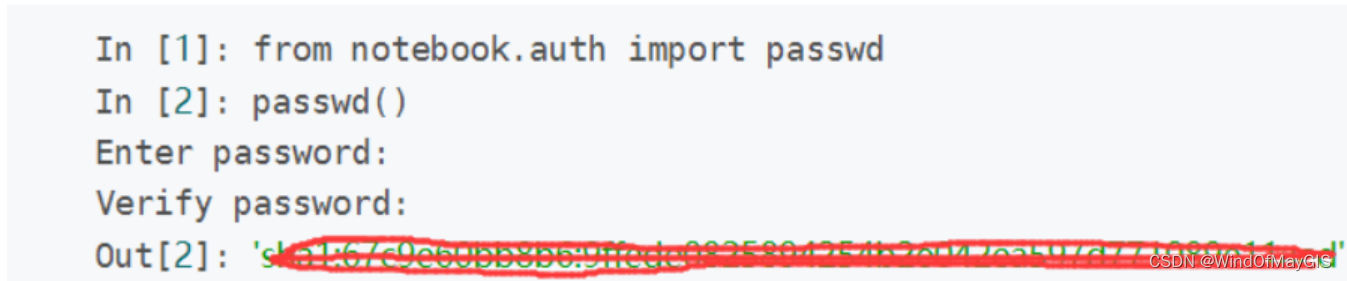
out[2]后面的这段乱码就是你的密码,复制一下保存下来
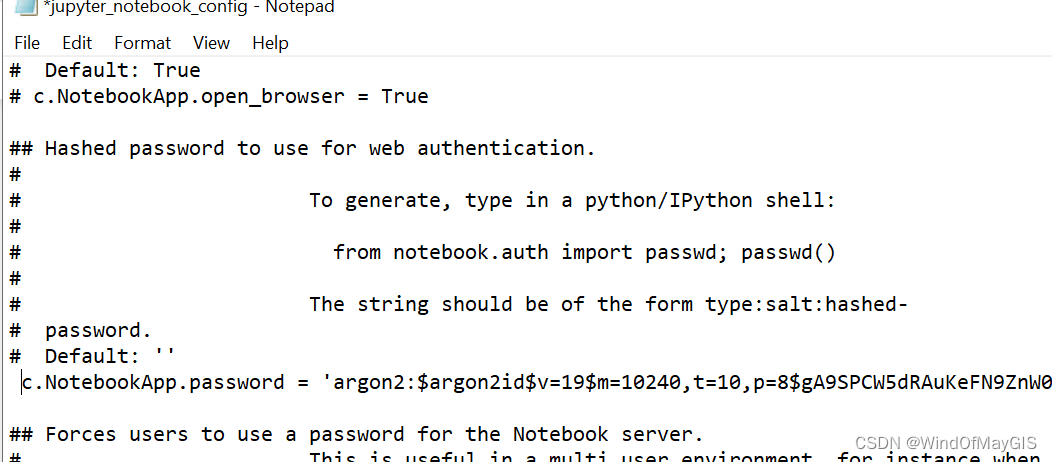
C:\Users\Administrator.jupyter\jupyter_notebook_config.py
用记事本打开这个python文件
添加如下几行命令:
c.NotebookApp.password = u' ' # 在u后的引号内输入上一步复制的密码
c.NotebookApp.ip='*'
c.NotebookApp.open_browser = False
c.NotebookApp.port =39 #可自行指定一个端口, 访问时使用该端口
之前是因为多了个空格,怎么都没有找到,所以无法排除错误
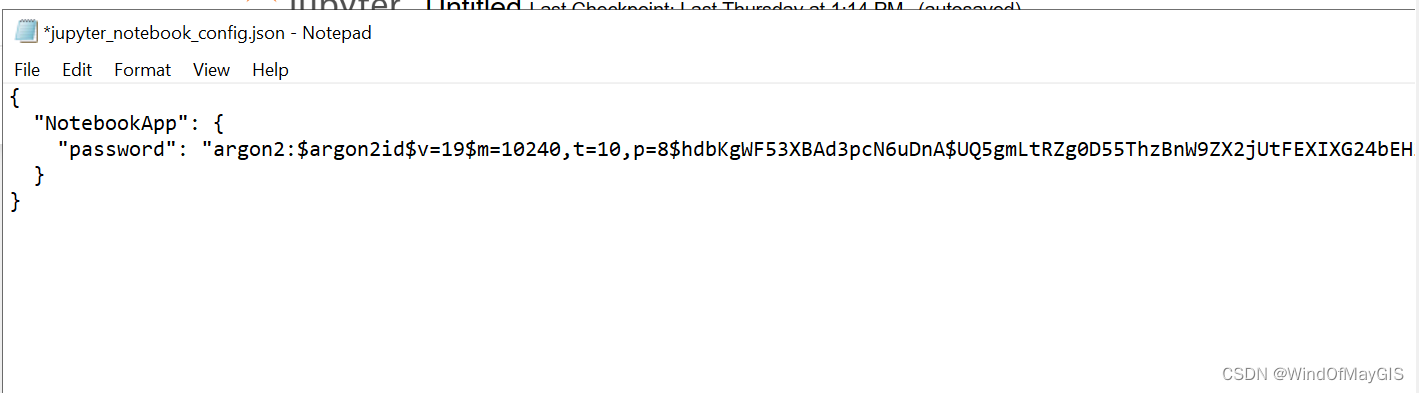
同时,还需要给JSON文件修改一下密码
4.之前已经开通了范火墙的端口范围了,这里不再开通了;
5.在服务器命令行中输入jupyter notebook开启
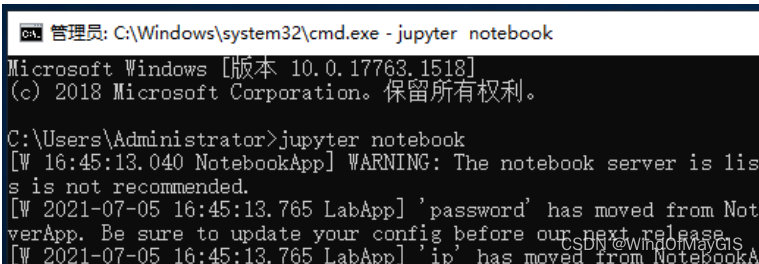
6.在本地就可以通过浏览器访问 http:// 公网ip:port(例如:http://127.0.0.1:39)远程访问jupyter
如:http://13.49.102.116:8888/tree?
主要参考:https://zhuanlan.zhihu.com/p/440080687
子步骤4.2:部署flask服务,使之可以外网访问
- Falsk:小而轻,极容易上手,第三方提供的组件多,加起来可以完全覆盖Django。
- Flask应用构建示例
1.安装flask
pip install Flask
2.验证是否已经安装成功,若import没有报错,即是已经安装成功:
import flask
3.我用的是jupyter notebook环境,写一个简单的flask程序:
#export
# 【整体流程】
# 在app.py程序文件中,app是flask的实例,功能就是接受来自web服务器的请求,
# 1、浏览器将请求给web服务器,web服务器将请求给app ,
# 2、app收到请求,通过路由找到对应的视图函数,然后将请求处理,得到一个响应response
# 3、然后app将响应返回给web服务器,
# 4、web服务器返回给浏览器,
# 5、浏览器展示给用户观看,流程完毕。
# 【1、初始化】
# 所有的Flask都必须创建程序实例
# web服务器把客户端所有的请求都转发给这个程序实例,程序实例是Flask的对象
# 一般情况下用如下方法实例化
# Flask类只有一个必须指定的参数,即程序主模块或者包的名字,__name__是系统变量,该变量指的是本py文件的文件名
from flask import Flask
app = Flask(__name__)
# 【2、路由和视图函数】
# 客户端发送url给web服务器,web服务器将url转发给flask程序实例,程序实例
# 需要知道对于每一个url请求启动哪一部分代码,所以保存了一个url和python函数的映射关系。
# 处理url和函数之间关系的程序,称为路由
# 在flask中,定义路由最简便的方式,是使用程序实例的app.route装饰器,把装饰的函数注册为路由
@app.route('/')
def cdc_say():
return "Hello, Flask !"
@app.route('/angela')
def angela_say():
return "Hi, I'm angela !"
@app.route('/alex')
def alex_say():
return "Hay, I'm alex !"
# 【3、程序实例用run方法启动flask集成的开发web服务器】
# __name__ == '__main__'是python常用的方法,表示只有直接启动本脚本时候,才用app.run方法
# 如果是其他脚本调用本脚本,程序假定父级脚本会启用不同的服务器,因此不用执行app.run()
# 服务器启动后,会启动轮询,等待并处理请求。轮询会一直请求,直到程序停止。
if __name__ == '__main__':
print('dd',__name__)
app.run()
# app.run( )
4.跑起来,得到如下结果:

在Chrome浏览器地址栏输入: http://127.0.0.1:5000/
如果无法访问,多半是因为anaconda的问题,可以直接保存为Python文件,然后用Python命令来跑。
主要参考:https://blog.csdn.net/qinwolf_/article/details/128762630
子步骤4.3:部署Django服务,是之可以外网访问
子步骤4.4:构建IBM qiskit开发环境
参考地址:
https://qiskit.org/documentation/partners/qiskit_ibm_runtime/getting_started.html
pip install qiskit
pip install qiskit-ibm-runtime
from qiskit_ibm_runtime import QiskitRuntimeService
# Save an IBM Quantum account.
QiskitRuntimeService.save_account(channel="ibm_quantum", token="MY_IBM_QUANTUM_TOKEN")
token的生成地址如下:
https://quantum-computing.ibm.com/account?needs_refill=true
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
program_inputs = {'iterations': 1}
options = {"backend_name": "ibmq_qasm_simulator"}
job = service.run(program_id="hello-world",
options=options,
inputs=program_inputs
)
print(f"job id: {job.job_id()}")
result = job.result()
print(result)
job的运行结果如下:
其他注意事项
- 同时开通安全组和防火墙的CIMP、TCP端口,才有效;
- Anaconda的config.py文件中不能多空格;
- 设置anaconda远程访问需要配置两处密码;
- AWS每次关机后,IP值会变,公网IP,所以需要重新找到对应的IP;