T.-C. Wang et al., “Video-to-Video Synthesis,” arXiv:1808.06601 [cs], Dec. 2018, Accessed: Nov. 03, 2020. [Online]. Available: http://arxiv.org/abs/1808.06601.
论文项目地址: https://tcwang0509.github.io/vid2vid/
目录
Abstract
Introduction
Related Work
1. GANs
2. Unconditional video synthesis
3. Future video prediction
4. video-to-vide synthesis
Video-to-Video Synthesis
序列生成器
基本原理
trick1: 通过光流估计利用帧间冗余
trick2: 前景-背景先验
trick3: Multimodal Synthesis
生成器网络结构
判别器
损失函数
实验
数据集
Baseline
评价指标
结果
如下图所示:人脸
跳舞视频
道路视频
Discussion
Abstract
video-to-video synthesis: 学习一个从输入视频(如一系列语义分割组成的视频)到输出视频(如真实场景)的映射.
目前(2018年底)的研究现状: 尽管image-to-image得到了很好的研究,但视频到视频的研究害很少。如果直接采用image-to-image的技术,在强行把每一帧拼到一起得到视频,则视频质量很低,看起来也不连贯。
本文的工作: 提出了一个基于GAN的video-to-video synthesis方法。并在三种不同类型的场景(分割、骨架和姿态)下进行了验证。
本文的效果: 可以达到2k的分辨率和最长30s的长度,远好于SOTA.
Introduction
生成视频很有意义, 可以应用在计算机视觉、机器人、计算机图形学等领域。目前有根据已有帧预测futer video的研究;有无条件的视频生成。但这篇文章inspired by其他特定目的的视频处理方法,如视频去噪、视频取模糊等,研究了视频到视频的条件生成任务。
具体而言,本文将视频到视频的图像合成任务看作了分布匹配问题,通过条件GAN将分割视频、骨架视频等转换为真实的视频。
文章在多个数据集上进行了尝试,输入的格式包括分割、骨架和姿态,能够产生2k的分辨率和最长30s的长度,远好于SOTA.
1. GANs
文章使用了条件GAN, 以manipulable(可操作的) semantic representations作为条件输入。
2. Unconditional video synthesis
从随机向量生成视频,如VGAN使用了时空卷积网络,TGAN将latent code映射为图片,再转换为视频;MoCoGAN使用RNNl;
因为无条件的设定,所以该类方法的重建视频通常分辨率较低且时间短。
3. Future video prediction
用观测到的帧预测未来的帧,它以图像重建loss 进行优化,常常会导致模糊,同时也无法完成长时间的预测毕竟信息有限。
video-to-video合成问题与视频预测在本质上是不同的。因为video-to-video合成不会尝试预测物体的运动,而是根据已有的条件信息来产生另一个域的对应信息。
4. video-to-vide synthesis
视频去噪、去模糊、去雨等也可以看作是video-to-vide synthesis问题。但这类研究都是对特定任务的,因此不能直接把已有的去噪之类的方法拿来做为本文的方法。
Video-to-Video Synthesis
 : 输入视频序列,比如是语义分割帧的序列或者边缘图序列;
: 输入视频序列,比如是语义分割帧的序列或者边缘图序列;
 :真实场景的(目标)视频序列;
:真实场景的(目标)视频序列;
本篇文章的目标:找到从到重建视频 的映射。从而使二者的条件分布相同:
的映射。从而使二者的条件分布相同:

根据GAN理论,目标函数为:
![\max_{D}\min_{G} E_{(x_{1}^T,s_{1}^T)} [\log D(x_{1}^T,s_{1}^T)] + E_{s_{1}^T} [\log (1 - D(G(s_{1}^T),s_{1}^T))]](https://private.codecogs.com/gif.latex?%5Cmax_%7BD%7D%5Cmin_%7BG%7D%20E_%7B%28x_%7B1%7D%5ET%2Cs_%7B1%7D%5ET%29%7D%20%5B%5Clog%20D%28x_%7B1%7D%5ET%2Cs_%7B1%7D%5ET%29%5D%20+%20E_%7Bs_%7B1%7D%5ET%7D%20%5B%5Clog%20%281%20-%20D%28G%28s_%7B1%7D%5ET%29%2Cs_%7B1%7D%5ET%29%29%5D)
以此为理论依据,论文提出了新的网络结构去完成video-to-vide synthesis任务。
序列生成器
基本原理
通过假设马尔可夫过程来简化图像生成任务,即认为条件分布 可以分解为
可以分解为

也就是说视频仅仅通过部分的帧序列即可还原,并且第t帧 只与下面3个有关:
只与下面3个有关:
(1) 当前输入帧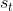 ;
;
(2) 之前的L个输入帧 ;
;
(3)之前的L个生成帧 。
。
通过训练一个网络F,来使用第t帧 建模条件分布
建模条件分布 .
.
通过递归使用F来得到最终的输出,即重建的视频。
L的取值显然需要trade-off,当L太大时,太耗卡;当L过小时,质量不好。因此文章选择了L=2;
trick1: 通过光流估计利用帧间冗余
除了连续帧之间恰好被遮挡的物体,其他情况下使用光流估计利用帧间冗余都是有效的。通过把F建模为

其中, 表示element-wise操作,1表示全1图像。这样,第一部分就是考虑到光流估计的前一帧;第二部分即为合成的有新像素的图片。上式中各项的含义为
表示element-wise操作,1表示全1图像。这样,第一部分就是考虑到光流估计的前一帧;第二部分即为合成的有新像素的图片。上式中各项的含义为
-
 : 估计的从
: 估计的从 到
到 的光流;W是光流预测网络。文章通过输入的帧
的光流;W是光流预测网络。文章通过输入的帧 和之前合成的帧来估计光流.
和之前合成的帧来估计光流.  的意思是使用
的意思是使用 来wrap.
来wrap.
-
 是由生成器H合成的图片;
是由生成器H合成的图片;
-
 是遮挡mask,取值为[0,1]之间的连续值,M则是mask预测网络。通过使用连续取值而不是bool值来更好地处理放大区域(也就是图片放大之后会变模糊,一些像素看起来就好像既被遮挡了又没被遮挡),从而更好地恢复细节。
是遮挡mask,取值为[0,1]之间的连续值,M则是mask预测网络。通过使用连续取值而不是bool值来更好地处理放大区域(也就是图片放大之后会变模糊,一些像素看起来就好像既被遮挡了又没被遮挡),从而更好地恢复细节。
trick2: 前景-背景先验
这个trick只针对分割语义的输入情况,此时F可以进一步建模为

其中,  是前景模型;
是前景模型; 是后景模型;
是后景模型; 是由输入的分割语义得到的背景mask. 实验证明,该trick能够提高指标。
是由输入的分割语义得到的背景mask. 实验证明,该trick能够提高指标。
trick3: Multimodal Synthesis
论文中好像没有明确表示是否适用于所有输入,但只描述了在语义分割下的原理。能够使得同样的输入得到多个不同视觉效果的输出,
生成器网络结构
生成器使用了粗-精细两部分重建的结构。其中,粗糙重建的网络结构如下图所示

可见,它以输入序列和之前的合成序列为网络输入,每部分的帧被concat一起然后经过几个res block形成了两个包含high-level features的中间层。然后,将两个中间层加到一起并且feed into两个分离的残差网络。第一个网络H得到由生成器H合成的图片 ;第二个网络表示M和W,得到了光流和遮挡mask。
接下来是全部的网络结构,即再加上两个精细还原结构:

通过相加将G2提取的特征和G1的输出组合到一起并decode得到最终的高分辨率结果。
判别器
文章使用了两个鉴别器来缓解mode collapse并提升效果。
条件图像鉴别器DI: 判断每一个输出帧是否真实,即对真实的pair  输出1;对假pair
输出1;对假pair  输出0;
输出0;
条件视频鉴别器DV: 在给定相同光流的情况下判断生成的序列是否真实。对对真实的pair  输出1;对假pair
输出1;对假pair  输出0;
输出0;
使用了采样算子来实现上面的操作。
损失函数
损失函数如下

其中LI是图像部分条件GAN的loss,使用了采样算子
![E_{\phi_I(x_1^T,s_1^T)} [\log D_I(x_i,s_i)] + E_{\phi_I(\hat{x}_1^T,s_1^T)} [\log (1 - D_I(\hat{x}_i,s_i))]](https://private.codecogs.com/gif.latex?E_%7B%5Cphi_I%28x_1%5ET%2Cs_1%5ET%29%7D%20%5B%5Clog%20D_I%28x_i%2Cs_i%29%5D%20+%20E_%7B%5Cphi_I%28%5Chat%7Bx%7D_1%5ET%2Cs_1%5ET%29%7D%20%5B%5Clog%20%281%20-%20D_I%28%5Chat%7Bx%7D_i%2Cs_i%29%29%5D)
LV是视频部分条件GAN的loss,使用了采样算子
![E_{\phi_V (w_1^{T-1},x_1^T,s_1^T)} [\log D_V(x_{i-K}^{i-1},w_{i-K}^{i-2})] + E_{\phi_V (w_1^{T-1},\hat{x}_1^T,s_1^T)} [\log (1 - D_V(\hat{x}_{i-K}^{i-1},w_{i-K}^{i-2}))]](https://private.codecogs.com/gif.latex?E_%7B%5Cphi_V%20%28w_1%5E%7BT-1%7D%2Cx_1%5ET%2Cs_1%5ET%29%7D%20%5B%5Clog%20D_V%28x_%7Bi-K%7D%5E%7Bi-1%7D%2Cw_%7Bi-K%7D%5E%7Bi-2%7D%29%5D%20+%20E_%7B%5Cphi_V%20%28w_1%5E%7BT-1%7D%2C%5Chat%7Bx%7D_1%5ET%2Cs_1%5ET%29%7D%20%5B%5Clog%20%281%20-%20D_V%28%5Chat%7Bx%7D_%7Bi-K%7D%5E%7Bi-1%7D%2Cw_%7Bi-K%7D%5E%7Bi-2%7D%29%29%5D)
LW则是光流损失,包括两个部分,一个是估计的光流和真实的光流之间的区别;另一个是由光流估计的帧和真实帧之间的区别:

实验
数据集
文章共使用了如下数据集:
- Cityscapes
- Apolloscape
- Face Video Dataset
- Dance Video Dataset
Baseline
使用了两个baseline
- pix2pixHD,通过生成图片并拼接来比较;
- COVST
评价指标
使用了基于Amazon Mechanical Turk的人类主观评价 以及 FID。
结果
如下图所示:人脸

跳舞视频

道路视频

定量比较

Discussion
主要的缺点是
- 对一些场景不能很好地重建,如正在转弯的车,也许可以通过加3D线索,如深度信息来解决;
- 无法保证同意物体在整个场景下保持不变;
- 难以完成语义操纵。