1.简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop生态的三大核心组件分别是MapReduce分布式计算框架,HDFS(Hadoop Distributed File System)分布式数据存储,YRAN资源管理器,其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。
集群环境:
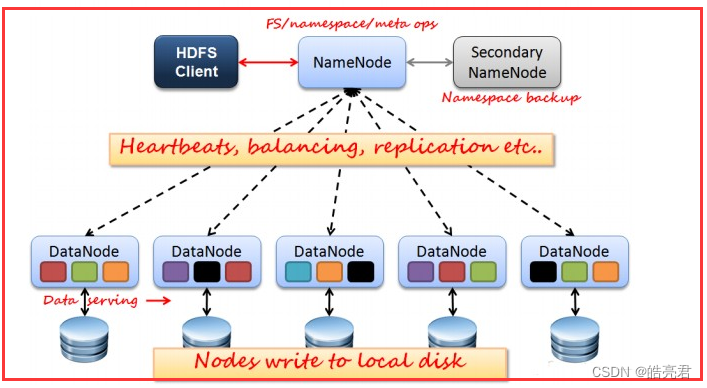
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
-
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
-
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
-
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
2.环境准备
| 节点类型 |
节点主机名 |
节点IP地址 |
| 主节点 |
master |
192.168.239.128 |
| 从节点 |
slave1 |
192.168.239.129 |
| 从节点 |
slave2 |
192.168.239.130 |
修改3台机器的/etc/hosts文件
在启动集群时,主节点需要通过主机名远程访问从节点,所以需要让主节点能够识别从节点的主机名。
vi /etc/hosts
192.168.239.128 master
192.168.239.129 slave1
192.168.239.130 slave2
配置免密登录
在3台机器上分别执行以下命令,生成公钥和秘钥文件。
ssh-keygen -t rsa
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R2bAuFgl-1663742215304)(https://note.youdao.com/yws/res/36430/WEBRESOURCE83000fc822eb59eaa0e67a9d86b0a710)]](https://img-blog.csdnimg.cn/06432173dcd1443aa14614032418e135.png)
以主机名为master的节点为例查看
ll ~/.ssh/
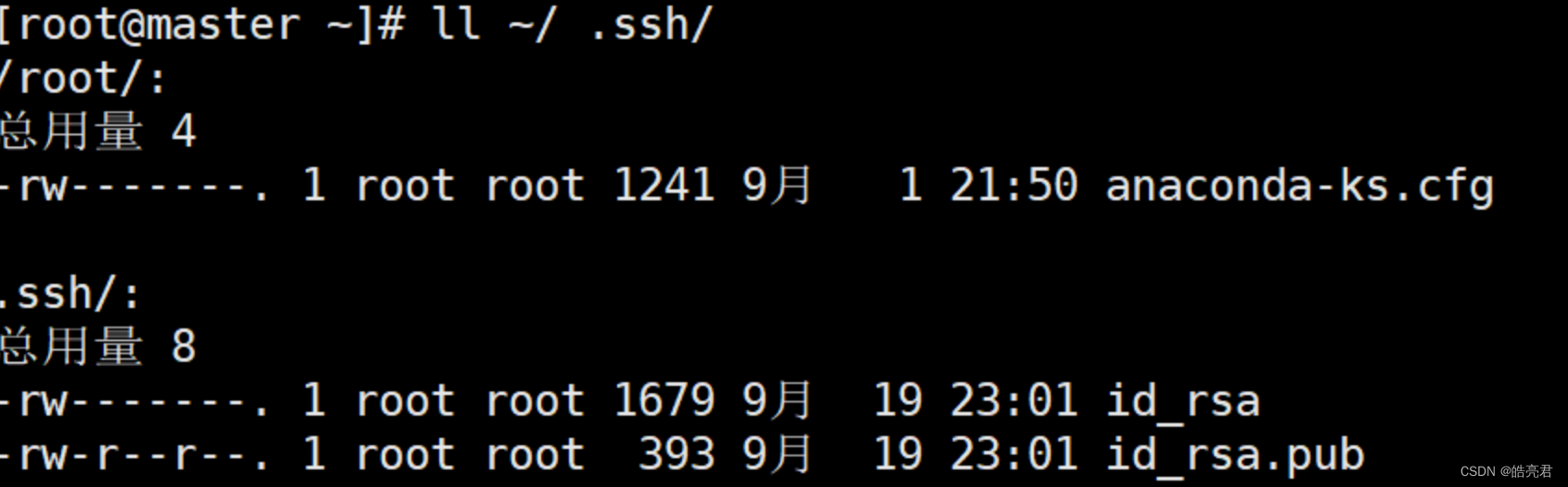
将公钥复制到需要免密登录的节点(包含自己)。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys slave1:~/
scp ~/.ssh/authorized_keys slave2:~/
在从节点slave1和slave2这两台主机上执行下面操作
cat ~/authorized_keys >> ~/.ssh/authorized_keys
最后在主机名为master的节点测试免密登录
[root@master ~]# ssh slave1
Last login: Mon Sep 19 22:31:09 2022 from 192.168.239.1
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@master ~]#
配置时间同步
只要集群涉及多个节点,就需要对这些节点做时间同步。
三个节点都需要设置
[root@master ~]# yum install -y ntpdate
[root@master ~]# ntpdate -u ntp.sjtu.edu.cn
19 Sep 23:26:40 ntpdate[3807]: step time server 119.28.183.184 offset 107.125039 sec
配置到定时任务中去执行保证时间永远是同步的
vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
3.安装hadoop
hadoop官网下载地址: 点我跳转
本文使用的版本是3.2.4版本,下载完上传hadoop-3.2.4.tar.gz到服务器的/home/soft目录下并解压
cd /home/soft
tar -zxvf hadoop-3.2.4.tar.gz
Hadoop目录有两个重要的目录: bin目录和sbin目录。为了操作Hadoop方便,配置下环境变量,运行Hadoop需要至少jdk8环境。
安装JDK,如果已安装请忽略
#jdk安装
yum install -y java-1.8.0-openjdk
#jdk相关工具
yum install -y java-1.8.0-openjdk-devel
设置hadoop环境变量,方便在任意目录执行hadoop命令
[root@master soft]# vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/soft/hadoop-3.2.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行下面的刷新环境变量
source /etc/profile
3.修改Hadoop配置文件
配置文件都在安装目录的 etc/hadoop目录下
修改Hadoop的配置文件,主要的为下:
- hadoop-env.sh: Hadoop的环境变量配置文件
- core-site.xml: Hadoop的扩展配置文件
- hdfs-site.xml: HDFS的扩展配置文件
- mapred-site.xml: MapReduce的扩展文件
- yarn-site.xml: YARN的扩展配置文件
- workers: 从节点的配置文件
切换到配置文件存储目录
cd /home/soft/hadoop-3.2.4/etc/hadoop/
3.1.hadoop-env.sh配置
创建hadoop数据存储路径
mkdir -p /data/hadoop_repo/logs/hadoop
增加JAVA_HOME和HADOOP_LOG_DIR环境变量
[root@master hadoop]# vi hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64/jre
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
3.2.core-site.xml配置
- fs.defaultFS: 属性值的中master需要配置问NameNode的节点主机ip,本文NameNode节点部署在主机名为master上面。
- hadoop.tmp.dir:配置hadoop数据存储路径
[root@master hadoop]# vi core-site.xml
<configuration>
<!-- 描述集群中NameNode结点的URI(包括协议、主机名称、端口号) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
3.3.hdfs-site.xml配置
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<-- node level参数,需要在每台datanode上设置,因datanode节点只有2所以设置为2-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置secondaryamenode节点地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
3.4.mapred-site.xml配置
[root@master hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.5.yarn-site.xml配置
- yarn.resourcemanager.hostname: 配置资源管理器的主机名,本文配置是主机名master机器。
[root@master hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
3.6.workers配置
设置工作节点的主机名(hosts文件中配置的)
[root@master hadoop]# vi workers
slave1
slave2
3.7.hadoop启动脚本配置
启动脚本在hadoop安装目录下的sbin目录里
cd /home/soft/hadoop-3.2.4/sbin/
编辑start-dfs.sh和stop-dfs.sh脚本
[root@master sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@master sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
编辑start-yarn.sh和stop-yarn.sh文件
[root@master sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@master sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4.启动集群
4.1.复制hadoop安装包到从节点
把改完配置文件的hadoop目录复制到另外两台重节点,soft目录必须提前在两台从节点创建好
cd /home/soft
scp -rq hadoop-3.2.4 slave1:/home/soft/
scp -rq hadoop-3.2.4 slave2:/home/soft/
4.2.格式化NameNode
在新安装的Hadoop环境master节点执行1次即可,不能重复执行.如果需要重复执行需要清空集群所有节点中的hadoop.tmp.dir属性对应的目录。
cd /home/soft/hadoop-3.2.4
bin/hdfs namenode -format
看到下面打印了successfuly就表示成功了。

4.3.关闭防火墙
方便测试先把所有节点防火墙先关闭
systemctl stop firewalld.service
4.4.启动集群
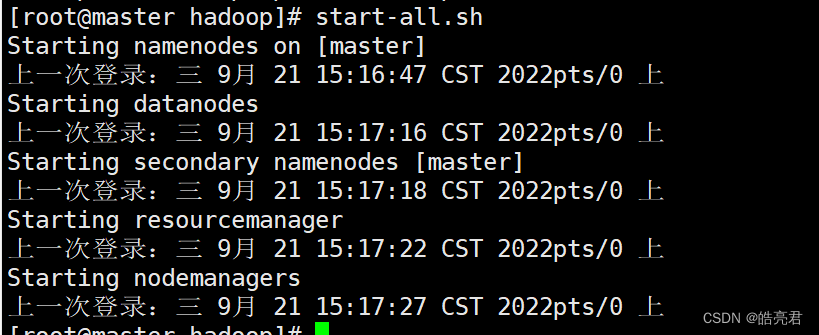
在master节点执行
start-all.sh
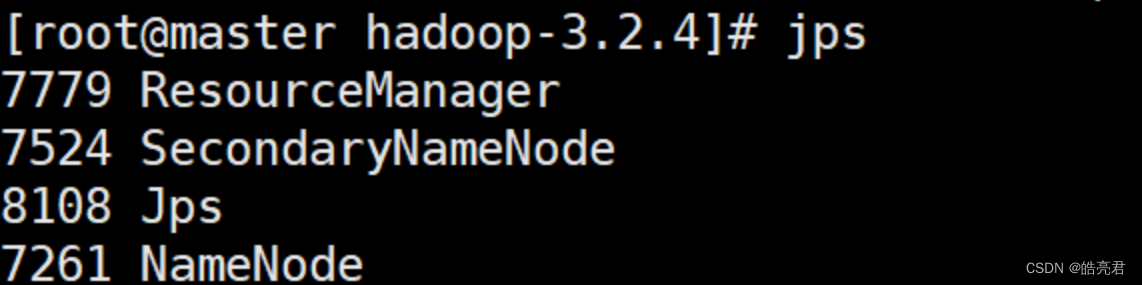
在主节点执行jps查看可以看到ResourceManager,SecondaryNameNode,NameNode这三个服务
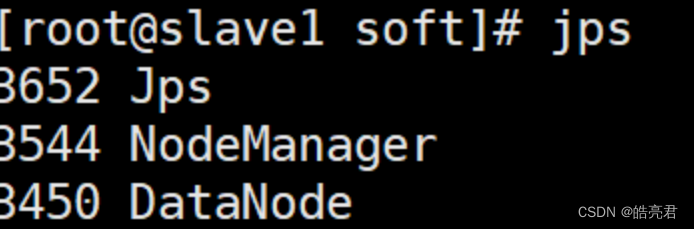
在从节点上执行jps查看可以看到启动了NodeManager和DataNode这两个服务
4.5.停止集群
在master节点执行
stop-all.sh
执行完查看各个节点可以看到进程已经全部停止了。

5.HDFS常用命令
命令格式: hdfs dfs -xxx schema://authority/path
- dfs: 全称是Distributed File System,表示操作分布式文件系统
- xxx: xxx是占位符,需要替换为具体的命令
- schema: 针对HDFS分布式系统,它是hdfs
- authority: Hadoop集群中主节点IP和对应的PORT(默认9000)
- path: 要操作的文件或目录的路径信息
put上传文件:
上传文件到HDFS根目录,执行完没有提示就表示成功,master为hadoop主节点的ip地址
hdfs dfs -put /home/soft/test.txt hdfs://master:9000/
也可以执行下面的(HDFS在执行时会根据HDOOP_HOME环境变量自动识别core-site.xml配置文件中的fs.defaultFS属性的值)
hdfs dfs -put /home/soft/test.txt /
ls查看文件列表信息
查询指定路径信息
hdfs dfs -ls /

递归显示所有文件,在ls后面加-R
hdfs dfs -ls -R /
cat查看文本内容
hdfs dfs -cat /test.txt
get下载文件
#下载文件保存到当前目录
hdfs dfs -get /test.txt
#也可以指定目录保存下载文件
hdfs dfs -get /test.txt /home/test.txt
mkdir创建目录
hdfs dfs -mkdir /test
#递归创建多级目录需要指定 -p
hdfs dfs -mkdir -p /test/abc
统计hdfs文件
以下统计根目录下的文件个数
hdfs dfs -ls / | grep /| wc -l
执行完控制台会输出: 1
显示hdfs文件名称和大小
以下输出hdfs根目录下的文件名称和文件大小
hdfs dfs -ls / | grep /| awk '{print $8,$5}'
执行完控制台会输出: /test.txt 65
rm命令删除文件
hdfs dfs -rm /test.txt
执行完控制台会输出: Deleted /test.txt
删除目录(支持递归删除,在-rm后面添加-r)
hdfs dfs -rm -r/test
执行完控制台会输出: Deleted /test
【Hadoop生态圈】其它文章如下,后续会继续更新。