2021年MathorCup高校数学建模挑战赛—大数据竞赛
A题 二手车估价问题
原题再现:
随着我国的机动车数量不断增长,人均保有量也随之增加,机动车以“二手车”形式在流通环节,包括二手车收车、二手车拍卖、二手车零售、二手车置换等环节的流通需求越来越大。二手车作为一种特殊的“电商商品”,因为其“一车一况”的特性比一般电商商品的交易要复杂得多,究其原因是二手车价格难于准确估计和设定,不但受到车本身基础配置,如品牌、车系、动力等的影响,还受到车况如行驶里程、车身受损和维修情况等的影响,甚至新车价格的变化也会对二手 车价格带来作用。目前国家并没有出台一个评判二手车资产价值的标准。一些二手车交易平台和二手车第三方估价平台都从自身的角度建立了一系列估价方法用于评估二手车资产的价值。
在一个典型的二手车零售场景,二手车一般通过互联网等线上渠 道获取用户线索,线下实体门店对外展销和售卖,俗称 O2O 门店模式。门店通过“买手”从个人或其他渠道收购二手车,然后由门店定价师定价销售,二手车商品和其他商品一样,如果定价太高滞销也会打 折促销,甚至直接以较低的价格打包批发,直至商品最终卖出。
基于以上背景,请你们团队根据附件给出的数据,通过数据分析与建模的方法帮助二手车交易平台解决下面的问题:
初赛问题
问题 1:基于给定的二手车交易样本数据(附件 1:估价训练数据),选用合适的估价方法,构建模型,预测二手车的零售交易价格,数据中会对 id 类,主要特征类等信息进行脱敏。主要数据包括车辆基础信息、交易时间信息、价格信息等,包含 36 列变量信息,其中15 列为匿名变量。字段如下:
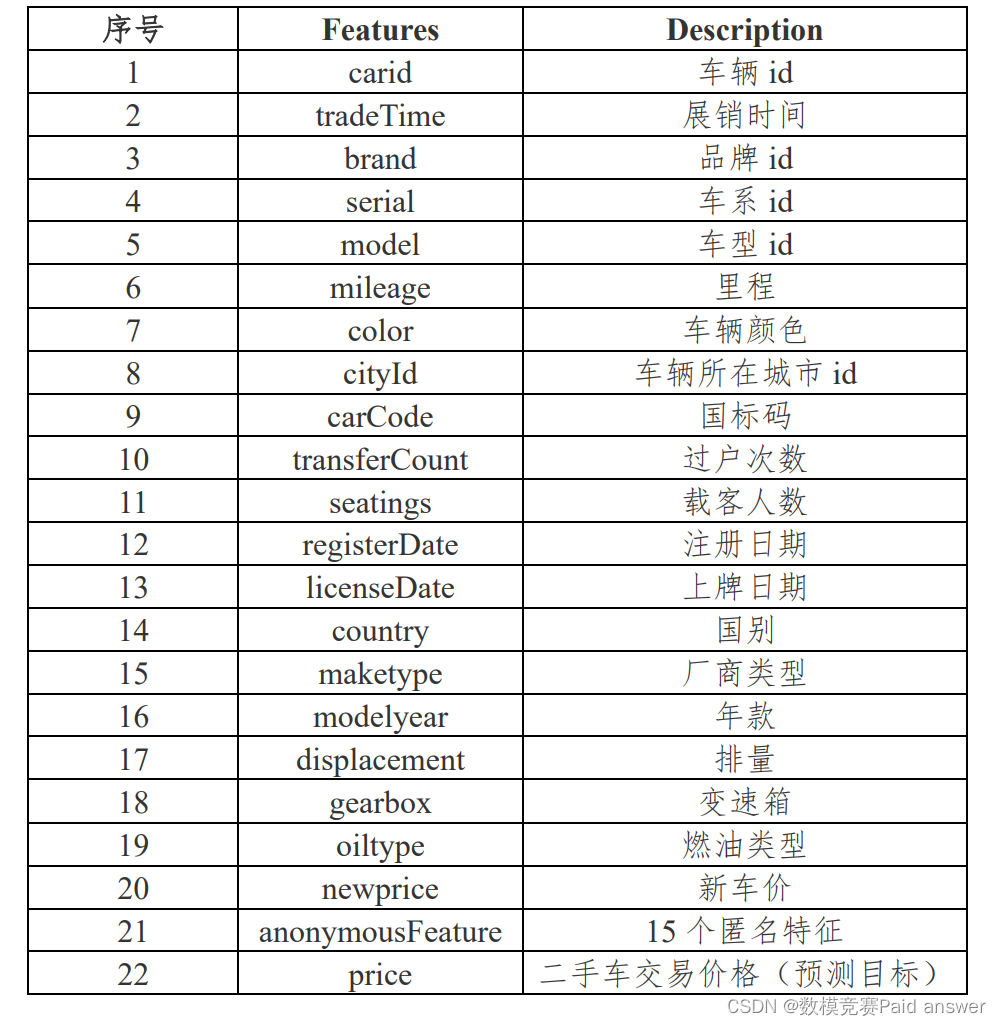
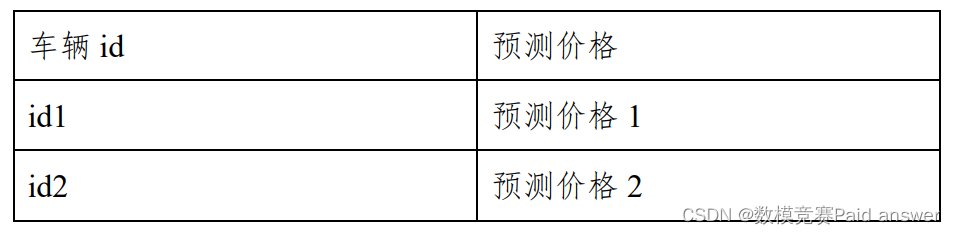
请采用附件 1 中的“估价训练数据”(带标签)训练模型和测试模型,自行设置测试集,使用训练完成后的模型对附件 2 中的“估价验证数据”(不带标签)进行预测,并将预测结果保存在附件 3“估价模型结果”文件中,注意不要修改格式,单独上传到竞赛平台。
其中附件 1“估价训练数据”和附件 2“估价验证数据”只相差最后1 列数据(二手车交易价格(预测目标)),附件 3“估价模型结果”文件字段如下:

问题 2:在门店模式中,车辆在被“买手”收车以后,会进入门店进行售卖,车辆能否成功交易,除了取决于销售的谈判技巧,更重要的是车辆本身是否受消费者青睐,价格是否公道。假设你们是门店的定价师,请你们结合附件 4“门店交易训练数据”对车辆的成交周期(从车辆上架到成交的时间长度,单位:天)进行分析,挖掘影响车辆成交周期的关键因素。假如需要加快门店在库车辆的销售速度,你们可以结合这些关键因素采取哪些行之有效的手段,并进一步说明这些手段的适用条件和预期效果。
附件 4“门店交易训练数据”包括 6 个字段,如下表所示,其中所有 carid 等相关信息包含在附件 1“估价训练数据”中。各字段间采用“\t”分隔符分割,不包含表头。
问题 3:依据给出的样本数据集,你们觉得还有哪些问题值得研究,并给出你们的思路?
将问题 1、2、3 的解决过程写成一篇论文,明确你们的思路、模型、方法和结果。
整体求解过程概述(摘要)
本文建立二手车估价模型,使得二手车电商进行快速准确地给二手车定价,制定营销补贴政策,提升二手车价值评估效率,分析影响车辆成交周期的关键因素,加快门店在库车辆的销售速度。
针对问题一,本文对“估价训练数据”进行分析,设置训练集和验证集构建模型,对“估价验证数据”进行预测。由于原始训练数据存在不规范性,首先进行数据清洗,包括对日期等非数值数据类型进行转换,处理缺失值和异常值,删除与预测目标无关列和重复列;在对原始数据进行清洗后,采用特征工程的方法对原始估价训练数据进行处理,包括对 price 和 newprice 进行对数化转换,对数据中的连续值特征归一化,对数据中的分类特征进行特征编码,对原始数据进行特征构造并进行嵌入式特征提取,以便增强模型的表达能力,获取更好的训练数据特征;在对数据清洗,进行特征处理后,得到一份经过处理的样本数据,再分别使用随机森林、LightGBM 和 XGBoost 模型,采取五折交叉验证法对样本数据进行拟合,得到各特征与二手车价格的关系,最后采取 stacking 模型融合的方法将上述三种模型的预测结果赋予不同权重,结合它们的优点建立最终预测二手车价格的模型。其中,stacking 融合模型根据模型评测标准在训练集的得分为 0.793,在验证集的得分为 0.636。
针对问题二,将门店交易数据根据 carid 索引“估价训练数据”表,将该表和“门店交易数据”合并为一个大表得到更多特征。此外,构造其他对成交周期天数产生影响的特征如车辆成交季节,车辆降价的幅度等。对原始数据中存在未成交的车辆,将它们的成交周期天数设为已成交车辆最大天数的两倍。采用基于惩罚项的特征选择方法,通过逻辑回归、LASSO 回归、SVM 模型得出影响成交周期的前五个重要性特征;采取基于树模型的特征选择方法,通过随机森林、LightGBM、XGBoost 模型得出影响成交周期的前五个重要性特征。通过投票机制选出 6 个模型中票数最多的前五个对成交周期影响的关键因素为 carid、车辆成交季节 transferCount、pushPrice 和车辆降价幅度。将选取的关键因素与成交周期做多元回归分析,得到对应因素调整对成交周期的影响的效果。根据关键因素加快车辆成交周期速度可分为销售策略类型的建议以及对二手车的收购标准的建议。销售策略有四个方面:将车辆从平均周期较大的城市转移到平均周期较短的城市,缩短的成交天数为城市间成交平均周期的时间差;在车辆出售淡季加大降价力度、提升降价的幅度,预期效果每降低 10%价格,缩短 3.625 天;降低车辆上架价格,每降低价格 1 个单位,缩短 1.5 天。二手车的收购标准方面为降低收购过户次数较多的车辆比例,每减少过户次数一次,缩短 10.952 天。
针对问题三,需要依据给出的样本数据,提出值得研究的问题并给出思路。本文研究季节因素对二手车交易价格的影响,挖掘影响二手车保值率的关键因素。对于季节因素对二手车交易价格的影响,本文根据“估价训练数据”和“门店交易数据”获取每一辆二手车的成交时间和成交价格,再按照月份将成交时间划分为春夏秋冬四个季节,分别对四个季节的成交价格统计特征进行分析,得出夏季和秋季的成交总额较多,而夏季的成交额的平均值较少,春季、秋季和冬季成交额的平均值比较接近;对于影响二手车保值率的关键因素,本文分别采用基于惩罚性的特征选择法和树模型的特征选择法,对重要特征进行提取,再使用投票机制得到最终影响汽车保值率的关键因素,分别为新车价、二手车交易价格、上架价格、品牌 id、车系 id 和厂商类型。
模型假设:
1. 假设影响二手车价格的因素仅包含题目所给定特征信息;
2. 假设样本数据中缺失过多的变量信息对二手车价格的预测产生的影响较小;
3. 假设预测集采集的 price 数据和训练集采集的 price 分布是一致的;
4. 假设在做出销售策略的阶段不会有黑天鹅事件或重大自然灾害等对门店二手车销售带来影响;
5. 假设异常值和缺失值处理后的数据有效可信,能够反映二手车本身属性与价格的关联性;
问题分析:
问题1分析
该问题需要基于给定的二手车交易样本数据构建模型预测二手车的零售价格,数据包括车辆基础信息、交易时间信息、价格信息等 36 列变量信息,其中 15 列为匿名变量。
由于原始数据存在不规范性,因此首先需要进行数据清洗,包括对日期等非数值数据类型进行转换,处理缺失值和异常值,删除与预测目标无关列和重复列。在对原始数据进行清洗后,采用特征工程的方法对原始估价训练数据进行处理,把原始数据转变为模型的训练数据,以便获取更好的训练数据特征,再使用合适的模型对数据进行训练,利用训练完成的模型对验证数据进行预测,并分析模型预测结果的准确度。
在特征工程的处理上,由于大部分模型需要的数据要求符合正态分布,因此需要对某些特征信息进行对数化转换;对于数据中的连续值特征,为了消除不同字段量纲对最终模型的影响,需要对数据进行归一化;对于数据中的分类特征,原始数据的值跨越较大且有多种形式,但是只有数字类型才能进行计算,所以需要对各种特殊的特征值进行相应的编码;为了对数据进行充分利用,增强模型的表达能力,需要对原始的数据进行特征构造,经过构造新特征后会得到较多的特征,因此需要对特征进行提取,防止模型的过拟合。
在对数据进行缺失值处理,异常值处理,特征工程步骤后,得到一份经过处理的样本数据。再分别使用 LightGBM,XGBoost 和随机森林模型,采取五折交叉验证法对样本数据进行拟合,得到各特征与二手车价格的关系,最后采取模型融合的方法将上述三种模型的预测结果赋予不同权重,结合它们的优点建立起最终预测二手车价格的模型。
对于模型的评测标准,需采取如下公式进行计算:

需要根据模型评测的计算标准,采用上述数据清洗、特征工程和模型训练的方法,使得评测标
准的计算得分尽可能高。
问题 2 分析
该问题需要结合“门店交易数据”对车辆的成交周期进行分析,并挖掘影响车辆成交周期的关键因素。因门店交易数据仅给出车辆 id、上架时间、上架价格、{价格调整时间:调整后价格}、下架时间和成交时间等 6 列数据,为挖掘影响二手车成交周期的关键因素,需要根据 carid 索引“估价训练数据”表,将该表和“门店交易数据”合并为一个大表,获取每一个二手车更多的特征信息。
对合并的表的原始数据进行预处理后,从原始数据计算出车辆的成交周期天数。同时原始数据中存在未成交的车辆,将它们的成交周期天数设为已成交车辆最大天数的两倍。此外,挖掘其他可能对成交周期天数产生影响的特征,如车辆成交的季节,车辆降价的次数,车辆降价的幅度等,构造新特征后再通过模型来得到对对车辆的成交周期的关键因素。
采用基于惩罚项的特征选择方法,通过逻辑回归、LASSO 回归、SVM 模型得出影响成交周期的前五个重要性特征;采取基于树模型的特征选择方法,通过随机森林、LightGBM、XGBoost 模型得出影响成交周期的前五个重要性特征。最后通过投票机制选出 6 个模型中票数最多的前五个对成交周期影响较大的因素。对五个重要因素分别和成交周期关系进行可视化,分析提供相应的建议。将选出的五个重要因素与成交周期做多元回归分析,以此来得到对应因素调整对成交周期的影响的效果。
问题 3 分析
在问题 1 选用合适的估价模型预测二手车交易价格,以及问题 2 挖掘出影响车辆成交周期的关键因素的基础上,依据样本的数据集,列举出需要研究的问题及思路如下。
1. 季节因素会对二手车的交易价格产生哪些影响?
与其它产品一样,二手车的交易市场同样存在淡季和旺季,一年内不同时间的二手车交易价格存在差异,这也导致季节因素会对二手车的交易价格产生影响。
将给出的“估价训练数据”和“门店交易训练数据”两个数据表合并为一个大表,可以获取每一
辆二手车的成交时间和成交价格,故按照月份将成交时间划分为春夏秋冬四个季节,即 1-3 月对应春季、4-6 月对应夏季、7-9 月对应秋季,10-12 月对应冬季,计算每个季节二手车交易价格的总和以及平均值,根据计算结果分析季节因素对二手车交易价格产生的影响,从而有利于二手车电商进行快速准确地给二手车定价,制定营销补贴政策。
2. 有哪些关键因素影响二手车的保值率?
二手车保值率一直是衡量二手车价值的关键指标,但也直接受新车价格稳定的影响。在新车交易中,保值率日渐成为消费者购车的决策因素之一,被誉为汽车价值生命的“第二周期”,故探究影响二手车保值率的关键因素,对各大汽车厂商以及二手车电商制定策略销售车辆有重要的作用。汽车保值率就是就是指某款车型在使用一段时期后,将其卖出的价格与先前购买价格的比值。基于给出的“估价训练数据”和“门店交易训练数据”,将两个数据表合并为一个大表,可以获取每一辆车的新车价、上架价格以及最终成交价格。计算出上架价格与新车价格的比值作为汽车的期望保值率,最终成交价格与新车价格的比值作为汽车的实际保值率,再取期望保值率与实际保值率的平均值作为汽车的保值率,可根据问题 2 寻找影响车辆成交周期的关键因素所使用的模型和方法,挖掘影响车辆保值率的关键因素。
模型的建立与求解整体论文缩略图


全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分Python程序如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression,Lasso,Ridge
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Ridge,RidgeCV, LassoCV, ElasticNetCV,LinearRegression
# 获取数据
df = pd.read_csv(open('C:/Users/Tracy/Desktop/123/2021/附件/附件2:估价验证数据.csv'))
id1 = df['carid']
price1 = df['price']
x = df.iloc[:, 1:-2]#-2
x = df.fillna(value=0)
# 读取模型
dirs ='C:/Users/Tracy/Desktop/123'
model = joblib.load(dirs + '/lasso模型.pkl')
#预估price存人list里, 并写入 附件2
price_list = []
to_list = model.predict(x)
for i in to_list:
price_list.append(abs(i))
df['price'] = price_list
df.to_csv('C:/Users/Tracy/Desktop/123/2021/附件/附件2:估价验证数据.csv')
#读取预估price并写入规定的附件3中
data = pd.read_csv('C:/Users/Tracy/Desktop/123/2021/附件/附件2:估价验证数据.csv',usecols=['carid','price'])
#print(data)
data.to_csv('C:/Users/Tracy/Desktop/123/2021/附件/附件3:估价模型结果.txt',index=False,sep='\t',header=False,encoding='utf_8_sig')
import joblib
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import ssl
ssl.create_default_https_context = ssl.create_default_context()
import matplotlib.pyplot as plt
import seaborn as sns
# 获取数据
df = pd.read_csv(open('C:/Users/Tracy/Desktop/123/2021/附件/附件1right.csv'))
#查看导入数据
print(df.head())
#数据各个列数据
print(df.info())
print(df.describe())
#用热度图表示不同特征之间的相关系数
cols = df.columns
data_corr = df.corr()
sns.heatmap(data_corr, annot = True)
data_corr = data_corr.abs()
plt.subplots(figsize = (38, 38))
p1 = sns.heatmap(data_corr, annot = True)
s1 = p1.get_figure()
s1.savefig('HeatMap1.jpg', dpi=300, bbox_inches = 'tight')
p2 = sns.heatmap(data_corr, mask = data_corr < 0.5, cbar = False)
s2 = p2.get_figure()
s2.savefig('HeatMap2.jpg', dpi=300, bbox_inches = 'tight')
#数据处理
size = data_corr.shape[0]
#去掉object型对象
col = cols.drop('tradeTime')
col = cols.drop('registerDate')
col = cols.drop('licenseDate')
col = cols.drop('anonymousFeature7')
col = cols.drop('anonymousFeature15')
corr_list=[]
threshold=0.5
for i in range(size):
for j in range(i+1,size):
if data_corr.iloc[i,j]>threshold and data_corr.iloc[i,j]<1:
corr_list.append([data_corr.iloc[i,j],i,j])
for v,i,j in corr_list:
print('{} and {} = {:.2f}'.format(col[i],col[j],v))
#对类别型特征,观察其取值范围
categorical_features= ['country','seatings','transterCount','color','maketype','modelyear','transterCount','serial']
for col in categorical_features:
print("\n%s属性的不同取值和出现的次数"%col)
print(df[col].value_counts())
df[col] = df[col].astype('object')
#对四个类别特征one hot处理
x_train_cat = df[categorical_features]
x_train_cat = pd.get_dummies(x_train_cat)
x_train_cat.head()
#对数值型变量预处理
from sklearn.preprocessing import MinMaxScaler
mn_x = MinMaxScaler()
df = df.fillna(value=(0))
numerical_features = ['transterCount','serial']
#print(df[numerical_features])#查看是否有数据缺失
#标准化为0-1之间的数
temp = mn_x.fit_transform(df[numerical_features])
x_train_num = pd.DataFrame(data=temp,columns=numerical_features)
print(x_train_num.head())
#特征数据
x_train=pd.concat([x_train_cat,x_train_num,df['mileage'],df['brand']],axis=1,ignore_index=False)
x_train.head()
print(x_train.head())
#拼接上carid,newprice,price 原有数据,将编码后的特征数据保存到新文件中‘特征_car.csv’
#carid 是记录的序号,newprice,price用于数据训练
TZ_train=pd.concat([df['carid'],x_train,df['newprice'],df['price']],axis=1,ignore_index=False)
#保存
TZ_train.to_csv('C:/Users/Tracy/Desktop/123/2021/附件/特征_car.csv',index=False)
# 获取数据
data = pd.read_csv("C:/Users/Tracy/Desktop/123/2021/附件/特征_car.csv")
# 数据基本处理
#确定特征值,目标值
x = data.iloc[:, 1:-2]#-2
y = data.iloc[:, -1]
x = data.fillna(value=0)
data = data.dropna()
# 数据集拆分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33)
# 特征工程标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 机器学习
estimator = LogisticRegression()
estimator.fit(x_train, y_train.astype('int'))
# 存储模型
joblib.dump(estimator, 'test.pkl')
# 模型评估
y_predict = estimator.predict(x_test)
print('逻辑回归预测值为:', y_predict)
print('逻辑回归预测值与真实值比较:', y_test == y_predict)
score = estimator.score(x_test, y_test.astype('int'))
print('逻辑回归准确率为:', score)
# AUC评估
y_test = np.where(y_test > 2.5, 1, 0)
print("逻辑回归AUC指标:", roc_auc_score(y_test, y_predict))
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可