本系列参考清风老师的数学建模课程
层次分析法模型
一、模型介绍
(一)模型引入
对于方案选择类问题,评价类问题采用层次分析法(The ayalytic hierarchy process / AHP)模型进行评分,之后评分高的就是最佳方案。
(二)模型详解
(1)建立层次结构
分析系统中各因素之间的关系,建立系统的递阶层次结构。
该层次结构分为:
1.目标层(Objective)
回答问题:评价目标是什么?
2.准则层(Criterion)
回答问题:评价指标是什么?
3.方案层(Plan)
回答问题:可选方案是什么?
将其绘制成层次清晰的示意图。
(2)构造判断矩阵
针对于准则层构造一个判断矩阵。
若有n个可选方案,则可以构造n个判断矩阵。
参考填表的准则:
| 标度 |
含义 |
| 1 |
两个因素相比具有同等重要性
|
| 3 |
一个因素比另一个因素稍微重要
|
| 5 |
一个因素比另一个因素明显重要
|
| 7 |
一个因素比另一个因素强烈重要
|
| 9 |
一个因素比另一个因素极端重要
|
| 2、4、6、8 |
介于奇数之间重要性 |
| 倒数 |
与之对应 |
填写判断矩阵的数据一定要有材料支撑。
(3)一致性检验
原理:检验我们构造的判断矩阵和一致矩阵是否有太大差别(定量角度)。
若正互反矩阵中的元素有性质:
a
i
j
×
a
j
k
=
a
i
k
a_{ij}×a_{jk}=a_{ik}
aij×ajk=aik则可以成为一致矩阵。(换句话说就是上下两行必须是成倍数的关系)
但在绝大多数情况下成为严格的一致矩阵不太可能,因此可以规定某个偏离范围,即使偏了一点也行,但不能偏太大,就有了一致性检验。(这块直接跑现成的程序出结果就行了,不介绍计算过程了)
一致性检验的通用步骤为:
1.计算一致性指标CI
C
I
=
λ
m
a
x
−
n
n
−
1
CI=\frac {\lambda_{max}-n}{n-1}
CI=n−1λmax−n
2.查找对应的平均随机一致性指标RI
3.计算一致性比例CR
C
R
=
C
I
R
I
CR=\frac {CI}{RI}
CR=RICI
4.判断CR是否<0.1,若是则认为一致性可以被接受,否则需要调整判断矩阵。
(4)求指标权重
求解指标权重时需要通过一致性检验,通过后就可以求出了,一共有三种求法。
1.算术平均法求权重
step1:将判断矩阵按照列归一化。
step2:将归一化的各列相加。
step3:将相加后得到的向量中每个元素除以n即可得到权重向量。
2.几何平均法求权重
step1:将判断矩阵元素按照行相乘得到一个新的列向量。
step2:将新的向量的每个分量开n次方。
step3:对该列向量进行归一化即可得到权重向量。
3.特征值法求权重
step1:求出判断矩阵的最大特征值以及其对应的特征向量。
step2:对求出的特征向量进行归一化即可得到权重。
(5)计算得分
每一个方案的任意评价指标最终得分=该评价指标在准则层的权重×方案在方案层的权重。
因此任意一个方案的最终得分=各项评价指标之和。
(三)模型举例
(1)举例
从苏杭、北戴河和桂林三个中选择一个作为旅游目的地。
(2)思路
本题属于方案选择类问题,因此使用层次分析法进行分析,考虑以下重要问题:
1.评价目标(目标层)?选择最佳旅游目的地。
2.评价指标(准则层)?(查阅资料后)景点景色、旅游花费、居住环境、饮食情况、交通便利程度。
3.可选方案(方案层)?苏杭、北戴河、桂林。
由以上思路可以得出下图:

(3)整理
设计数据表格,参考层次分析法的通用表格:
|
指标权重 |
方案1 |
方案2 |
… |
| 指标1 |
|
|
|
|
| 指标2 |
|
|
|
|
| 指标3 |
|
|
|
|
| … |
|
|
|
|
将以上思路内容填入上述通用表格中:
|
指标权重 |
苏杭 |
北戴河 |
桂林 |
| 景色 |
|
|
|
|
| 花费 |
|
|
|
|
| 居住 |
|
|
|
|
| 饮食 |
|
|
|
|
| 交通 |
|
|
|
|
解释:指标权重表示各个指标在准则层所占的权重大小值,而之后则代表该指标在方案层所占的权重大小值,因此若要最终评分,一定是准则层(Criterion)中指标权重×方案层(Plan)中指标权重得到最终得分。
(4)数据
之后就可以填写这张表格了。
step1:填写准则层判断矩阵:
|
景色 |
花费 |
居住 |
饮食 |
交通 |
| 景色 |
1 |
1
2
\frac 12
21 |
4 |
3 |
3 |
| 花费 |
2 |
1 |
7 |
5 |
5 |
| 居住 |
1
4
\frac 14
41 |
1
7
\frac 17
71 |
1 |
1
2
\frac 12
21 |
1
3
\frac 13
31 |
| 饮食 |
1
3
\frac 13
31 |
1
5
\frac 15
51 |
2 |
1 |
1 |
| 交通 |
1
3
\frac 13
31 |
1
5
\frac 15
51 |
3 |
1 |
1 |
解释:比如对于第三行第四列的单元格数据可以解释为花费比居住强烈重要。
step2:填写五个方案层判断矩阵:
| (景色) |
苏杭 |
北戴河 |
桂林 |
| 苏杭 |
1 |
2 |
5 |
| 北戴河 |
1
2
\frac 12
21 |
1 |
2 |
| 桂林 |
1
5
\frac 15
51 |
1
2
\frac 12
21 |
1 |
| (花费) |
苏杭 |
北戴河 |
桂林 |
| 苏杭 |
1 |
1
3
\frac 13
31 |
1
8
\frac 18
81 |
| 北戴河 |
3 |
1 |
1
3
\frac 13
31 |
| 桂林 |
8 |
3 |
1 |
| (居住) |
苏杭 |
北戴河 |
桂林 |
| 苏杭 |
1 |
1 |
3 |
| 北戴河 |
1 |
1 |
3 |
| 桂林 |
1
3
\frac 13
31 |
1
3
\frac 13
31 |
1 |
| (饮食) |
苏杭 |
北戴河 |
桂林 |
| 苏杭 |
1 |
3 |
4 |
| 北戴河 |
1
3
\frac 13
31 |
1 |
1 |
| 桂林 |
1
4
\frac 14
41 |
1 |
1 |
| (交通) |
苏杭 |
北戴河 |
桂林 |
| 苏杭 |
1 |
1 |
1
4
\frac 14
41 |
| 北戴河 |
1 |
1 |
1
4
\frac 14
41 |
| 桂林 |
4 |
4 |
1 |
step3:填好表格后开始进行一致性检验。
1.检验准则层判断矩阵:
一致性指标CI=
0.0180
一致性比例CR=
0.0161
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
2.检验方案层判断矩阵:
一致性指标CI=0.0028
一致性比例CR=0.0053
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
一致性指标CI=7.7081e-04
一致性比例CR=0.0015
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
一致性指标CI=-4.4409e-16
一致性比例CR=-8.5402e-16
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
一致性指标CI=0.0046
一致性比例CR=0.0088
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
一致性指标CI=0
一致性比例CR=0
因为CR<0.10,所以该判断矩阵A的一致性可以接受!
可以发现之前所有判断矩阵均通过了一致性检验。(若有没通过的判断矩阵需要对其中元素进行修改直到通过检验为止)
step4:计算各项指标对应的权重,有三种计算方法,最好三种方法取平均值,也可只采纳特征值法所算出的数据。(这块直接跑现成的程序出结果就行了,不介绍计算过程了)
填入数据:
|
指标权重 |
苏杭 |
北戴河 |
桂林 |
| 景色 |
0.2636 |
0.5954 |
0.2764 |
0.1283 |
| 花费 |
0.4758 |
0.0819 |
0.2363 |
0.6817 |
| 居住 |
0.0538 |
0.4286 |
0.4286 |
0.1429 |
| 饮食 |
0.0981 |
0.6337 |
0.1919 |
0.1744 |
| 交通 |
0.1087 |
0.1667 |
0.1667 |
0.6667 |
(5)结论
计算各个方案的最终得分。(这块Excel拉表出结果)
苏杭:0.299
北戴河:0.245
桂林:0.455
结论:桂林得分最高,因此选择去桂林。
二、模型实现
本模型采用多种软件实现。
(1)层次分析模型示意图
采用Office自带的SmartArt绘图。
(2)判断矩阵一致性检验代码
A=input('判断矩阵:')
clc;
[n,n]=size(A);
[X,Y]=eig(A);
lambda_max=max(Y(:));
CI=(lambda_max-n)/(n-1);
RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59];
CR=CI/RI(n);
disp('CI=');disp(CI);
disp('RI=');disp(CR);
if CR<0.1
disp('可以接受!');
else
disp('需要修改!');
end
(3)算术平均法求权重代码
A=input('判断矩阵:');
Sum=sum(A);
[n,n]=size(A);
Sum=repmat(Sum,n,1);
clc;
res=A./Sum;
disp('结果1:');
disp(sum(res,2)/n);
(4)几何平均法求权重代码
A=input('判断矩阵:');
Pro=prod(A,2);
Res=Pro.^(1/n);
disp('结果2:');
disp(Res/sum(Res));
(5)特征值法求权重代码
A=input('判断矩阵:');
[X,Y]=eig(A);
lambda_max=max(Y(:));
Y==lambda_max;
[x,y]=find(Y==lambda_max,1);
X(:,y);
disp('结果3:');
disp(X(:,y)./sum(X(:,y)));
(6)为方案评分
此处将数据导入到Excel表中,按F4锁定第一行作为乘数拉表计算。
三、模型应用
(一)题目描述
近年来,电动汽车在世界各国的生产和销售发展势头猛烈。这一方面与各国政府的大力扶持有关系,另一方面也与电动汽车本身的一些特定优势有关,比如充电而非耗油、运行耗能低等。不考虑牌照限制等问题,建立数学模型解决如下问题:
- 从用户的角度出发,比较电动汽车和燃油汽车的总体拥有成本。
- 一对年龄在 25 岁左右的年轻夫妇,参加工作不久,都在一家杭州软件公司工作,目前家庭年收入 20 万元,没有房产。考虑日常通勤、周末和假期出游等需求,他们准备
买一辆 15 万元左右的车。帮他们决定该买电动车还是燃油车。
(二)模型实战
第一问是有一个对应的总体拥有成本的公式,通过查阅各大网站或者书籍资料可得到公式中对应的参数值,从而计算出对应的总体拥有成本。(可能会用到Excel)没有模型。
第二问给了一个具体的场景,并且属于评价决策类问题,使用AHP层次分析法再合适不过了。于是按照AHP流程走。
参考一等奖论文思路
(1)建立层次结构(考虑五种准则,在这块可以变)
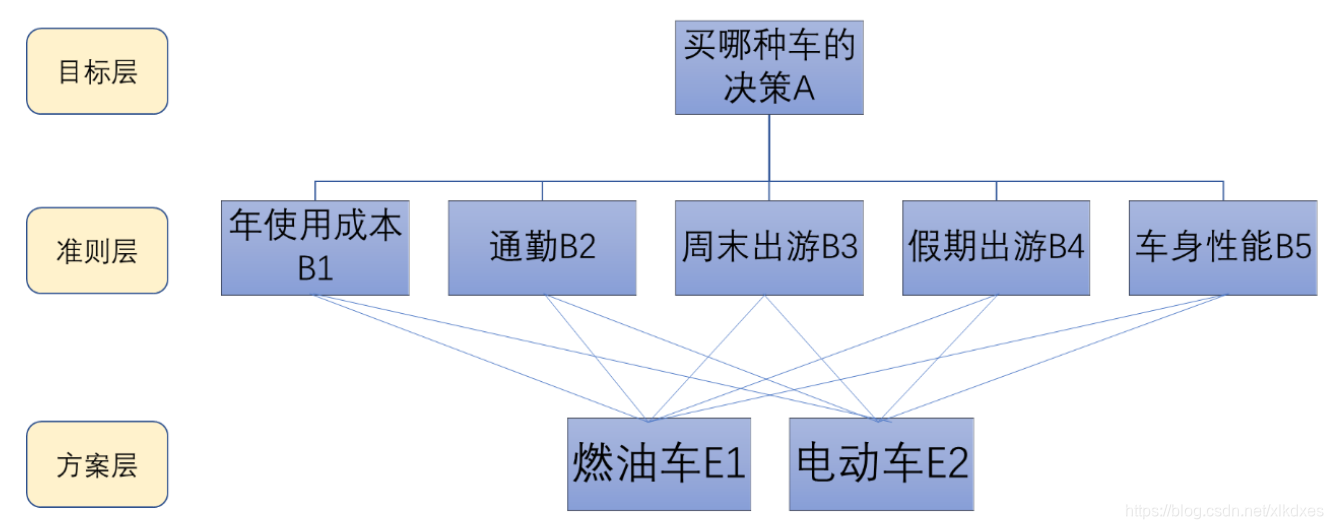
(2)构造判断矩阵(忽略计算与检验过程)
支撑材料1:
一对年龄在 25 岁左右的年轻夫妇,参加工作不久,都在一家杭州软件公司工作,目前家庭年收入 20 万元,没有房产。考虑日常通勤、周末和假期出游等需求,他们准备买一辆 15 万元左右的车。帮他们决定该买电动车还是燃油车。
总结信息:收入中等,工作频繁,闲暇时间不多。
1、使用成本时第一个要考虑的因素,不能负担不起。
2、通勤时使用车辆的第一理由。
3、很少有假期,因此驾车远游不重要。
目标层-准则层判断矩阵:
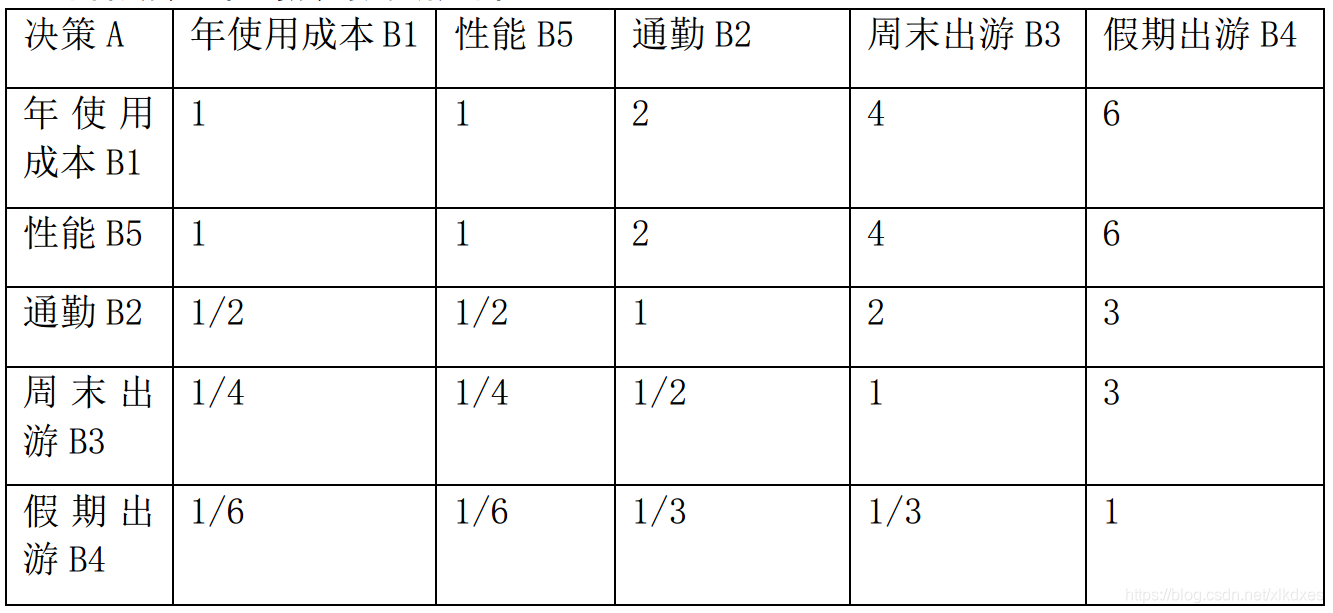
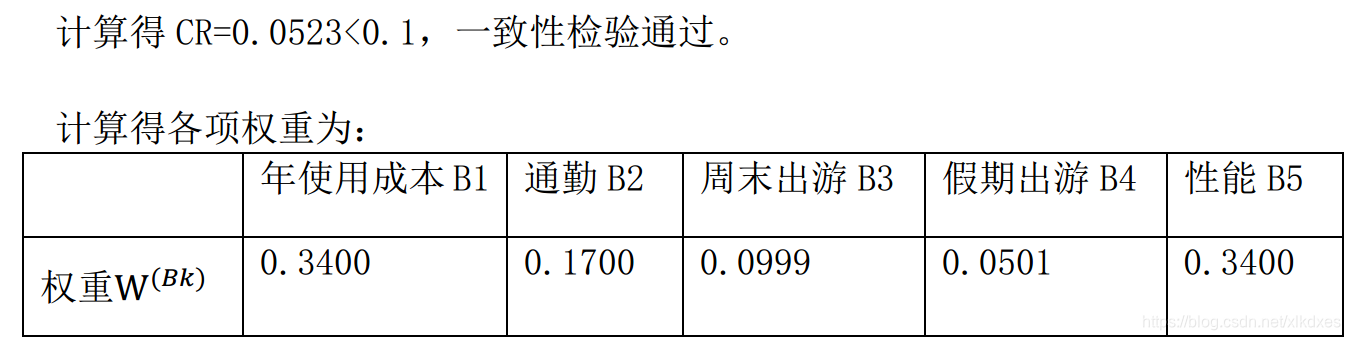
准则层-方案层判断矩阵:
支撑材料2:
通过查阅资料可得出年使用成本公式
A
A
C
=
P
T
+
C
I
+
M
+
F
i
+
M
V
I
+
V
V
AAC=PT+CI+M+F_i+MVI+VV
AAC=PT+CI+M+Fi+MVI+VV
根据具体情况查阅对应指标的值可得到:

如果有一个年使用成本占总生活支出比例就更加直观了,因此也可以查阅资料求出对应比例。
总结信息:年使用成本上,与燃油车相比,电动车具有明显的令人满意程度。
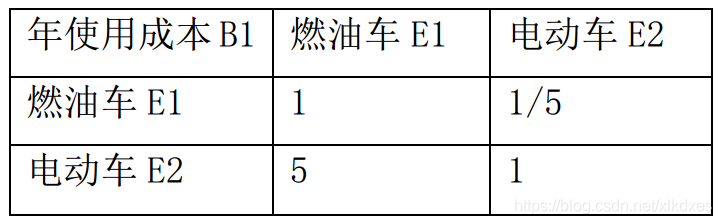

支撑材料3:
通过查阅资料可以得到通勤主要成本

同时根据常识可知在路上不开车等候更费油。
总结信息:通勤上,与燃油车相比,电动车具有强烈的令人满意程度。


支撑材料4:
与通勤情况类似。满足“短距离低速”特点。


支撑材料5:
电动车长距离开车要充电,然而查阅资料(摆上地图之类的)可知充电桩都在繁华地带,造成充电不方便。
总结信息:可知在燃料费上,与燃油车相比,电动车具有强烈的令人满意程度。
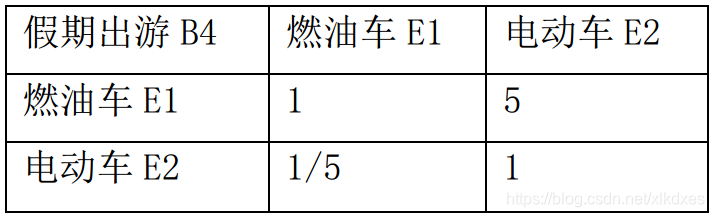

支撑材料6:
通过查阅资料将两种类型的车(一定注意控制变量,比如价格不能相差太远)的性能指标罗列出来逐一对比,可以自己设定一套定量评分规则,进而最终确定性能判断矩阵。
总结信息:在车身性能上,与电动车相比,燃油车具有明显的令人满意程度。
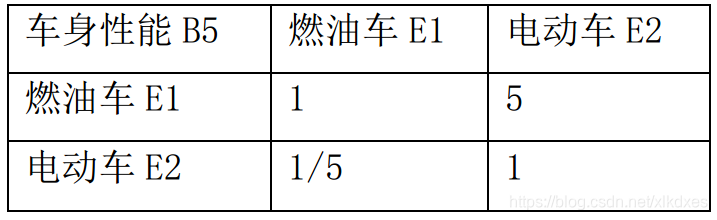

(3)评价方案
逐一填入对应权重:
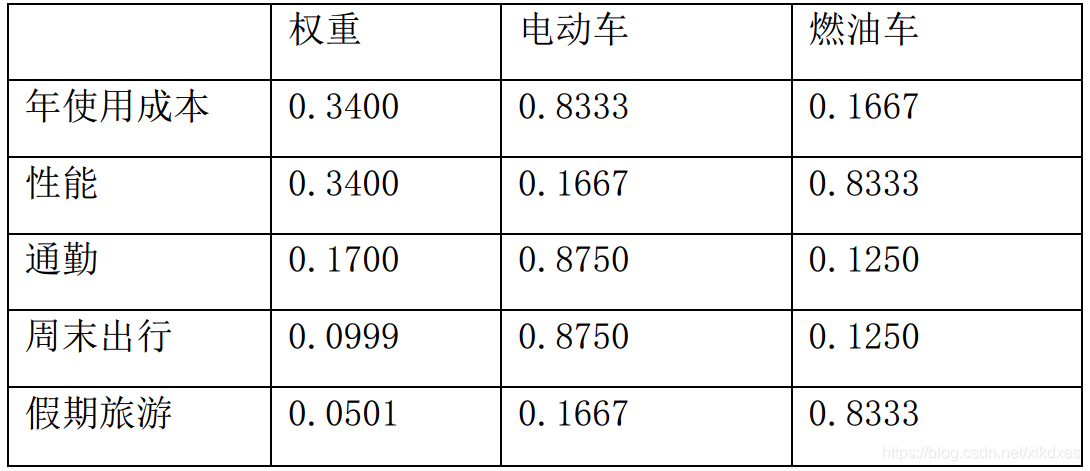
由此得出最终结论:
1、方案E1权重为0.4155
2、方案E2权重为0.5845
故购买电动车(E2)更合适。
(三)总结思考
1、分析由层次分析法得到各项评价指标权重,并从实际意义进行评价。比如说:通过层次分析法得出的权重值,XXX的权重最大,这也符合XXX的实际功能/实际意义…
2、模型评价:利用层次分析法决定XXX使得评价具有一定的客观性、准确性,避免了过于偏重某个需求而忽略其他的需求。但在给予各个准则相应的权重以及比较XXX的各个指标时不可避免地带有一定的主观性,使得评价结果的客观性及准确性降低。
3、模型贡献:通过层次分析法计算各项指标权重,总结出了XXX控制的重点因素,为XXX提供了明确的数据指导,为XXX指明了未来发展的重点方向与道路。