使用python对链家新房相关数据进行爬取,并进行持久化存储。
前言
保持练习
以下是本篇文章正文内容,下面案例可供参考
一、页面分析
老样子进行页面分析,ul下的li中存放着我们想要的信息,没什么好讲的。
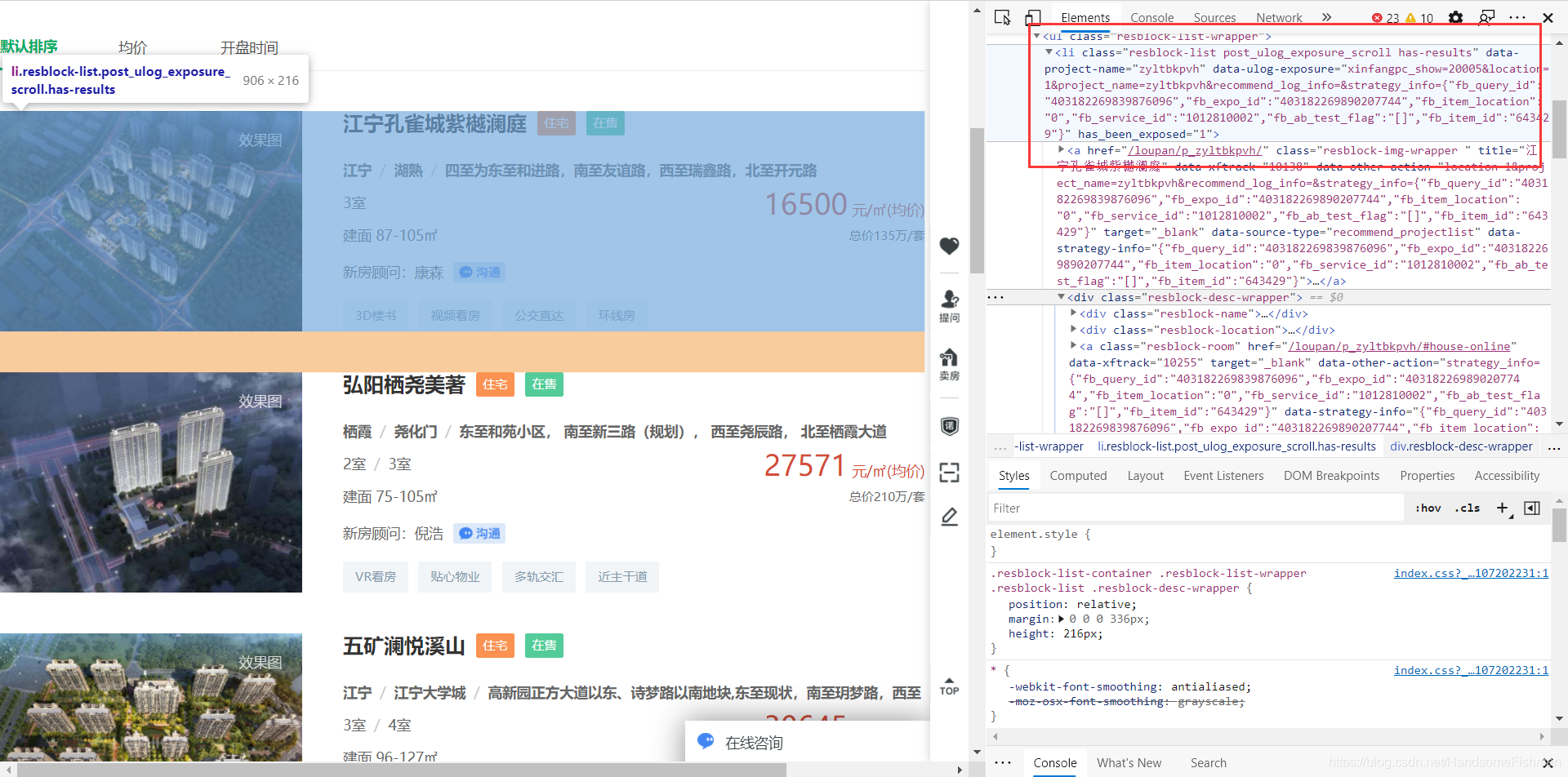
理清楚思路,对所有一共八十几个页面进行访问,随机伪装机型和ip代理,并找到链接的请求格式。

接下来只需要使用xpath定位到相关的元素信息即可,将解析的数据存入数据库中。
进入代码编写阶段。
二、代码编写
1.数据库表的建立
代码如下:
CREATE TABLE `xinfang` (
`id` int(255) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`resblock_type` varchar(10) DEFAULT NULL,
`sale_status` varchar(10) DEFAULT NULL,
`area` varchar(10) DEFAULT NULL,
`location` varchar(255) DEFAULT NULL,
`resblock_room` varchar(10) DEFAULT NULL,
`resblock_area` varchar(30) DEFAULT NULL,
`main_price` varchar(150) DEFAULT NULL,
`second` varchar(30) DEFAULT NULL,
`img_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=843 DEFAULT CHARSET=utf8;
2.代码编写
代码如下:
import requests
from lxml import etree
from fake_useragent import UserAgent
import random
import pymysql
# 代理池
proxy_pool = [{'HTTP': '112.84.53.165:9999'}, {'HTTP': '171.35.169.58:9999'}, {'HTTP': '49.86.180.142:9999'},
{'HTTP': '113.194.131.190:9999'}, {'HTTP': '110.243.22.233:9999'}, {'HTTP': '123.169.163.99:9999'},
{'HTTP': '123.163.117.140:9999'}, {'HTTP': '113.195.20.166:9999'}, {'HTTP': '114.235.23.237:9000'},
{'HTTP': '202.109.157.64:9000'}, {'HTTP': '171.35.175.31:9999'}, {'HTTP': '113.195.168.235:9999'},
{'HTTP': '125.108.75.135:9000'}, {'HTTP': '123.101.237.3:9999'}, {'HTTP': '139.155.41.15:8118'},
{'HTTP': '118.212.104.240:9999'}]
# 伪装头
headers = {
'Referer': 'https://nj.fang.lianjia.com/',
'User-Agent': UserAgent().random
}
if __name__ == '__main__':
print('打开数据库...')
# 打开数据库
conn = pymysql.Connect(host='localhost', port=3306, user='root',
password='', db='spider', charset='utf8')
# 链接模板 使用format填充
base_url = 'https://nj.fang.lianjia.com/loupan/pg{}/'
# 存放url的数组
data = []
print('初始化数据...')
for i in range(1, 86):
# 循环写入url
data.append(base_url.format(i))
print('开始爬取...')
# 遍历url 请求网址 并解析
for url in data:
# get请求访问 使用代理
response = requests.get(url=url, headers=headers, proxies=random.choice(proxy_pool))
# etree解析
res_data = etree.HTML(response.content.decode())
# xpath定位到所有的li
lis = res_data.xpath('//li[@class="resblock-list post_ulog_exposure_scroll has-results"]')
# 在循环的li下进行解析
for li in lis:
# 图片地址
img_url = li.xpath('./a/img/@data-original')[0].split('.592x432.jpg')[0]
# 小区名字
name = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/a[1]/text()')[0]
# 以下都是相关信息 就不做赘叙
resblock_type = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/span[1]/text()')[0]
sale_status = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-name"]/span[2]/text()')[0]
area = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[1]/text()')[0]
location = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[1]/text()')[0] + '/' + \
li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/span[2]/text()')[0] + '/' + \
li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-location"]/a[1]/text()')[0]
resblock_room = li.xpath('./div[@class="resblock-desc-wrapper"]/a[@class="resblock-room"]/span[1]/text()')
# 有些数据为空 要进行替换 否则数据库写入报错
if resblock_room:
resblock_room = resblock_room[0]
else:
resblock_room = '暂无信息'
resblock_area = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-area"]/span[1]/text()')
if resblock_area:
resblock_area = resblock_area[0]
else:
resblock_area = '暂无信息'
main_price = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div[@class="main-price"]/span[@class="number"]/text()')[0]
second = li.xpath('./div[@class="resblock-desc-wrapper"]/div[@class="resblock-price"]/div[@class="second"]/text()')
if second:
second = second[0]
else:
second = '暂无信息'
# sql语句
sql = 'insert into xinfang(name, resblock_type, sale_status, area, location, resblock_room, resblock_area, main_price, second, img_url) values ("{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}", "{}")'.format(
name, resblock_type, sale_status, area, location, resblock_room, resblock_area, main_price, second,
img_url)
cursor = conn.cursor()
# 事务 提交 回滚
try:
cursor.execute(sql)
conn.commit()
except Exception as e:
print(e)
conn.rollback()
print('爬取结束关闭数据库...')
# 关闭数据库链接 程序结束
conn.close()
结果
程序运行结果如下:
