本次分享一个数据挖掘实战项目: 个人信贷违约预测
项目背景
当今社会,个人信贷业务发展迅速,但同时也会暴露较高的信用风险。信息不对称在金融贷款领域突出,在过去时期借款一方对自身的财务状况、还款能力及还款意愿有着较为全面的掌握,而金融机构不能全面获知借款方的风险水平。这种信息劣势,使得金融机构在贷款过程中可能由于风险评估与实际情况的偏离,产生资金损失,直接影响金融机构的利润水平。
而现今时间金融机构可以结合多方数据,提前对客户风险水平进行评估,并做出贷款决策。
解决方法
运用分类算法预测用户违约情况
模型选择
单模型: 决策树、贝叶斯、SVM等
集成模型: 随机森林、梯度提升树等
评分卡模型: 逻辑回归
项目可输出: 评分卡
数据描述
数据总体概述
可用的训练数据包括:
- 用户的基本属性 user_info_train.txt
- 银行流水记录 bank_detail_train.txt
- 用户浏览行为 browse_history_train.txt
- 信用卡账单记录 bill_detail_train.txt
- 放款时间 loan_time_train.txt
- 顾客是否发生逾期行为的记录 overdue_train.txt
注意:并非每一位用户都有非常完整的记录,如有些用户并没有信用卡账单记录,有些用户却没有银行流水记录。
相应地,还有用于测试的数据包含:
- 用户的基本属性 user_info_test.txt
- 银行流水记录 bank_detail_test.txt
- 信用卡账单记录 bill_detail_test.txt
- 用户浏览行为 browse_history_test.txt
- 放款时间 loan_time_test.txt
- 待预测用户的 id 列表 usersID_test.txt
脱敏处理:
(a) 隐藏了用户的id信息;
(b) 将用户属性信息全部数字化;
© 将时间戳和所有金额的值都做了函数变换。
数据字段的含义
(1)用户的基本属性 user_info.txt,共 6 个字段,分别是 用户id、性别、职业、教育程度、婚姻状态、户口类型,其中字段性别为0表示性别未知。例如:57189,1,2,4,3,2
(2)银行流水记录 bank_detail.txt,共 5 个字段,分别是 用户id、时间戳、交易类型、交易金额、工资收入标记,其中第2个字段,时间戳为 0 表示时间未知;第3个字段,交易类型有两个值,1表示支出、0表示收入;第5个字段,工资收入标记为1时,表示工资收入。例如:6951,5894316387,0,13.756664,0
(3)用户浏览行为 browse_history.txt。共 4 个字段,分别为用户id、时间戳、浏览行为数据、浏览子行为编号。例如 34724,5926003545,172,1
(4)信用卡账单记录 bill_detail.txt,共 15 个字段,分别为
| 字段 |
注释 |
| 用户id |
整数 |
| 账单时间戳 |
整数0表示时间未知 |
| 银行id |
枚举类型 |
| 上期账单金额 |
浮点数 |
| 上期还款金额 |
浮点数 |
| 信用卡额度 |
浮点数 |
| 本期账单余额 |
浮点数 |
| 本期账单最低还款额 |
浮点数 |
| 消费笔数 |
整数 |
| 本期账单金额 |
浮点数 |
| 调整金额 |
浮点数 |
| 循环利息 |
浮点数 |
| 可用金额 |
浮点数 |
| 预借现金额度 |
浮点数 |
| 还款状态 |
枚举值 |
(5)放款时间信息 loan_time.txt。共 2 个字段,用户 id 和放款时间。
(6)顾客是否发生逾期行为的记录 overdue.txt。共 2 个字段,为用户 id 和样本标签,样本标签为1,表示逾期30天以上;样本标签为 0,表示逾期 10 天以内。
注意:逾期 10 天~ 30 天之内的用户,并不在此问题考虑的范围内。用于测试的用户,只提供 id 列表,文件名为 UsersID_test.csv。
各个数据表之间的关系
通过用户 id 找到表格之间的关联。

数据预处理
读取数据,用中文字段替换英文字段的表头,代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
columns_BankDetail = ['用户id', '时间戳', '交易类型', '交易金额', '工资收入标记']
df_bank_detail_train = pd.read_table("./bank_detail_train.txt", names = columns_BankDetail, sep = ',')
columns_UserInfo = ['用户id','性别','职业','教育程度','婚姻状态','户口类型']
columns_BillDetail = ['用户id','账单时间戳','银行id','上期账单金额','上期还款金额','信用卡额度','本期账单余额','本期账单最低还款额','消费笔数','本期账单金额','调整金额','循环利息','可用金额','预借现金额度','还款状态']
columns_BrowseHistory = ['用户id','时间戳','浏览行为数据','浏览子行为编号']
columns_LoanTime= ['用户id','放款时间']
columns_overdue = ['用户id','样本标签']
df_UserInfo_train = pd.read_table("./user_info_train.txt",names = columns_UserInfo, sep = ',')
df_overdue_train = pd.read_table("./overdue_train.txt", names = columns_overdue, sep = ',')
df_BillDetail_train = pd.read_table("./bill_detail_train.txt", names = columns_BillDetail, sep = ',')
df_BrowseHistory_train = pd.read_table("./browse_history_train.txt", names = columns_BrowseHistory, sep = ',')
df_LoanTime_train = pd.read_table("./loan_time_train.txt", names = columns_LoanTime, sep = ',')
依次对每个数据表格,查看前 5 行的数据、数据缺失情况,统计用户数量,以 df_bank_detail_train 为例,代码如下:
df_bank_detail_train.head()
df_bank_detail_train.info()
# 查看缺失情况
df_bank_detail_train.isnull().sum()
# 查看银行账单总记录数
len(df_bank_detail_train.用户id)
# 查看银行账单总用户数
len(set(df_bank_detail_train.用户id))
# 另一个写法
len(df_bank_detail_train.用户id.unique())
# 打印每个表格的总用户数
print( { 'user_info表的用户id数':len(df_UserInfo_train.用户id.unique()),
'bank_detail表的用户id数':len(df_bank_detail_train.用户id.unique()),
'overdue表的用户id数':len(df_overdue_train.用户id.unique()),
'bill_detail表的用户id数':len(df_BillDetail_train.用户id.unique()),
'browse_history表的用户id数':len(df_BrowseHistory_train.用户id.unique()),
'loan_time表的用户id数':len(df_LoanTime_train.用户id.unique())})
结果如下:
{'user_info表的用户id数': 55596,
'bank_detail表的用户id数': 9294,
'overdue表的用户id数': 55596,
'bill_detail表的用户id数': 53174,
'browse_history表的用户id数': 47330,
'loan_time表的用户id数': 55596}
发现用户信息表,是否逾期表,放款时间表这三张表的id数目都是 55,596,银行流水表为 9,294,浏览信息表为 47,330,信用卡账单表为 53,174。
从表中数据得知并非每一位用户都有非常完整的记录,如有些用户并没有信用卡账单记录,有些用户却没有银行流水记录。需要从这里刷选出在 6 个表中存在记录的用户。
我们要预测的测试集都是还没有放款的用户特征,所以训练数据也选取放款时间之前的特征,将存在时间戳的表与放款时间表进行交叉,筛选用户,具体实现如下。
# 合并表格:银行流水记录 bank_detail 与 放款时间 loan_time
df = pd.merge(left=df_bank_detail_train, right=df_LoanTime_train, how='left', on='用户id')
# 账单记录在放款时间之前
t = df[df.时间戳<=df.放款时间]
bank_detail = t[['用户id']]
# 去除重复的用户id
bank_detail = bank_detail.drop_duplicates(subset='用户id',keep='first')
# 信用卡账单记录 bill_detail_train.txt
df1 = pd.merge(left=df_BillDetail_train, right=df_LoanTime_train, how='left', on='用户id')
df1.head()
t1 = df1[df1.账单时间戳<=df1.放款时间]
bill_detail = t1[['用户id']]
bill_detail = bill_detail.drop_duplicates(subset='用户id',keep='first')
# 用户浏览行为 browse_history_train.txt
df2 = pd.merge(left=df_BrowseHistory_train, right=df_LoanTime_train, how='left', on='用户id')
df2.columns
t2 = df2[df2.时间戳<=df2.放款时间]
browse_history = t2[['用户id']]
browse_history = browse_history.drop_duplicates(subset='用户id',keep='first')
# 合并表格
user1 = pd.merge(left=bill_detail, right=browse_history, how='inner', on='用户id')
user = pd.merge(left=user1, right=bank_detail, how='inner', on='用户id')
user.T

筛选出这 6 张表共有的用户 id,总共 5735 个用户的记录是完整的。
数据清洗
银行流水记录
银行流水记录 bank_detail.txt,共有 5 个字段,分别是 用户 id、时间戳、交易类型、交易金额、工资收入标记,其中第 2 个字段,时间戳为 0 表示时间未知;第 3 个字段,交易类型有两个值,1 表示支出、0 表示收入;第 5 个字段,工资收入标记为 1 时,表示工资收入。
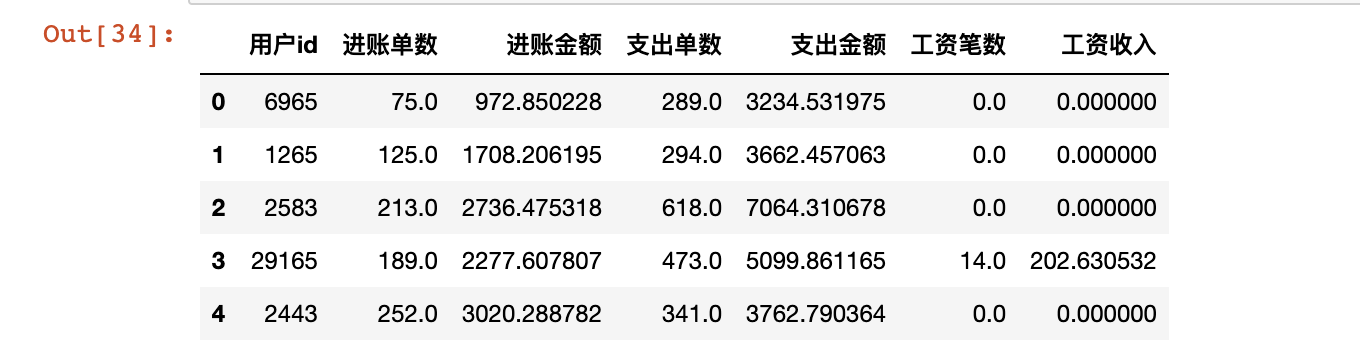
统计用户进账单数,对进账金额求和;统计用户支出单数,对支出金额求和;统计用户工资收入计数,对工资收入求和;形成新表。
bank_detail_select = pd.merge(left=df_bank_detail_train, right=user, how='inner', on='用户id')
b1=bank_detail_select[(bank_detail_select['交易类型']==0)].groupby(['用户id'], as_index=False)
b2=bank_detail_select[(bank_detail_select['交易类型']==1)].groupby(['用户id'], as_index=False)
b3=bank_detail_select[(bank_detail_select['工资收入标记']==1)].groupby(['用户id'], as_index=False)
c1=b1['交易金额'].agg({'进账单数':'count','进账金额':'sum'}) # 统计用户进账单数,对进账金额求和
c2=b2['交易金额'].agg({'支出单数':'count','支出金额':'sum'}) # 统计用户支出单数,对支出金额求和
c3=b3['交易金额'].agg({'工资笔数':'count','工资收入':'sum'}) # 统计用户工资收入计数,对工资收入求和
# 合并 user 表格,综合分析用户收入情况
d1=pd.merge(left=user, right=c1, how='left', on='用户id')
d1=d1.fillna(0)
d1.info()
d2=pd.merge(left=user, right=c2, how='left', on='用户id')
d2=d2.fillna(0)
d2.info()
d3=pd.merge(left=user, right=c3, how='left', on='用户id')
d3=d3.fillna(0)
d3.info()
# 表格合并
bank_train=d1.merge(d2)
bank_train=bank_train.merge(d3)
bank_train.head()
代码运行结果如下:
用户浏览行为
用户浏览行为 browse_history.txt。共 4 个字段,分别为用户 id、时间戳、浏览行为数据、浏览子行为编号。
先剔除 5735 以外的数据,再统计每个用户的浏览记录,求浏览记录的总和,代码实现如下:
browse_history_select=pd.merge(left=user, right=df_BrowseHistory_train, how='left', on='用户id')
g1=browse_history_select.groupby(['用户id'], as_index=False)
g1.head()
h1=g1['浏览行为数据'].agg({'浏览行为数据':'count'})
browse_train=pd.merge(left=user, right=h1, how='inner', on='用户id')
browse_train.head()
处理结果如下

信用卡账单记录
信用卡账单记录 bill_detail.txt,共 15 个字段,去掉了时间、银行 id、还款状态这几个变量,按用户 id 分组后对每个字段均值化处理。
bill_select = pd.merge(left=user, right=df_BillDetail_train, how='right', on='用户id')
bill_select.drop(['账单时间戳','银行id','还款状态'], axis=1, inplace=True)
e1 = bill_select.groupby(['用户id'], as_index=False)
f1 = e1['上期账单金额', '上期还款金额', '信用卡额度', '本期账单余额','本期账单最低还款额', '消费笔数', '本期账单金额', '调整金额', '循环利息', '可用金额', '预借现金额度'].agg(np.mean)
bill_train = pd.merge(left=user, right=f1, how='left', on='用户id')
bill_train.head()
逾期表、用户表
overdue_train=pd.merge(left=df_overdue_train,right=user, how='right', on='用户id')
user_train=pd.merge(left=user, right=df_UserInfo_train, how='left', on='用户id')
overdue_train.head()
user_train.head()

合并五张表
将筛选后的五个表进行合并,得出 25 个字段
df_train=user_train.merge(bank_train)
df_train=df_train.merge(bill_train)
df_train=df_train.merge(browse_train)
df_train=df_train.merge(overdue_train)
df_train.head()
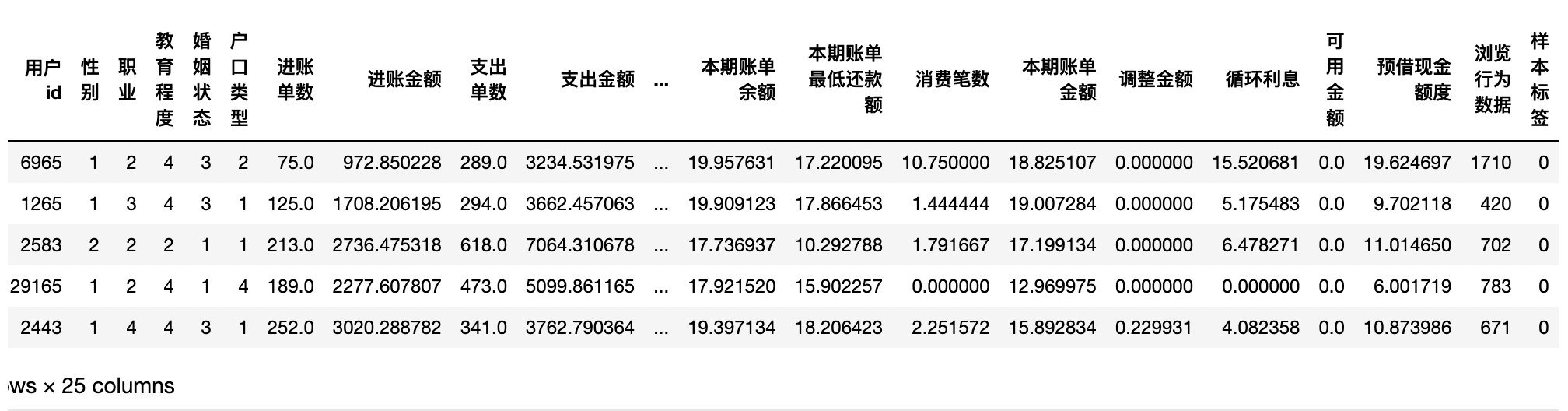
查看完整表格的基本情况,无缺失值,均是数值类型。

特征工程
基于业务理解的筛选
银行流水记录特征相关性分析
import matplotlib.pyplot as plt
internal_chars = ['进账单数', '进账金额', '支出单数', '支出金额', '工资笔数', '工资收入']
# 相关性结果数据表
corrmat = bank_train[internal_chars].corr()
plt.subplots(figsize=(10,10))
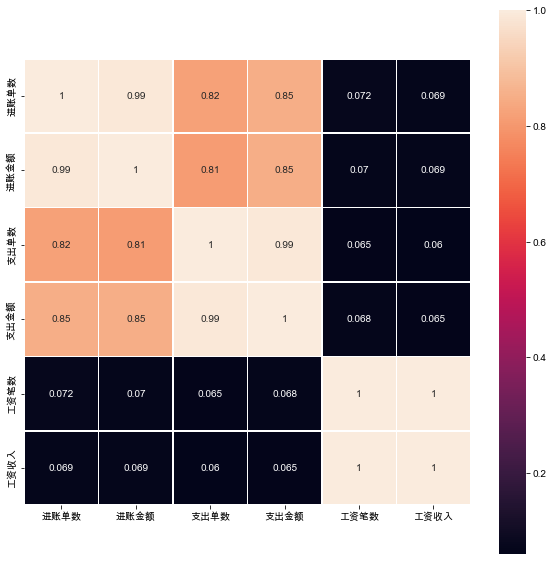
sns.heatmap(corrmat, square=True, linewidths=.5, annot=True); #热力图
-
'进账单数’与’进账金额’的相关系数很高,相关系数为 0.99
-
‘支出单数’, '支出金额’的相关性较高,相关系数分别为 0.82,0.85
-
‘进账金额’与’支出单数’, '支出金额’的相关性较高,相关系数分别为 0.81、0.85
-
'支出单数’与 '支出金额’的相关性很高,相关系数为 0.99
-
'工资笔数’与’工资收入’相关系数为1
-
可见收入、支出、工资三个指标的金额跟笔数是线性关系,那么后续将构建一个新的特征:笔均=金额/笔数,取工资笔均;而且收入、支出是强相关(0.82),所以只取一个即可,支出笔均。
-
后续将用’进账金额/进账单数’,‘支出金额/支出单数’,‘工资收入/工资笔数’得到’进账笔均’,‘支出笔均’,‘工资笔均’
总表相关性分析
internal_chars=['上期账单金额', '上期还款金额', '信用卡额度', '本期账单余额',
'本期账单最低还款额', '消费笔数', '本期账单金额', '调整金额',
'循环利息', '可用金额', '预借现金额度']
corrmat=df_train[internal_chars].corr() # 相关性结果数据表
plt.subplots(figsize=(10,8))
plt.xticks(rotation='0')
sns.heatmap(corrmat, square=False, linewidths=.5, annot=True); # 热力图

-
'本期账单金额’与’本期账单余额’相关系数为 0.85
-
'上期账单金额’与’上期还款金额’相关系数为 0.75
-
'本期账单金额’与’上期还款金额’相关系数为 0.64
-
'信用卡额度’与’上期账单金额’和’上期还款金额’相关系数分别为 0.54 和 0.52
-
'本期账单金额’与’上期账单金额’相关系数为 0.5
本期的账单余额与最低还款额具有高度共线性,决定只选用最低还款额。
重新构建数据表
上期还款差额 = 上期账单金额 - 上期还款金额,上期还款差额还会直接影响用户的信用额度以及本期的账单金额。
调整金额和循环利息是跟“上期的还款差额”有关的:
-
还款差额>0,需要计算循环利息,调整金额不计
-
还款差额<0,需要计算调整金额,循环利息不计
可以将还款差额进行“特征二值化”来代替这两个特征。
预借现金额度,是指持卡人使用信用卡通过 ATM 等自助终端提取现金的最高额度,取现额度包含于信用额度之内,一般是信用额度的50%左右,所以可以不用这个特征,选择信用额度即可。
df_train['平均支出']=df_train.apply(lambda x:x.支出金额/x.支出单数, axis=1) # apply() 当函数的参数存在于字典或元组中时
df_train['平均工资收入']=df_train.apply(lambda x:x.工资收入/x.工资笔数, axis=1)
df_train['上期还款差额']=df_train.apply(lambda x:x.上期账单金额-x.上期还款金额, axis=1)
df_select=df_train.loc[:,['用户id', '性别', '教育程度', '婚姻状态', '平均支出',
'平均工资收入', '上期还款差额', '信用卡额度', '本期账单余额', '本期账单最低还款额',
'消费笔数', '浏览行为数据', '样本标签']].fillna(0)
df_select.head()

基于机器学习的筛选
将上期还款差额二值化
# 将上期还款差额二值化
from sklearn.preprocessing import Binarizer
X=df_select['上期还款差额'].values.reshape(-1,1)
transformer = Binarizer(threshold=0).fit_transform(X)
df_select['上期还款差额标签']=transformer
样本不均衡
观察数据
x=df_select.drop(['用户id','上期还款差额','样本标签'],axis=1)
x.shape
y=df_select['样本标签']
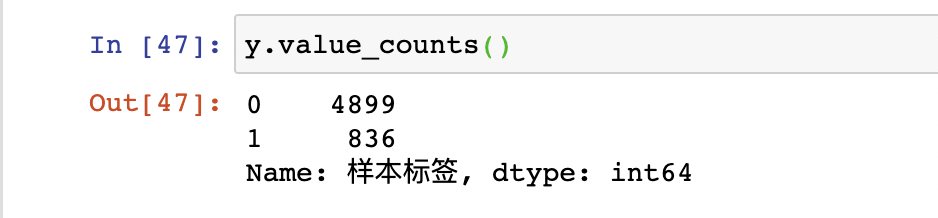
通过观察,正负样本比例为 836:4899,属于样本不均衡范畴,可采用上采样的SMOTE算法对其进行样本不均衡处理。
from imblearn.over_sampling import SMOTE
over_samples = SMOTE(random_state=111)
over_samples_x, over_samples_y = over_samples.fit_sample(x,y)
模型建立与调参
文章开始已经提到过了,可选模型较多,这里举例三种模型逻辑回归、决策树、随机森林模型,其余模型的选用,小伙伴们可以自己动手练习练习。
二分类模型——逻辑回归模型
超参数对模型效果的影响
用学习曲线对参数 C 进行调整,分别在两个模型中进行调参。
超参数C : 一般不会超过1, 越大惩罚力度越小,本次选取从 0.05 - 2范围。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score as cvs
l1CVS=[]
l2CVS=[]
# 用学习曲线对参数C进行调整,分别在两个模型中进行调参
# C : 一般不会超过1, 越大惩罚力度越小, 从 0.05 - 2
for i in np.linspace(0.05,1,30):
# 使用参数进行建模
lrl1 = LogisticRegression(penalty='l1', solver='liblinear', C=i, max_iter=1000, random_state=0)
lrl2 = LogisticRegression(penalty='l2', solver='liblinear', C=i, max_iter=1000, random_state=0)
once1 = cvs(lrl1, x, y, cv=5, scoring='f1').mean()
once2 = cvs(lrl2, x, y, cv=5, scoring='f1').mean()
l1CVS.append(once1)
l2CVS.append(once2)
plt.plot(np.linspace(0.05,1,30) ,l1CVS, "r")
plt.plot(np.linspace(0.05,1,30) ,l2CVS, 'g')
plt.show()
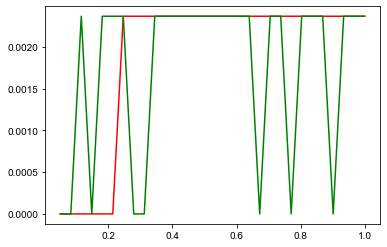
由图可知,当超参数C=0.4-0.6时,模型效果是最好的。
树模型——决策树
因为样本均衡化处理前后,对模型效果提升较为明显,因此在使用决策树模型建立之前,对样本进行均衡化处理。
因为深度参数max_depth是对决策树模型影响最大的参数之一,因此本案例正对决策树深度绘制学习曲线,探索决策树最佳参数。
# 导入train_test_split
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score, classification_report
from sklearn.tree import DecisionTreeClassifier as DTC
from imblearn.over_sampling import SMOTE
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=999)
over_samples = SMOTE(random_state=111)
over_samples_x_train, over_samples_y_train = over_samples.fit_sample(x_train,y_train)
over_samples_x_test, over_samples_y_test = over_samples.fit_sample(x_test,y_test)
dtc = DTC(splitter='random', random_state=222).fit(over_samples_x_train, over_samples_y_train)
cvs(dtc, over_samples_x_train, over_samples_y_train, cv=10, scoring='f1').mean()
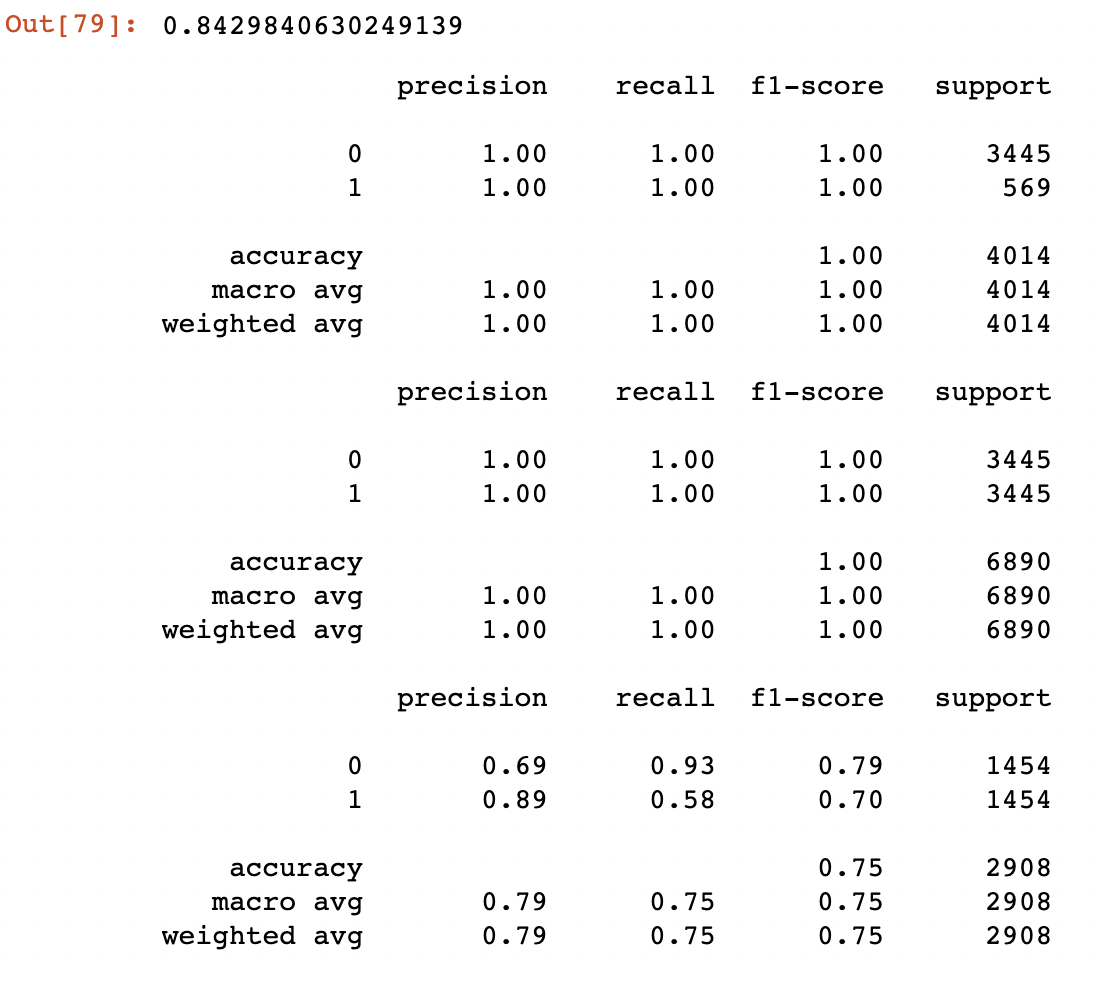
print(classification_report(y_test, dtc.predict(x_test)))
print(classification_report(over_samples_y_test, dtc.predict(over_samples_x_test)))
print(classification_report(over_samples_y_train, dtc.predict(over_samples_x_train)))
plt.plot(L_CVS, 'r')
plt.plot(L_train, 'g')
plt.plot(L_test, 'b')

由学习曲线可知,在max_depth=5时训练集和测试集模型效果均达到了最佳状态,当在max_depth大于5后,模型在训练集上的分数依然在上升,而测试集上的表现有所下降,这就是模型过拟合现象,因此最终我们选用max_depth=5。
特征重要性
dtc.feature_importances_
features_imp = pd.Series(dtc.feature_importances_,
index = x.columns).sort_values(ascending=False)
features_imp
结果如下:

树模型——随机森林
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import GridSearchCV
rfc = RFC(n_estimators=200,random_state=90).fit(over_samples_x_train,over_samples_y_train)
score_pre = cvs(rfc,over_samples_x_train,over_samples_y_train,cv=5, scoring='f1').mean()
score_pre
#print(classification_report(y_train,rfc.predict(x_train)))
print(classification_report(over_samples_y_train,rfc.predict(over_samples_x_train)))
print(classification_report(over_samples_y_test,rfc.predict(over_samples_x_test)))
结果如下:
模型调参
有⼀些参数是没有参照的,一开始很难确定⼀个范围,这种情况下采用先通过学习曲线确定参数大致范围,再通过网格搜索确定最佳参数。
比如确定n_estimators范围时,通过学习曲线观察n_estimators在什么取值开始变得平稳,是否⼀直推动模型整体准确率的上升等信息。
scorel = []
for i in range(0,200,10):
rfc = RFC(n_estimators=i+1, n_jobs=-1, random_state=90)
score = cvs(rfc,over_samples_x_train, over_samples_y_train,cv=5, scoring='f1').mean()
scorel.append(score)
print('最⾼score:',max(scorel))
print('最优n_estimators:',(scorel.index(max(scorel))*10)+1)
#plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
结果如下:
最⾼ score: 0.8433495577693615
最优 n_estimators: 191

对于其他参数也是按照同样的思路,如影响单棵决策树模型的参数max_depth来说,⼀般根据数据的⼤⼩来进⾏⼀个试探,比如乳腺癌数据很⼩,所以可以采⽤1~10,或者1~20这样的试探。
但对于像digit recognition那样的⼤型数据来说,我们应该尝试30~50层深度(或许还不⾜够),此时更应该画出学习曲线,来观察深度对模型的影响。
确定范围后,就可以通过网格搜索的方式确定最佳参数。其他参数就不一一举例了,大家可以动手尝试一下。
模型评价
本次案例模型评估使用classification_report
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数。
本文旨在梳理数据挖掘的一般过程,没有涉及到很复杂的算法,每个环节,如数据预处理、特征工程、模型建立于评价,均是常用的方法。
代码和数据:
链接: https://pan.baidu.com/s/1Yk76kn0iPq8zsH6_do8dJg 提取码: 0f5n
–来自百度网盘超级会员v5的分享