K
K
K
KNN分类问题是找出一个数据集中与一个给定查询数据点最近的
k
k
k
R
R
R
S
S
S
R
R
R
S
S
S
k
k
k
R
R
R
S
S
S
KNN的中心思想为建立一个分类方法,使得对于将
y
y
y
x
x
x
f
f
f
x
=
(
x
1
,
x
2
,
…
,
x
n
)
x=(x_1,x_2,\dots,x_n)
x = ( x 1 , x 2 , … , x n )
y
=
f
(
x
)
y=f(x)
y = f ( x )
f
f
f
p
=
(
p
1
,
p
2
,
…
,
p
n
)
p=(p_1,p_2,\dots,p_n)
p = ( p 1 , p 2 , … , p n )
p
p
p
k
k
k
k
k
k
k
k
k
给定如下两个
n
n
n
X
X
X
Y
Y
Y
X
=
(
X
1
,
X
2
,
…
,
X
n
)
X=(X_1,X_2,\dots,X_n)
X = ( X 1 , X 2 , … , X n )
Y
=
(
Y
1
,
Y
2
,
…
,
Y
n
)
Y=(Y_1,Y_2,\dots,Y_n)
Y = ( Y 1 , Y 2 , … , Y n )
d
i
s
t
a
n
c
e
(
X
,
Y
)
=
∑
i
=
1
n
(
X
i
−
Y
i
)
2
distance(X,Y)=\sqrt{\sum_{i=1}^n(X_i-Y_i)^2}
d i s t a n c e ( X , Y ) = ∑ i = 1 n ( X i − Y i ) 2
d
i
s
t
a
n
c
e
(
X
,
Y
)
=
∑
i
=
1
n
∣
X
i
−
Y
i
∣
distance(X,Y)=\sum_{i=1}^n \vert X_i-Y_i \vert
d i s t a n c e ( X , Y ) = ∑ i = 1 n ∣ X i − Y i ∣
(
∑
i
=
1
n
(
∣
X
i
−
Y
i
∣
)
q
)
1
/
q
(\sqrt { \sum_{i=1}^n(\vert X_i-Y_i \vert })^q)^{1/q}
( ∑ i = 1 n ( ∣ X i − Y i ∣
) q ) 1 / q
KNN算法可以总结为以下的简单步骤:
1、确定
k
k
k
k
k
k
2、计算新输入与所有训练数据之间的距离
3、对距离进行排序,并根据第
k
k
k
k
k
k
4、收集这些近邻所属的类别
5、根据多数投票确定新输入数据类别
在理解了KNN算法的步骤之后,理解MapReduce方案就简单了,在映射器运行之前将训练集中的数据读取出来,接下来通过计算每条数据与训练集数据中的距离,对距离进行排序,根据多数投票原则确定新输入数据类别,整个操作过程使用映射器即可实现。
S.txt文件如下
100;c1;1.0,1.0
101;c1;1.1,1.2
102;c1;1.2,1.0
103;c1;1.6,1.5
104;c1;1.3,1.7
105;c1;2.0,2.1
106;c1;2.0,2.2
107;c1;2.3,2.3
208;c2;9.0,9.0
209;c2;9.1,9.2
210;c2;9.2,9.0
211;c2;10.6,10.5
212;c2;10.3,10.7
213;c2;9.6,9.1
214;c2;9.4,10.4
215;c2;10.3,10.3
300;c3;10.0,1.0
301;c3;10.1,1.2
302;c3;10.2,1.0
303;c3;10.6,1.5
304;c3;10.3,1.7
305;c3;1.0,2.1
306;c3;10.0,2.2
307;c3;10.3,2.3
R.txt文件如下:
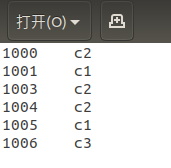
1000;3.0,3.0
1001;10.1,3.2
1003;2.7,2.7
1004;5.0,5.0
1005;13.1,2.2
1006;12.7,12.7
这个阶段的主要任务两个:
1、读取训练集中的数据
2、计算训练集数据与输入数据距离并根据投票原则实现分类
package com.deng.KNN;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
public class KNNMapper extends Mapper<LongWritable,Text,Text, Text> {
private static Text reduceKey;
private static Text reduceValue;
private static List<Point> training=null;
public static List<Point> readTrainingFromHFDS() throws IOException{
return KNNUtil.readFromHDFS("input/S.txt");
}
//从文件系统中读取数据并存入链表中
public void setup(Context context) throws IOException{
training=readTrainingFromHFDS();
}
public void map(LongWritable key,Text value,Context context){
String line=value.toString();
Point query=new Point(line); //查询数据
SortedMap<Double,Point> top=new TreeMap<Double, Point>(); //按照距离由小到大存取
for(int i=0;i<training.size();i++){
double distance=KNNUtil.calculateEuclidianDistance(query.getVector(),training.get(i).getVector());
top.put(distance,training.get(i));
if(top.size()>5){
top.remove(top.firstKey());
}
}
//根据投票原则进行分类,majorityVote为输入数据按照投票原则分类到的祖
String majorityVote=null;
int maxCount=0;
for(Point p:top.values()) {
p.addCount();
if (p.getGroupCount() > maxCount) {
maxCount = p.getGroupCount();
majorityVote = p.getGroup();
}
}
reduceKey=new Text(query.getGroup());
reduceValue=new Text(majorityVote);
try {
context.write(reduceKey,reduceValue);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
package com.deng.KNN;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
public class KNNUtil {
//计算两个输入数据欧氏距离
public static double calculateEuclidianDistance(Vector<Double> query,Vector<Double> training){
double sum=0.0;
for(int i=0;i<query.size();i++){
sum+=Math.pow(training.get(i)-query.get(i),2);
}
return sum;
}
//从文件系统中读取数据
public static List<Point> readFromHDFS(String p) throws IOException{
BufferedReader br=new BufferedReader(new FileReader(p));
String str;
int k=0;
List<Point> points=new ArrayList<>();
while((str=br.readLine())!=null){
Point point=new Point(str);
System.out.println(point);
points.add(point);
}
br.close();
return points;
}
}
package com.deng.KNN;
import java.util.Vector;
public class Point {
private String group;
private Integer groupCount;
private Vector<Double> vector=new Vector<>();
public Point(){}
public Point(String s){
// 输入数据中,训练集数据和输入数据输入格式不同,利用长度来进行区分并标记
String[] line=s.split(";");
if(line.length==3){
group=line[1];
String[] tokens=line[2].split(",");
for(int i=0;i<tokens.length;i++){
vector.add(Double.parseDouble(tokens[i]));
}
}else{
group=line[0];
String[] tokens=line[1].split(",");
for(int i=0;i<tokens.length;i++){
vector.add(Double.parseDouble(tokens[i]));
}
}
groupCount=0;
}
public String getGroup() {
return group;
}
public Vector<Double> getVector() {
return vector;
}
public Integer getGroupCount() {
return groupCount;
}
//封装加法操作
public void addCount(){
this.groupCount++;
}
@Override
public String toString() {
return "Point{" +
"group='" + group + '\'' +
", vector=" + vector +
'}';
}
}
package com.deng.KNN;
import com.deng.util.FileUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class KNNDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
FileUtil.deleteDirs("output");
String[] otherArgs=new String[]{"input/R.txt","output"};
Configuration conf=new Configuration();
Job job=new Job(conf,"KNN");
job.setJarByClass(KNNDriver.class);
job.setMapperClass(KNNMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit((job.waitForCompletion(true)?0:1));
}
}