国防科大2022年3月的综述
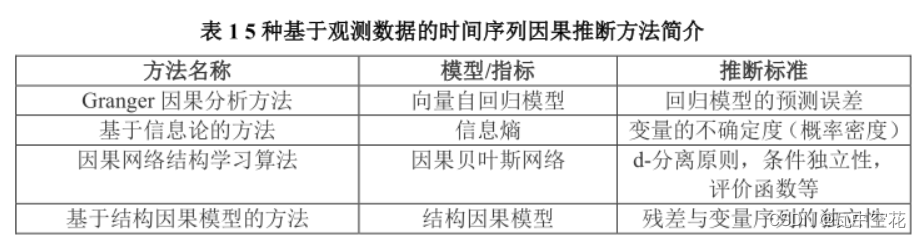

1.Granger
多元Granger: VAR+条件集,P(X|Y)=>条件VAR模型,比较y与y^来判定因果关系。
(加入条件集,消除其它变量影响)
条件Granger:用矩阵表示参数,简化计算。并提出基于 检验的因果判定方法。
检验的因果判定方法。
检验方法的创新,或者先变换空间在创新都能提高Granger适用性。
Lasso-GRanger:添加Lasso进行变量筛选,降低计算复杂度。
Copular-Granger:结合Lasso-Granger和潜在因果模型,用D-分离排除混杂因素,用Granger的“非超常分布”识别因果关系。(有点意思——那可以结合反事实计算吗?)
2.信息论
这些方法课衡量因果关系的强度,但对方向性未准确。
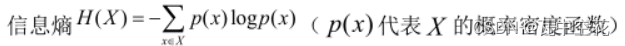
互信息:一个变量 X中包含的关于另一个变量Y的信息量;或者说X由于已知Y而减少的不确定性
它是一个非负量,如果MI显著不等于 0,则认为两个变量之间存在因果关系,反之亦然。
缺点:由于互信息具有对称性,因此在确定因果关系后还需要其他方法进一步定向。(可以结合Granger和互信息吗?感觉有希望)
传递熵: TE是一种度量因果关系的非对称指标。如果 X和Y的历史信息所决定的
X的不确定度,小于单独通过 X的历史信息所决定的 X的不确定度,那么Y就是 X的原
因,即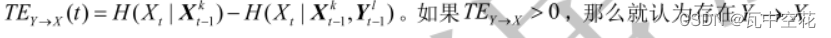
缺点:TE在应用于非平稳序列因果推断时精度较低,高维序列中的变量选择也制约了其计算效率。
(接下来的两篇文章可以看看,比较新,分别是2020和2022的文章。可以了解根源推理方法)
Rashidi等[28]提出了符号动态归一化传递熵(Symbolic Dynamic-based Normalized Direct TE,SDNDTE)并将其应用于复杂系统根源变量定位中。SDNDTE首先利用归一化操作排除变量自信息对因果推断造成的影响,然后将时间序列转化为基于频率计数的状态转移矩阵,通过符号发射矩阵的估计代替传统多维核概率密度函数拟合方法。SDNDTE能不仅能推断多元非平稳序列中的因果关系,还能有效降低计算复杂度、减少虚假因果的出现。此外,Zeng等[29]提出了归一化有效传递
熵(Normalized Effective TE,NETE),NETE在保持数据概率分布不变的情况,将传递熵减
去随机打乱数据后得到的随机传递熵,以消除时间序列的噪声和非平稳性造成的影响。
3.因果网络结构学习
Huang等[45]提出了一种用于非平稳和异构时间序列因果推断的CD-NOD(Constraint-based causal Discovery from Nonstationary/heterogeneous Data)方法。该方法利用变量代理和条件独立性检验重构因果网络框架,然后利用潜在因果模型中隐含的数据分布进行定向。相比此前的方法,CO-NOD是非参数的,对数据分布没有严格限制,且不依赖于时间窗口分割,还能在带有混杂因素的异质数据中识别因果关系。
传统的因果网络结构学习算法依赖于因果充分性假设[5],即假设系统中不存在未观测的
共同驱动因素,但真实系统中往往存在未观测变量(隐变量)。
2020年,Runge[52]又提出了PCMCI+算法,通过分离存在时延和同期的条件集,以及修改单个条件独立性测试的条件集,可以在高召回率的前提下有效减少虚假因果,降低时间复杂度。
4.基于结构因果模型的方法
第一代:LiNGAM
初始条件:线性,无未观测的共因,误差服从非高斯分布。
因果方向判断方法:因果机制的不对称性和因果机制的不对称性。
5.基于非线性状态空间模型的方法
2012年,Sugihara等[66]提出了收敛交叉映射(Convergent Cross Mapping, CCM)方法,该
方法基于Takens定理[67],通过状态空间重构推断因果关系.
什么是Takens定理?(需要补充)
如果变量 X可以通过变量Y的时延嵌入重构系统来预测,那么 X和Y之间就存在因果效应。
基于非线性状态空间模型的时间序列因果推断方法假设交互作用发生在一个潜在的动力系统中,然后基于Takens定理和非线性状态空间重构来推断因果关系。Takens定理可以用于重构时间序列中的动力学信息。它证明在满足某些条件时,从一个吸引子到重构空间的映射是一一对应的,只要找到合理的嵌入维数,就能实现相空间中轨道的重构,并保持其原来的微分结构不变。
方法一:NLIM 非线性相互依赖度量

方法二:非线性相互依赖

Krakovská和Jakubík[74]利用重构状态空间预测原理,提出了基于交叉预测(Cross
Prediction,CP)和混合预测(Predictability Improvement,PI)的因果关系推断方法。其中
CP方法通过自预测和交叉预测的平均绝对误差判定因果关系,PI则通过两种混合优化预测
方法判定因果关系。CP和PI能适用于多变量系统,还能用于因果推断结果的敏感性分析。
(这两篇文章可以看看,应该与预测有关)
Liu等[81]利用条件熵检测反馈驱动的交易和反映市场回报流的“自因果性”,并使用传递熵识别新闻情绪和市场回报的信息流相关的交易活动。
(这篇文章可以看看,与反馈机制有关)
Li和Convertino[91]提出一种互信息和传递熵的最优信息流生态系统模型,通过从时间序列中提取复杂生态系统的预测因果网络,提供广泛的生态信息。Oh等[92]提出一种相对符号传递熵来研究南大洋的南极绕极波大规模气候现象,并解释了厄尔尼诺-南方涛动的特征。
(一个是预测因果网络,什么样的网络?)
(相对符号传递熵,如何进行符号推理?)
Zeng等[96]利用基于归一化修正传递熵和改进的因果网络结构学习算法,将遥测参数因果关系与注意力机制的LSTM相结合,实现了低误报率的航天器遥测数据异常检测。
(2022年的文章,可能用处不大)
Tian等[99]提出一种基于CCM的重大工业事故主因告警和根因追踪方法,利用CCM识别变量之间的因果方向和间接因果关系,作为后续告警根因追踪的依据。
(用CCM进行识别,到底根因到哪个阶段?)
总结:
1.这篇文章总结的还不错,比之前大连理工任伟杰等人的综述详细,深入些。
2.对于我想要的内容,还是没有太大的帮助。
3.选取的文章都比较新,想了解相关方向,值得去看看。
4.现有的推理还是指图上的推理,未总结与应用结合的推理方式。