大数据项目实战
第五章 数据分析
学习目标
了解数据分析
·了解数据仓库
掌握 Hive 的操作
掌握 HQL语句的使用
数据分析师大数据价值链中最重要的一环,目的是提取数据中隐藏的数据,以便于提供有意义的建议以致做出正确的决策。通过数据分析,人们可以从天花缭乱的数据中萃取和提炼有价值的信息,从而找出研究对象的内在规律。本篇介绍如何通过数据分析技术对上篇预处理后的数据进行相关分析。
一、设计 Hive 数据仓库
1、事实表 ods_jobdata_origin
事实表 ods_jobdata_origin 主要用于存储 MapReeduce 计算框架清洗后的数据。
表结构如下:
city(城市)String
salary(薪资)array < String >
company(福利标签)array < String >
kill(技能标签) array < String >
事实表 ods_jobdata_oragin 的表明前缀为 ods(Operational Data Store),指的是操作型数据存储,作用是使用者提供当前数据的状态,且具有及时性、操作性、集成性的全体数据信息。
2、维度表 t_salary_detail
维度表 t_salary_detail 主要用于存储薪资分布分析的数据。
表结构如下:
salary(薪资分布区间) String
count(区间内出现薪资的频次)
3、维度表 t_company_detail
维度表 t_company_detail 主要用于储存福利标签分析的数据。
表结构如下:
company(每个福利标签) String
count(每个福利标签的频次) Int
4、维度表 t_city_detail
维度表 t_city_detail 主要用于存储城市分布分析的数据。
表结构如下:
city(城市) String
count(城市频次) Int
5、维度表 t_kill_detail
维度表 t_kill_detail 主要用于存储技能标签分析的数据。
表结构如下:
kill(每个技能标签) String
count(每个技能标签的频次) Int
二、实现数据仓库
将采集到的职位数据进行预处理后,加载到 Hive 数据仓库中,后续进行相关分析。
1.创建数据仓库
启动 Hadoop 集群后,在主节点 Hadoop001 上启动 Hive 服务端,创建名为 “jobdata” 的数据仓库。
hive> create database jobdata;
创建成功后,通过 use 命令使用 jobdata 数据仓库,进入库中创建相应的表结构。
2.创建事实表
创建存储原始职位数据的事实表 ods_jobdata_origin
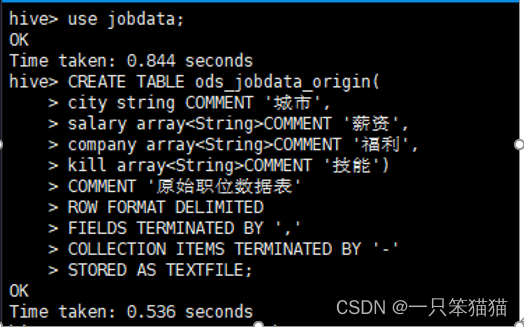
hive> CREATE TABLE ods_jobdata_origin(
city string COMMENT '城市',
salary array<String>COMMENT '薪资',
company array<String>COMMENT '福利',
kill array<String>COMMENT '技能')
COMMENT '原始职位数据表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
STORED AS TEXTFILE;
(1)CREATE TABLE:创建一个指定名字的表。
(2) COMMENT :后面跟着的字符串是给表字段或者表内容添加注释说明的,虽然它对应表之间的计算没有影响,但是为了后期的维护,所以实际开发都是必须要加 COMMENT 。
(3)ROW FORMAT DELIMITED:用来设置创建的表在加载看数据的时候支持的列分隔符。不同列之间默认用一个 ‘\001’ 分隔,集合(例如 array , map) 的元素之间默认以 ‘\002’ 隔开,map 中 key 和 value 默认用 ‘\003’ 分隔。
(4)FIELDS TERMINATED BY:指定列分隔符,本数据表指定逗号作为列分隔符。
(5)COLLECTION ITEMS TERMINATED BY:指定 array 集合中各元素的分隔符,本数据表以 “-” 作为分隔符。
(6)STORED AS TEXTFILE:表示文件数据是纯文本。
3.导入预处理数据到事实表
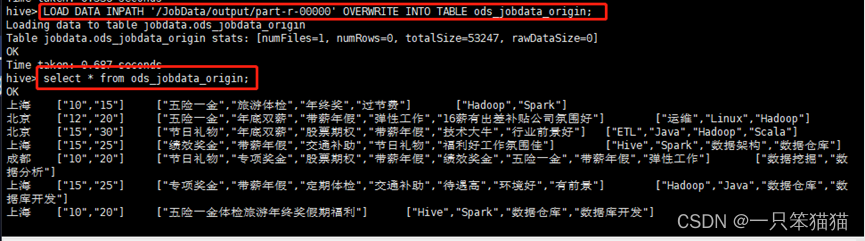
由于预处理程序的运行结果将预处理完成的数据存储到 HDFS 上的 /JobData/output/part-r-00000 文件中,因此通过 Hive 的加载命令将 HDFS 上的数据加载到 ODS 层的事实表 ods_jobdata_origin 中。
hive> LOAD DATA INPATH '/JobData/output/part-r-00000' OVERWRITE INTO TABLE ods_jobdata_origin;
通过 select 语句查看表数据内容,验证数据是否导入成功。
select * from ods_jobdata_origin;
执行上述命令后的效果如下。
4.明细表的创建与加载数据
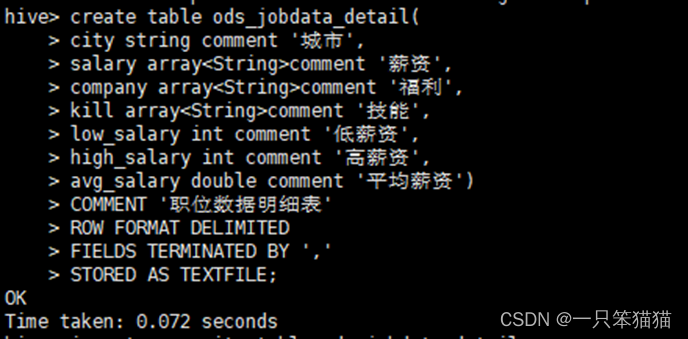
创建明细表 ods_jobdata_detail,用于存储细化薪资字段的数据,即对薪资列进行分,列处理,将薪资拆分形成高薪资、低薪资两列,并新增一列为平均薪资,平均薪资是通过最低薪资和最高薪资相加的平均值得出。
create table ods_jobdata_detail(
city string comment '城市',
salary array<String>comment '薪资',
company array<String>comment '福利',
kill array<String>comment '技能',
low_salary int comment '低薪资',
high_salary int comment '高薪资',
avg_salary double comment '平均薪资')
COMMENT '职位数据明细表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
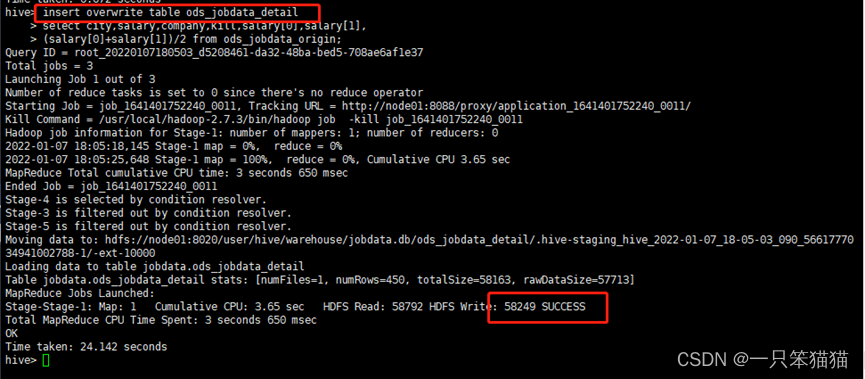
创建完明细表后,就可以向 ods_jobdata_detail 表中加载数据。
hive> insert overwrite table ods_jobdata_detail
select city,salary,company,kill,salary[0],salary[1],
(salary[0]+salary[1])/2 from ods_jobdata_origin;
5.创建中间表
(1)对薪资字段内容进行扁平化处理,将处理结果存储到临时中间表 t_ods_tmp_salary
hive> create table t_ods_tmp_salary as select explode(ojo.salary) from ods_jobdata_origin ojo;
上述命令使用 explode() 函数将 salary 字段的 array 类型数据进行遍历,提取数组中的每一条数据。
(2)对 t_ods_tmp_salary 表的每一条数据进行泛化处理,将处理结果存储到中间表 t_ods_tmp_salary_dist
hive> create table t_ods_tmp_salary_dist as
select case when col>=0 and col<=5 then "0-5"
when col>=6 and col<=10 then "6-10"
when col>=11 and col<=15 then "11-15"
when col>=16 and col<=20 then "16-20"
when col>=21 and col<=25 then "21-25"
when col>=26 and col<=30 then "26-30"
when col>=31 and col<=35 then "31-35"
when col>=36 and col<=40 then "36-40"
when col>=41 and col<=45 then "41-45"
when col>=46 and col<=50 then "46-50"
when col>=51 and col<=55 then "51-55"
when col>=56 and col<=60 then "56-60"
when col>=61 and col<=65 then "61-65"
when col>=66 and col<=70 then "66-70"
when col>=71 and col<=75 then "71-75"
when col>=76 and col<=80 then "76-80"
when col>=81 and col<=85 then "81-85"
when col>=86 and col<=90 then "86-90"
when col>=91 and col<=95 then "91-95"
when col>=96 and col<=100 then "96-100"
when col >= 101 then ">101" end from t_ods_tmp_salary;
上述命令使用条件判断函数 case,对 t_ods_tmp_salary 表的每一条数据进行泛化处理,指定每一条数据所在区间。
(3)对福利标签字段内容进行扁平化处理,将处理结果存储到临时中间表 t_ods_tmp_company
hive> create table t_ods_tmp_company as select explode (ojo.company) from ods_jobdata_origin ojo;
上述命令使用 explode() 函数将 company 字段的 array 类型数据进行遍历,提取出数组中的每一条数据。
(4)对技能标签字段内容进行扁平化处理,将处理结果存储到临时的中间表 t_ods_tmp_kill
hive> create table t_ods_tmp_kill as select explode (ojo.kill) from ods_jobdata_origin ojo;
上述命令使用 explode() 函数将 kill 字段的 array 类型数据进行遍历,提取出数组中的每一条数据。
6.创建维度表
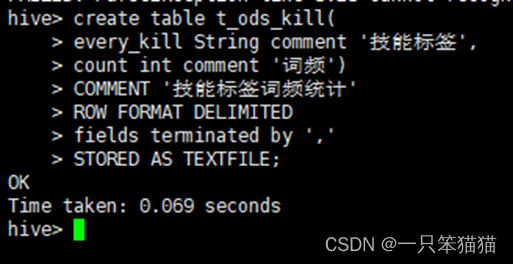
(1)创建维度表 t_ods_kill,用于存储技能标签的统计结果。
hive> create table t_ods_kill(
every_kill String comment '技能标签',
count int comment '词频')
COMMENT '技能标签词频统计'
ROW FORMAT DELIMITED
fields terminated by ','
STORED AS TEXTFILE;
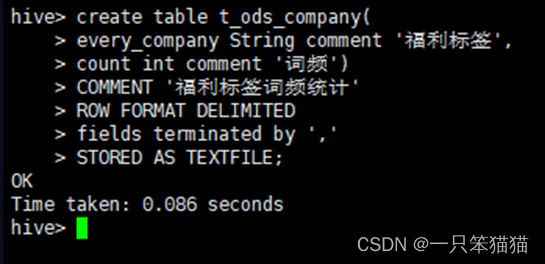
(2)创建维度表 t_ods_company,用于存储福利标签的统计结果。
hive> create table t_ods_company(
every_company String comment '福利标签',
count int comment '词频')
COMMENT '福利标签词频统计'
ROW FORMAT DELIMITED
fields terminated by ','
STORED AS TEXTFILE;
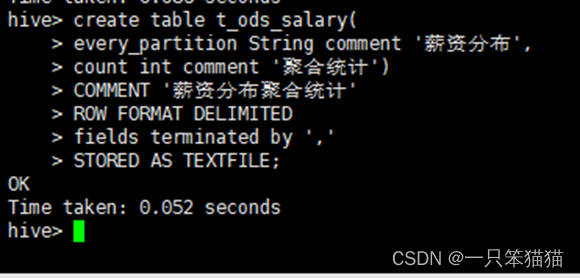
(3)创建维度表 t_ods_salary,用于存储薪资分布的统计结果。
hive> create table t_ods_salary(
every_partition String comment '薪资分布',
count int comment '聚合统计')
COMMENT '薪资分布聚合统计'
ROW FORMAT DELIMITED
fields terminated by ','
STORED AS TEXTFILE;
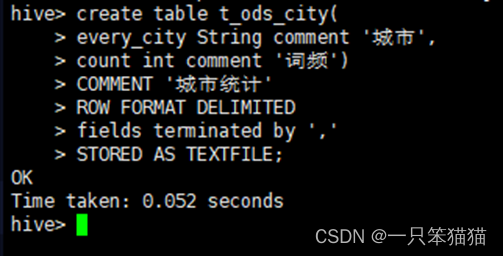
(4)创建维度表 t_ods_city,用于存储城市的统计结果。
hive> create table t_ods_city(
every_city String comment '城市',
count int comment '词频')
COMMENT '城市统计'
ROW FORMAT DELIMITED
fields terminated by ','
STORED AS TEXTFILE;
三、分析数据
在实际开发中,统计指标会随社会需求而不断的发生变化。本篇的统计指标为招聘网站的职位区域分析、职位薪资统计、公司福利分析以及职位的技能要求统计。
1、职位区域分析
通过对事实表 ods_jobdata_origin 提取城市字段数据进行统计分析,并将分析结果存储在维度表 t_ods_city 中
hive> insert overwrite table t_ods_city
select city,count(1) from ods_jobdata_origin group by city;
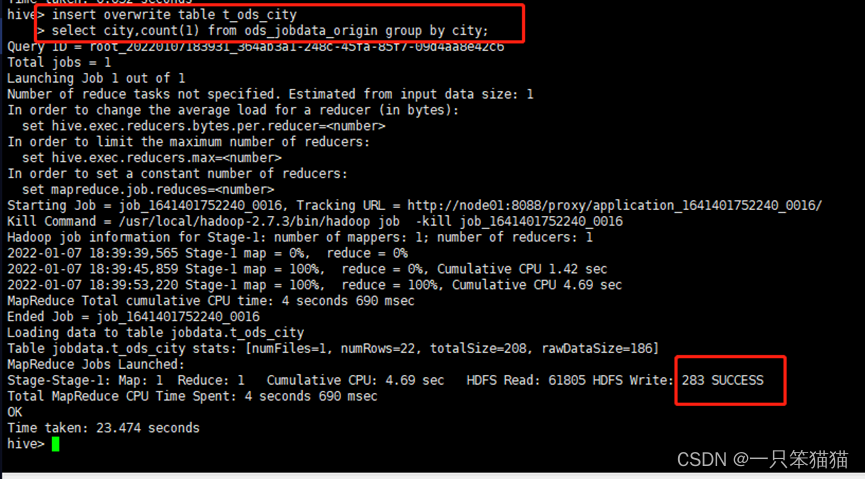
查看维度表 t_ods_city 中的分析结果,使用 sort by 参数对表中的 count 列进行逆序排序
hive> select * from t_ods_city sort by count desc;
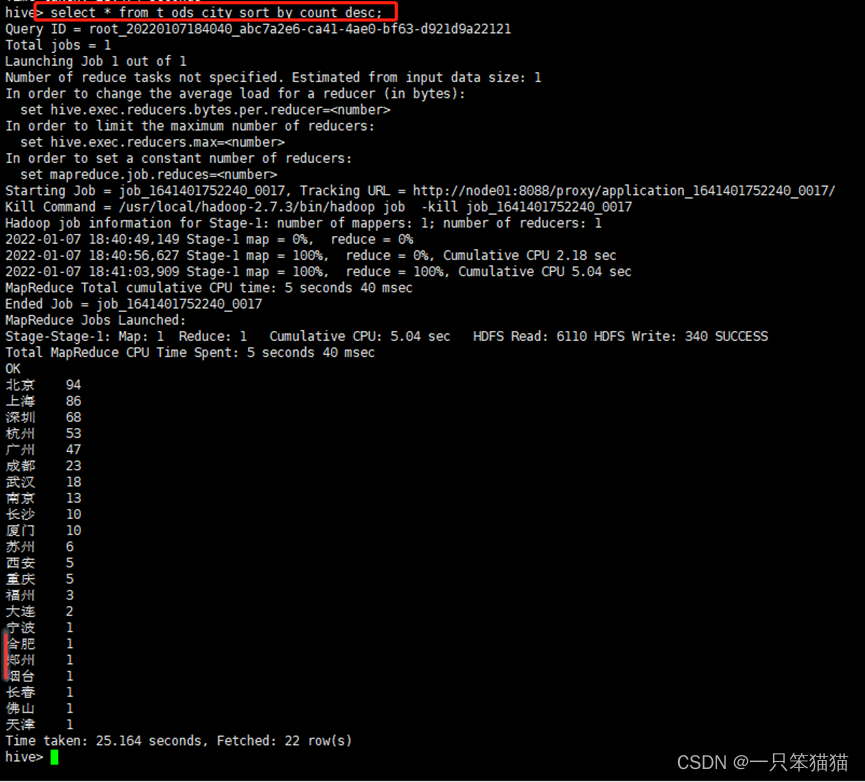
通过分析,可以得出以下三点结论
(1)大数据职位的需求主要集中在大城市,其中最多的是北京,其次分别是上海和深圳。
(2)一线城市(北上广深)占据前几名的位置,然而杭州这座城市对大数据职位的需求也很高,超越广州,次于深圳。
(3)四座一线城市北上广深加上杭州这五座城市的综合占总体的 77%,想要从事大数据相关岗位的从业者可以先考虑先这几个城市,,机遇会比较高。
2、职位薪资分析
(1)全国分布情况
通过中间表 t_ods_tmp_salary_dist 提取薪资分布数据进行统计分析,将分析结果存储在维度表 t_ods_salary 中
hive> insert overwrite table t_ods_salary
select `_c0`,count(1) from t_ods_tmp_salary_dist group by `_c0`;
因为创建临时表 t_ods_tmp_salary_dist 时使用的是 “create table as select” 语句,该语句不可以指定列名,所以默认列名为 _c0、_c1。
查看维度表 t_ods_salary 中的分析结果,使用 sort by 参数对表中的 count 列进行逆序排序
select * from t_ods_salary sort by count desc;
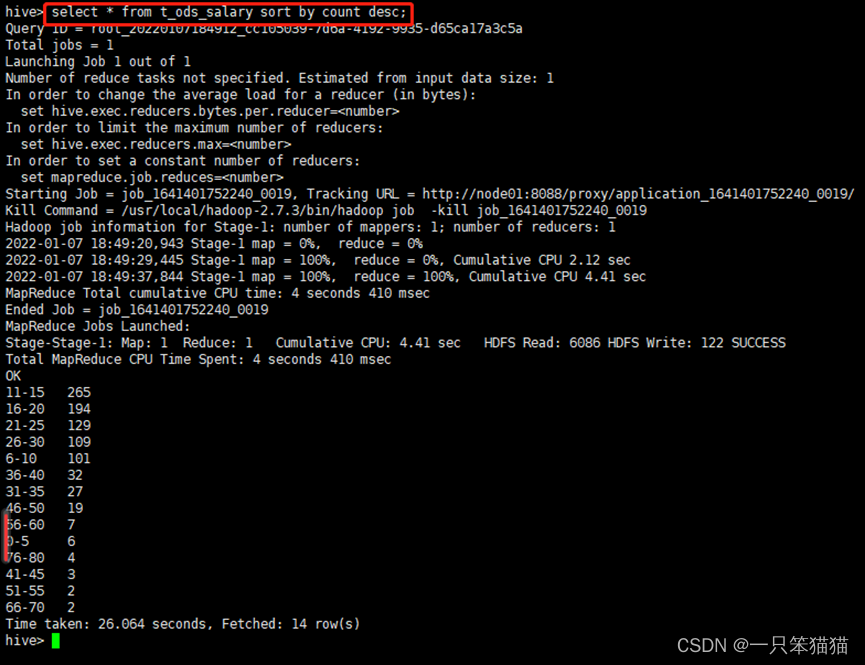
通过分析,可以了解到全国大数据相关岗位的月薪资分布主要集中在11k-30k,在总体的薪资分布中占比达77%,其中出现频次最高的月薪资区间在11k-15k。
(2)薪资的平均值、中位数和众数
通过明细表 ods_jobdata_detail 提取 avg_salary (高薪资 + 低薪资的平均值数据统计分析),此部分的分析结果本次不做数据的存储操作,通过查询结果查看分析内容。
1.求薪资的平均值
hive> select avg(avg_salary) from ods_jobdata_detail;
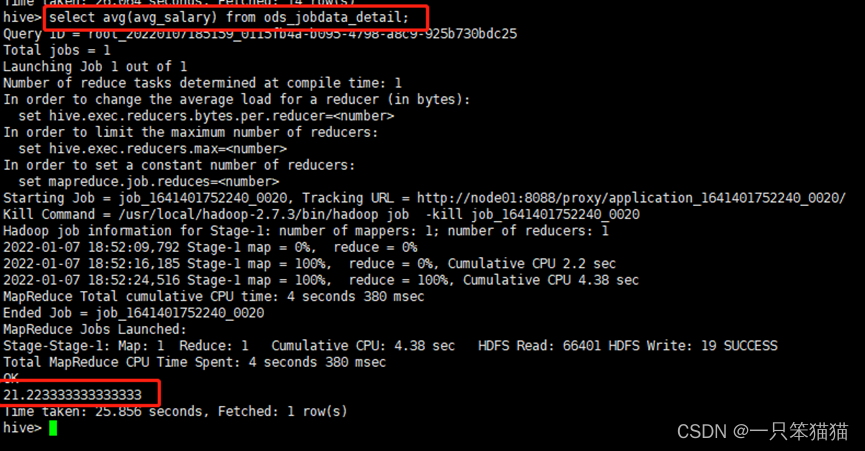
通过分析,全国大数据相关职位薪资的平均值为21.2333333333333333。
2.求薪资的众数
hive> select avg_salary,count(1) as cnt from ods_jobdata_detail group by avg_salary order by cnt desc limit 1;
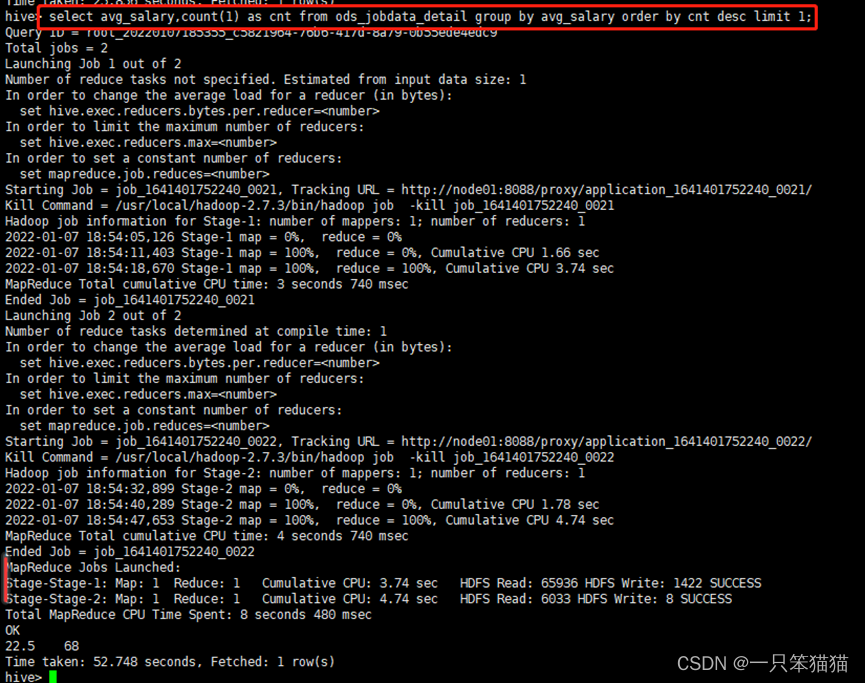
通过分析,全国大数据相关职位薪资的众数值为22.5,在整体薪资值中出现了68次。
3.求薪资的中位数
hive> select percentile(cast(avg_salary as BIGINT),0.5) from ods_jobdata_detail;
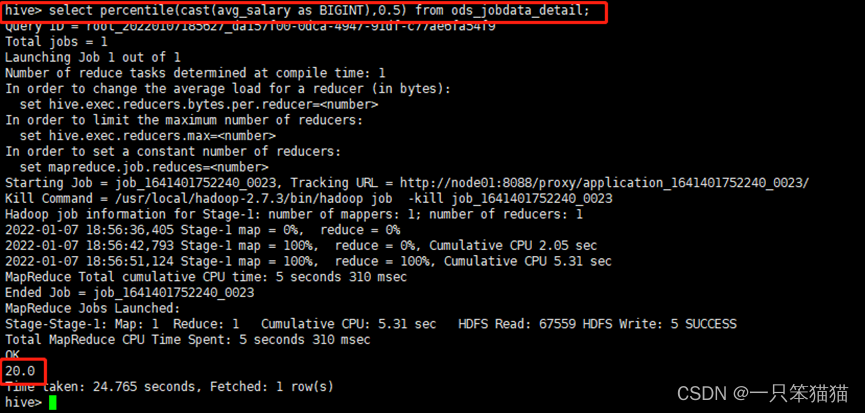
通过分析,全国大数据相关职位薪资的中位数值为20.0。
通过观察薪资平均值、众数、中位数的分析结果,可以得出,在全国大部分大数据职位的月薪资在20k以上。
(3)各城市平均薪资待遇
通过在查询句中添加 group by(分组)、avg(平均值)和 order by(排序)等函数对明细表 ods_jobdate_detail 中 avg_salary (高薪资+低薪资的平均值)和 city(城市)这两个字段数据进行统计分析获取各城市平均薪资待遇
hive> select city,count(city),round(avg(avg_salary),2) as cnt from ods_jobdata_detail group by city order by cnt desc;
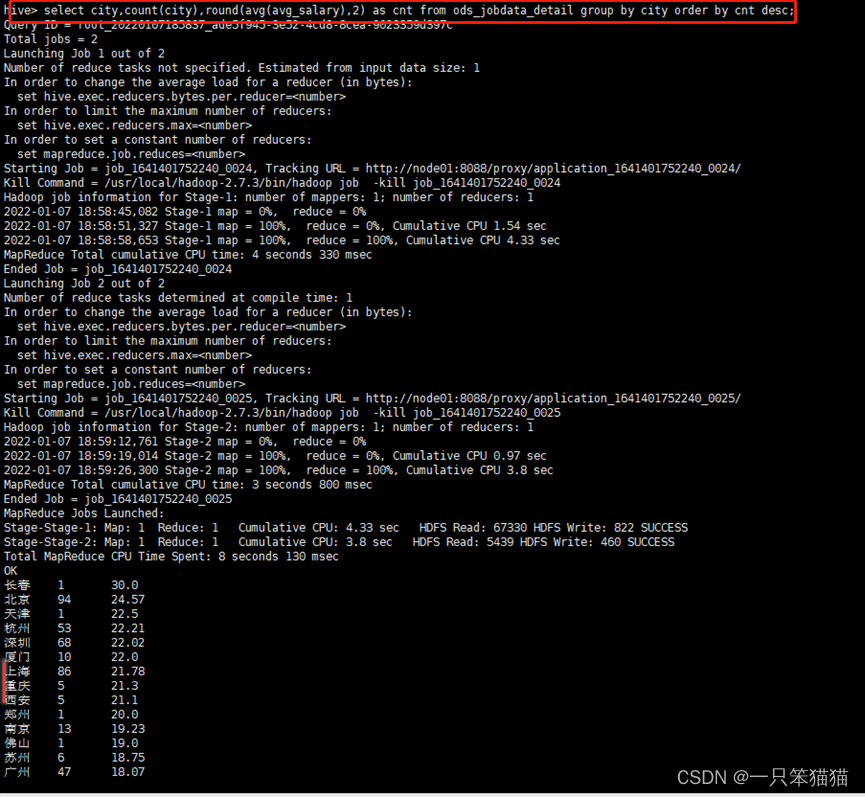
通过观察各城市平均薪资待遇分析结,可以看出最终的查询结果包括三部分数据:城市名称、城市职位数和城市平均薪资,从数据来看,长春的大数据职位平均薪资最高,但是该城市只有一个招聘的工作岗位,可以说是一枝独秀,没有什么选择性。相比较,北京、上海、深圳、杭州这四个城市的平均薪资待遇都在20k以上,而且招聘职位相比较其他城市较多,机遇更多一些。
3、公司福利分析
通过中间表 t_ods_tmp_company 提取福利标签数据进行统计分析,将分析结果存储在维度表 t_ods_company 中
hive> insert overwrite table t_ods_company select col,count(1) from t_ods_tmp_company group by col;
查看维度表 t_ods_company 中的分析结果,使用 sort by 参数对表中的 count 列进行逆序排序,因为标签内容数据较多,所以加上 limit 10 参数查看出现频次最多的前10个福利标签
hive> select every_company,count from t_ods_company sort by count desc limit 10;
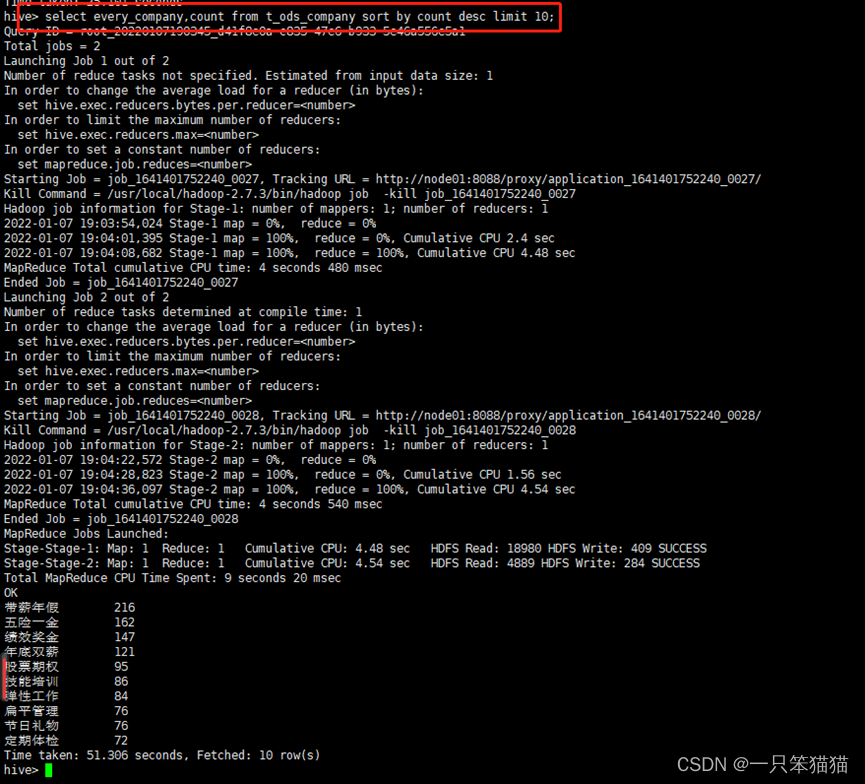
通过观察福利标签的分析数据,可以看出公司对员工的福利政策都有哪些,出现频次较多的福利标签可以视为大多数公司对员工的标准待遇,在选择入职公司时可作为一个参考。
4、职位技能要求分析
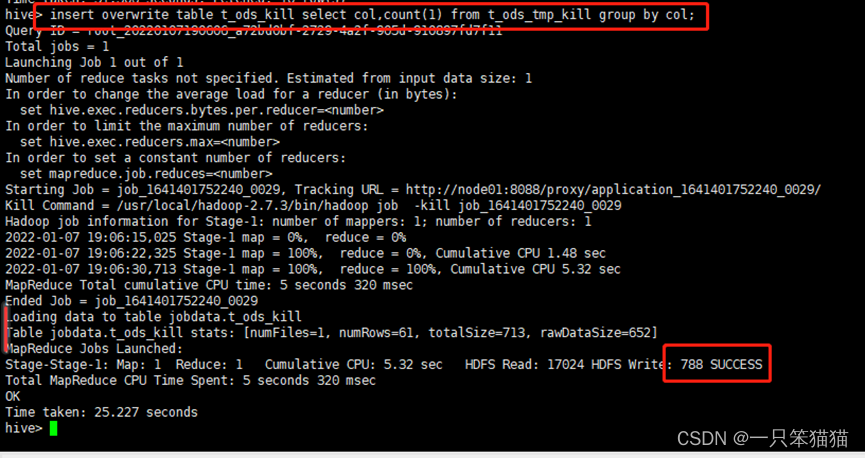
通过中间表 t_ods_tmp_kill 提取技能标签数据进行统计分析,将分析结果存储在维度表 t_ods_kill 中
hive> insert overwrite table t_ods_kill select col,count(1) from t_ods_tmp_kill group by col;
查看维度表 t_ods_kill 中的分析结果,使用 sort by 参数对表中的 count 列进行逆序排序,因为标签内容数据过多,所以加上 limit 3 参数查看出现频次最多的前3个技能标签
hive> select every_kill,count from t_ods_kill sort by count desc limit 3;
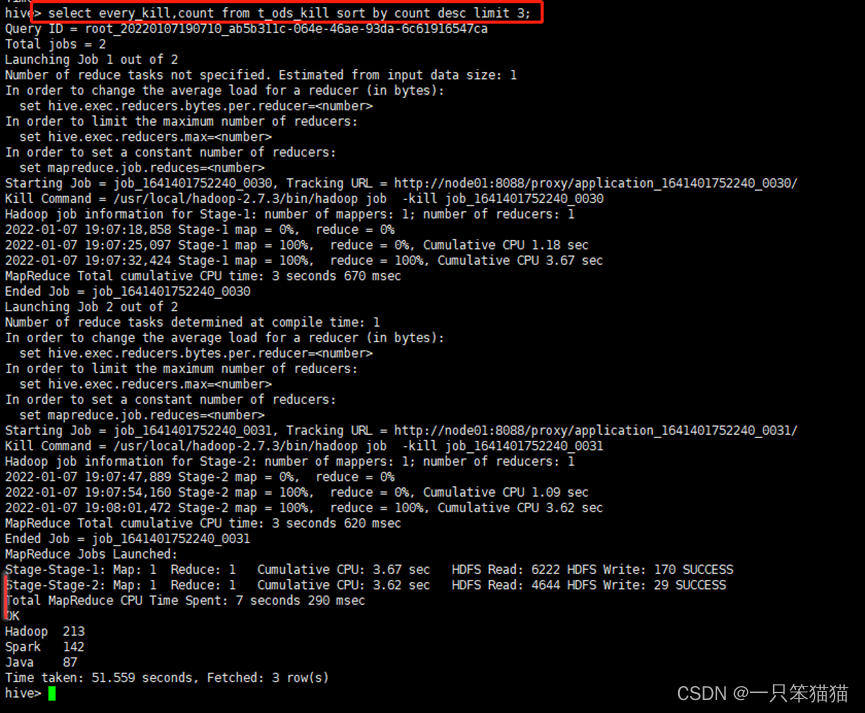
通过观察技能标签的分析数据,看到要从事大数据相关工作需要掌握哪些技能,这些需要掌握的技能前三名的占比达38%,也就是说,超过1/3的公司会要求大数据工作者需要掌握 Hadoop、Spark和Java这三项技能。
总结
本篇主要通过 Hive 进行数据分析。通过本篇的学习,读者可以掌握 HQL 创建数据仓库和数据分析的相关操作。