想起本科毕业论文时要用 Stata 跑实证却一点都不会的痛苦,这学期学明白了一点,因此写个帖子帮助一点都不懂的小白上手使用 Stata 。
本文9000余字,非常详细地介绍了最基础的命令。上篇内容包括 Stata 简介,标签命名,格式设置,统计信息与文件管理等,希望这些内容能为小白打好良好的基础。我认为只有掌握了最基本的命令,才不会对 Stata 望而生畏,从而进一步掌握高阶技巧,大神看到一笑而过就行,谢谢!数据处理的部分会放在下篇。
另外 csdn 并无 Stata 专属代码段,每一个新内容的命令我会加粗加斜标红显示,文段主要含义以及我认为需要强调的地方也会加粗表示。
Stata初步了解
获取
Stata 目前最新版本为 Stata17,相比于网络上各种混杂的下载地址,我推荐搜索“羽兔网”,进入网页内在右上角搜索栏里输入Stata,找到软件结果一栏,选择 17 版下载即可。该网站对于软件的获取与安装给予了详细的介绍,且广告较少,非常推荐。资源以百度网盘存储,这是唯一的缺点。(羽兔网地址:常见软件免费下载-羽兔网)
安装后运行你会看到如下界面:
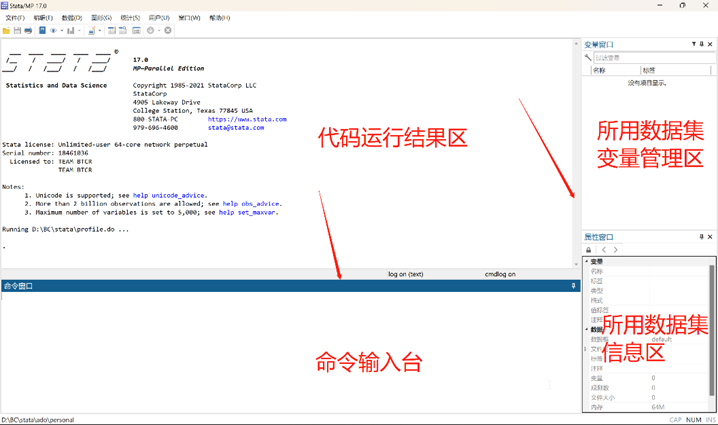
整个页面分为四个区。左上方为代码运行结果区,在命令输入台输入任何代码,无论正确与否,运行后都会返回结果。右上方为变量管理区域,右下角用的较少;代码运行除在命令输入台输入外,还可以编写 do 文档选中对应代码运行,我认为应理清STATA基本用法后再学习do文档,初期还是使用命令控制台;拖动红箭头所指的竖线与横线区域可以放大对应区。
简单练习
我们用STATA自带数据集进行一些使用上的练习。Stata 专属存储数据格式为 dta,在命令输入台输入sysuse nlsw88.dta, clear(其实不加 dta 也行,但是初学还是培养一下写后缀的意识)。
我们需对该命令进行介绍。sysuse 表示的是 (system use),即从系统中调用数据。使用非 Stata 自带数据只需输入 use,但自带的必须写 sysuse;Nlsw88 是1988 年收集的 2246 个美国年轻妇女相关资料的数据集,其格式存储为 dta,所以需在名字后加上格式后缀;clear 表示清除上一个数据集使用所占用的各种空间,研究时可能在各个数据集间穿梭,clear非常重要,请你导入新的数据集时,每次都在后面加入clear。另一个需讨论的问题是为什么clear是在逗号之后而不是之前,原因在于 Stata 命令通常会以几个字符开头,而后跟上最为关键的参数,缺少这些参数便无法运行,输入完必须输入的参数后,往往会加上一个逗号,在此后面的参数相对来说不那么重要,通常是一些格式命令。
打开数据后先不要着急操作,我需要先教你清除内存空间与清屏的命令。导入数据后,右上方数据变量管理栏是有许多变量的,他们都占用了内存空间,此时输入 clear all 便可使 Stata 回到启动的初始状态,你会发现数据变量栏的变量都消失了。如果觉得代码运行结果碍眼,输入 cls,就可以实现代码运行结果区的完全清除。两个命令并没有关联,clear all 把数据使用的痕迹全部擦除,代码运行结果并不会清零。而 cls 只会清屏,对于数据集不会产生影响。
现在,请再次导入数据。右上角的变量你可能看不懂,我们可以先查看一下数据的具体内容。控制台输入 br(全称为 browse,简写为 br),会立马打开数据页面。现在是浏览模式,红色框第一个选项为编辑模式,你可以在此模式下对数据进行改写,但不建议这样做,通常会污染数据。另外,如果变量非常多但你只想查看几个特定变量时,输入 br 想查看的变量名 ,例如 br race grade 只会显示 race 和 grade 两列数据浏览。可以说,大部分查看数据结构,统计概要的命令,只输入命令会显示全部的结果,在命令后加入具体变量名则显示特定结果。
标签管理
为变量与数据集添加标签
返回命令输入栏,我们接下来对变量的标签进行处理。为什么需要标签?在数据非常少的时候,我们可以通过简要命名来理解变量,但数据非常多时,如政府一般公共预算所有变量都包含时(这可能有几百个),此时再靠变量性质命名就不可行了。我本科毕业论文指导老师给我的数据里变量名字是 a1 - a332。这样命名的好处是方便我们编写代码,但不利于我们了解这个变量的含义,此时我们就需要为变量添加标签。标签就像化学里玻璃瓶外面贴的字一样,不改变玻璃瓶里东西的性质,又能告诉使用者这是什么物质。
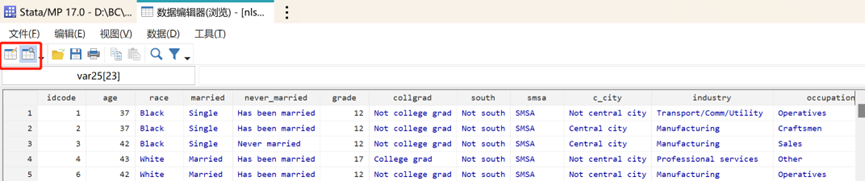
现在我们为变量加上中文标签使数据集更容易理解一些。对第一个表示个体编号的变量 idcode,我们输入 label var idcode "妇女个体编号",此时该变量后的标签就会显示为我们输入的文字。
label 表示标签类命令,var ( variable 简写) 表示我们要改变的是变量的标签,idcode 表示所要改变的变量,"妇女个体编号" 是我们输入的标签名称,请注意中文属于字符,需要用引号括起来,并且一定要使用英文引号,命令中的任何符号都是英文输入法下的符号,请不要使用中文符号。再输入 label var ttl_exp "已工作年数",改变另一个变量标签。如何对标签进行集体命名,很抱歉我目前也不清楚,似乎只能一个一个命名。如果你想去除一个变量的标签,需要采取赋名的形式,输入label var idcode,此时 idcode 的标签名消失。

你当然也可以为数据集贴上标签,研究使用一些不同版本的数据或相似但有区别的数据时,为数据集贴标签是非常有必要的。请输入 label data "1988年美国2246个妇女相关数据"。右下角数据集的 label 处你可以看到你刚刚的命名。

一个个翻找有哪些变量名显然是不方便的,输入 ds,这一命令会为你显示数据集中所有的变量名 。如果你认为某个变量名不合适或者命名错误,输入 rename idcode id,rename 为变量重命名命令,因为需指定对谁重命名,所以先写原变量名,之后再写你要更改的名字。此时你可以看到 idcode 变成了 id 。


为值变量添加标签
除变量与数据集加标签外,还有一个非常重要的是为值变量加标签。许多变量都有数值,但是他们不一定是值变量。值变量是以数值存储分类类型的变量,比如说 nlsw88 数据集里,种族 race 就是值变量。但是在数据浏览界面,你可以看到 race 下都是 white, black, other,似乎并不是数值存储,这是加入了标签的结果,实际上数据反应的含义是 white 为 1, black 为 2, other 为 3。也就是说 race 实际是由 1,2,3 组成的变量,而非浏览模式中的字符。为什么如此做?因为相比于字符,计算机更擅长于处理数字,采用数值存储变量的具体分类有利于计算机的快速运行,而对值变量赋予标签则有利于我们查看数据。(更多情况下是先有的分类名称,然后自己根据每一个分类设置对应的数值)
如何查看 race 的值标签呢?输入 label dir 会显示数据集中所有的值变量的标签名,而具体添加的标签,需要输入 label list,只查看 race 时,则需用到前面 label dir 所看到的对应变量的标签名,label list racelbl 你可以看到我前面所说的结果。
接下来我需要你练习如何去除值标签与为值变量添加标签。以 race 为例,输入 label drop racelbl ,此时查看数据你会发现 race 原先的字符全部变成了数字。添加值变量具体标签分为两步。
第一步,定义标签名称,label define race_lbl 1 "white" 2 "black" 3 "other"。label 为标签处理操作命令,define 是对标签命名的规则 race_lbl 进行定义,也就是说 race_lbl 存储了这样一个规则:1 表示 white,2 对应的是 black,3 是 other。
第二步,为值变量命名,输入label values race race_lbl。Values 表示是对值变量进行操作,因此在后面需立马写上要操作的值变量是 race。我们在第一步中封装了一个规则叫做 race_lbl,此时将它赋予给 race,输入命令后你可以看到 race 又变成了具体分类的字符,但实际上它仍是按数值存储的。值得注意的是,命令是 values 而非 value,因为分类值至少有两个,理解这一点可以减少你写错命令的概率。
如果数值标签漏加或加错也是可以更改的。首先让我们清除 race 标签,label drop race_lbl (drop为去除)。定义遗漏 2 的标签时:label define race_lbl 1 “white” 3 “other”, 之后再赋予规则 label values race race_lbl。由于定义时我们并没有定义数值 2 对应的标签,因此查看数据可以发现 race 中会出现数字 2,此时重新去除标签再赋值非常繁琐,我们可以 label define race_lbl 2 “black”, add,就可以将 2 的标签加上去,由于规则已经封装给了 race,此次命令仅是对封装命令规则的修改,因此不需要 label values 的步骤;如果说3定义错了,输入 label define race_lbl 3 “Asian”, modify。即可修正3的标签名。
数据结构查看与格式
格式设置
如果想要了解各变量是如何存储的,输入 d,该命令为 describe 的简写(注意和 ds 表示全部变量名所区分开)。Storage type 表示变量存储类型,int 为整数型,范围在 ±32000 左右,byte 是字节类型范围为 [-127,100] 仅占 1 个字节,值变量通常为 byte 类型。Float 则占 4 个字节。
Display format 是数据的展现格式。在网上的许多代码中你可以看到如第一个变量展现格式 %8.0g类似的代码,要记住这是格式代码。格式代码的设置非常有必要,有时回归展示的系数仅有 4 位,如果你想要 8 位的系数,就必须进行格式设置。
格式设置命令为 format 具体变量 %w.d 。format 为格式命令,% 表示设置,w(width) 表字符宽度也就是小数点前位数,d(digits) 表保留几位小数。在 d 后还可以加其他字母表示数值采用的格式,加f表固定格式,加 e 表科学计数法,加 g 表通用格式。说实话我也不知道 f 与 g 的区别。有时在某些命令逗号后你会见到 f(%8.1c),你要知道 f 指的就是 format。
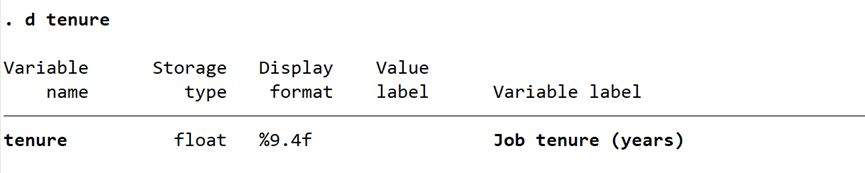
输入 br 查看数据显示格式你会发现 tenure 的值保留的小数位数比较混乱,我们需对变量 tenure 格式进行设置。我要教你一个小技巧,控制台输入命令后,其实无需手动输入变量名,将鼠标移动到变量窗口的具体变量名前,会出现下载符号,点击该符号即可实现变量名的输入,在跑回归时这样做会省去很多时间。在控制台输入 format tenure %9.4f,再看 tenure 数值你会发现格式统一保留了后四位数。再输入d tenure,与未设置之前的相比可以看到 tenure 的数据展示格式发生了变化。


输入 sysuse auto, clear 后打开摩托车数据,其中 make 变量为制造厂商。输入 list make,list 为在命令运行展示台展示对应的数据,与 br 命令相同功能。你会发现厂商都是右对齐的,如果想名称左对齐该如何做呢?输入 format make %-18s,负号 - 表示的就是左对齐,18 表示字符个数最多显示 18 个,s 表示告诉系统这是字符串。此后输入 d make,你会看到 make 的展示格式已经更改。再输入 list make in 1/20 你会得到下图。( in 表选中数据展示范围,1/20 表示 1-20 行)
统计信息
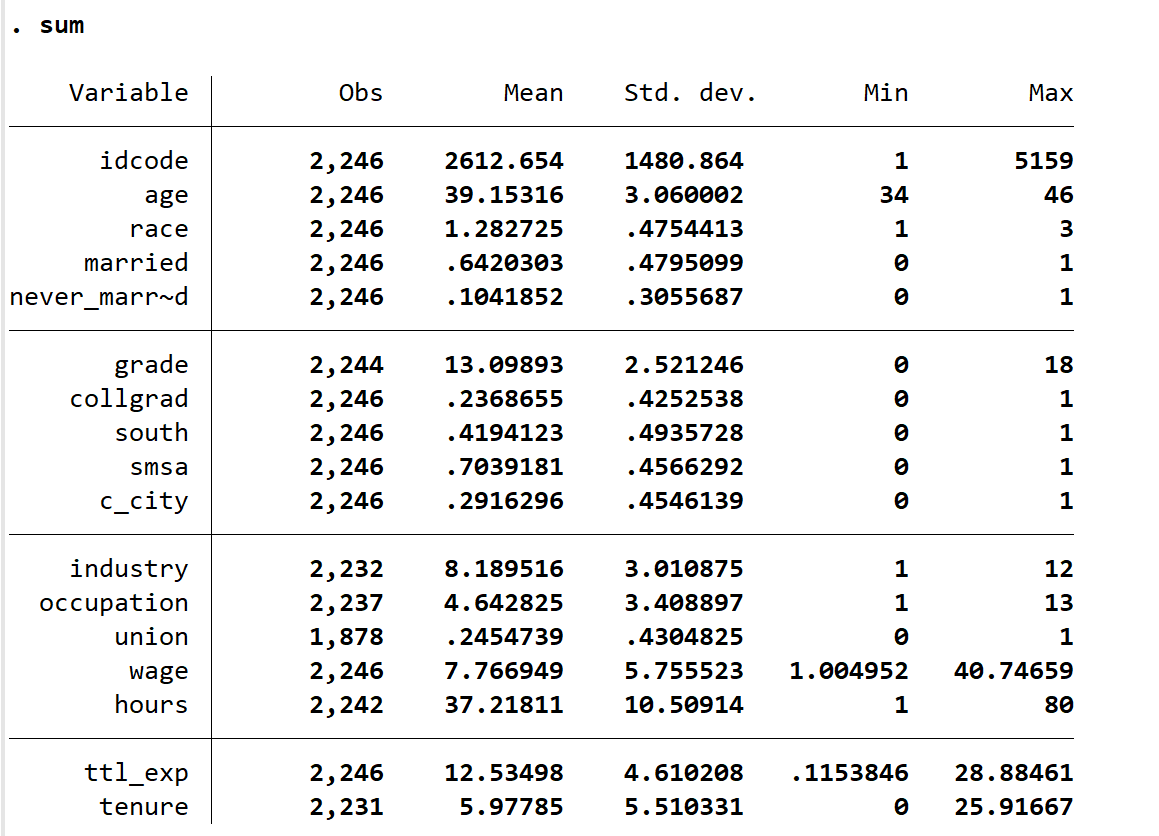
sum 命令是查看大致信息的一般命令,它会返回变量的样本容量,平均值,离散程度sd以及最大最小值。但通常来讲,我并不推荐这一命令,你可以看到它的显示格式非常糟糕,况且很多情况下我们想要看的是两个符合两个或多个条件的统计信息,例如已婚的黑人有多少个,就我的水平而言,我无法用 sum 命令做到这一点。
tabstat 是可以替代 sum 的一个命令,输入 tabstat age 会默认给出均值,如果想要更多的信息可以在命令后加入, s(mean range sum),s (应该是 statistic 的缩写),在其中给出你想知道的统计量,那些统计量我都写在了下方,但是对于初学者而言会用才重要。可以看出 tabstat 的优点在于给出的信息非常简洁,也可以给出指定统计信息,因此常有人用该命令作描述性统计。另外,图中变量为横轴,如果想要变量在左侧纵轴出现,请在逗号后加入 col(stat) 即可实现。
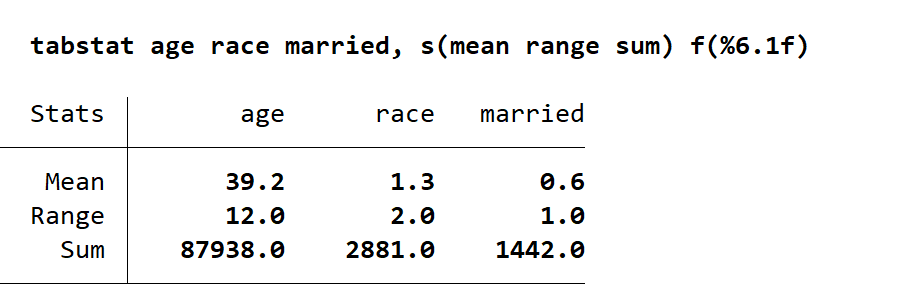
极差 range,变异系数 cv,非缺失值总数 count,标准误 semean,中位数 median
四分位数 q,四分位距 iqr,计数 n,方差 var,偏度 skewness
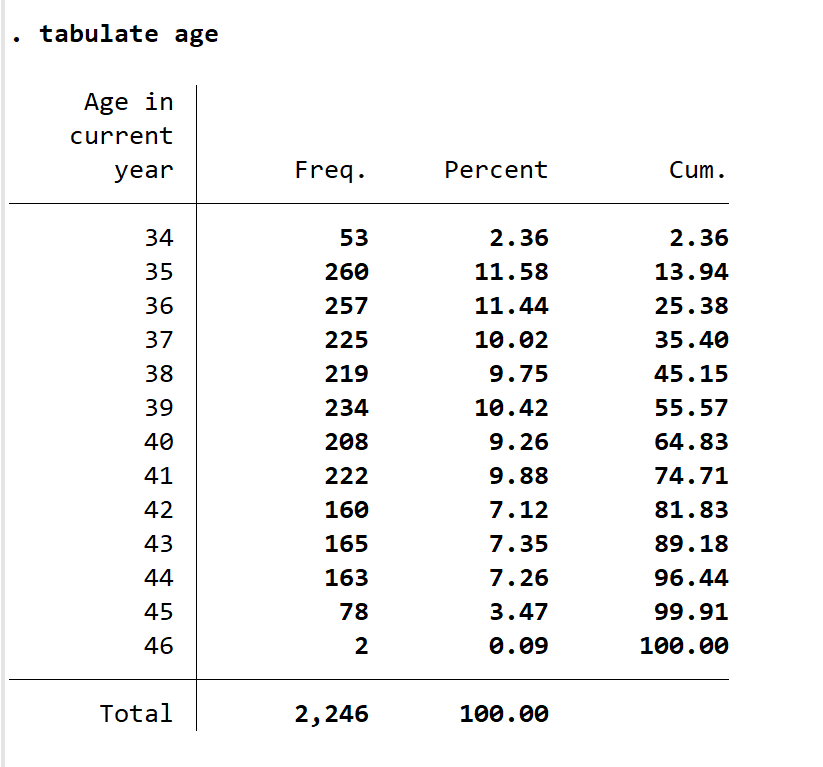
如果你想知道某个变量里不同的值出现的频次与百分比,tabulate 是一个很好的命令。输入tabulate age,你可以看到下图。Cum 指的是累计占比,如 36 的 cum 是由 34, 35, 36 占总体百分比相加得到的。
tabulate 命令更多用于创建二维列表。如我们想看 race 中 age 的分布,则输入 tabulate race age ,其中第一个变量为行变量,第二个变量为列变量。输入后你会发现表分成了上下两个并不是一个完整的图,这是出于显示的问题。一般而言,当变量值较多时,放在行变量更为恰当,重新输入 tabulate age race 你可以看到下图。
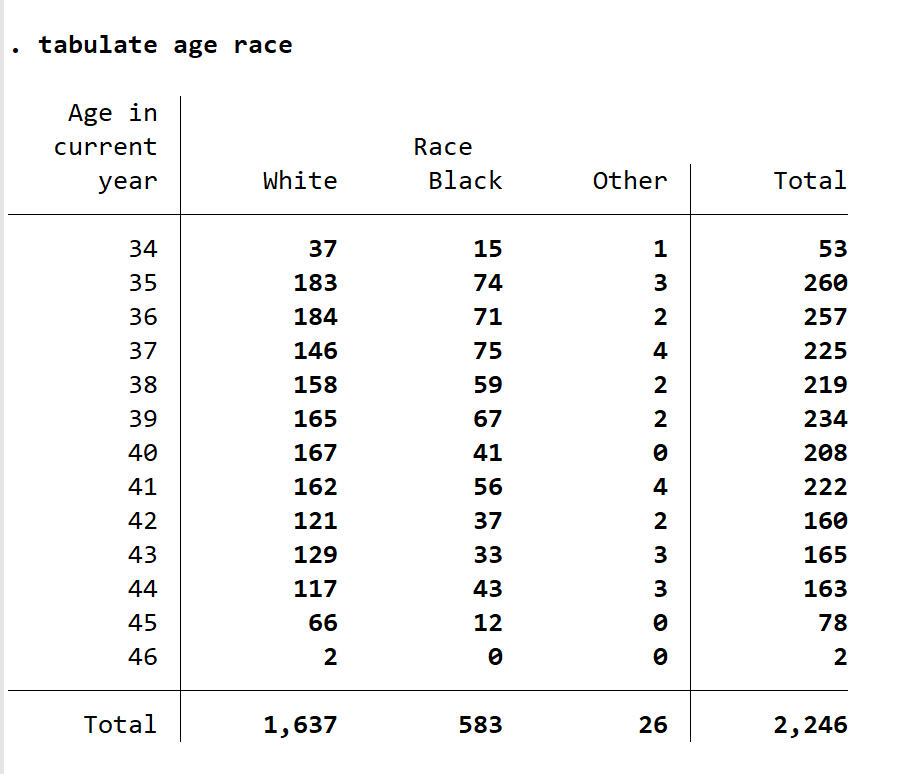
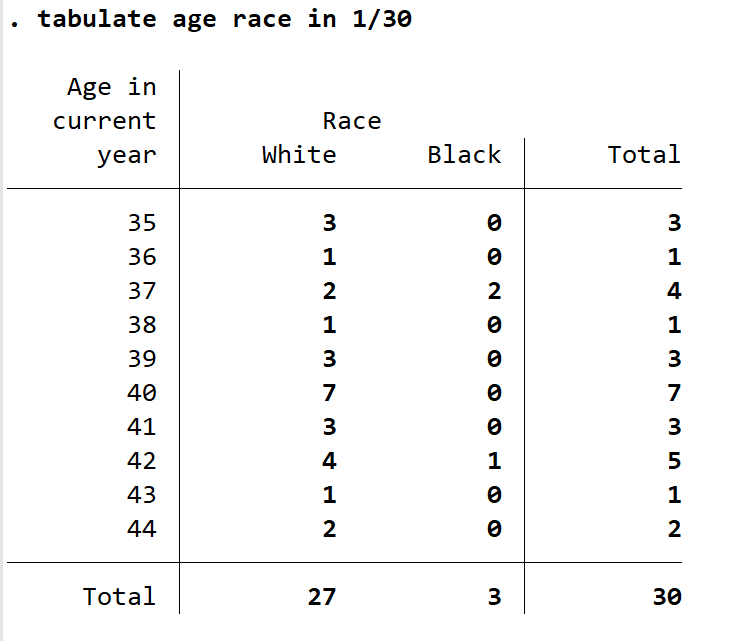
另外,如果你对数据进行排序后,比如说将将工资从大到小排序后,你只关心前30行的变量种族与年龄分布情况,则输入 tabulate age race in 1/30 ,此时统计表仅显示 1-30 行的数据统计情况,in 表示选定范围,/ 表示从 1 到 30 而不是或的意思。
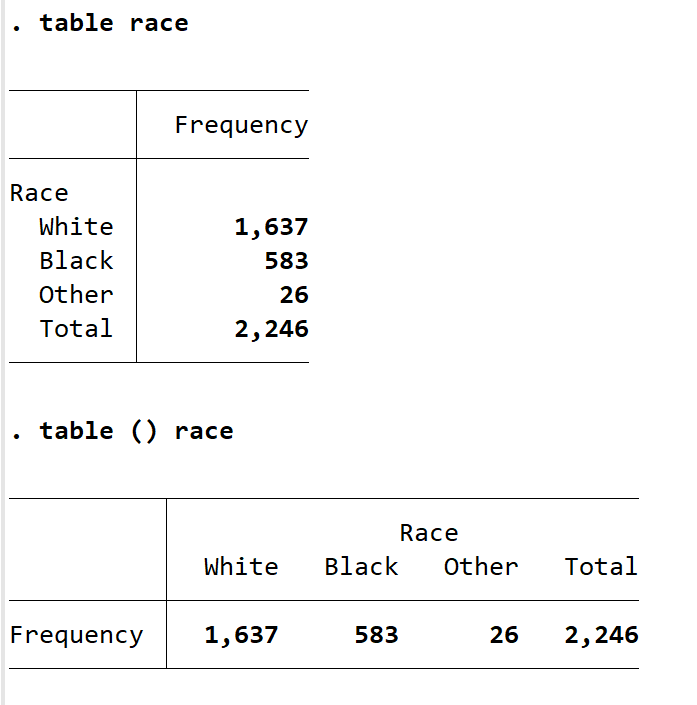
上述命令多用于连续变量,而涉及到虚拟变量或二值变量时,table 命令更为常用。现在了解一下race 的情况。输入 table race,该命令默认报告频数,且变量默认为行变量。如果想变量为列变量,输入 table () race ,这将 race 放在列变量的位置,但是行变量的位置需要加括号告诉系统以识别。
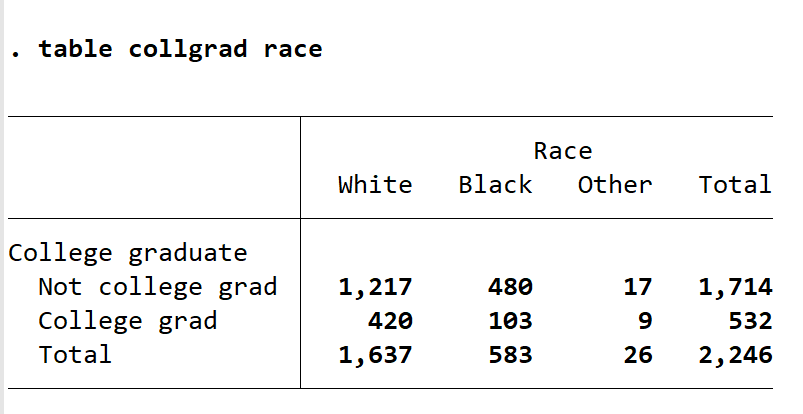
了解一下不同人种大学毕业状况,输入 table collgrad race ,可得下图(输入 collgrad 可用前文提到的点击变量前的下载小图标)
图中行与列都显示了总和,非常烦人。我们现在只关心大学毕业状况的人数总和,输入 table collgrad race, totals(collgrad),我们将会得到下图。输入 totals(race) 你会得到只显示行变量的总和。另外,我们通常不想看到列总和,此时只需在逗号后输入 nototals 即可,这种方式其实更为常用。

现在需展示更多的统计量。输入 table collgrad race, nototals stat(frequency) stat(percent) stat(mean age) stat(sd age),可以得到下图。这个命令需要注意的是,需要写成 stat 括号内加统计量名词,之所以是 stat 而不是 s 的原因我也不清楚,很有可能是因为 s 是其他命令的简称有所冲突。另外和前面 tabstat 命令里将所有统计量写入 s() 不同,table 命令对于想要展示的统计量都需要写一次 stat。frequency 与 percent 由于是二值变量无需指定。但我们其实更想知道的是某个人种,是否毕业的人数中的年龄的均值与方差,则我们需要指定 stat(mean age) stat(sd age),因此实际上 frequency 和 percent 的含义,和 mean sd 表达的含义完全不同,这一点需要注意。
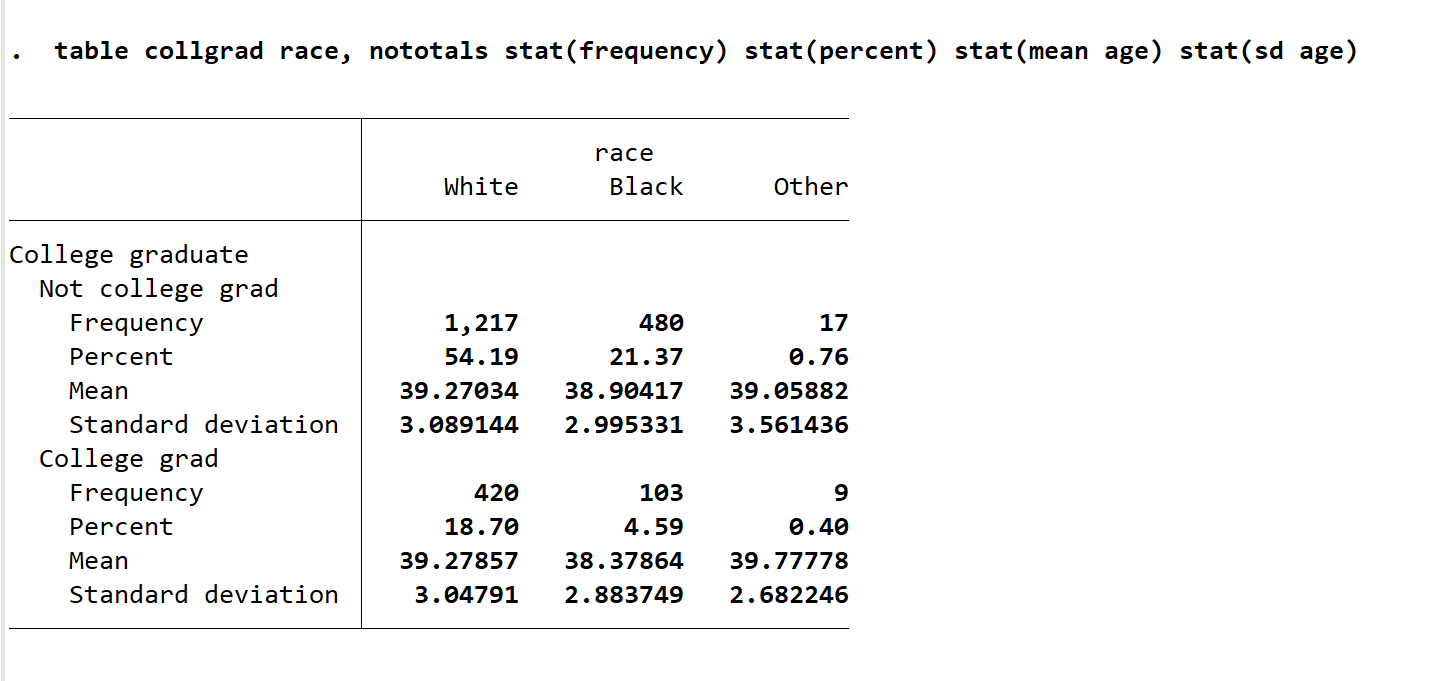
这个表展示了我们想要的东西,但有一个缺陷,就是不美观,每个变量小数位置显示不同。我们将变量设置为两位数小数显示,则只需在逗号后加入 nformat(%5.2f) 即可得到下图。nformat 表示的是 number format,括号内的含义需要你返回到前面的部分看关于格式设置的知识。如果你想要将 mean 与 sd 设置一样的格式,则输入 nformat(%5.3f mean sd),虽然这样并不好看,如果你想要表格数字呈现出完全对齐的形状,请你使用 nformat(%5.2f mean) nformat(%5.3f sd) 等命令一个个设置不同变量的显示格式。
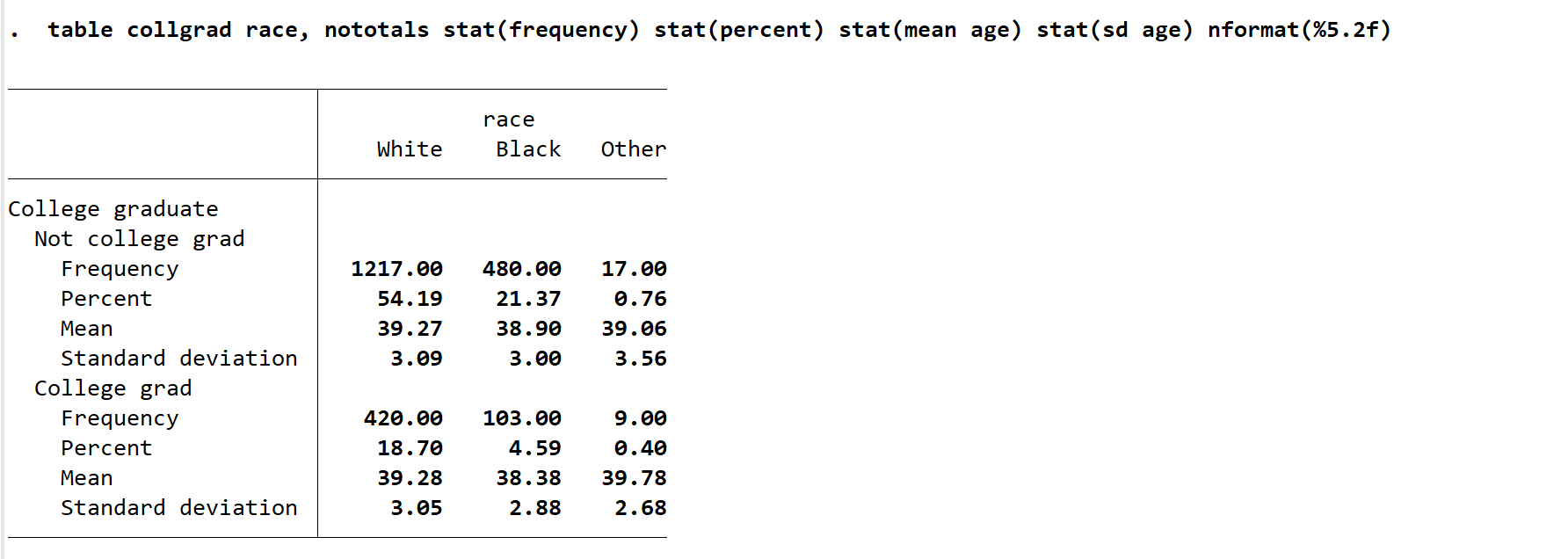
table 还有更高阶的用法,但初学者来说并不涉及,你需要在掌握我上述所说的内容后,在网上搜索你想要的图表的代码,那时候你才能理解代码在说什么。
文件管理与保证研究可重复
文件管理
在介绍数据处理之前,我需要对如何管理你的文件进行一些介绍。输入 sysdir (system directory),会显示 stata 五个主要文件夹,我的文件存储位置是更改过的,我会在后面说如何更改。文件夹你需要关注,第一个是 BASE,该文件夹存放 stata 自带命令的原始文件,PLUS 存放你自主下载的外部命令,PERSONAL 存放用户的个人文件。(下图为我的 stata 文件路径,我将stata 放到 D 盘的一个叫做 BC (编程)内的 stata 文件夹内了)这几个文件夹其实也可以不关注,但了解一下命令的存放位置可以帮你更好的了解命令的存放位置。

请输入 pwd(查看当前工作文件夹),该文件夹是 stata 此次工作时文件输入与输出的路径。日若你收集了一组数据,想在数据存放的文件夹里工作而非 stata 自带的路径,输入 cd D:\BC\stata,cd 为设置工作路径。通常,我喜欢在 stata 的文件存放位置新建一个文件夹,然后输入 pwd 查看当期工作路径,复制下来再加上新的位置。如 pwd 得到 D:\BC\stata\personal,在 personal 下面设置新文件夹 2022_12_VAT,然后输入 cd D:\BC\persoanl\2022_12_VAT。这是一种很方便的方式,但有一个麻烦的事情,你需要一个一个点开文件夹到达工作路径,如果你没有软件 Listary的话,输入 cdout,该命令会立马打开当前工作路径。
假设你把收集的数据文件放到工作路径后,现在你想要通过代码调用数据,你又不想打开工作路径一个个查看,那么使用 stata 自带的命令,输入 dir,该命令会展示当前工作路径下的所有文件。如果你只想看 dta 文件,你需要通配符*的帮助,输入dir *.dta,如果只想找 csv 文件也是同样的道理。如果说想看所有以 s 开头的文件,则输入 dir s*,他会展示所有类型的 s 开头的文件。
如果你觉得你在处理数据的过程中,文件过多,需要新设立一个文件夹单独存放,又不想打开文件夹,那么输入 mkdir data_1,该命令 mkdir 指 make directory 新创建文件夹,后加入你想创建的文件夹名字。刚刚创建的文件夹并没有存放任何实质的东西,我们需要将其删除,输入 rmdir data_1,其中 rmdir 指 remove directory 移除文件夹,后面直接跟上想要删除的文件夹即可。两个命令都默认在当前工作路径内工作。
连玉君老师也编写了更方便的命令,如果想了解请访问:https://www.lianxh.cn/news/3e220af7d06b7.html
可重复研究
可重复研究也可以参照连玉君老师的文章,但我觉得对于初学者或仅需要毕业论文的学生来说,只需要用到一部分。
什么是可重复研究,指你在写完初稿的几个月后初次答辩后,老师要求你改论文时,你知道你的数据是如何处理的,与论文对应的数据文件及图表分别是哪些。我写毕业论文时,犯了一个错误,即跑一次代码后,复制一次数据,导致数据有很多个版本,命名又很混乱,指导老师叫我改的时候我不知道哪一个是我的最终的数据,也不知道哪一个是初稿的毕业论文对应的图表。因此保证研究的可重复非常的重要。
可重复研究简化为 3 个部分。
第一,代码。首先,代码需规范,我们目前了解的都是非常基础的命令,更多的命令会在后续数据处理部分介绍,因此这里不关注代码书写问题。代码书写规范也可以参照连玉君老师的文章(搜索可重复性研究)。其次,最好每次研究后存放的是代码而非数据。因为数据往往会很大,且实际有效的只有最新一版的数据,初始数据往往也会丢失,多个版本的数据保存也会占用很多的空间。但do 文档(即 stata 的代码书写文档)只需要几十 k,详细的注释也可以帮助你很久之后回忆当时是怎么处理的数据,如果老师对你的数据处理有疑问,你只需要找出唯一的初始数据并打开 do 文档讲述你的处理过程即可,而不是找到十几个版本的数据且忘记了是怎么处理的。
第二,命名问题。命名首先涉及文件夹,一个研究最简单只需要 2 个文件夹:初始数据与处理文档+输出结果。但在几个月的研究过程中,你会多次跑代码,如果每次的处理输出文件较多时,我建议每次处理单独存放到一个文件夹里,文件夹命名为日期+版本,如 20230120_dp_v1,表示 2023年 1 月 20 号进行的 dp (data process 数据处理) 版本 1。若输出文件较少时,可以只写明所作内容+版本,如 dp_v2。为什么不需要时间,因为我觉得文件夹命名显示时间更加直观,而文件更关注版本,且文件夹中展示文件时他会显示时间。(提示:windows 里选中文件\文件夹,先按 Alt 后 按 Enter 可快速显示对象属性)。
第三,记录问题。记录指对每次 stata 运行时所输入的命令,以及命令和运行结果都给予展示。自动化记录很重要,即使有很多版本的文件可以帮助我们回忆,但具体操作我们是难以记住的,对此连玉君老师给出了自动化方案。先插句题外话,stata 每次运行前,会执行一个 profile.do 文件,而这个文件里包含了你的 sysdir 的文件夹,如果你想要改变 stata 的 personal 与 plus 文件的存放位置时,或者永久更改 stata 的工作路径为你指定的位置(否则你需要每次都要 cd ),将 profile.do文件中的文件路径更换为你想要的路径即可。如果想要每次运行都有记录日志的话,意味着需要打开时要自动生成操作日志,因此我们需要在 profile.do 文件中加入自动日志生成的代码,同样你只需更改对应的文件工作路径的代码即可,该代码也是连玉君老师编写,让我们一起谢谢老师。注意 profile.do 文件一定要存放到stata的子文件夹里,即和 ado 文件夹同一个位置。如果顺利,关闭stata 再打开随便操作几下后关闭,你会看到你设置的 log 文件夹里有两个 txt 文件,一个存放你输入的所有命令,一个存放命令加结果。
profile.do文件下载(百度云)
链接:https://pan.baidu.com/s/1E7-0ygtWuDJGb1vWNF7YnA
提取码:UA8y
至此,你已经拥有了使用 Stata 开展研究的最基础能力。但研究中数据处理是非常耗费时间的事情,如何进行数据处理,我会在下一篇文档中提及。