效果展示:
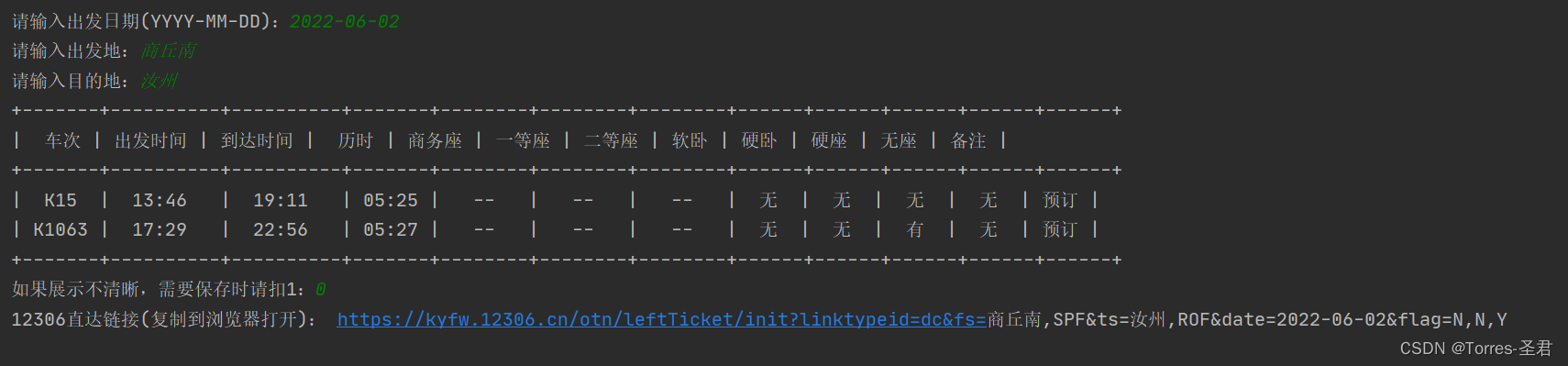
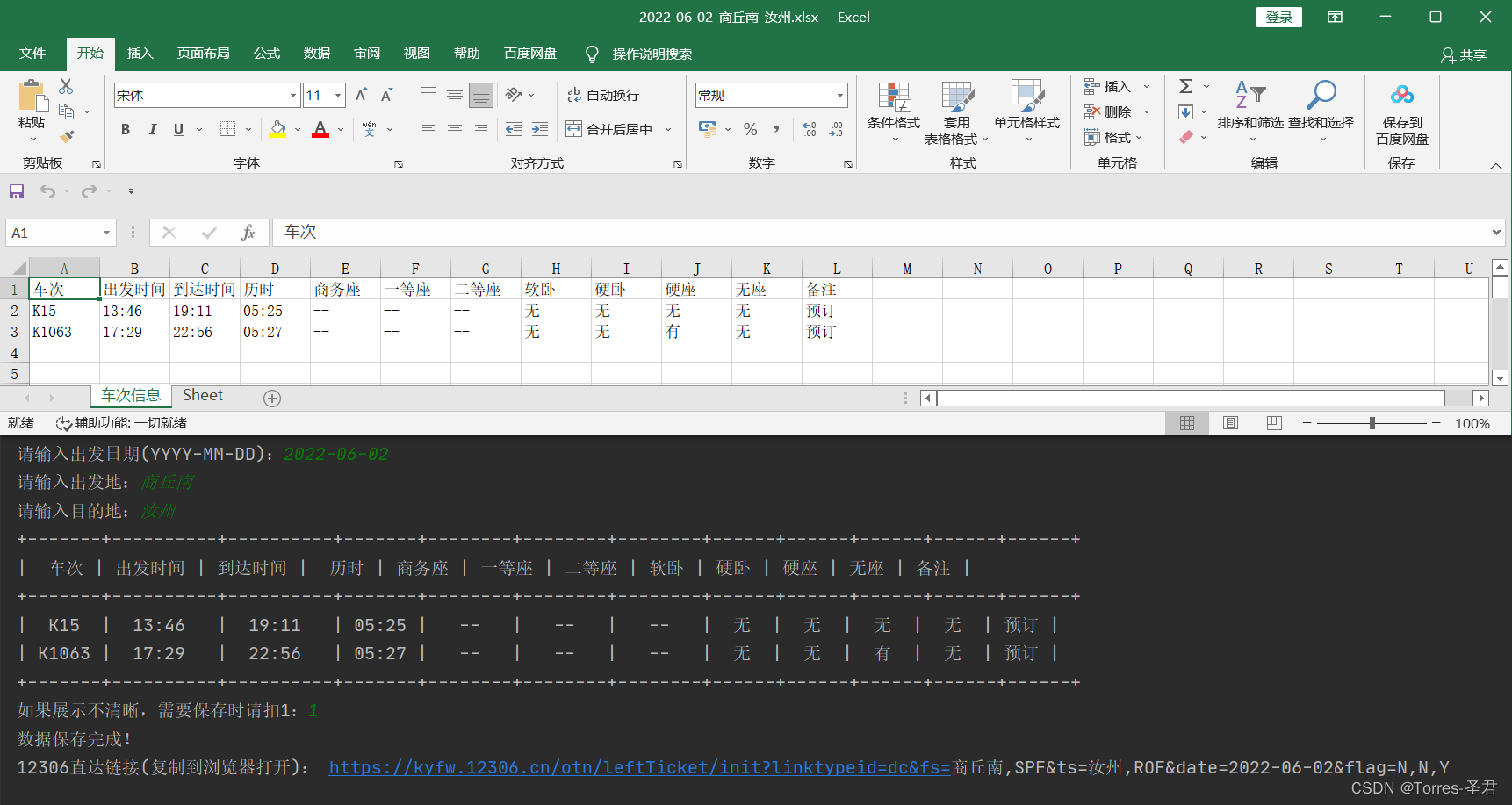
分析目标网站:
- 进入12306官网
- 以
商丘南到汝州为例,在点击查询后会跳转到查询结果的网站
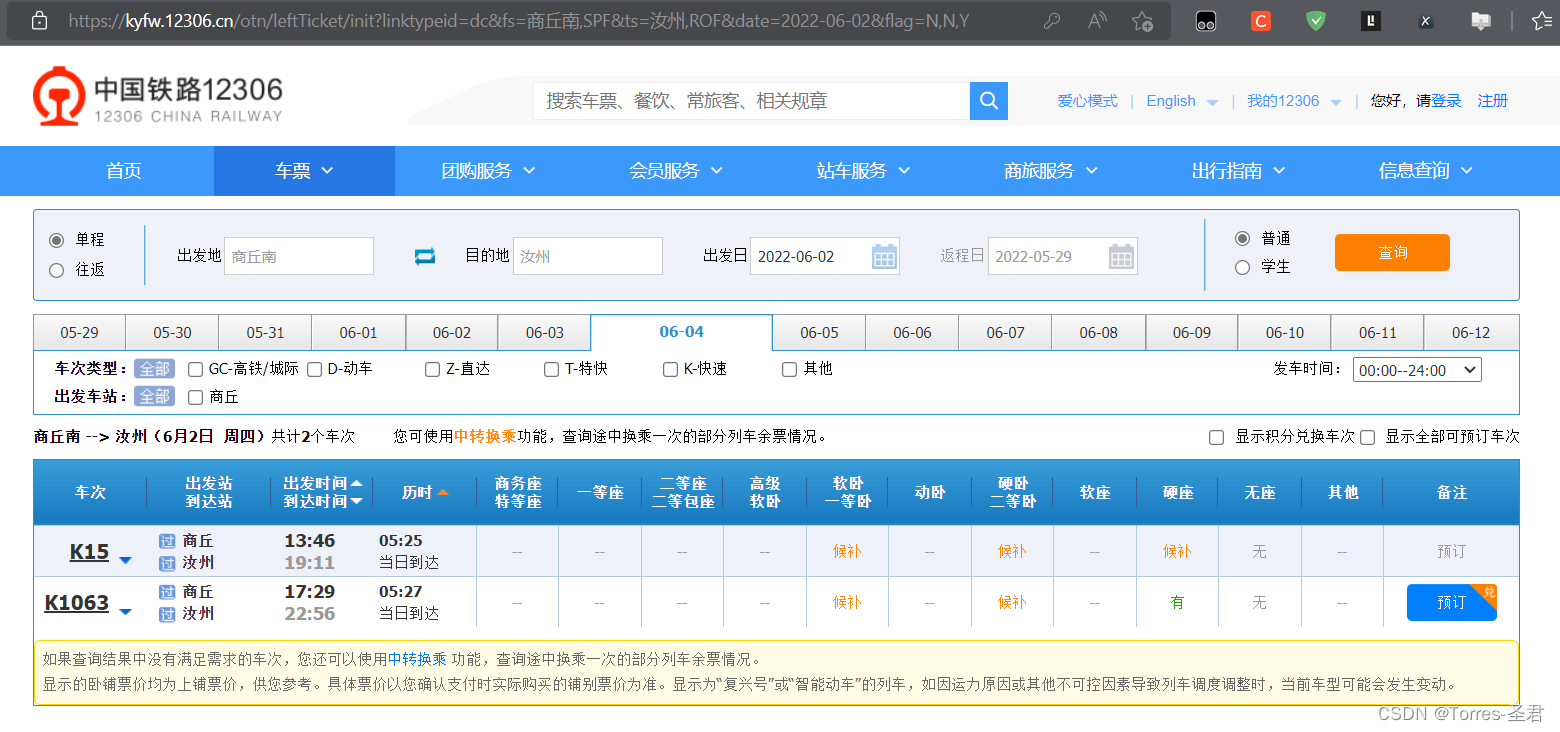
- 右键点
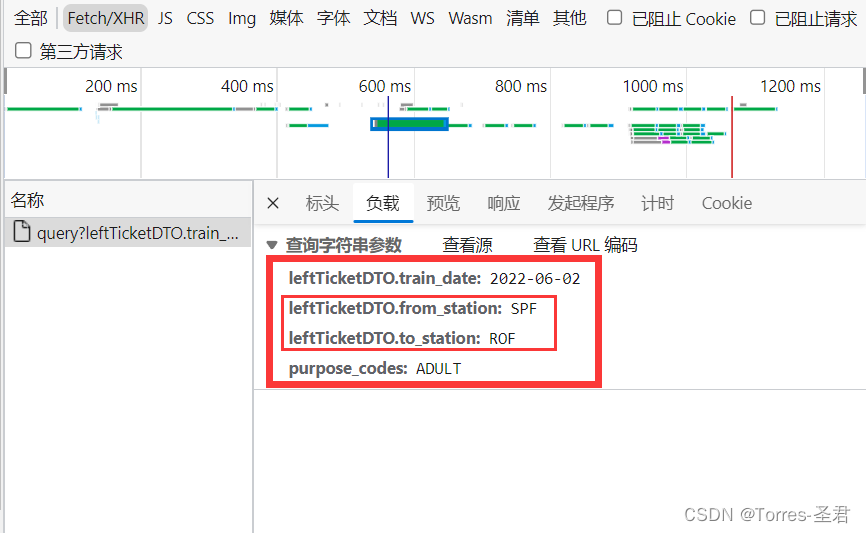
检查或审查元素,在弹出的控制台中点网络或network,如果没有显示数据的话,刷新一下网页就有了;在点击Fetch/XHR后会发现有一个名为query...的请求,点开它后再点击预览会发现,车票的信息就在这个里面
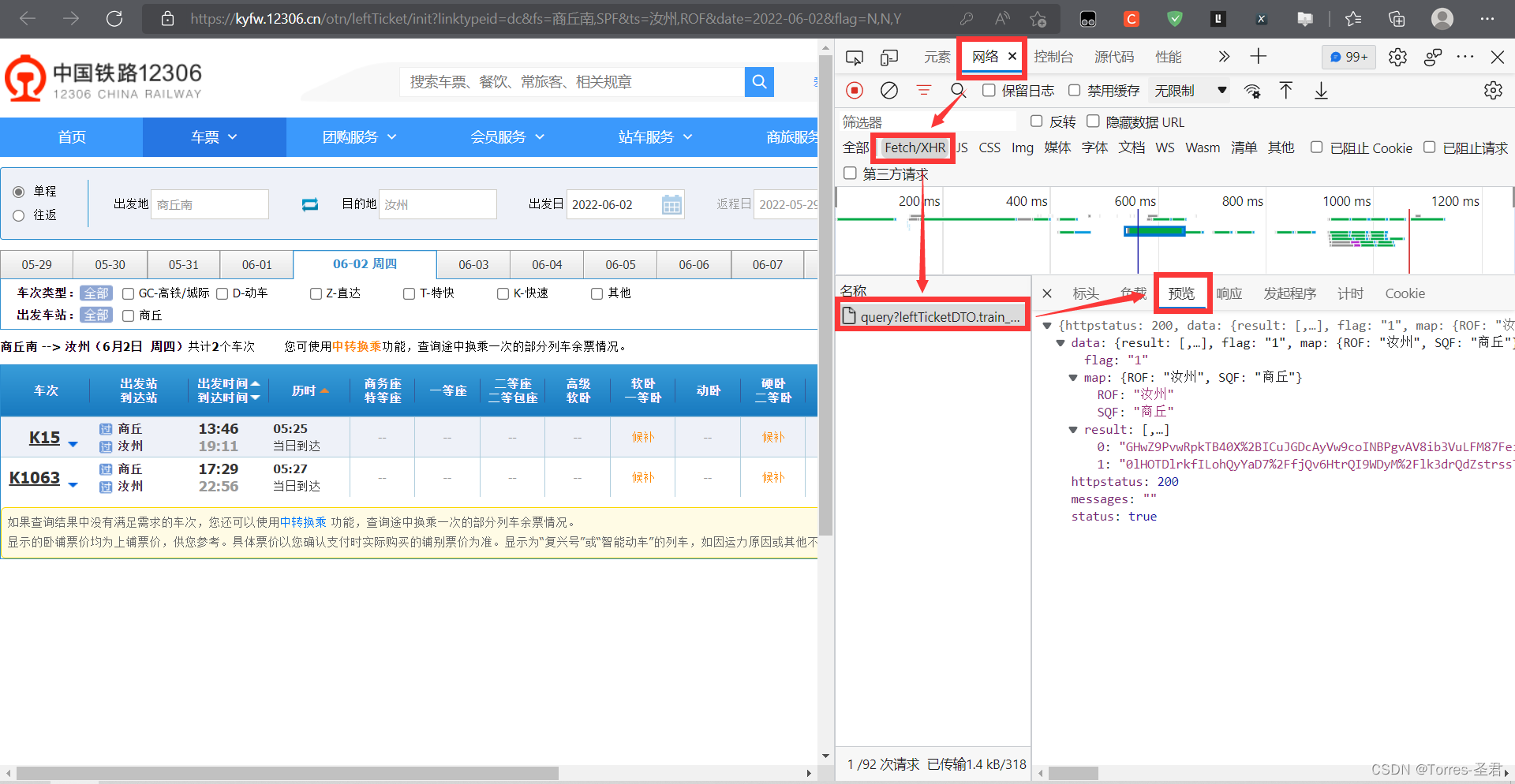
4. 在找到存放的车票信息后,按常理直接对目标链接发送请求即可,但我们通过查看URL携带的参数时,不难发现:
- 第一个参数:查询的日期,固定格式(YYYY-MM-DD)
- 第二个和第三个参数:不同城市对应的英文代码
- 第四个参数:固定值
获取所有城市英文代码:
- 这里不在过多叙述,找到
URL链接直接发送请求,获取响应的数据即可,代码如下:
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9053"
print("正在获取数据。")
# 发送请求,获取返回的数据
res = requests.get(url)
data = str(res.content, encoding="utf8")
print(data)

- 通过返回的数据可以发现,所有的数据都是以
|符号隔开的,所以使用split("|")对数据进行处理,代码如下:
dict_data = dict()
# 根据'|'分隔数据
list_data = data.split('|')
# 从下标'1'开始, 每间隔5个为字典key
result_x = list_data[1:len(list_data):5]
# 从下标'2'开始, 每间隔5个为字典value
result_y = list_data[2:len(list_data):5]
# 循环将数据写入字典
for i in range(len(result_x)):
dict_data[result_x[i].replace(" ", "")] = result_y[i]
print(dict_data)
- 将数据提取后保存到工作路径的
data文件夹下,这样后期使用时,就无需再次对该网站发送请求了,代码如下:
json_data = json.dumps(dict_data, indent=1, ensure_ascii=False)
with open("./data/city_data.json", 'w') as w:
w.write(json_data)
print("数据保存完成!")
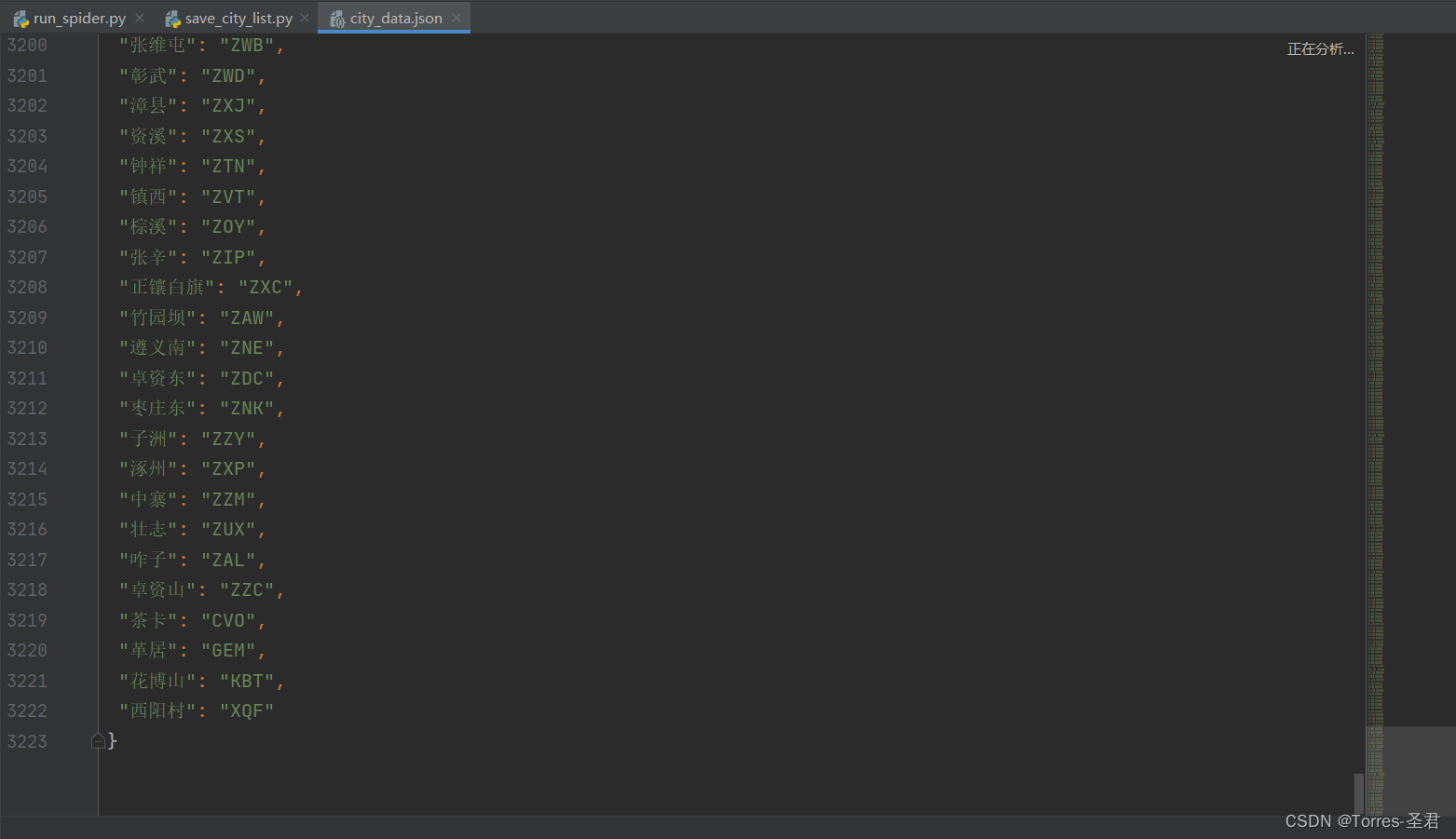
- 预览
city_data.json文件,所有的数据都已保存在了该文件里,共三千多个不同的城市。
完整版代码:
import requests
import json
def get_city_data():
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9053"
print("正在获取数据。")
# 发送请求,获取返回的数据
res = requests.get(url)
data = str(res.content, encoding="utf8")
# 格式化返回的数据
response_format(data)
def response_format(data):
dict_data = dict()
# 根据'|'分隔数据
list_data = data.split('|')
# 从下标'1'开始, 每间隔5个为字典key
result_x = list_data[1:len(list_data):5]
# 从下标'2'开始, 每间隔5个为字典value
result_y = list_data[2:len(list_data):5]
# 循环将数据写入字典
for i in range(len(result_x)):
dict_data[result_x[i].replace(" ", "")] = result_y[i]
# 保存数据
save_data(dict_data)
def save_data(dict_data):
json_data = json.dumps(dict_data, indent=1, ensure_ascii=False)
with open("./data/city_data.json", 'w') as w:
w.write(json_data)
print("数据保存完成!")
get_city_data()
获取12306车次的信息:
- 在前面成功获取所有城市对应的英文代码后,先让用户输入需要查询的日期、出发地和目的地信息,从文件中提取城市对应的英文代码,代码如下:
date = input("请输入出发日期(YYYY-MM-DD):")
begin = input("请输入出发地:")
end = input("请输入目的地:")
# 读取生成的json文件
city_list = json.load(open('./data/city_data.json', 'r'))
# 获取城市对应的英文代码
begin_id = city_list[begin]
end_id = city_list[end]
- 再获取到城市对应的英文代码后,构建请求头和需要携带的参数,代码如下:
# 请求的目标链接
self.url = "https://kyfw.12306.cn/otn/leftTicket/query"
# 构建请求头
self.headers = {
# 失效时,需要更新cookie
"Cookie": "JSESSIONID=5BCD4997EB7387D6F2F26CF860144AE6; RAIL_EXPIRATION=1653658158853; RAIL_DEVICEID=OYdRuCkXuonxJIyWihWNwMa5x-JAFt30BYWuZd9lAzHOtXh1TezSjz0oQm9n0TYq3InM3pJKfGexQCQEFpOqkTJq5XqXQ_taNYf1hTlQ6YWdWKWrJosRmvmDdUmt9omgZ2sDBAmcohSg662SJ-55JM97DtJQ0sfA; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; BIGipServerotn=384827914.50210.0000; BIGipServerpool_passport=31719946.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_toDate=2022-05-25; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u5546%u4E18%2CSQF; _jc_save_toStation=%u90D1%u5DDE%2CZZF; _jc_save_fromDate=2022-05-29",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53"
}
# 构建请求所需参数
self.params = {
"leftTicketDTO.train_date": date,
"leftTicketDTO.from_station": begin_id,
"leftTicketDTO.to_station": end_id,
"purpose_codes": "ADULT"
}
- 构建完成必须的参数后,发送请求观察返回的数据发现,每条数据间也是由
|隔开的,用同样的方法对数据进行分隔,代码如下:
res = requests.get(self.url, headers=self.headers, params=self.params).json()
data_list = res['data']['result']
for data in data_list:
all_data_list = data.split('|')
# 此处使用枚举,方便后期查看列表下标
for i,j in enumerate(all_data_list):
print(f"[{i}__{j}]")
- 提取列表元素中的数据,获取车次的相关信息,这里直接分享我查找的,不同车次信息对应列表元素的各下标,代码如下:
trains_msg = [
all_data_list[3],
all_data_list[8],
all_data_list[9],
all_data_list[10],
all_data_list[32] if all_data_list[32] != "" else "--",
all_data_list[31] if all_data_list[31] != "" else "--",
all_data_list[30] if all_data_list[30] != "" else "--",
all_data_list[23] if all_data_list[23] != "" else "--",
all_data_list[28] if all_data_list[28] != "" else "--",
all_data_list[29] if all_data_list[29] != "" else "--",
all_data_list[26] if all_data_list[26] != "" else "--",
all_data_list[1] if all_data_list[1] != "" else "--"
]
print(trains_msg)
- 到此以可以获取到车次的信息了,但以这种方式显示显然并不友好,下面介绍美化方法!
以表格形式输出车次信息:
-
这里我们使用的是prettytable第三方库,这个库可以将我们的数据进行表格化显示,安装方法:pip install prettytable
-
导入该模块,并实例化对象:
from prettytable import PrettyTable
# 实例化美化表格对象
self.pt= PrettyTable()
- 构建表头,并将提取的数据以表格的形式显示出来:
# 创建表头,即表格的首行信息
header_list = [
['车次', '出发时间', '到达时间', '历时', '商务座', '一等座', '二等座', '软卧', '硬卧', '硬座', '无座', '备注']
]
# 将表头信息添加进展示表格的表头
self.pt.field_names = header_list[0]
# 将提取到的车次信息添加到表格的内容信息
self.pt.add_row(trains_msg)
# 打印表格
print(self.pt)
- 此时的效果如下图所示,可以清晰的看出表格的对齐有点问题,所有此时为程序增加保存数据的功能!

将数据保存为Excel表格:
-
这里我们使用的是openpyxl第三方库,这个库可以将我们的数据进行表格化显示,安装方法:pip install openpyxl
-
导入该模块,并实例化对象:
from openpyxl import Workbook
wb = Workbook()
- 因为车次信息是不定的,所有车次少时可以无需保存,这时就需要用户自己选择是否要保存信息了,代码如下:
num = input("如果展示不清晰,需要保存时请扣1:")
if num == "1":
wb = Workbook()
sheet = wb.create_sheet("车次信息", -1)
# 遍历表格索引,写入数据
for x in range(len(trains_data_list)):
for y in range(len(trains_data_list[x])):
sheet.cell(x + 1, y + 1).value = trains_data_list[x][y]
wb.save(f"./data/{date}_{begin}_{end}.xlsx")
print("数据保存完成!")
- 为了更加人性化,这里通过用户输入的日期、出发地和目的地,再拼接出12306购票的直达链接,代码如下:
print(
"12306直达链接(复制到浏览器打开):",
"https://kyfw.12306.cn/otn/leftTicket/init?"
"linktypeid=dc&"
f"fs={begin},{begin_id}&"
f"ts={end},{end_id}&"
f"date={date}&"
"flag=N,N,Y"
)
- 此时就完全实现了这次的查票查询,谢谢观看~
最终完整版代码:
import requests
import json
from openpyxl import Workbook
from prettytable import PrettyTable
from save_city_list import get_city_data
class GetTrains:
def __init__(self, date, begin_id, end_id):
self.url = "https://kyfw.12306.cn/otn/leftTicket/query"
# 构建请求头
self.headers = {
# 失效时,需要更新cookie
"Cookie": "JSESSIONID=5BCD4997EB7387D6F2F26CF860144AE6; RAIL_EXPIRATION=1653658158853; RAIL_DEVICEID=OYdRuCkXuonxJIyWihWNwMa5x-JAFt30BYWuZd9lAzHOtXh1TezSjz0oQm9n0TYq3InM3pJKfGexQCQEFpOqkTJq5XqXQ_taNYf1hTlQ6YWdWKWrJosRmvmDdUmt9omgZ2sDBAmcohSg662SJ-55JM97DtJQ0sfA; guidesStatus=off; highContrastMode=defaltMode; cursorStatus=off; BIGipServerotn=384827914.50210.0000; BIGipServerpool_passport=31719946.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_toDate=2022-05-25; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u5546%u4E18%2CSQF; _jc_save_toStation=%u90D1%u5DDE%2CZZF; _jc_save_fromDate=2022-05-29",
# "Referer": referer,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53"
}
# 构建请求所需参数
self.params = {
"leftTicketDTO.train_date": date,
"leftTicketDTO.from_station": begin_id,
"leftTicketDTO.to_station": end_id,
"purpose_codes": "ADULT"
}
# 实例化美化表格对象
self.pt = PrettyTable()
def run(self):
# 对目标网址发送请求
res = requests.get(self.url, headers=self.headers, params=self.params).json()
data_list = res['data']['result']
# 构造表格的表头,用于展示和保存
header_list = [
['车次', '出发时间', '到达时间', '历时', '商务座', '一等座', '二等座', '软卧', '硬卧', '硬座', '无座', '备注']
]
# 将表头信息添加进展示表格的表头
self.pt.field_names = header_list[0]
for data in data_list:
# 格式化添加表数据
trains_msg = self.format_data(data)
# 将数据添加进列表,用于保存
header_list.append(trains_msg)
# 打印表格
print(self.pt)
# 返回车次信息列表
return header_list
def format_data(self, data):
# 将返回的数据以'|'进行分隔
all_data_list = data.split('|')
# 提取车次的信息
trains_msg = [
all_data_list[3],
all_data_list[8],
all_data_list[9],
all_data_list[10],
all_data_list[32] if all_data_list[32] != "" else "--",
all_data_list[31] if all_data_list[31] != "" else "--",
all_data_list[30] if all_data_list[30] != "" else "--",
all_data_list[23] if all_data_list[23] != "" else "--",
all_data_list[28] if all_data_list[28] != "" else "--",
all_data_list[29] if all_data_list[29] != "" else "--",
all_data_list[26] if all_data_list[26] != "" else "--",
all_data_list[1] if all_data_list[1] != "" else "--"
]
# 增添表内容
self.pt.add_row(trains_msg)
# 将提取的信息返回,用于保存
return trains_msg
def save_data(self, trains_data_list, date, begin, end):
num = input("如果展示不清晰,需要保存时请扣1:")
if num == "1":
wb = Workbook()
sheet = wb.create_sheet("车次信息", -1)
# 遍历表格索引,写入数据
for x in range(len(trains_data_list)):
for y in range(len(trains_data_list[x])):
sheet.cell(x + 1, y + 1).value = trains_data_list[x][y]
wb.save(f"./data/{date}_{begin}_{end}.xlsx")
print("数据保存完成!")
if __name__ == '__main__':
# 更新城市对应的英文代码,需要时再启用
# get_city_data()
date = input("请输入出发日期(YYYY-MM-DD):")
begin = input("请输入出发地:")
end = input("请输入目的地:")
# 读取生成的json文件
city_list = json.load(open('./data/city_data.json', 'r'))
# 获取城市对应的英文代码
begin_id = city_list[begin]
end_id = city_list[end]
gt = GetTrains(date, begin_id, end_id)
trains_data_list = gt.run()
# 是否需要保存数据
gt.save_data(trains_data_list, date, begin, end)
print(
"12306直达链接(复制到浏览器打开):",
"https://kyfw.12306.cn/otn/leftTicket/init?"
"linktypeid=dc&"
f"fs={begin},{begin_id}&"
f"ts={end},{end_id}&"
f"date={date}&"
"flag=N,N,Y"
)