python3下使用requests实现模拟用户登录 —— 基础篇(马蜂窝)
##1. 了解cookie和session
-
首先一定要先了解到cookie和session是什么,这是后面理解网站交互,模拟用户登录的基础。
###1.1. 无状态协议:Http
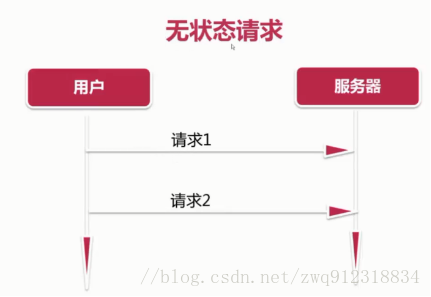
-
如上图所示,HTTP协议 是无状态的协议,用户浏览服务器上的内容,只需要发送页面请求,服务器返回内容。对于服务器来说,并不关心,也并不知道是哪个用户的请求。对于一般浏览性的网页来说,没有任何问题。
-
但是,现在很多的网站,是需要用户登录的。以淘宝为例:比如说某个用户想购买一个产品,当点击 “ 购买按钮 ” 时,由于HTTP协议 是无状态的,那对于淘宝来说,就不知道是哪个用户操作的。
-
为了实现这种用户标记,服务器就采用了cookie这种机制来识别具体是哪一个用户的访问。
###1.2. 了解cookie

-
如图,为了实现用户标记,在Http无状态请求的基础之上,我们需要在请求中携带一些用户信息(比如用户名之类,这些信息是服务器发送到本地浏览器的,但是服务器并不存储这些信息),这就是cookie机制。如下图所示,在登录马蜂窝网站之后,就可以看到浏览器已经保存了一些cookie信息(chrome浏览器为例):

-
需要注意的是:cookie信息是保存在本地浏览器里面的,服务器上并不存储相关的信息。 在发送请求时,cookie的这些内容是放在 Http协议中的header 字段中进行传输的。

-
几乎现在所有的网站都会发送一些 cookie信息过来,当用户请求中携带了cookie信息,服务器就可以知道是哪个用户的访问了,从而不需要再使用账户和密码登录。
-
但是,刚才也提到了,cookie信息是直接放在Http协议的header中进行传输的,看得出来,这是个隐患!一旦别人获取到你的cookie信息(截获请求,或者使用你的电脑),那么他很容易从cookie中分析出你的用户名和密码。为了解决这个隐患,所以有了session机制。
###1.3. 了解session
- 刚才提到了cookie不安全,所以有了session机制。简单来说(每个框架都不一样,这只是举一个通用的实现策略),整过过程是这样:
- 服务器根据用户名和密码,生成一个session ID,存储到服务器的数据库中。
- 用户登录访问时,服务器会将对应的session ID发送给用户(本地浏览器)。
- 浏览器会将这个session ID存储到cookie中,作为一个键值项。
- 以后,浏览器每次请求,就会将含有session ID的cookie信息,一起发送给服务器。
- 服务器收到请求之后,通过cookie中的session ID,到数据库中去查询,解析出对应的用户名,就知道是哪个用户的请求了。
####1.3.1. 看一下Django是如何实现session机制的,来加深对session的了解
- 第一步:对用户登录信息进行加密,生成一个sessionID,存储到数据库中。


Session_key:服务器给用户返回的ID
Session_data:一段加密的文字。用户名,密码,一些其他的用户信息。把这些信息生成一段字符串,是加密的
expire_date:django后台会设置过期时间。 主要是担心session被黑客截取,那就一直可以用,盗用数据。
-
第二步,当用户登录时,服务器会给本地浏览器返回一些cookie信息,包括session ID。

-
第三步:以后浏览器每次访问时,浏览器都会把 session ID带过来,这样服务器不需要知道你的用户名,就知道是哪个用户的访问了。
-
服务器是如何把sessionID转换成用户名的?

-
如上图所示,在Django中,需要对session进行配置。这个INSTALLED_APPS 是会对每次request和response进行拦截,拦截到浏览器发送过来的request时,找到其中的session信息,然后到数据库中进行查询,找到session_data,再做解密,就知道所有的用户信息了,取出user信息。新建完Django项目之后,这个sessions信息就配置好了。如果注释掉这一个session配置,自动登录机制就会失效,无法使用。
###1.4. 总结一下
- cookie 在客户端(本地浏览器),session 在服务器端。cookie是一种浏览器本地存储机制。存储在本地浏览器中,和服务器没有关系。每次请求,用户会带上本地cookie的信息。这些cookie信息也是服务器之前发送给浏览器的,或者是用户之前填写的一些信息。
- Cookie有不安全机制。 你不能把所有的用户信息都存在本地,一旦被别人窃取,就知道你的用户名和密码,就会很危险。所以引入了session机制。
- 服务器在发送id时引入了一种session的机制,很简单,就是根据用户名和密码,生成了一段随机的字符串,这段字符串是有过期时间的。
- 一定要注意:session是服务器生成的,存储在服务器的数据库或者文件中,然后把sessionID发送给用户,用户存储在本地cookie中。每次请求时,把这个session ID带给服务器,服务器根据session ID到数据库中去查询,找到是哪个用户,就可以对用户进行标记了。
- session 的运行依赖 session ID,而 session ID 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,那么同时 session 也会失效(但是可以通过其它方式实现,比如在url中传递 session ID)
- 用户验证这种场合一般会用 session。 因此,维持一个会话的核心就是客户端的唯一标识,即session ID
##2. 环境
- 系统:win7
- python 3.6.1
- requests 2.14.2 (通过pip list查看)
##3. 模拟登录马蜂窝网站
- 马蜂窝:http://www.mafengwo.cn/
##3.1. 分析用户登录流程
- 这里会用到两个小技巧
- 第一,先使用一个错误的用户名和密码来登录,这样就可以清晰的看到这个登录请求有post哪些数据,post到哪个url。因为如果使用正确的用户名和密码登录,一旦登录成功,就会直接跳转到其他页面,页面和请求都会被刷新。很难找出原始的请求信息。

- 第二,在截取请求的地方,勾选Preserve log,保留跳转前的请求数据。

- 截取到的请求如下:


#提取到的请求信息:
Headers:
Request URL:https://passport.mafengwo.cn/login/
Request Method:POST
origin:https://passport.mafengwo.cn
referer:https://passport.mafengwo.cn/
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Form Data:
passport:13725168940
password:aaa00000000
##3.2. 模拟登录
# -*- coding: utf-8 -*-
import requests
userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
header = {
# "origin": "https://passport.mafengwo.cn",
"Referer": "https://passport.mafengwo.cn/",
'User-Agent': userAgent,
}
def mafengwoLogin(account, password):
# 马蜂窝模仿 登录
print ("开始模拟登录马蜂窝")
postUrl = "https://passport.mafengwo.cn/login/"
postData = {
"passport": account,
"password": password,
}
responseRes = requests.post(postUrl, data = postData, headers = header)
# 无论是否登录成功,状态码一般都是 statusCode = 200
print(f"statusCode = {responseRes.status_code}")
print(f"text = {responseRes.text}")
if __name__ == "__main__":
# 从返回结果来看,有登录成功
mafengwoLogin("13756567832", "000000001")
- 一般来说,调试期,判断是否登录成功的最简单的方法:就是直接打印登录之后的text内容,使用错误的用户名登录,和使用正确的用户名登录,对比打印输出的内容。
- 后面会提出一个更好的判断方式…
##3.3. 使用cookie访问站点
- 在上一步,我们已经成功登录到马蜂窝网站了。那么接下来要如何访问站点中其他页面呢。前面提到过,网站是通过cookie和session来标记是哪个用户访问的。所以,在我们登录成功之后,有很重要的一步,就是我们需要把cookie保存下来,下一次请求这个站点的页面时,把这个cookie带过去。
###3.3.1. 保存cookie信息
# -*- coding: utf-8 -*-
import requests
# python2 和 python3的兼容代码
try:
# python2 中
import cookielib
print(f"user cookielib in python2.")
except:
# python3 中
import http.cookiejar as cookielib
print(f"user cookielib in python3.")
# session代表某一次连接
mafengwoSession = requests.session()
# 因为原始的session.cookies 没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,这个类实例化的cookie对象,就可以直接调用save方法。
mafengwoSession.cookies = cookielib.LWPCookieJar(filename = "mafengwoCookies.txt")
userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
header = {
# "origin": "https://passport.mafengwo.cn",
"Referer": "https://passport.mafengwo.cn/",
'User-Agent': userAgent,
}
def mafengwoLogin(account, password):
# 马蜂窝模仿 登录
print("开始模拟登录马蜂窝")
postUrl = "https://passport.mafengwo.cn/login/"
postData = {
"passport": account,
"password": password,
}
# 使用session直接post请求
responseRes = mafengwoSession.post(postUrl, data = postData, headers = header)
# 无论是否登录成功,状态码一般都是 statusCode = 200
print(f"statusCode = {responseRes.status_code}")
print(f"text = {responseRes.text}")
# 登录成功之后,将cookie保存在本地文件中,好处是,以后再去获取马蜂窝首页的时候,就不需要再走mafengwoLogin的流程了,因为已经从文件中拿到cookie了
mafengwoSession.cookies.save()
if __name__ == "__main__":
# 从返回结果来看,有登录成功
# mafengwoLogin("13756567832", "000000001")
# 文件:mafengwoCookies.txt
#LWP-Cookies-2.0
Set-Cookie3: __today_login=1; path="/"; domain=".mafengwo.cn"; path_spec; domain_dot; expires="2018-03-16 15:56:15Z"; httponly=None; version=0
Set-Cookie3: mafengwo="0a60e1a04f6a6f5555f0e285602b5b17_94281374_5aab641fb23d42.37804626_5aab641fb23dc3.28763728"; path="/"; domain=".mafengwo.cn"; path_spec; domain_dot; expires="2018-06-13 06:25:03Z"; httponly=None; version=0
Set-Cookie3: mfw_uuid="5aab641f-b789-96ef-736d-48640285f4c0"; path="/"; domain=".mafengwo.cn"; path_spec; domain_dot; expires="2019-03-16 06:25:03Z"; version=0
Set-Cookie3: oad_n="a%3A3%3A%7Bs%3A3%3A%22oid%22%3Bi%3A1029%3Bs%3A2%3A%22dm%22%3Bs%3A20%3A%22passport.mafengwo.cn%22%3Bs%3A2%3A%22ft%22%3Bs%00009%3A%222018-03-16+14%3A28%3A47%22%3B%7D"; path="/"; domain=".mafengwo.cn"; path_spec; domain_dot; expires="2018-03-23 06:25:03Z"; version=0
Set-Cookie3: uol_throttle=94281374; path="/"; domain=".mafengwo.cn"; path_spec; domain_dot; expires="2018-03-16 06:35:03Z"; version=0
###3.3.2. 使用cookie登录
- 为了测试访问页面时,是否处于登录状态。有一个比较巧妙的方法:就是直接访问一个需要登录后,才可见的地址。比如说涉及到用户信息的页面。下面以 “我的路线” 页面为例:http://www.mafengwo.cn/plan/route.php
- 这是登录状态后见到的页面:


- 如果是 非登录状态,会自动跳转(重定向302)到 用户登录页面:

- 所以,我们可以用这个页面判断cookie登录是否成功,代码如下:
# -*- coding: utf-8 -*-
import requests
# python2 和 python3的兼容代码
try:
# python2 中
import cookielib
print(f"user cookielib in python2.")
except:
# python3 中
import http.cookiejar as cookielib
print(f"user cookielib in python3.")
# session代表某一次连接
mafengwoSession = requests.session()
# 因为原始的session.cookies 没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,这个类实例化的cookie对象,就可以直接调用save方法。
mafengwoSession.cookies = cookielib.LWPCookieJar(filename = "mafengwoCookies.txt")
userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
header = {
# "origin": "https://passport.mafengwo.cn",
"Referer": "https://passport.mafengwo.cn/",
'User-Agent': userAgent,
}
def isLoginStatus():
# 通过访问个人中心页面的返回状态码来判断是否为登录状态
routeUrl = "http://www.mafengwo.cn/plan/route.php"
# 下面有两个关键点
# 第一个是header,如果不设置,会返回500的错误
# 第二个是allow_redirects,如果不设置,session访问时,服务器返回302,
# 然后session会自动重定向到登录页面,获取到登录页面之后,变成200的状态码
# allow_redirects = False 就是不允许重定向
responseRes = mafengwoSession.get(routeUrl, headers = header, allow_redirects = False)
print(f"isLoginStatus = {responseRes.status_code}")
if responseRes.status_code != 200:
return False
else:
return True
if __name__ == "__main__":
mafengwoSession.cookies.load()
isLogin = isLoginStatus()
print(f"is login mafengwo = {isLogin}")
'''
# 按照之前保存过的mafengwoCookies.txt登录,属于登录状态:
user cookielib in python3.
isLoginStatus = 200
is login mafengwo = True
'''
'''
# 如果把mafengwoCookies.txt中的信息修改掉之后,就无法登录了,属于非登录状态了
user cookielib in python3.
isLoginStatus = 302
is login mafengwo = False
'''
##3.4. 最终形成的登录模式
- 因为cookie是有有效期的,所以没法做到一次登录,终生有效。所以,一般的登录模式,就是:
- 第一步:先尝试cookie登录
- 第二步:如果cookie无法登录成功,就使用用户名密码登录,将新的cookie保存下来。
# -*- coding: utf-8 -*-
import requests
# python2 和 python3的兼容代码
try:
# python2 中
import cookielib
print(f"user cookielib in python2.")
except:
# python3 中
import http.cookiejar as cookielib
print(f"user cookielib in python3.")
# session代表某一次连接
mafengwoSession = requests.session()
# 因为原始的session.cookies 没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,这个类实例化的cookie对象,就可以直接调用save方法。
mafengwoSession.cookies = cookielib.LWPCookieJar(filename = "mafengwoCookies.txt")
userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
header = {
# "origin": "https://passport.mafengwo.cn",
"Referer": "https://passport.mafengwo.cn/",
'User-Agent': userAgent,
}
# 马蜂窝模仿 登录
def mafengwoLogin(account, password):
print("开始模拟登录马蜂窝")
postUrl = "https://passport.mafengwo.cn/login/"
postData = {
"passport": account,
"password": password,
}
# 使用session直接post请求
responseRes = mafengwoSession.post(postUrl, data = postData, headers = header)
# 无论是否登录成功,状态码一般都是 statusCode = 200
print(f"statusCode = {responseRes.status_code}")
print(f"text = {responseRes.text}")
# 登录成功之后,将cookie保存在本地文件中,好处是,以后再去获取马蜂窝首页的时候,就不需要再走mafengwoLogin的流程了,因为已经从文件中拿到cookie了
mafengwoSession.cookies.save()
# 通过访问个人中心页面的返回状态码来判断是否为登录状态
def isLoginStatus():
routeUrl = "http://www.mafengwo.cn/plan/route.php"
# 下面有两个关键点
# 第一个是header,如果不设置,会返回500的错误
# 第二个是allow_redirects,如果不设置,session访问时,服务器返回302,
# 然后session会自动重定向到登录页面,获取到登录页面之后,变成200的状态码
# allow_redirects = False 就是不允许重定向
responseRes = mafengwoSession.get(routeUrl, headers = header, allow_redirects = False)
print(f"isLoginStatus = {responseRes.status_code}")
if responseRes.status_code != 200:
return False
else:
return True
if __name__ == "__main__":
# 第一步:尝试使用已有的cookie登录
mafengwoSession.cookies.load()
isLogin = isLoginStatus()
print(f"is login mafengwo = {isLogin}")
if isLogin == False:
# 第二步:如果cookie已经失效了,那就尝试用帐号登录
print(f"cookie失效,用户重新登录...")
mafengwoLogin("13756567832", "000000001")
resp = mafengwoSession.get("http://www.mafengwo.cn/plan/fav_type.php", headers = header, allow_redirects = False)
print(f"resp.status = {resp.status_code}")
# 第一次运行程序的输出:
# 由于第一次还没有生成cookie,所以需要用账户登录一次
user cookielib in python3.
isLoginStatus = 302
is login mafengwo = False
cookie失效,用户重新登录...
开始模拟登录马蜂窝
statusCode = 200
……………………
resp.status = 200
# 第二次运行程序的输出:
# 第二次,就直接使用cookie登录了,不再需要使用帐号登录
user cookielib in python3.
isLoginStatus = 200
is login mafengwo = True
resp.status = 200