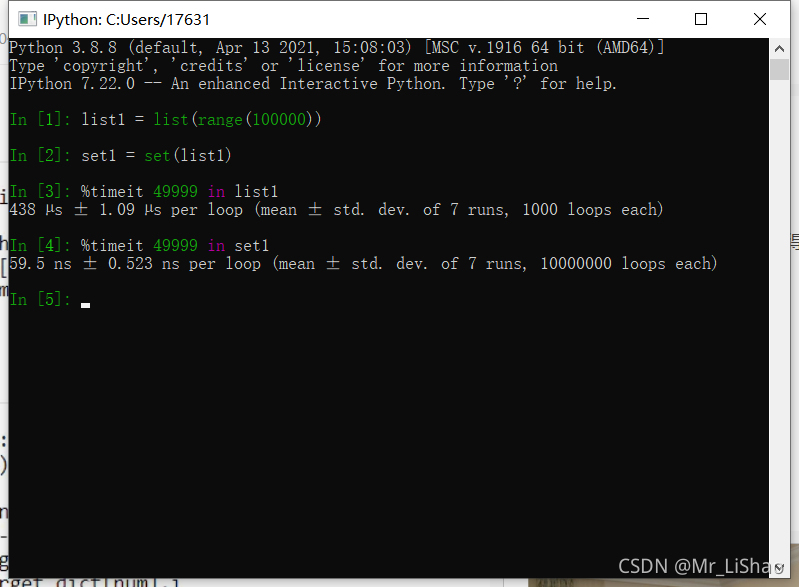
从上图可以看到,同样情况下,在set中查找大概60纳秒,在list中查找大概440微秒=440*1000纳秒=440000纳秒。所用时间大概是set的6000倍。
总结原因:
- list是顺序存储的,在查找的时候遍历整个数组,所以时间复杂度是O(n)
- set在底层是被设计成没有值的字典型,即只有key没有value。而字典dict类型在python中的实现是基于hash map哈希表的,有一个映射关系,所以在查找时候,通过哈希函数f(x)就能轻易地找到相应的值,所以时间复杂度是O(1)。在Python中,我们平时定义的对象或者它内置的对象很多都是基于dict来建立的。
- 但是dict占的内存相对较大,另外由于是使用哈希表,所以内存空间的使用不是连续的,所以当dict中剩余的内存空间小于申请的空间的1/3时,就触发扩容机制,在另一块内存空间中申请一块更大的内存,将当前的数据挪到申请的新内存上。在挪之前,dict中数据是按照输入时的顺序存放的,即有序的。但是在挪了之后,由于空间变大,所以相应的hash函数也要相应变大,数据存放位置需要重新hash,所以扩容之后,dict中的顺序可能改变。
- 另外,当存到dict中的数据通过hash都指向一块内存的时候,即发生哈希冲突问题,在通过其它方法解决之后,再在搜索的过程时,对于一个hash值的那些数据,只能顺序搜索,所以若是n个数据都是一个hash值,那么它的查找效率就是O(n).
- 由于底层使用hash实现,所以对于dict的键key以及set中的数据,都需要是不可变对象,即:int、float、str、tuple等。另外:set相当于是可变对象(底层是dict),所以不能作为dict的键或者存储在set中。