一、树集结构
1.1二叉查找树
二叉查找树(BST)具备什么特性呢?
1.左子树上所有结点的值均小于或等于它的根结点的值。
2.右子树上所有结点的值均大于或等于它的根结点的值。
3.左、右子树也分别为二叉排序树。
查找效率:
二叉查找树查找的最大次数为二叉查找树的最大高度
缺点:
可能造成线性结构
二叉查找树的相关原理可参考:
漫画算法:什么是红黑树?https://blog.csdn.net/p5deyt322jacs/article/details/78433942
1.2 红黑树
红黑树也是一个二叉查找树,它对二叉查找树的高度问题作了一定的优化。
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
红黑树最重要的作用就是维护二叉查找树(BST)宽度,保持高效平衡红黑树的特性
二、Java红黑树数据结构
2.1 TreeMap
数据结构为红黑树。
TreeMap特性
尽管如此,HashMap与LinkedHashMap还是有自己的局限性----它们不具备统计性能,或者说它们的统计性能时间复杂度并不是很好才更准确,所有的统计必须遍历所有Entry,因此时间复杂度为O(N)。比如Map的Key有1、2、3、4、5、6、7,我现在要统计:
1.所有Key比3大的键值对有哪些
2.Key最小的和Key最大的是哪两个
就类似这些操作,HashMap和LinkedHashMap做得比较差,此时我们可以使用TreeMap。TreeMap的Key按照自然顺序进行排序或者根据创建映射时提供的Comparator接口进行排序。
TreeMap为增、删、改、查这些操作提供了log(N)的时间开销,从存储角度而言,这比HashMap与LinkedHashMap的O(1)时间复杂度要差些;但是在统计性能上,TreeMap同样可以保证log(N)的时间开销,这又比HashMap与LinkedHashMap的O(N)时间复杂度好不少。
因此总结而言:如果只需要存储功能,使用HashMap与LinkedHashMap是一种更好的选择;如果还需要保证统计性能或者需要对Key按照一定规则进行排序,那么使用TreeMap是一种更好的选择。
2.2 TreeSet
TreeSet的数据结构就是基于TreeMap,故它的实现原理和TreeMap相似
三、Java8 HashMap
3.1 数据结构
JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。时间复杂度为 O(logN)。同样,后续如果由于删除或者其他原因调整了大小,当红黑树的节点小于或等于 6 个以后,又会恢复为链表形态。
其数据结构如下
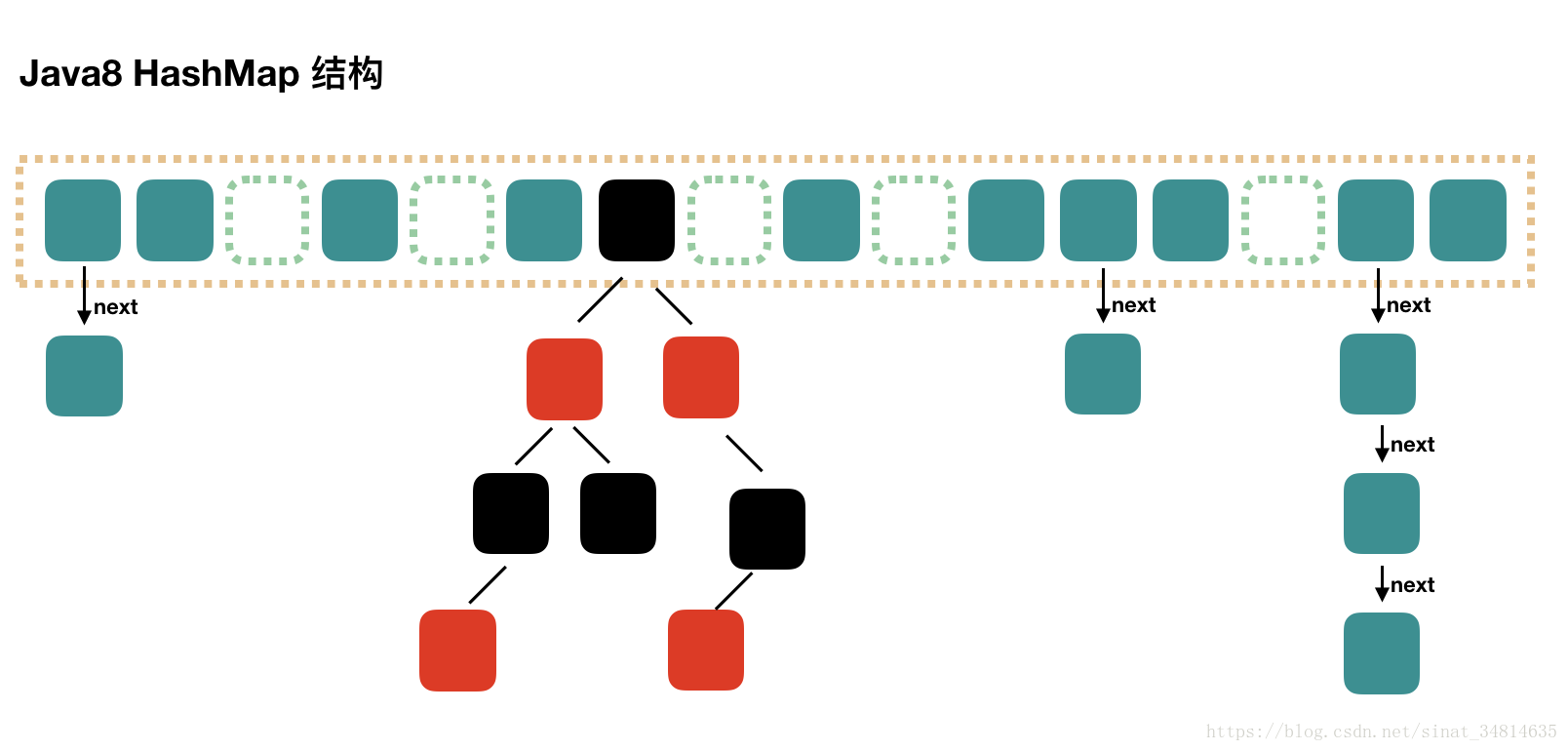
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点。
Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
3.2 底层原理
3.2.1 put原理
下面简单说下添加键值对put(key,value)的过程:
1,判断键值对数组tab[]是否为空或为null,否则以默认大小resize();
2,根据键值key计算hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点添加,否则转入3
3,判断当前数组中处理hash冲突的方式为链表还是红黑树(check第一个节点类型即可),分别处理
3.2.2 get原理
相对于 put 来说,get 真的太简单了。
1.计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
2.判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
3.判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
4.遍历链表,直到找到相等的key
思考
1.HashMap的时间复杂度是多少?
1.查找
如果不存在hash冲突,则时间复杂度为O(1)。如果存在冲突,且数组上的结构为链表,则时间复杂度为O(n),n为链表的长度。如果数组上的结构为红黑树则为o(logN)。
2.插入
如果不存在hash冲突,则时间复杂度为O(1)。如果存在冲突,且数组上的结构为链表,由于采用的是头插法,但要检查是否有重复key值,所以时间复杂度为O(n),如果数组上的结构为红黑树则为o(logN)。其中N为当前红黑树的元素个数。
2.HashMap为什么不直接用红黑树?
那为什么不一开始就用红黑树,反而要经历一个转换的过程呢?其实在 JDK 的源码注释中已经对这个问题作了解释:
Because TreeNodes are about twice the size of regular nodes,
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due
removal or resizing) they are converted back to plain bins.
通过查看源码可以发现,默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想.即红黑树占用的空间更大一些。
最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。
3.Hashmap链表长度为8时转换成红黑树,你知道为什么是8吗?
在源码中也对选择 8 这个数字做了说明,原文如下:
In usages with well-distributed user hashCodes, tree bins
are rarely used. Ideally, under random hashCodes, the
frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because
of resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
上面这段话的意思是,如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低, 而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
参考:
面试官:Hashmap链表长度为8时转换成红黑树,你知道为什么是8吗
https://blog.csdn.net/kyle_wu_/article/details/113578055
4.Hashmap负载因子为何是0.75?
我们在考虑HashMap的时候,首先要想到的是HashMap只是一个数据结构,既然是数据结构最主要的就是节省时间和空间。负载因子的作用肯定也是节省时间和空间。因为是什么呢?首先我们考虑下两种极端情况。
1、负载因子是1.0
当负载因子是1.0的时候,也就意味着,只有当数组全部填充了,才会发生扩容。这就带来了很大的问题,因为Hash冲突时避免不了的。当负载因子是1.0的时候,意味着会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
2、负载因子是0.5
负载因子是0.5的时候,这也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素少了,Hash冲突也会减少,那么底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加。
但是,兄弟们,这时候空间利用率就会大大的降低,原本存储1M的数据,现在就意味着需要2M的空间。
一句话总结就是负载因子太小,虽然时间效率提升了,但是空间利用率降低了。
3、负载因子0.75
经过前面的分析,基本上为什么是0.75的答案也就出来了,这是时间和空间的权衡。答案就在源码上,我们可以看看:
/* <p>As a general rule, the default load factor (.75) offers a good
* tradeoff between time and space costs. Higher values decrease the
* space overhead but increase the lookup cost (reflected in most of
* the operations of the <tt>HashMap</tt> class, including
* <tt>get</tt> and <tt>put</tt>). The expected number of entries in
* the map and its load factor should be taken into account when
* setting its initial capacity, so as to minimize the number of
* rehash operations. If the initial capacity is greater than the
* maximum number of entries divided by the load factor, no rehash
* operations will ever occur.*/
大致意思就是说负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
参考:HashMap的负载因子初始值为什么是0.75?
https://blog.csdn.net/damokelisijian866/article/details/104763748
5.Hashmap 1.7和1.8的扩容机制?
JDK7 中的扩容机制
1.空参数的构造函数: 以默认容量、 默认负载因子、 默认阈值初始化数组。 内部数组是空数组。
2.有参构造函数: 根据参数确定容量、 负载因子、 阈值等。
3. 第一次 put 时会初始化数组, 其容量变为不小于指定容量的 2 的幂数, 然后根据负载因子确定阈值。
4.如果不是第一次扩容, 则 新容量=旧容量 x 2 , 新阈值=新容量 x 负载因子 。
JDK8 的扩容机制
1.空参数的构造函数: 实例化的 HashMap 默认内部数组是 null, 即没有实例化。 第一次调用 put 方法时, 则会开始第一次初始化扩容, 长度为 16。
2.有参构造函数: 用于指定容量。 会根据指定的正整数找到不小于指定容量的 2 的幂数,将这个数设置赋值给阈值( threshold) 。 第一次调用 put 方法时, 会将阈值赋值给容量,然后让 阈值 = 容量 x 负载因子。
3.如果不是第一次扩容, 则容量变为原来的 2 倍, 阈值也变为原来的 2 倍。 ( 容量和阈值都变为原来的 2 倍时, 负载因子还是不变) 。
此外还有几个细节需要注意:
- 首次 put 时, 先会触发扩容( 算是初始化) , 然后存入数据, 然后判断是否需要扩容;
- 不是首次 put, 则不再初始化, 直接存入数据, 然后判断是否需要扩容;
四、Java8 ConcurrentHashMap
4.1 数据结构
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap。
虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
4.2 put原理
1.如果没有初始化就先调用initTable()方法来进行初始化过程
2.如果没有hash冲突就直接CAS插入
3.如果还在进行扩容操作就先进行扩容。
4.如果存在hash冲突,就加锁(使用synchronized)来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入。
5.最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环
6.如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
可见锁的粒度为每个node数组。
4.3 get原理
ConcurrentHashMap的get操作的流程很简单,也很清晰,可以分为三个步骤来描述
1.计算hash值,定位到该table索引位置,如果是首节点符合就返回
2.如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
3.以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考:
4.4 对比
1.JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,一个Segment下包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)。
同时,JDK7中,HashMap在多线程并发put的情况下可能会形成环形链表,ConcurrentHashMap通过这个锁的方式,使同一时间只有有一个线程对某一table下的链表执行put,解决了并发问题。
2.JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,同时也减少了对应的存储空间。
因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了。
3.JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
思考
1.为什么ConcurrentHashMap的读操作不需要加锁?
get操作全程不需要加锁是因为Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
注意:这和数组用volatile修饰没有关系。数组用volatile修饰主要是保证在数组扩容的时候保证可见性。举个栗子,volatile int array[10]是指array的地址是volatile的而不是数组元素的值是volatile的.
@see 为什么ConcurrentHashMap的读操作不需要加锁? https://www.cnblogs.com/keeya/p/9632958.html
2.ConcurrentHashMap 1.8为何放弃分段锁?
1.并发角度:降低了锁粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)。即1.7版本不同的Segment可以并发读写,而1.8只要是不同的HashEntry就可以并发读写
2.性能角度:取消了Segment,就不用进行二次hash了,只需hash一次即可,提升了读写性能。
3.空间角度:取消了Segment,减少了对应的存储空间。
3.JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock
1.因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
2.JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然.
3.减少内存开销。假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承AQS来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
4.ConcurrentHashMap的迭代器是强一致性的迭代器还是弱一致性的迭代器?
在遍历过程中,如果已经遍历的数组上的内容变化了,迭代器不会抛出ConcurrentModificationException异常。如果未遍历的数组上的内容发生了变化,则有可能反映到迭代过程中。
这就是ConcurrentHashMap迭代器弱一致的表现。
ConcurrentHashMap的弱一致性主要是为了提升效率,是一致性与效率之间的一种权衡。要成为强一致性,就得到处使用锁,甚至是全局锁,这就与Hashtable和同步的HashMap一样了。
@see 为什么ConcurrentHashMap是弱一致的https://segmentfault.com/a/1190000000377057
参考资料
1.Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析http://www.importnew.com/28263.html
2.Java中HashMap底层实现原理(JDK1.8)源码分析 https://www.cnblogs.com/little-fly/p/7344285.html
3.漫画算法:什么是红黑树?https://blog.csdn.net/p5deyt322jacs/article/details/78433942
4.图解集合7:红黑树概念、红黑树的插入及旋转操作详细解读https://www.cnblogs.com/xrq730/p/6867924.html
5.图解集合8:红黑树的移除节点操作https://www.cnblogs.com/xrq730/p/6882018.html
6.深入并发包 ConcurrentHashMap http://www.importnew.com/26049.html