github:https://github.com/facebookresearch/fastText
pypi:https://pypi.org/project/fasttext/
简介
fastText是一种Facebook AI Research在16年开源的一个文本分类器。 其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。
fastText专注于文本分类,在许多标准问题上的分类效果非常好。
模型架构
fastText的模型架构和 word2vec 中的 CBOW 模型的结构很相似。CBOW 模型是利用上下文来预测中间词,而fastText 是利用上下文来预测文本的类别。而且从本质上来说,word2vec是属于无监督学习,fastText 是有监督学习。但两者都是三层的网络(输入层、单层隐藏层、输出层),具体的模型结构如下:
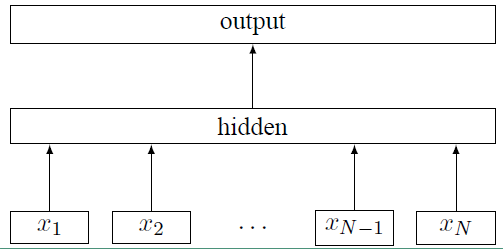
上面图中 xi 表示的是文本中第 i 个词的特征向量,该模型的负对数似然函数如下:
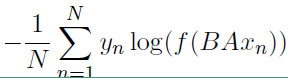
上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。式子中的 B 是函数 f 的权重系数。
分层 softmax(Hierarchical softmax)
首先来看看softmax 函数的表达式如下:
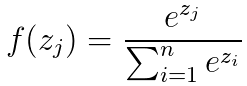
然而在类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为 O(kh) ,其中 k 是类别的数量,h 是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为 O(h;log2(k)) (二叉树的时间复杂度是 O(log2(k)) )。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
N-grams 特征
传统的词袋模型不能保存上下文的语义,例如“我爱你”和“你爱我”在传统的词袋模型中表达的意思是一样的,N-grams 模型能很好的保存上下文的语义,能将上面两个短语给区分开。而且在这里使用了 hash trick 进行特征向量降维。hash trick 的降维思想是讲原始特征空间通过 hash 函数映射到低维空间。
使用
pip install fasttext==0.9.1
# -*- coding:utf-8 -*-
"""
@author: zhouxinfei
@license: Apache Licence
@file: *.py
@time: 2021/07/14
@site:
@software: PyCharm2020.1
"""
import time
import os,sys,random
import csv
import jieba
import fasttext
csv.field_size_limit(int(sys.maxsize/100_0000_0000))
file_path = r'./sample/category_sample.csv'
file_path2 =file_path.replace('.csv','.txt')
# 生成样本
def sample_deal():
out = open(file_path2,'w',encoding='utf-8',newline='')
with open(file_path, encoding='utf-8',newline='') as f:
reader = csv.reader(f)
for row in reader:
if len(row)<2:
print(row)
continue
seglist = jieba.lcut(','.join(row[1:]))
line="__label__" + row[0] + ' ' + ' '.join(seglist) + '\n'
out.write(line)
def train():
# 有监督的学习,训练分类器
classifier = fasttext.train_supervised(input=file_path2,label_prefix='__label__',
dim=256,epoch=2000,lr=0.1,wordNgrams=3,loss='softmax', verbose=2)
classifier.save_model(r'./train_model/classifier.model')
# 单一测试
def one_test():
classifier = fasttext.load_model(r'./model/category_classifier_sec.model')
name='好客便利店'
seglist=jieba.lcut(name)
text=' '.join(seglist)
labels= classifier.predict(text=text, k=3)
# labels= classifier.predict([' '.join(seglist)], k=3)
print(labels)
print(labels[0][0],labels[1][0])
# 整体测试
def all_test():
classifier = fasttext.load_model(r'./model/category_classifier_sec.model')
# path='./sample/fasttext_new.txt'
path='./sample/category_sample.txt'
result = classifier.test(path=path)
print('测试集上数据量', result[0])
print('测试集上准确率', result[1])
print('测试集上召回率', result[2])
with open(path, encoding='utf-8') as fp:
for line in fp.readlines():
line = line.strip()
if line == '':
continue
labels = classifier.predict(line, k=1)
print(line, labels[0][0],labels[1][0])
if __name__ == '__main__':
# sample_deal()
train()
# one_test()
# all_test()
在训练fastText的时候有两点需要特别注意,一个是wordNgrams,一个是loss,这两个是fastText的精髓所在,之后会提到。
在使用fastText进行文本训练的时候需要提前分词,这里的wordNgrams是根据分词的结果来组织架构的;
事实上在训练文本分类的时候有个副产物就是word2vec,fastText在实现文本分类的时候其实和cbow非常类似,就是把word2vec求和之后过了一个fc进行的分类。
fastText 运行速度快的原因
1)多线程训练:fastText在训练的时候是采用的多线程进行训练的。每个训练线程在更新参数时并没有加锁,这会给参数更新带来一些噪音,但是不会影响最终的结果。无论是 google 的 word2vec 实现,还是 fastText 库,都没有加锁。线程的默认是12个,可以手动的进行设置。
2)分层softmax:对于类别过多的类目,fastText并不是使用的原生的softmax过交叉熵,而是使用的分层softmax,这样会大大提高模型的训练和预测的速度。
fasttext参数:
The following arguments are optional:
-lr learning rate [0.05]
-lrUpdateRate change the rate of updates for the learning rate [100]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-minCount minimal number of word occurences [1]
-neg number of negatives sampled [5]
-wordNgrams max length of word ngram [1]
-loss loss function {ns, hs, softmax} [ns]
-bucket number of buckets [2000000]
-minn min length of char ngram [3]
-maxn max length of char ngram [6]
-thread number of threads [12]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
-lr:学习速率[0.1]
-lrUpdateRate:更改学习率的更新速率[100]
-dim :字向量大小[100]
-ws:上下文窗口的大小[5]
-epoch:历元数[5]
-neg:抽样数量[5]
-loss:损失函数 {ns,hs,softmax} [ns]
-thread:线程数[12]
-pretrainedVectors:用于监督学习的预培训字向量
-saveOutput:输出参数是否应该保存[0]
方括号[]中的值表示传递的参数的默认值
参考:https://www.cnblogs.com/hyserendipity/p/11698606.html
https://www.cnblogs.com/jiangxinyang/p/9669294.html
https://blog.csdn.net/john_bh/article/details/79268850
https://www.jianshu.com/p/e828f02e41c8
http://www.atyun.com/3590.html