关注公众号,发现CV技术之美
▊ 写在前面
视觉和语言预训练(VLP)提高了各种联合视觉和语言下游任务的表现。然而,当前的VLP方法严重依赖于图像特征提取的过程,其中大部分涉及区域监督(例如,目标检测)和卷积结构(例如,ResNet)。他们存在以下两方面的问题:
1)效率/速度 ,提取输入特征比多模态交互拥有更多的计算量;
2)表现力 ,视觉embedder的能力和预定义的视觉词汇决定了整个模型性能的上限。
在这篇文章中,作者提出了一个更小的视觉与语言Transformer(ViLT),视觉输入的处理被极大地简化为了无卷积的方式。因此,ViLT可以比以前的VLP模型快几十倍,但依旧可以获得相似甚至更好的性能。
▊ 1. 论文和代码地址

ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
论文地址:https://arxiv.org/abs/2102.03334
代码地址:https://github.com/dandelin/vilt
▊ 2. Motivation
先预训练再微调(pre-train-and-fine-tune) 的方案已经扩展到视觉和语言的联合领域,从而产生了视觉语言预训练(Vision-and-Language Pre-training (VLP)) 模型。这些模型通过图像文本匹配(ITM) 和掩蔽语言建模(MLM) 目标进行了预训练,然后在下游的视觉语言任务上进行微调,实现更好的性能。
要将图像送入到VLP模型中,首先需要对图像进行embed,形成一个token序列。大多数VLP采用在Visual Genome数据集上预训练的目标检测器来提取视觉特征。Pixel-Bert是这一趋势的一个例外,它使用了在ImageNet分类上进行预训练的ResNet模型,用grid特征来代替region特征。
到目前为止,许多VLP研究都集中在通过增加视觉embedder的能力来提高性能。由于区域特征通常在训练时被提前缓存,从而减轻了特征提取的负担,因此在实验中往往忽略了视觉embedder的缺点。然而,这些限制在实际的应用中仍然是显而易见的,因为所有的图片都必须经历一个缓慢的视觉特征提取过程。
为此,作者将重点转移到构建轻量级和快速的视觉embedder上。ViT等研究表明,使用patch的简单线性投影足以有效地进行视觉信息的表示。
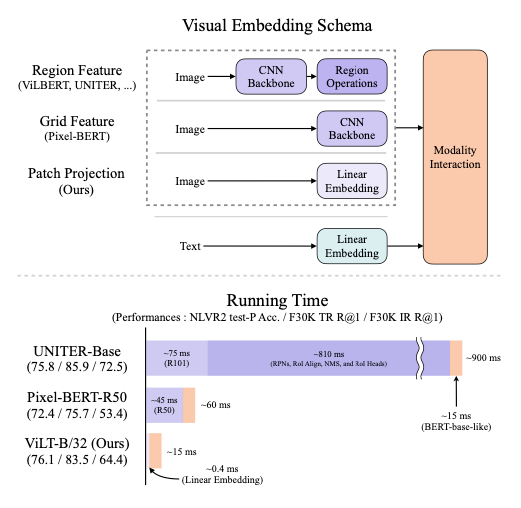
本文提出了视觉与语言Transformer(ViLT),它以一种统一的方式处理两个模态。它与以前的VLP模型的主要不同之处在于它对像素级输入只进行了浅层的、无卷积的embed,因此处理速度非常快。
去掉用于视觉输入的深度embedder,可显著减少模型大小和运行时间。如上图所示,本文的模型比具有区域特征的VLP模型快几十倍,比具有grid特征的VLP模型快至少四倍,并且在视觉和语言下游任务上表现出类似甚至更好的性能。
视觉和语言模型的分类
作者基于两点提出了视觉和语言模型的分类:
1)两个模态在预处理 参数或计算方面的水平是否相等;
2)两个模态是否在深层网络中交互 作用。
基于这两个点,目前的网络可以分为四类:
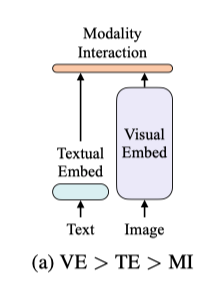
如上图所示,视觉语义嵌入(VSE)模型,如VSE++、SCAN,对图像和文本使用单独的嵌入器,但是前者的设计有更多的参数量。然后,它们用简单的点积或比较浅的注意力层来表示两个模态嵌入特征的相似性。

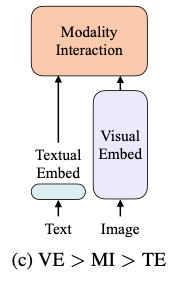
第二类模型,如CLIP,如上图所示,它为每种模态使用分开且复杂的Transformer嵌入器,但是交互的模块非常简单。尽管CLIP在图像-文本检索任务的zero-shot性能非常不错,但在其他视觉和语言下游任务中,并没有这么惊人的表现。
因此,作者认为高性能嵌入器的简单输出融合可能不足以学习复杂的视觉和语言任务,因此交互模块的精心设计是非常重要的。
目前的VLP模型大多采用上图中的结构,使用深层Transformer对图像和文本特性的交互进行建模。除了交互模块之外,图像特征的提取和嵌入仍然涉及卷积网络,这是计算量的主要部分。

本文提出的ViLT模型如上图所示,视觉和文本的嵌入层都是轻量级,该结构大部分的计算都用在模态交互上面。
▊ 3. 方法
3.1. Model Overview
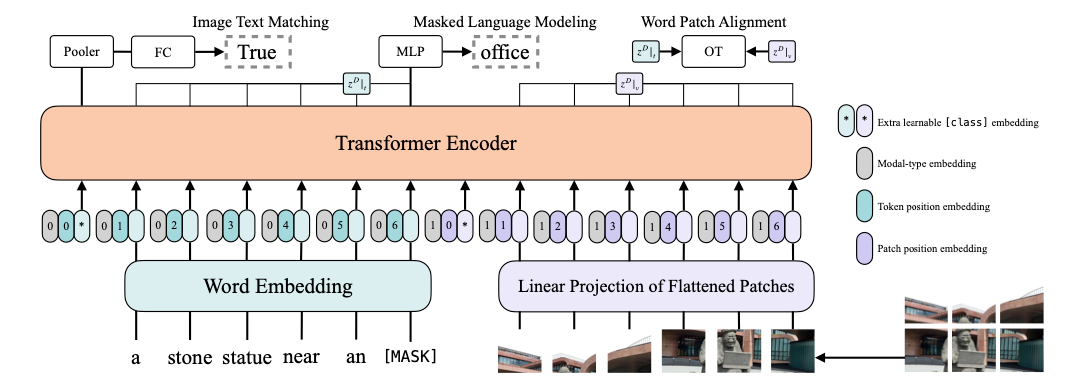
如上图所示,ViLT具有简洁的结构,最小的视觉嵌入pipeline,并遵循single-stream的方法。作者采用了预训练的ViT参数来对模型进行初始化,这种初始化利用了交互层的能力来处理视觉特征,同时不需要单独的深度视觉嵌入器。
ViT由多头自注意力(MSA)层和MLP层的堆叠块组成。输入文本基于嵌入矩阵和位置嵌入矩阵,得到。输入图像被切片成多个小patch,并将调整为,其中,是patch分辨率,。然后通过线性投影矩阵和位置嵌入矩阵,计算得到
中。
将文本和图像嵌入与其对应的模态类型嵌入向量相加,然后将其concat成组合序列。上下文向量通过D层的Transformer迭代更新,得到最后的上下文序列。是整个多模态输入的集合表示,它是通过线性投影和序列的正切函数来获得的,表示如下:
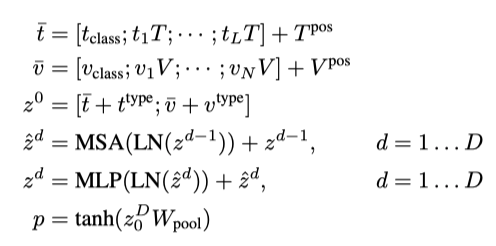
3.2. Pre-training Objectives
作者用两个常用的目标任务来训练VLP模型:图像文本匹配(ITM)和掩蔽语言建模(MLM)。
Image Text Matching
作者用0.5的概率将不同图像随机替换对齐的图像。一个单线性层的ITM head将汇集的输出特征p投影到二进制类上的logits上,然后计算负对数似然损失作为ITM的损失函数。此外,作者还设计了单词块对齐(WPA),来计算的两个子集之间的对齐分数:(文本子集)和(视觉子集)。
Masked Language Modeling
该任务的目标是根据上下文向量来预测被mask掉的单词,在本文中,作者将mask的概率设为0.15。作者使用一个两层的MLM head,输入并输出mask词汇的logit。然后,将MLM损失设为mask token的负对数似然损失。
3.3. Whole Word Masking
全词掩蔽(Whole Word Masking)是一种mask技术,它mask了组成整个单词的所有连续子字token。该算法应用于原版和中文版的BERT时,对下游任务都是有效的。为了充分利用来自另一种模态的信息,全词掩蔽对视觉语言处理尤为重要。
例如,单词“giraffe”使用预训练的tokenizer被tokenize成三个token [“gi”,“##raf”,“##fe”]。如果不是所有的token都被mask,即[“gi”,“[ask]”,“##fe”],则该模型可以仅依靠附近的两个语言token [“gi”,“##fe”],来预测被屏蔽的“##raf”,而不使用来自图像的信息。在预训练期间,作者用0.15的概率mask整个单词。
3.4. Image Augmentation
图像增强提高了视觉模型的泛化能力。建立在VIT基础上的DeIT试验了各种增强技术,并发现它们对VIT训练是有益的。然而,在VLP模型中,图像增强的效果还没有被探索过。
因此,基于区域特征的VLP模型很难使用通用的图像增强方法。此外,Pixel-Bert虽然可以进行数据增强,但也没有研究它的影响。因此,在本文中,作者还研究了微调过程中使用数据增强对结果的影响。
▊ 4.实验
4.1. Overview

在预训练过程中,作者采用了四个数据集,数据集统计如上表所示。
4.2. Classification Tasks
Visual Question Answering
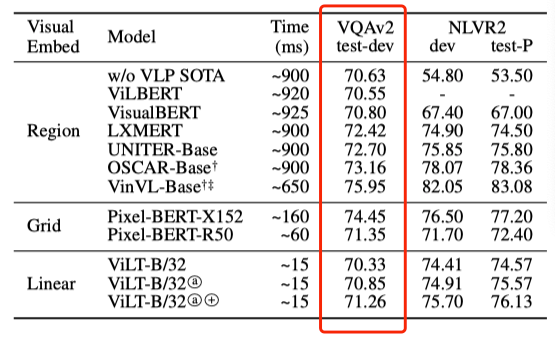
上表展示了ViLT在VQA任务上的结果,可以看出相比于其他方法,ViLT在VQA任务上的性能比较一般。
Natural Language for Visual Reasoning
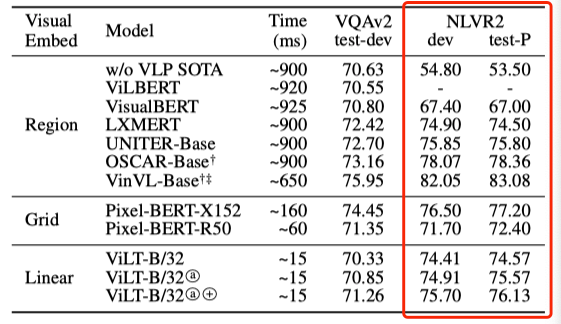
从上表可以看出在NLVR2任务上,ViLT取得了和很多预训练模型相似的性能,但是速度快了很多。
4.3. Retrieval Tasks

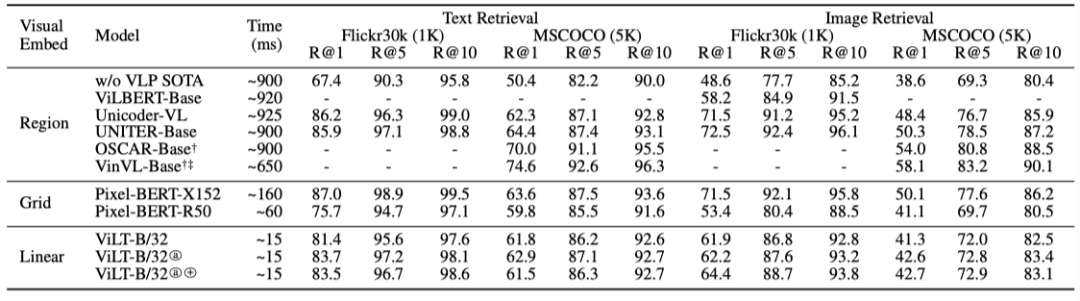
上表展示了检索任务上的性能,ViLT也可以达到比较不错的性能。
4.4. Ablation Study
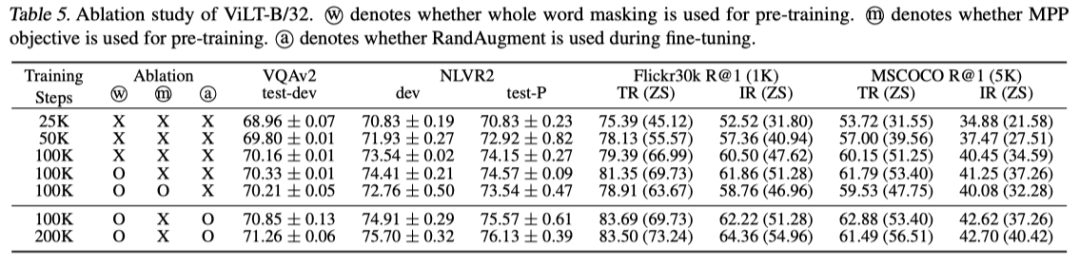
上表展示了不同模块的消融实验结果,可以看出Whole Word Masking和数据增强的有效性。
4.5. Complexity Analysis of VLP Models
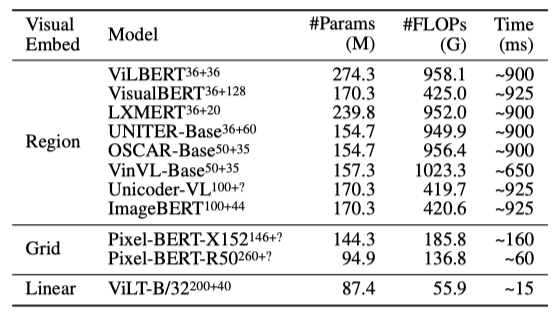
上表展示了不同模型参数量、计算量和推理时间的统计。可以看出,本文的方法具有绝对的优势。
4.6. Visualization

上图展示了ViLT跨模态对齐的可视化结果。
▊ 5. 总结
在本文中,作者提出了一种简单的VLP结构——视觉和语言Transformer(ViLT)。ViLT可以与大量配备卷积视觉嵌入网络(例如,Faster R-CNN和ResNet)的模型达到相似的性能。在本文中,作者验证了交互模块的重要性,也希望将来的工作能够基于交互模块进行进一步发展,而不是找到一个更好的特征提取器。
本文的工作可以说是极大的降低了多模态预训练模型的复杂度,在embed的时候采用了最简单的结构,并且也达到了不错的性能,最重要的是能够让模型的速度大幅度提升。不过,作者在进行参数初始化的时候还是用到了ViT的预训练参数,这也导致了对于模型结构修改的空间就比较小。因为如果模型改变太大,就不能用预训练好的参数初始化,从而性能也会降低。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「Transformer」交流群
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)