时间序列算法
time series data mining 主要包括decompose(分析数据的各个成分,例如趋势,周期性),prediction(预测未来的值),classification(对有序数据序列的feature提取与分类),clustering(相似数列聚类)等。
时间序列的预测
常用的思路:
1、计算平均值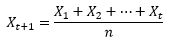
2、exponential smoothing指数衰减
不同的时间点,赋予不同的权重,越接近权重越高
3、snaive:假设已知数据的周期,上一个周期对应的值作为下一个周期的预测值
4、drift:飘移,即用最后一个点的值加上数据的平均趋势
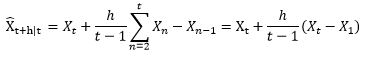
5、Holt-Winters: 三阶指数平滑
Holt-Winters的思想是把数据分解成三个成分:平均水平(level),趋势(trend),周期性(seasonality)。R里面一个简单的函数stl就可以把原始数据进行分解:
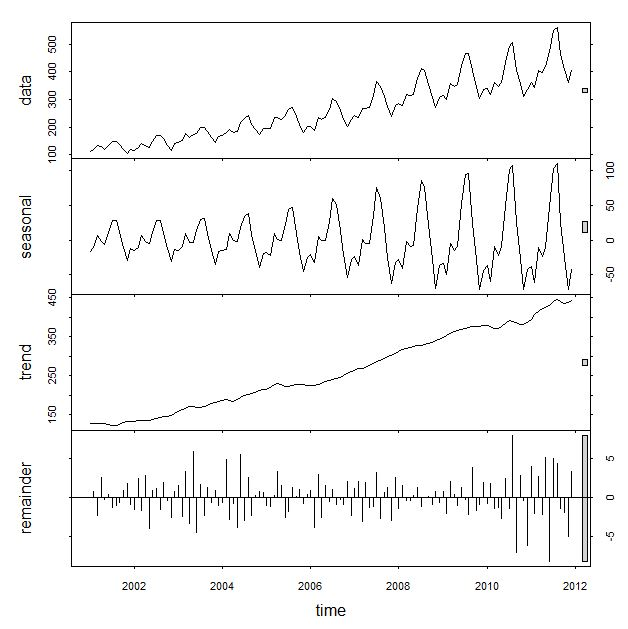
一阶Holt—Winters假设数据是stationary的(静态分布),即是普通的指数平滑。
二阶算法假设数据有一个趋势,这个趋势可以是加性的(additive,线性趋势),也可以是乘性的(multiplicative,非线性趋势),只是公式里面一个小小的不同而已。
三阶算法在二阶的假设基础上,多了一个周期性的成分。同样这个周期性成分可以是additive和multiplicative的。 举个例子,如果每个二月的人数都比往年增加1000人,这就是additive;如果每个二月的人数都比往年增加120%,那么就是multiplicative。
性能衡量采用的是RMSE。 当然也可以采用别的metrics:
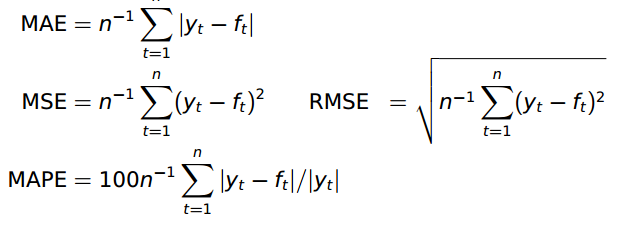
6、ARIMA: AutoRegressive Integrated Moving Average,ARIMA是两个算法的结合:AR和MA。在ARMA模型中,AR代表自回归,MA代表移动平均。其公式如下:
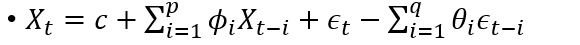
- 是白噪声,均值为0, C是常数。 ARIMA的前半部分就是Autoregressive:
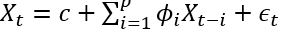 , 后半部分是moving average:
, 后半部分是moving average: 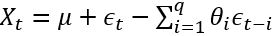 。 AR实际上就是一个无限脉冲响应滤波器(infinite impulse resopnse), MA是一个有限脉冲响应(finite impulse resopnse),输入是白噪声。
。 AR实际上就是一个无限脉冲响应滤波器(infinite impulse resopnse), MA是一个有限脉冲响应(finite impulse resopnse),输入是白噪声。
ARIMA里面的I指Integrated(差分)。 ARIMA(p,d,q)就表示p阶AR,d次差分,q阶MA。
为什么要进行差分呢? ARIMA的前提是数据是stationary的,也就是说统计特性(mean,variance,correlation等)不会随着时间窗口的不同而变化。用数学表示就是联合分布相同。
当然很多时候并不符合这个要求,例如这里的airline passenger数据。有很多方式对原始数据进行变换可以使之stationary:
(1) 差分,即Integrated。 例如一阶差分是把原数列每一项减去前一项的值。二阶差分是一阶差分基础上再来一次差分。这是最推荐的做法。
(2)先用某种函数大致拟合原始数据,再用ARIMA处理剩余量。例如,先用一条直线拟合airline passenger的趋势,于是原始数据就变成了每个数据点离这条直线的偏移。再用ARIMA去拟合这些偏移量。
(3)对原始数据取log或者开根号。这对variance不是常数的很有效。
如何做平稳性检验呢?一种方法是肉眼观察,根据肉眼及人的经验判断,不同的人可能会给出不同的结论,还有另一种更客观的统计学方法来辅助判断,也就是“单位根检验”。
对差分后的数据做单位根检验,参考代码如下:
print("单位根检验:\n")
print(ADF(data.diff1.dropna()))
得到:1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,p-value接近于0,ADF Test result同时小于5%、10%即说明很好地拒绝该假设,也就是差分后的序列是平稳的。
序列平稳后,还需要做白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
acorr_ljungbox(data.diff1.dropna(), lags = [i for i in range(1,12)],boxpierce=True)
结果通过P<α,拒绝原假设,说明差分后的序列是平稳的非白噪声序列,可以进行下一步建模。
模型定阶
经过平稳性检测和白噪声检测,得到平稳的时间序列后,就开始选择合适的ARIMA模型,即ARIMA模型中合适的p,q
第一步我们要先检查平稳时间序列的自相关图和偏自相关图。通过sm.graphics.tsa.plot_acf和sm.graphics.tsa.plot_pacf得到图形
这里就要用到两个很常用的量了: ACF(auto correlation function)和PACF(patial auto correlation function)。对于non-stationary的数据,ACF图不会趋向于0,或者趋向0的速度很慢。
acf(train) ——原始数据
acf(diff(train,lag=1)) ——一阶差分
acf(diff(diff(train,lag=7))) ——去除周期性的一阶差分
确保stationary之后,下面就要确定p和q的值了。定这两个值还是要看ACF和PACF:
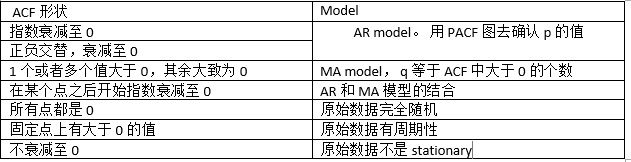
AR(p)模型,PACF会在lag=p时截尾,也就是,PACF图中的值落入宽带区域中。
MA(q)模型,ACF会在lag=q时截尾,同理,ACF图中的值落入宽带区域中。
确定好p和q之后,就可以调用R里面的arime函数了。
ARIMA更多表示为 ARIMA(p,d,q)(P,D,Q)[m] 的形式,其中m指周期(例如7表示按周),p,d,q就是前面提的内容,P,D,Q是在周期性方面对应的p,d,q含义。
R里面有两个很强大的函数: ets 和 auto.arima。 用户什么都不需要做,这两个函数会自动挑选一个最恰当的算法去分析数据。
在R中各个算法的效果如下:

模型优化

其中L是在该模型下的最大似然,n是数据数量,k是模型的变量个数。
python代码如下:
arma_mod20 = sm.tsa.ARIMA(data["xt"],(1,1,0)).fit()
arma_mod30 = sm.tsa.ARIMA(data["xt"],(0,1,1)).fit()
arma_mod40 = sm.tsa.ARIMA(data["xt"],(1,1,0)).fit()
values = [[arma_mod20.aic,arma_mod20.bic,arma_mod20.hqic],[arma_mod30.aic,arma_mod30.bic,arma_mod30.hqic],[arma_mod40.aic,arma_mod40.bic,arma_mod40.hqic]]
df = pd.DataFrame(values,index=["AR(1,1,0)","MA(0,1,1)","ARMA(1,1,0)"],columns=["AIC","BIC","hqic"])
df
构造这些统计量所遵循的统计思想是一致的,就是在考虑拟合残差的同时,依自变量个数施加“惩罚”。但要注意的是,这些准则不能说明某一个模型的精确度,也即是说,对于三个模型A,B,C,我们能够判断出B模型是最好的,但不能保证B模型能够很好地刻画数据。可以用AIC(mod1)来检验与比较,值越小越好。
参数估计
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(data["xt"], order=(0,1,1))
result = model.fit()
print(result.summary())
模型检验



P<α,拒绝原假设,认为该参数显著非零MA(2)模型拟合该序列,残差序列已实现白噪声

resid = result.resid#残差
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = qqplot(resid, line='q', ax=ax, fit=True)
qq图显示,我们看到红色的KDE线与N(0,1)平行,这是残留物正太分布的良好指标,说明残差序列是白噪声序列,模型的信息的提取充分,当让大家也可以使用前面介绍的检验白噪声的方法LB统计量来检验
模型预测
pred = result.predict('1988', '1990',dynamic=True, typ='levels')
print (pred)
plt.figure(figsize=(12, 8))
plt.xticks(rotation=45)
plt.plot(pred)
plt.plot(data.xt)
plt.show()
预测效果评价:accuracy()函数包含了很多评价指标,也可以自定义。
7、ARFIMA(p,d,q):分数积分自回归移动平均模型,时间序列长期记忆
关键步骤在于对序列进行分数阶差分,得到满足零均值ARMA过程的序列,再进行参数估计。
案例:
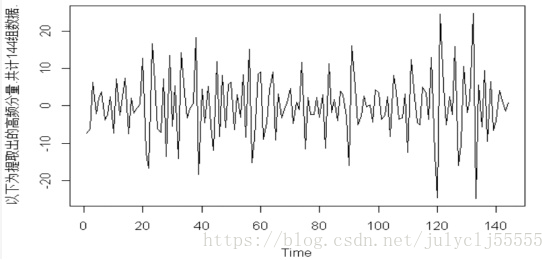
我们有一个时间序列的数据 "D1_data.txt"
1.拿到这个时间序列你先目测,上图通过目测可以认为是一个平稳的时间序列。
R步骤
a <- read.csv(“D:/D1_data.txt”) #括号中的东西取决于你的数据在电脑上存放的路径
aa <-ts(a) #命名该事件序列为aa
plot(aa) #画出时间序列aa如上图
2、通过ACF和PACF也就是自相关系数和偏自相关系数来判断是否稳定
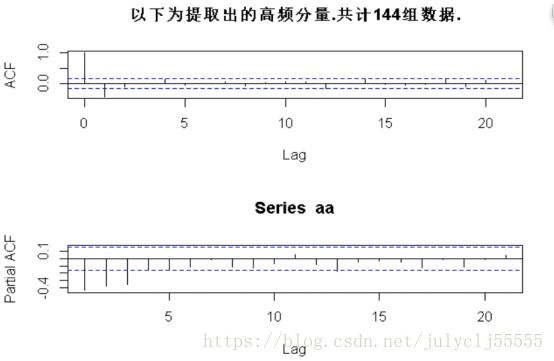
由于ACF在lag=1之后便落入置信区间,PACF在lag=3之后落入置信区间,我们认为该时间序列稳定。
R步骤
layout(1:2) #一次显示两张图
acf(aa) #显示自相关系数
pacf(aa) #显示偏自相关系数
3、模型拟合
选择ma(1)或者arma(3,1)
用arima命令来拟合,并用AIC来看哪个模型更适合,AIC数值越小越好。
R步骤
ma1 <- arima(aa,order = c(0,0,1))
arma13 <- arima(aa,order = c(3,0,1))
AIC(ma1)
AIC(arma13)
#AIC结果:
AIC(ma1) [1] 939.6636
AIC(arma13) [1] 943.8848
可以看出ma1优于arma13.
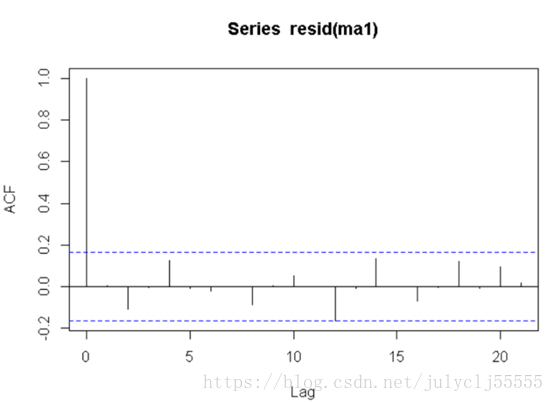
4、看拟合好的模型的残差是否为白噪声
R步骤
acf(resid(ma1)) #ma1的残差的自相关系数
注意事项:
对于这几个模型的选择绝对不是IC谁高就选谁。
正确的流程:1)根据acf和pacf的特点进行选择。比如题主的图acf缓慢下行,而pacf只有一个lag significant,这样对应的model是AR,相反如果pacf decays而acf cuts off,你就该去选MA。每个model都有对应的acf,pacf的特点,根据对应的特点细节去选model,选lag,增加sessional ar ma,验证残差等等。
2)在1)的基础上选出的可能性的model中,用IC和残差的表现来选一个最好的,这时候才用到IC。不谈1)来谈IC没有意义。其中还有很多需要注意的点建议题主自己搜索学习一下。
有trend代表一定不stationary,但这并不影响模型,在去除趋势项后,一个时间序列依然可以稳态,这个叫做trend stationary,因此即使有trend,依然可以使用ar等模型来model。
存在趋势的序列都是非平稳的,AR等一系列模型是必须建立在平稳的基础上才有意义…一般时间序列建模的流程是:去除确定性因素(趋势还有季节性),然后对剩下的随机因素进行平稳性检验,检验通过之后进行arima建模,具体的阶数你可以用acf,pacf来确定,比较方便的是R里面的auto.arima直接定阶…然后进行模型的拟合与预测…最后就是对残差进行arch效应检验,如果有arch效应,就进一步用波动率模型进行建模…总的来说就是确定性因素的分解—随机因素的均值建模—波动率建模。
疑问:
如何判断一个序列是否平稳?
1、均值 ,是与时间t 无关的常数。
2、方差 ,是与时间t 无关的常数。这个特性叫做方差齐性。
3、协方差 ,只与时期间隔k有关,与时间t 无关的常数。
如果一个序列不平稳,就要用方法使它变平稳:如消除长期趋势、差分化
检查平稳性的公式,
1、引入Rho系数:X(t) = Rho * X(t-1) + Er(t)
2、Dickey-Fuller检验是测试一个自回归模型是否存在单位根。X(t) - X(t-1) = (Rho - 1) X(t - 1) + Er(t),要测试如果Rho–1=0是否差异显著。如果零假设不成立,我们将得到一个平稳时间序列。
如何判断一个序列符合AR还是MA?
自回归AR案例:
例如,x(t)代表一个城市在某一天的果汁的销售量。在冬天,极少的供应商进果汁。突然有一天,温度上升了,果汁的需求猛增到1000.然而过了几天,气温有下降了。但是众所周知,人们在热天会喝果汁,这些人会有50%在冷天仍然喝果汁。在接下来的几天,这个比例降到了25%(50%的50%),然后几天后逐渐降到一个很小的数。
移动平均MA案例:
一个公司生成某种类型的包,这个很容易理解。作为一个竞争的市场,包的销售量从零开始增加的。所以,有一天他做了一个实验,设计并制作了不同的包,这种包并不会被随时购买。因此,假设市场上总需求是1000个这种包。在某一天,这个包的需求特别高,很快库存快要完了。这天结束了还有100个包没卖掉。我们把这个误差成为时间点误差。接下来的几天仍有几个客户购买这种包。
AR模型与MA模型的不同
AR与MA模型的主要不同在于时间序列对象在不同时间点的相关性。
MA模型用过去各个时期的随机干扰或预测误差的线性组合来表达当前预测值。当n>某一个值时,x(t)与x(t-n)的相关性总为0.
AM模型仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,步骤模型变量相对独立的假设条件约束,所构成的模型可以消除普通回退预测方法中由于自变量选择、多重共线性等造成的困难。即AM模型中x(t)与x(t-1)的相关性随着时间的推移变得越来越小。
用ACF和PACF来区分AR与MA
时间序列x(t)滞后k阶的样本自相关系数(ACF)和滞后k期的情况下样本偏自相关系数(PACF)。
AR模型的ACF和PACF:
通过计算证明可知:
- AR的ACF为拖尾序列,即无论滞后期k取多大,ACF的计算值均与其1到p阶滞后的自相关函数有关。
- AR的PACF为截尾序列,即当滞后期k>p时PACF=0的现象。
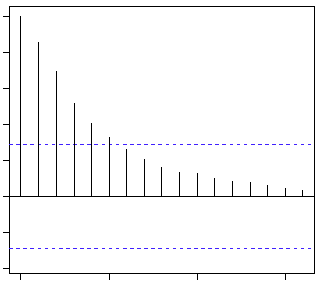
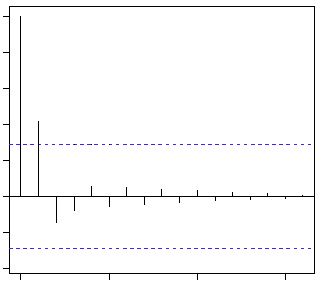
上图蓝线显示值与0具有显著的差异。很显然上面PACF图显示截尾于第二个滞后,这意味这是一个AR(2)过程。
MA模型的ACF和PACF:
- MA的ACF为截尾序列,即当滞后期k>p时PACF=0的现象。
- AR的PACF为拖尾序列,即无论滞后期k取多大,ACF的计算值均与其1到p阶滞后的自相关函数有关。
很显然,上面ACF图截尾于第二个滞后,这以为这是一个MA(2)过程
如何让时间序列变得平稳?
1 消除趋势:这里我们简单的删除时间序列中的趋势成分
2 差分:这个技术常常用来消除非平稳性。这里我们是对序列的差分的结果建立模型而不是真正的序列。
x(t) – x(t-1) = ARMA (p , q)
差分后,ARIMA对应为:p:AR d:I q:MA
3 季节性:季节性直接被纳入ARIMA模型中。
如何确定pdq的值?
1、参数p,q可以使用ACF和PACF图发现。
2、如果相关系数ACF和偏相关系数PACF逐渐减小,这表明我们需要进行时间序列平稳并引入d参数。
选择模型时,选择AIC和BIC最小的(p,d,q)组合。
进行时间序列预测的步骤