作业简介:
1、信息格式:
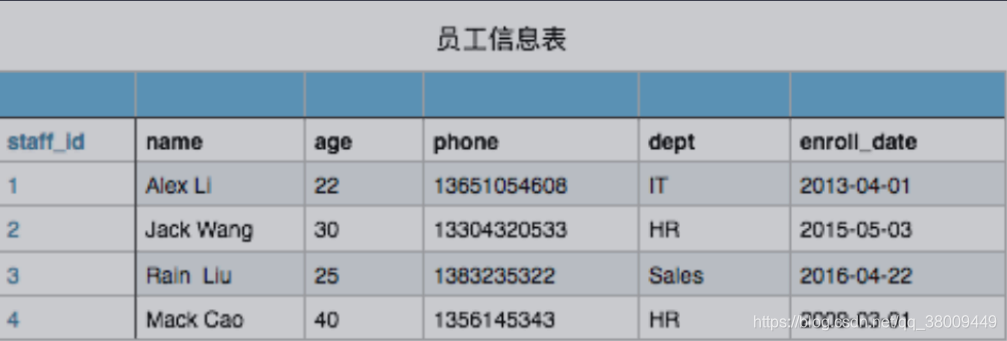
2.文本数据:
1,Alex Li,22,13651054608,IT,2013-04-01
2,Jack Wang,28,13451024608,HR,2015-01-07
3,Rain Wang,21,13451054608,IT,2017-04-01
4,Mack Qiao,44,15653354208,Sales,2016-02-01
5,Rachel Chen,23,13351024606,IT,2013-03-16
6,Eric Liu,19,18531054602,Marketing,2012-12-01
7,Chao Zhang,21,13235324334,Administration,2011-08-08
8,Kevin Chen,22,13151054603,Sales,2013-04-01
9,Shit Wen,20,13351024602,IT,2017-07-03
10,Shanshan Du,26,13698424612,Operation,2017-07-02
3.作业需求:
1 查⽂件((find)):
find name,age from staff_table where age > 22
find * from staff_table where dept = "IT"
find * from staff_table where enroll_data like "2013"
2 添加员⼯信息(⽤户的⼿机号不允许重复) 添加员⼯信息(⽤户的⼿机号不允许重复)
>>>:add staff_table Mosson,18,13678789527,IT,2018-12-11
3 删除员⼯信息(根据序号删除相应员⼯的信息) 删除员⼯信息(根据序号删除相应员⼯的信息)
>>>:del from staff_table where id = 10
需求:从staff_table中删除序号id为10的这⼀条员⼯的信息
4 修改员⼯信息(可以根据特殊条件修改员⼯信息) 修改员⼯信息(可以根据特殊条件修改员⼯信息)
>>>:update staff_table set dept=“Market” where dept = "IT"
需求:将staff_table中dept为IT的修改成dept为 Market
4.写README.md文档:
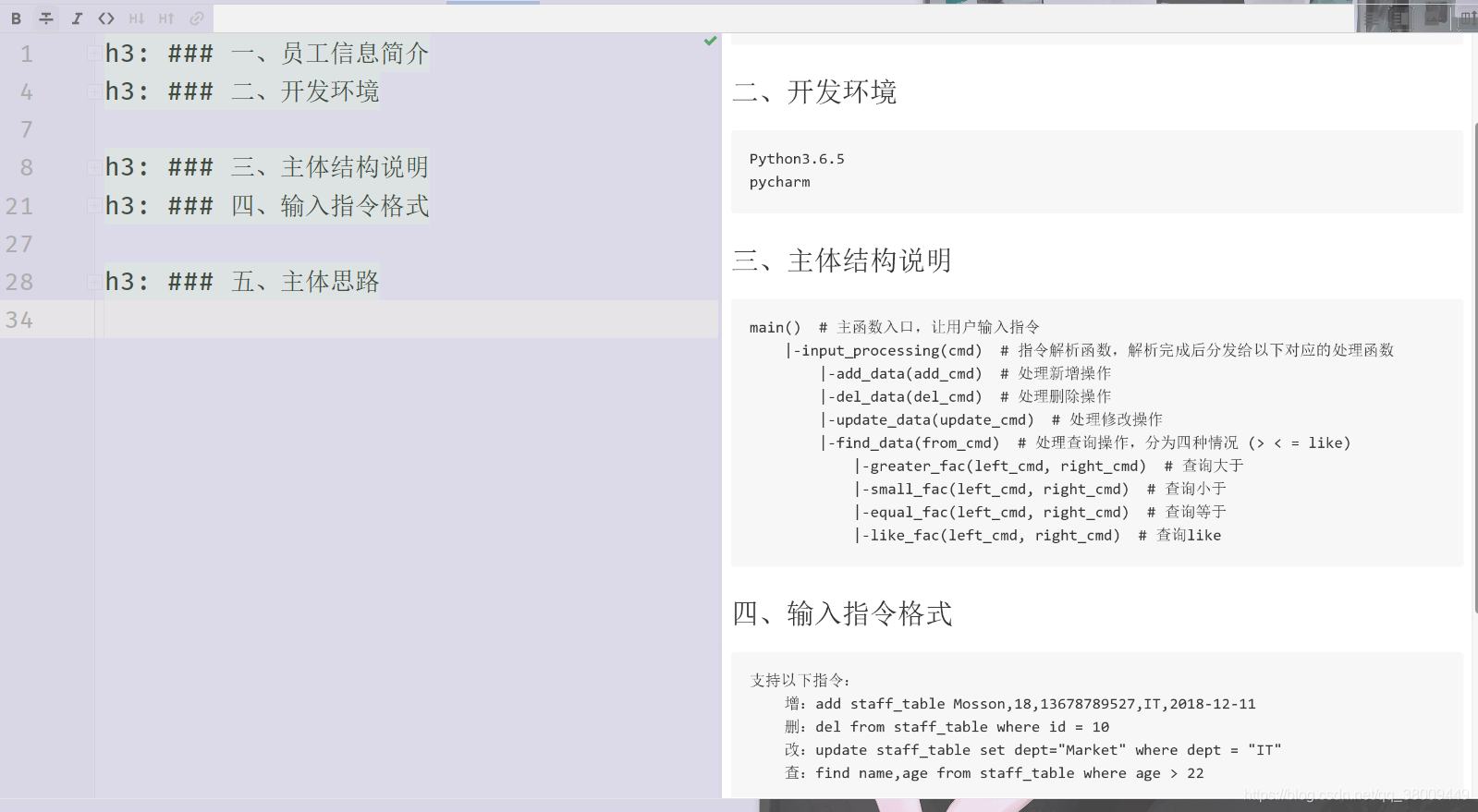
5.主体函数目录:
main() # 主函数入口,让用户输入指令
|-input_processing(cmd) # 指令解析函数,解析完成后分发给以下对应的处理函数
|-add_data(add_cmd) # 处理新增操作
|-del_data(del_cmd) # 处理删除操作
|-update_data(update_cmd) # 处理修改操作
|-find_data(from_cmd) # 处理查询操作,分为四种情况 (> < = like)
|-greater_fac(left_cmd, right_cmd) # 查询大于
|-small_fac(left_cmd, right_cmd) # 查询小于
|-equal_fac(left_cmd, right_cmd) # 查询等于
|-like_fac(left_cmd, right_cmd) # 查询like
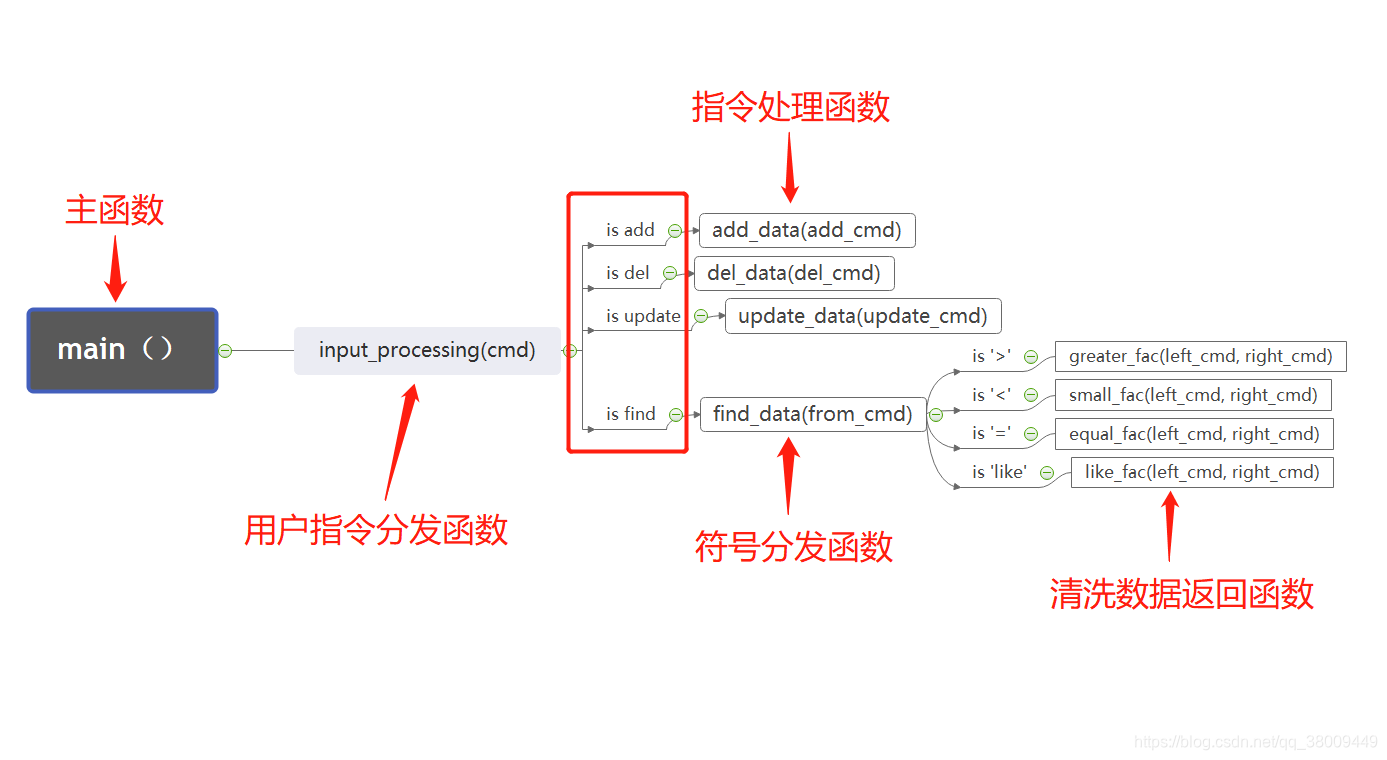
6.思维导图:
7.支持的指令:
支持以下指令:
-
增:
add staff_table Mosson,18,13678789527,IT,2018-12-11
-
删:
del from staff_table where id = 10
-
改:
update staff_table set dept="Market" where dept = "IT"
-
查:
find name,age from staff_table where age > 22
8.项目主体思路:
- 1.运行主函数mian(),让用户输入如果输入为空,continue
- 2.如果用户输入指令不为空,将指令(cmd)传入input_processing(cmd)函数,进入函数继续下一步
- 3.如果指令正确,执行对应的函数进行数据的清洗工作,否则提示指令错误
- 4.清洗完数据结束后将结果返回给用户
- 5.用户操作结束后,输入q退出程序
9.项目源码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
# Python就业班:HuangPei
# datetime:20201203
# TXT数据路径
data_file = './staff_table.txt'
# 数据头目格式
name_index = ['id', 'name', 'age', 'phone', 'dept', 'enrolled_date']
# 从TXT获取数据,并整理数据格式
def read_data(file_path):
"""
读取数据表到内存,
:param file_path:传入文件
:return:
"""
data = []
with open(file_path, mode='r', encoding='utf-8') as f:
for i in f.readlines(): # 将数据以列表的形式存到data中
data.append(dict(zip(name_index, i.strip().split(','))))
# print(dict(zip(name_index, i.strip().split(','))))
# print(list(zip(name_index, i.strip().split(','))))
return data
# 整理好的TXT数据
DATA = read_data(data_file)
# 返回大于数据
def greater_fac(left_cmd, right_cmd):
"""
返回大于的数据
:return:
"""
for i in DATA:
if left_cmd[0] == '*':
print(i['id'], i['name'], i['age'], i['phone'], i['dept'], i['enrolled_date'])
elif len(left_cmd) == 1 and left_cmd[0].isalpha():
if int(i['age']) > int(right_cmd):
print(i[left_cmd[0]])
elif len(left_cmd) == 2:
if int(i[left_cmd[1]]) > int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]])
elif len(left_cmd) == 3:
if int(i[left_cmd[1]]) > int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]])
elif len(left_cmd) == 4:
if int(i[left_cmd[1]]) > int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]], i[left_cmd[3]])
elif len(left_cmd) == 5:
if int(i[left_cmd[1]]) > int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]], i[left_cmd[3]], i[left_cmd[4]])
else:
print('请检查查询字段!!')
else:
print('结果输出完成~~')
# print("这是大于", left_cmd, right_cmd)
# 返回小于数据
def small_fac(left_cmd, right_cmd):
"""
返回小于的数据
:return:
"""
# print("这是小于", len(left_cmd), left_cmd, right_cmd)
for i in DATA:
if left_cmd[0] == '*':
print(i['id'], i['name'], i['age'], i['phone'], i['dept'], i['enrolled_date'])
elif len(left_cmd) == 1 and left_cmd[0].isalpha():
if int(i['age']) < int(right_cmd):
print(i[left_cmd[0]])
elif len(left_cmd) == 2:
if int(i[left_cmd[1]]) < int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]])
elif len(left_cmd) == 3:
if int(i[left_cmd[1]]) < int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]])
elif len(left_cmd) == 4:
if int(i[left_cmd[1]]) < int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]], i[left_cmd[3]])
elif len(left_cmd) == 5:
if int(i[left_cmd[1]]) < int(right_cmd):
print(i[left_cmd[0]], i[left_cmd[1]], i[left_cmd[2]], i[left_cmd[3]], i[left_cmd[4]])
else:
print('字段错误,请检查查询字段。')
else:
print('结果输出完成!')
# 返回等于数据
def equal_fac(left_cmd, right_cmd):
"""
返回等于的数据
:return:
"""
new_name = right_cmd.replace('"', " ").strip()
print(new_name)
for i in DATA:
if left_cmd[0] == '*' and new_name in i['dept']:
print(i['id'], i['name'], i['age'], i['phone'], i['dept'], i['enrolled_date'])
# 返回like数据
def like_fac(left_cmd, right_cmd):
"""
返回值里对应的数据
:return:
"""
# print(right_cmd)
new_name = right_cmd.replace('"', " ").strip()
for like_data in DATA:
if new_name in like_data['enrolled_date']:
print(like_data['id'], like_data['name'], like_data['age'], like_data['phone'], like_data['dept'],
like_data['enrolled_date'])
else:
print('查询结果输出完成!')
# 处理查询
def find_data(from_cmd):
"""
处理指令返回数据
:param from_cmd:
:return:
"""
msg = """
find name,age from staff_table where age > 22,
find * from staff_table where dept = "IT",
find * from staff_table where enroll_data like "2013"
"""
# 转成:['name,age', ...., 'age', '>', '22']
deal_with = from_cmd.split()[1:]
# print(deal_with)
new_cmd = ' '.join(deal_with)
symbol_list = ['>', '<', '=', 'like']
# 如果 符号在列表中 根据索引分割 指令
for symbol in symbol_list:
if symbol in new_cmd:
left, right = new_cmd.split(symbol)
# print(list(t.split()),l)
new_left = list(left.split()) # ['name', 'age']
count_name = new_left[0].split(',')
# print(i, 55555555555)
# break
# 定义一个字典,值对应一个函数,如果符号在key中,执行对应的函数
exe_fac = {
'>': greater_fac,
'<': small_fac,
'=': equal_fac,
'like': like_fac,
}
# print(exe_fac, '-----------')
# 判断符号是否在字典的key中
if symbol in exe_fac:
# print(symbol, 'zhess ')
exe_fac[symbol](count_name, right) # 调用字典里的函数
break
else:
print('语法错误!!!只支持示例指令:%s' % msg)
# 处理新增
def add_data(add_cmd):
"""
新增用户信息
:param add_cmd:
:return:
"""
msg = 'add staff_table Mosson,18,13678789527,IT,2018-12-11'
# 判断 staff_table 是否在指令中
if 'staff_table' in add_cmd:
# print(add_cmd)
read_data(data_file)
# 拆分为:['Mosson', '18', '13678789527', 'IT', '2018-12-11']
refactoring_name = add_cmd.strip().split()[2:]
new_name = ''.join(refactoring_name).split(',')
# print(new_name)
# 获取序号 进行自增
id_number = []
for i in DATA:
id_number.append(int(i['id']))
new_id = (max(id_number) + 1)
new_data = ','.join(new_name)
with open(data_file, 'a+') as f:
f.write(str(new_id) + ',' + new_data + '\r')
f.close()
print('信息添加成功:id:%s %s' % (new_id, new_data))
else:
print('add:语法错误!!支持以下指令:%s' % msg)
# 处理删除
def del_data(del_cmd):
"""
删除用户信息
:param del_cmd:
:return:
"""
msg = 'del from staff_table where id = 10'
# 如果 from 和 where 在指令中
if 'from' and 'where' in del_cmd:
# print(del_cmd)
# 分割为:del from staff_table where id 9
left_name, right_name = del_cmd.split('=')
# print(left_name, right_name)
# 清空后写入
new_file = open(data_file, mode='r+')
new_file.truncate()
new_file.close()
for i in DATA:
new_data = ','.join(i.values()) # 转换DATA里的数据
if int(right_name) != int(i['id']): # 这里是找出ID不相等,然后写入文件。
with open(data_file, mode='a+') as f:
f.write(new_data + '\r')
else:
print('成功删除id:%s 的信息~' % right_name)
else:
print("del:语法错误!!支持以下指令:%s" % msg)
# 处理修改
def update_data(update_cmd):
"""
修改员工信息函数
:param update_cmd:
:return:
"""
# left_name: age
# left_data: 25
# right_name: name
# right_data: "Alex Li"
# 左边25,右边Alex Li
# update staff_table set dept="Market" where dept = "IT"
# update staff_table set age=25 where name = "Alex Li"
msg = ',update staff_table set dept="Market" where dept = "IT"'
# 判断 set 和 where 是否在指令中
if 'set' and 'where' in update_cmd:
left_cmd, right_cmd = update_cmd.strip().split('where')
# print(left_cmd, right_cmd)
# 分割成 l:update staff_table r:dept="Market"
new_left, new_right = left_cmd.strip().split('set')
# print(new_left, new_right)
# 左边转成:left_name: dept left_data: "Market"
left_name, left_data = new_right.strip().split('=')
# print("left_name:",left_name, "left_data:", left_data)
# 右边转成:right_name: dept right_data: "IT"
right_name, right_data = right_cmd.strip().split('=')
# print("right_name:", right_name, "right_data:", right_data)
# 把 即将修改数据的 双引号改成单引号
new_left_data = left_data.replace('"', " ").strip()
new_right_data = right_data.replace('"', " ").strip()
# print('左边%s,右边%s' % (new_left_data, new_right_data))
# 清空操作
clear_file = open(data_file, mode='r+')
clear_file.truncate()
clear_file.close()
for i in DATA:
# 例如:如果名字在列表中,将包含名字项的age改成25
if new_right_data in i[right_name.strip()]:
# 修改内容
i[left_name.strip()] = new_left_data
print("成功将%s的%s修改为%s" % (right_data, left_name, new_left_data))
# i[right_name.strip()].replace(new_right_data,new_left_data )
data = ','.join(i.values())
with open(data_file, mode='a+') as f:
f.write(data + '\r')
else:
print('修改完成!!')
else:
print('update:语法错误!支持以下指令:%s' % msg)
# 处理用户输入
def input_processing(cmd):
"""
处理用户输入
:param cmd:
:return:
"""
# :find name,age from staff_table where age > 22
symbol = ['find', 'add', 'del', 'update']
# 取第0个数据进行查找,是否存在于symbol,如果在,执行对应的函数
if cmd.split()[0] in symbol:
if cmd.split()[0] == 'find':
print('find')
find_data(cmd)
if cmd.split()[0] == 'add':
print('add')
add_data(cmd)
if cmd.split()[0] == 'del':
print('del')
del_data(cmd)
if cmd.split()[0] == 'update':
print('update')
update_data(cmd)
else:
print("语法错误!!")
# 主函数,让用户一直输入
def main():
"""
主函数入口
:return:
"""
while True:
user_input = input(">>>>>:")
if user_input == 'q': quit()
if not user_input:
print('指令不能为空!!')
continue
input_processing(user_input)
# 执行主函数
main()
总结:
这个作业是对第二章和前面学习内容的综合,也算是自己写的比较多的代码了。这个作业还有很多优化的地方,分享给 小伙伴们看看,希望能帮助到你们。