摘要:
目前基于暹罗的跟踪器主要将视觉跟踪分为两个独立的子任务,包括分类和定位。它们通过单独处理每个样本来学习分类子网络,忽略了正负样本之间的关系。此外,这样的跟踪范例仅采用用于最终预测的建议的分类置信度,这可能产生分类和定位之间的不对准。为了解决这些问题,本文提出了一种基于排序的优化算法,以探索不同的建议之间的关系。为此,我们引入了两个排名损失,包括分类和IoU引导。
作为优化约束:
分类排序损失可以确保正样本的排序高于硬负样本,即,干扰项,使得跟踪器可以成功地选择前景样本而不被干扰项愚弄。
IoU排序损失旨在将分类置信度分数与阳性样本的对应定位预测的交集(IoU)对齐,从而使得能够通过高分类置信度来表示良好定位的预测。
具体而言,建议的两个排名损失是兼容的大多数暹罗跟踪器,并不会产生额外的计算推理。
代码和原始结果可在https://github.com/ sansanfree/RBO上获得。
引入:
尽管基于暹罗的跟踪器已经实现了有希望的性能,但是仍然受到两个限制:
(1)连体追踪者难以区分背景干扰物。特别地,在训练阶段,分类子网络由大量训练样本优化,其中存在大量无信息样本(easy sample),可以很容易地分类,而少数分散注意力的例子被淹没,并有助于对网络优化的微小影响。在测试时,虽然大多数非目标样本可以由跟踪器区分,背景干扰可能会严重误导跟踪器时,它有很强的正信心,导致跟踪失败。
(2)由于分类和定位任务是分开处理的,存在分类和定位任务不匹配的问题。更具体地说,分类损失驱动模型将相关目标与背景区分开来,而不管位置信息如何,而回归分支旨在定位所有正样本的目标边界框,而不考虑分类信息。因此,前景得分低的可能定位得分高,而前景得分高的可能定位得分低。
一个定义:
“Hard Negative Samples”(困难负样本)是指那些对模型来说比较难以正确分类的负样本。
“Easy Negative Samples”(简单负样本)则是相对于困难负样本而言的。它们是那些对模型来说相对容易正确分类的负样本。这些样本通常具有明显的特征或属性,使得模型可以轻松地将其识别为负样本。
实现:

**classification ranking:**确保正样本的排名高于负样本,这样跟踪器就可以成功地选择前景样本而不被干扰物所迷惑。
**IoU-guided Ranking:**将分类置信度分数与正样本的相应定位预测IoU相一致,即具有较大IoU的样本预期获得较高的分类置信度分数。
SiamRPN+±RBO:SiamRPN++和RBO
SiamBAN-RBO:SiamBAN和RBO
SiamPW-RBO:SiamBAN-RBO中用像素相关代替深度相关
结构

分类损失:对于困难负样本容易发生跟踪失败的问题,使得正样本排名高于困难负样本,旨在抑制干扰项的分类置信度。
IoU排名损失:缓解分类和定位之间的不匹配问题,旨在将分类与回归对齐,即,具有较大IoU的样本预期获得较高的分类置信度分数。(基于RankDetNet)
分类器实现:该分类器由交叉熵损失监督。然后,我们根据预测对象置信度得分对所有阴性样本进行排序。置信度得分低于τneg的阴性样本,例如,0.5,被过滤掉。其余的构成硬负样本集。
分类损失实现:
大多数基于暹罗的跟踪器经由交叉熵损失实现二进制分类,这可以确保大多数样本可以被正确分类。然而,如图3所示,一些硬负样本可能会穿过决策超平面并欺骗分类器。在跟踪任务中,只要一个负样本的分类得分大于所有正样本的分类得分,就会发生跟踪失败。因此,假阳性分类严重阻碍了跟踪器的鲁棒性。
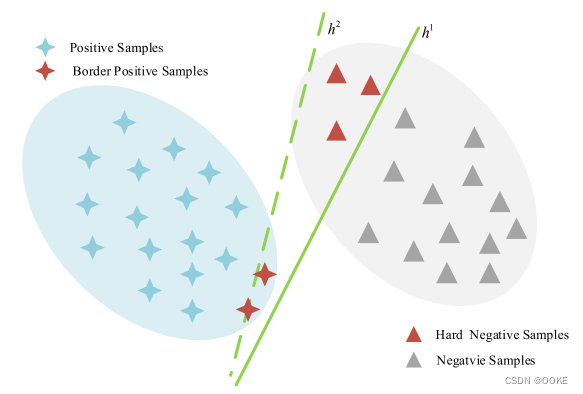
1、获得正负样本集:训练分类器,该分类器由交叉熵损失监督。然后,我们根据预测对象置信度得分对所有阴性样本进行排序。置信度得分低于τneg的阴性样本,例如,0.5,被过滤掉。硬负样本集:{pj-},正样本集{pj+ }。
2、对训练样本的期望进行排序:以扩大前景-背景分类裕度,同时时间复杂度可以显着降低到O(1)。硬性阴性和阳性样本的期望值定义为:(w代表权重,由softmax函数得到)
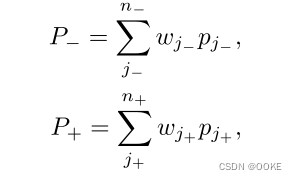
3、我们采用逻辑损失将期望P−和P+排序为
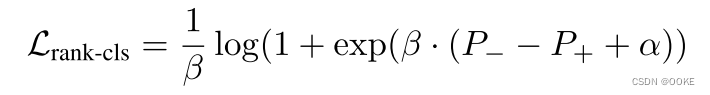
其中,β控制损失值,α是排名。具体来说,如果图像中没有硬负样本,我们将跳过此图像。如图3所示,在Lrank-cls的监督下,将决策超平面从h1调整到h2,并将硬负样本成功放置在负侧。注意,一些边界正样本可以位于决策超平面的负侧,这对于单个对象跟踪任务是可接受的,因为我们只需要一个正样本来表示被跟踪的目标。
IoU排名损失实现
IoU指导的排名损失,以协调分类和回归分支的优化。
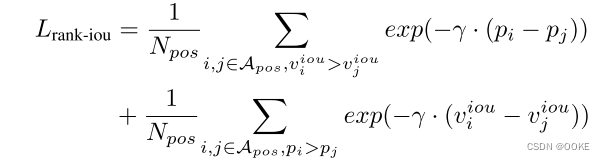
对于正样本i,j ∈ Apos,以成对方式组织排名约束,其中pi和pj分别指示正样本i,j的前景置信度得分,viou i和viou j表示具有样本i和j的地面实况的预测IoU值。
在反向传播优化过程中,如果viou i > viou j,我们将优化pi和pj,使pi的排名高于pj;如果Pi > Pj,则遵循,我们将冻结viouj并且仅优化vioui以实现预期的排名。如果viou j未被冻结,则损失可以通过减小viou j而下降,这将妨碍回归优化。