数据可视化课程报告
功能实现
(40) |
目标网址符合要求(5)
对文本信息进行分词、词频统计等预处理(5)
对研究热点词汇、高产作者、论文数量、论文标题长度等信息进行统计分析(10)
对上述分析结果进行可视化展示和说明(20) |
报告格式
(40) |
报告是否按照规定模板撰写(5)
是否符合科技文献撰写的格式规范(5)
是否使用了折线图、饼状图、词云等多种可视化方式(10)
可视化(图、表的格式)是否简洁、高效、美观、规范(10)
篇幅是否饱满(5)
有核心源代码(5) |
总结和分析
(20) |
是否包含对可视化结果的分析和理解(10)
上述分析和理解是否正确、深刻(10) |
要求及评分标准
- 功能(40分)
主要考查:是否按要求实现了主要功能,即:(1)对网址https://openaccess.thecvf.com/CVPR2020中所列文献信息进行分析;(2)对文本进行预处理,包括分词、词频统计等;(3)对研究热点词汇、高产作者、论文数量、论文标题长度等信息进行统计分析;(4)对上述分析结果进行可视化展示和说明;(5)可选项,对不同年份上的数据进行分析,揭示其变化和关联规律。
- 报告格式(40分)
主要考查:(1)报告是否按照规定模板撰写;(2)是否符合科技文献撰写的格式规范;(3)是否使用了折线图、饼状图、词云等多种可视化方式;(4)可视化(图、表的格式)是否简洁、高效、美观、规范;(5)篇幅是否饱满;(6)核心源代码。
- 总结和分析(20分)
主要考查:(1)是否包含对可视化结果的分析和理解;(2)上述分析和理解是否正确、深刻。
一、 问题描述
对CVPR2020文章列表进行分析,挖掘数据内在信息。使用爬虫获取文章标题和作者数据,并对数据进行分词,统计词频等分析处理。结合可视化技术对研究热点领域或词汇、论文篇数、高产作者数、论文标题等数据进行分析。对可视化的结果进行核心代码展示和解释说明。
报告使用了折线图,柱状图、饼状图、词云、关系图等可视化方式,对上述数据进行了包括时间维度上的不同角度的可视化处理,并讨论了其中蕴含的规律。
二、数据获取与预处理
2.1爬虫获取论文数据
使用 request 和 bs4 中的 BeautifulSoup 库对网页进行爬取,将爬取结果分两部分分别存放论文题目信息和作者信息,存放到对于年份目录下的 paperInfo.txt 和 authorInfo.txt 文件中。
爬虫核心代码:
urls:是爬取的网址列表,file_title:题目信息存放的路径,file_authors:作者信息存放路径
for url in urls:
print('爬取的网址:', url)
r = requests.get(url, headers=headers)
content = r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
dts = soup.find_all('dt', class_='ptitle')
print('爬取的数据数量', len(dts))
hts = 'http://openaccess.thecvf.com/'
for i in range(len(dts)):
title = dts[i].a.text.strip(); name = dts[i]
href = hts + dts[i].a['href']
r = requests.get(href, headers=headers)
content = r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
file_title.write(str(title) + '\n') # 写入文章题目信息
divauthors = soup.find(name='div', attrs={"id": "authors"}).text.strip()
authors = divauthors.partition(';')[0]
file_authors.write(str(authors) + '\n') # 写入作者信息

图 2-1 题目信息

图2-2 作者信息
2.2数据预处理
2.2.1 标题数据预处理
1、 首先对标题数据进行处理,使用lower转换为小写并去除常用词汇代码:
stopwords = {'a', 'do', 'does', 'an', 'is', 'with', 'on', 'by', 'using',
'for', 'of', 'and', 'in', 'to', 'the', 'from', 'be', 'can'} # 常用词汇
title_data = title_data.replace('-', ' ').replace(':', '').replace('?', '').replace('!', '').replace(',', '').split('\n') # 去除标号
for title in title_data:
word_list = title.lower().split(' ') # 转换为小写
2、 然后对标题进行分词和统计词频,主要使用了split和sort函数。并将统计结果写入文件保存:
title_data = open(file_name, 'r', encoding='utf8').read() # 读入题目数据
file_keyword_count = open(r'../datasets/2020/keyword_count.txt', 'w', encoding='utf8') # 保存的词频文件
wordcount = {} # 统计词频的字典
keyword = str(title_data).replace('\n', ' ').split(' ') # 对题目进行分词
for key in keyword: # 统计词频
if key in wordcount: wordcount[key] += 1
else: wordcount[key] = 1
按词频大小排序后写入文件
wordcount = sorted(wordcount.items(), key=lambda e: e[1], reverse=True)
2.2.2 作者数据预处理
统计每个作者发表的论文数,通过split获取所有作者列表,统计每个作者的出现次数,并写入文件保存,便于可视化分析。
author_list = author_data.replace('\n', ', ') .split(', ') # 论文中所有作者的列表
author_paper = {} # 作者:论文数字典
for author in author_list: # 统计每个作者的出现次数
if author in author_paper: author_paper[author] += 1
else: author_paper[author] = 1
# 排序后写入文件
author_paper = sorted(author_paper.items(), key=lambda e: e[1], reverse=True)
下面是预处理后得到的文件格式:
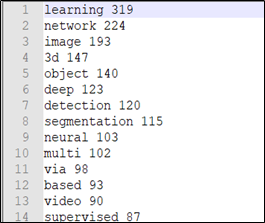
图2-3 词频文件数据
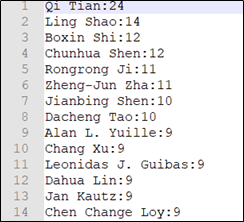
图2-4 作者文章数文件数据
三、有关热点词汇的可视化
3.1热点词汇的词频直方图和词云
3.1.1 热点词汇的词频直方图
使用matplotlib库中的bar进行绘制,可以显示频率前n的热点词汇。从之前数据预处理得到的词频文件中读取词频数据,进行简单处理后得到可视化要求的数据结构count_list,n是要可视化的热点词汇数量。下面是核心代码:
word_count = open(r'datasets/2020/keyword_count.txt', 'r').read().split('\n')# 读取数据
count_list = [] # 可视化数据列表
for wordcount in word_count:
count_list.append(wordcount.split(' '))
scale_x = range(n)
x = [] # 热点词汇列表
y = [] # 词频列表
for word in count_list:
if len(x) == n: break # 绘图显示Top n词汇
x.append(word[0]) # 词汇
y.append(int(word[1])) # 词频
plt.figure(figsize=(12, 5)) # 创建图形
plt.xticks(scale_x, x) # x轴
plt.title('top '+str(n)+' word', color='black', fontsize=13) # 标题
plt.bar(x, y, width=0.45, color="#87CEFA") # 直方图颜色
for i in range(n): # 显示直方图具体数据
plt.annotate(y[i], xy=(i, y[i]), xytext=(i, y[i] + 5), color='black', ha='center')
plt.xlabel('word', fontsize=12) # x轴标签
plt.ylabel('word frequency', fontsize=12) # y轴标签
plt.savefig(fname='top'+str(n)+'_keyword.png') # 保存文件

图3-1 前10热点词汇的词频直方图
结果分析:
- 由上面的词频直方图可以直观的看出每个热点词汇的出现次数,并可以比较不同热点词汇之间词频的大小。
- 可以从图中得到learning这个词汇在论文标题中出现次数最多,但是不知道learning什么东西,这还需要继续分析数据,这在后面的可视化中会进行讨论。
- network的词频第二,说明有关网络的论文很多。Image和3d出现次数也很高,说明图像和3维相关是计算机视觉领域的研究热点。
3.1.1 热点词汇的词云
通过调用wordcloud库进行词云的绘制,首先从爬虫获取的txt文件中获取题目输入,然后调用python中词云api传入数据并保存,下面是核心代码:
data_paper = open(r'datasets/2020/paperInfo.txt', 'r').read() # 获取题目数
# 创建词云
w = wordcloud.WordCloud(width=1000, height=700, background_color="white")
w.generate(data_paper) # 传入数据
w.to_file(save_file_name) # 保存文件

图3-2 热点词汇的词云
结果分析:
-
词云可以变换不同的形状和色彩,使用到的视觉通道很多,但是都不是具体量化的数字,仅仅通过不同词汇之间的相对大小或者说词汇所占的面积得到信息,然而面积信息是不敏感的,这是词云的一个缺点。
-
词云可以可视化很多词汇,也能让人清晰得看见主要信息,但是直方图显示太多词汇时会现得拥挤,并且词云更加美观,这是词云的一个优点。
3.2热点词汇与热点词汇的网络关系图
图形想要展示的是不同热点词汇间的联系,如果两个不同的热点词汇在同一篇论文中出现了,说明这两个词汇之间有关系,那么它们之间的关联次数就加1。网络图的绘制使用了pyechart库中的Graph对这种关系进行可视化展示。
3.2.1使用到的数据变换方式
1、节点大小变换:
当一个热点词汇和其他词汇关联的次数越多,那么可视化出的这个词汇所代表的节点就相对较大。如果要可视化所有词汇之间的关系,结果过于庞大且不易查看,所以只可视化词频大于 70 的 n 个热点词汇之间的关系,这些词汇我们用集合
w
o
r
d
l
L
i
s
t
=
w
o
r
d
i
,
w
o
r
d
(
i
+
1
)
,
…
,
w
o
r
d
n
wordlList={word_i,word_(i+1),…,word_n}
wordlList=wordi,word(i+1),…,wordn 表示。
对于某一个热点词汇
w
o
r
d
i
word_i
wordi ,其他所有词汇
w
o
r
d
j
(
j
∈
1
,
2..
n
,
j
!
=
i
)
word_j (j∈{1,2..n},j!=i)
wordj(j∈1,2..n,j!=i) 与
w
o
r
d
i
word_ i
wordi 在同一题目出现次数的总和,我们将这个总和用 sum 代表,而节点的大小用 sum 赋值的话可视化的结果太大(往往是几百的数量级),所以需要对 sum 进行一定的变换才能有更好的可视化效果。通过对数据的观察,我使用了下面的变换函数,将原始 sum 值映射到新的区间:
s
u
m
n
e
w
=
(
ln
s
u
m
)
×
100
−
450
sum_{new}=(\ln sum)×100-450
sumnew=(lnsum)×100−450
2、不同节点间连接线线宽变换:
当两个不同热点词汇出现在同一标题的次数愈多,说明这两个词汇之间连接的越紧密,那么对应的线宽就越宽。如果单纯的使用两个词汇的关联次数作为线宽的话,同样会遇到线宽过大占满整个屏幕的问题,所以我使用了 Min-max 标准化,将数据映射到 [0,3] 之间,为了加大线宽之间的差异,我又对其进行 e次方 的处理。设这些热点词汇的最大关联次数为 max ,最小关联次数为 min ,那么对于词汇
w
o
r
d
i
word_i
wordi 和词汇
w
o
r
d
j
word_j
wordj ,它们的关联次数为
r
e
l
a
t
i
o
n
i
j
relation_{ij}
relationij ,那么
w
o
r
d
i
word_i
wordi 和
w
o
r
d
j
word_j
wordj 之间的线宽可由下面的公式计算:
l
i
n
e
W
i
d
t
h
=
e
3
×
r
e
l
a
t
i
o
n
i
j
−
m
i
n
m
a
x
−
m
i
n
lineWidth=e^{3\times \cfrac{relation_{ij}-min}{max-min}}
lineWidth=e3×max−minrelationij−min
3.2.2核心代码
# -------------------------------------------- 关系矩阵计算--------------------------------------------------
word_relation = [['' for j in range(scale)] for i in range(scale)] # 关系次数矩阵
for i in range(len(word_list)):
for j in range(len(word_list)):
num = 0 # 热点词汇i和j的关联次数
for title in title_data: # 遍历题目数据,判读热点词汇i和j出现在同一个标题的次数
if (title.find(word_list[i]) != -1) and (title.find(word_list[j]) != -1):
num += 1
if i == j: num = 0
else:
max_relation = max(max_relation, num) # 更新最大关联次数
min_relation = min(min_relation, num) # 更新最小关联析出
word_relation[i][j] = str(num) # 记录关联次数
# -------------------------------------------- 节点大小计算----------------------------------------------
nodes = []
for i in range(scale):
sum = 0 # sum为所有与该词在同一标题的文章总数,决定节点大小
for j in range(scale):
sum += int(word_relation[i][j]) # 节点大小映射变换
nodes.append((opts.GraphNode(name=word_list[i],symbol_size=np.log(sum)*100-450, label_opts={"normal": {"color": "black", "fontSize": 20}})))
# -------------------------------------------- 连线宽度计算-----------------------------------------------
links = []
for i in range(scale): # 创建连接
for j in range(scale):
if int(word_relation[i][j]) != 0:
line_width = 3*(int(word_relation[i][j]) - min_relation) / (max_relation - min_relation) # max-min变换,计算线宽度
color = '#b5b5b5' #连线颜色
if int(word_relation[i][j]) > 30: # 关联次数大于30,连线用红色强调
color = '#fc0033'
links.append(opts.GraphLink(source=word_list[i], target=word_list[j],
linestyle_opts=opts.LineStyleOpts(width=np.exp(line_width), color=color), # 线宽
value=int(word_relation[i][j]))) # 线值
# -------------------------------------------- 画图 -----------------------------------------------------------
c = (Graph(opts.InitOpts(width="100%", height="800px"))
.add("", nodes, links, repulsion=100000, is_focusnode=False, layout="force",
linestyle_opts=opts.LineStyleOpts(width=1.1, type_="solid", curve=0),
itemstyle_opts=opts.ItemStyleOpts(color="#ffbc57",border_color="#fa9600", border_width=1, opacity=0.9,),
label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="Word network")))
c.render("Word Network.html") # 保存
3.2.3可视化结果与分析
面是词频大于70的热点词汇之间关系的网络关系图:

图3-3 不同热点词汇的网络关系图
结果分析:
- 使用了pyechart库进行网络图的生成,其结果是一个可交互的html文件,当鼠标悬停在某一条线上时会提示这条线的值,也就是两个热点词汇的关联次数。上图对关联次数大于30的连线用红色表示,进行强调。
- 可以看到Learning节点连接的词汇很多,这与之前可视化词频的结果一致,但是词频可视化出的直方图无法看出learning与其他词汇的联系。通过观察线的粗细,可以看到learning和supervised的关联次数很高,说明监督式或非监督式和半监督式学习等包含supervised的机器学习算法在计算机视觉领域运用很多。
- 我们还可以观察到network和neural的关联次数也很高,我认为这是因为neural network常常作为神经网络组合出现,这也说明了神经网络的火热。
- Object和detection的关联次数也很高,这反映了目标检测在计算机视觉领域是一个研究热点。
- Learning和deep的关联说明了深度学习的火热,deep和network的联合又说明网络正在越来越深,3d和object的联合也反应了三维相关是计算机视觉的一个研究方向。
四、有关作者的可视化
4.1作者论文发表数统计分析
使用matplotlib中的barh对每个作者在2020年发表的论文数量进行可视化。由于作者名字较长,所以采用水平直方图进行可视化。由于作者较多,所以仅对发表文章数前10的10为作者进行真实,下面是核心代码:
scale_x = range(n)
x = []; y = [] # x轴和y轴数据
for ap in count_list:
if len(x) == n: break # 只显示前 n 个作者
x.append(ap[0]) # x轴数据,为作者名
y.append(int(ap[1])) # y轴数据,为发表文章数
plt.figure(figsize=(10, 5)) # 绘图显示Top n词汇
plt.yticks(scale_x, x) # y轴标签
plt.title('top ' + str(n) + ' paper count author', color='black', fontsize=13) # 标题
plt.barh(x, y, height=0.45, color="#87CEFA")
for xx, yy in enumerate(y): # 显示直方图数字
plt.text(yy + 0.2, xx, yy, va='center')
plt.xlabel('author paper count', fontsize=12) # 标签

图4-1 发表文章数前10的作者直方图
结果分析:
- 可以看出Qi Tian发表文章数最多,且知道具体数值24篇,Ling Shao第二有14篇,后面作者发表篇数都在10左右,相差不大,这说明第一名作者Qi Tian文章发表数遥遥领先其他作者。
- 水平直方图解决了作者名字过长的问题,使得作者名可以完整显示。每个作者发表文章数的具体数值也很清晰,与其他作者文章数进行对比也很容易。
4.2作者与作者之间合作的网络关系图和热图
由于作者太多,且大多数作者发表篇数不多,所以为了可视化效果,我只选取了发表篇数大于5篇的的作者可视化他们之间的关系。与可视化词汇网络关系的库相同。
热图的绘制使用了seaborn库中的headmap,由于作者过多,所以也是只选取了前20为作者可视化他们的合作关系矩阵。下面是核心代码。
首先获取作者之间的关系矩阵:
scale = len(authors_list) # 获取关系矩阵大小
author_relation = [[0 for j in range(scale)] for i in range(scale)]
for i in range(len(authors_list)):
for j in range(len(authors_list)):
num = 0
for authors in authors_cooperation: # 对每篇文章的作者列表进行遍历
if (authors.find(authors_list[i]) != -1) and (authors.find(authors_list[j]) != -1):
num += 1 # 如果作者i,j都在这一篇文章的作者列表中,合作数加 1
if i == j: num = 0
author_relation[i][j] = num
作者与作者之间的网络图(这一部分与之前词汇网络图的绘制大致相同):
nodes = [] # -------------------------------- 节点 ------------------------------------------------------
for i in range(scale):
sum = 0 # sum为所有与该该作者合作总数,决定节点大小
for j in range(scale):
sum += int(author_relation[i][j])
print(sum)
nodes.append((opts.GraphNode(name=authors_list[i], symbol_size=sum + 8, # 节点大小
label_opts={"normal": {"color": "black", "fontSize": 12}})))
links = [] # --------------------------- 连线 ----------------------------------------------------------
for i in range(scale): # 创建连接
for j in range(scale):
if int(author_relation[i][j]) != 0:
color = '#b5b5b5'
if int(author_relation[i][j]) > 3: # 合作次数大于3次进行强调
color = '#fc0033'
links.append(opts.GraphLink(source=authors_list[i], target=authors_list[j],
linestyle_opts=opts.LineStyleOpts(width=1.1, color=color),
value=int(author_relation[i][j]))) # 线值-
c = (Graph(opts.InitOpts(width="100%", height="800px")) # ------------ 画图 -------------- .add("", nodes, links, repulsion=100, is_focusnode=False, layout="force",
linestyle_opts=opts.LineStyleOpts(width=1.1, type_="solid", curve=0), # 连线样式
itemstyle_opts=opts.ItemStyleOpts(color="#3a9fef", border_color="#2861ee", border_width=1, opacity=0.8,),
label_opts=opts.LabelOpts(is_show=True)) # 节点label显示
.set_global_opts(title_opts=opts.TitleOpts(title="Authors network"))) # 标题设置
c.render("Authors Network.html")
可视化作者与作者关系矩阵的热图:
author_relation_pd = pd.DataFrame(np.array(author_relation)[0:m, 0:m], index=authors_list[0:m], columns=authors_list[0:m]) # 热图,m=20,只可视化前20为作者
plt.figure(figsize=(13, 13)) # 热图大小
sns.heatmap(data=author_relation_pd, linewidths=0.3, cmap="RdBu_r", annot=True, fmt="d", center=3) # 传入数据,设置间隔和颜色

图4-2 作者与作者间的合作网络关系图

图4-3不同作者间的合作关系矩阵热图
结果分析:
- 如图4-2所示作者与作者之间的合作关系网络图,我将合作次数大于3次的作者用红色连线进行了强调。从图中可以很好的看出,哪些作者进行了合作,以及合作的频率的相对大小,但是无法知道具体合作次数。
- 和网络图中可以看出,作者之间“传递性”合作很常见,这样的合作可视化后就会聚集在一起,如图4-2左下角所示,形成了抱团现象,猜测可能这些作者是一个实验室的。
- 由于网络图没有办法显示具体数字,所以我使用热图可视化合作关系矩阵如图4-3,矩阵中每一格的数字即为合作次数,合作次数越高,颜色越偏向红色,缺点是没有网络图直观。
五、有关论文标题的可视化
5.1 论文标题长度饼图
对论文标题的长度包括字母个数和单词个数,这两个维度进行可视化分析。使用饼图对各个标题字母和单词个数区间内文章所占比例进行展示。我将标题的字母长度分为六个区间,单词个数分为五个区间,使用pyecharts中的玫瑰图进行展示,下面是核心代码:
word_data = open(r'datasets/2020/title_word_count.txt', 'r').read().split('\n')
viz_data = {}
for i in range(5): # 初始化个数为 0
viz_data[i] = 0
for count in word_data: # 计算每个区间内标题数
count = int(count)
if count < 4: viz_data[0] += 1
elif count < 8: viz_data[1] += 1
elif count < 12: viz_data[2] += 1
elif count < 16: viz_data[3] += 1
else: viz_data[4] += 1
data = viz_data.values()
cate = ['0 ~ 4', '4 ~ 8', '8 ~ 12', '12 ~ 16', '16 ~ 20'] # 标签
pie = (charts.Pie()
.add('', [list(z) for z in zip(cate, data)], radius=["30%", "70%"], center=["35%", "50%"],rosetype="radius",label_opts=opts.LabelOpts(is_show=True, font_size=13, formatter='{b}: {c}\n {d}%'),) # 颜色表
.set_colors(['#393939', '#f5b031', '#fad797', '#59ccf7', '#c3b4df', 'red', 'blue', 'pink'])
.set_global_opts(title_opts=opts.TitleOpts(title="title word count analyse"), legend_opts=opts.LegendOpts(is_show=False)))
pie.render('paper title word count .html') # 保存
论文标题单词数区间所占比重的可视化大致相同,就不再重复放了。

图5-1论文标题字母长度所占比重

图5-2 论文标题单词数所占比重
结果分析:
- 由图5-1和图5-2可以直观的看出不同区间内标题字母和单词长度所占的比重。饼图反应了数据在整体所占的百分比,而玫瑰图夸张了这种对比,且具有交互功能,使得可视化的效果更好。
- 从上图5-1可以看出标题长度在40-60区间内的标题最多,占44.43%,60-80长度的标题占比第二有35.06%,说明标题的长度普遍偏长,需要较多字符对文章研究内容进行描述。
- 从上图5-2可以看出标题单词数8-12区间的占比最多有49.18%,占比第二的是4-8区间,有38.27%。说明论文标题使用的单词数普遍较多,可能更多的单词可以更具体的表示文章内容。
六、题目长度和热点词汇词频的双Y轴折线图
对于前10的热点词汇,统计每个热点词汇所在标题的平均字母长度和平均单词个数,将它们和热点词汇的词频画在同一张图中进行对比分析。由于词频和标题字母数和标题单词数相比数量级比较大,所以使用了双Y轴折线图,左边的Y轴表示词频和标题平均字母长度,右边的Y轴表示标题的评论单词个数。 为了便于观看,我将Y轴和使用该Y轴的折线都染成同一种颜色,例如词频和字母长度折线染为蓝色,单词个数折线染为绿色。考虑到报告的黑白打印,所以不仅在颜色上做了区分,还使用了不同的marker进行标记。为了更好的观察数据,还给每个点标上了具体数值。
下面是核心代码:
首先计算每个热点词汇所在文章的平均长度:
avg_letter = [0 for x in range(n)] # 关键词的平均字母数
avg_word = [0 for x in range(n)] # 关键词的平均单词数
for i in range(len(title_list)):
for j in range(n):
if keyword_list[j] in title_list[i]:
avg_letter[j] += int(letter_count[j]) # 加上字母个数
avg_word[j] += int(word_count[j]) # 加上单词个数
for i in range(n):
avg_letter[i] = round(avg_letter[i] / float(keyword_count[i]), 2) # 计算平均字母长度
avg_word[i] = round(avg_word[i] / float(keyword_count[i]), 2) # 计算平均单词个数
绘图核心代码:
figure, ax1 = plt.subplots() # 创建绘图
plt.title("The relationship between keywords and title length", fontsize=20) # 标题
# ---------------------------------- 绘制词频折线 ----------------------------------
plot1 = ax1.plot(keyword_list, keyword_count, 'b-^', label='Keyword frequency')
for i in range(n): # 显示每个点的数据,下面每个折线都会有这个代码所以只放了一次
ax1.text(i, keyword_count[i] + 5, s=keyword_count[i], fontsize=12, color="b",
verticalalignment='bottom', horizontalalignment='center')
# ---------------------------------- 绘制论文标题平均字母长度折线 ----------------------------------
plot2 = ax1.plot(keyword_list, avg_letter, 'b8-.', label='average number of letters in the title of the keyword')
ax1.grid(axis="y", color="grey", linestyle="--", alpha=0.5) # 横向网格背景
ax1.set_ylabel("Average Letter Count", fontsize=17, color='b') # Y 轴标签
plt.tick_params(axis='both', labelsize=14)
ax1.set_xlabel("Keyword", fontsize=17) # x轴标签
for tl in ax1.get_yticklabels(): tl.set_color('b') # 左边y轴颜色,蓝色
ax2 = ax1.twinx() # 双Y轴
# ---------------------------------- 绘制论文标题平均单词个数折线 ----------------------------------
plot3 = ax2.plot(keyword_list, avg_word, 'g-s', label='average number of words in the title of the keyword')
lines = plot1 + plot2 + plot3 # 绘制图例
ax2.legend(lines, [l.get_label() for l in lines], loc='upper center')

图6-1题目长度和热点词汇词频的双Y轴折线图
结果分析:
- 虽然learning的词频很高,但是他所在文章标题的平均字母长度和平均字母个数都相对较少,说明含有learning的文章标题一般都比较简短。
- Multi的词频虽然不是很高但是它所在文章标题的平均单词数最大,说明含有multi的标题需要更多的单词去概况文章的研究内容。
- 从整体上来看热点词汇所在论文的标题字母长度相差不大,但是标题所用的单词数相差较大。热点词汇的词频和该词汇所在文章的标题长度一般没有太大关系。
七、热点词汇与所在论文作者数的并列柱状图
对于前10的热点词汇,我可视化了对于每个热点词汇,所有标题中包含这个词汇的平均作者数,最大作者数和最小作者数。通过将这个三个信息并列画出的方式,对比分析不同热点词汇的研究难度。下面是核心代码:
首先获取每个热点词汇的最大,最小,平均作者数:
# 可视化信息 0: max作者数; 1: min作者数; 2: sum作者数; 3: num文章数; 4: 平均作者数
viz_data = [[0 for i in range(5)] for j in range(len(keyword_list))]
for v in viz_data: # 可视化信息初始化
v[0] = -1; v[1] = 100; v[2] = 0; v[3] = 0
for i in range(len(keyword_list)):
for j in range(len(title_list)):
if title_list[j].find(keyword_list[i]) != -1:
viz_data[i][0] = max(int(authors_count[j]), viz_data[i][0]) # 更新最大作者数
viz_data[i][1] = min(int(authors_count[j]), viz_data[i][1]) # 更新最小作者数
viz_data[i][2] = int(authors_count[j]) + viz_data[i][2] # 更新作者总数
viz_data[i][3] = 1 + viz_data[i][3] # 更新文章总数
for v in viz_data: # 计算平均作者数
v[4] = round(v[2] / v[3], 2)
绘图核心代码:
plt.style.use("seaborn-whitegrid") # 设置主题
fig = plt.figure(figsize=(13, 6)); ax = fig.subplots() # 创建绘图
plt.xticks(x+0.3, keyword_list, fontsize=13) # x轴标签
plt.title('Keywords study author number analysis', color='black', fontsize=15)
max_bar = plt.bar(x, viz_data[:, 0], width=0.3, color="#87CEFA",
label="Maximum number of study authors") # 最大作者数
min_bar = plt.bar(x+0.3, viz_data[:, 1], width=0.3, color="#7bf400",
label="Minimum number of study authors") # 最小作者数
avg_bar = plt.bar(x+0.6, viz_data[:, 4], width=0.3, color="#ff8540",
label="Average number of study authors") # 平均作者数
for rect in max_bar: # 柱状图上显示具体数据,min和avg的显示数据代码相同就不重复放了
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height + 0.1, str(height), ha="center", va="bottom")
plt.xlabel('keyword', fontsize=15)
plt.ylabel('author number', fontsize=15)
plt.legend() # 显示图例

图7-1 热点词汇的最大,最小,平均作者数柱状图
结果分析:
- 可以看出热点词汇image的最大作者数最多达到15个,learning,image和3d的最小作者数都只有1个。说明研究图像的某个领域可能需要较多的人,而研究learning,image,3d最少可以达到1人,所以对某一计算机视觉领域的研究工作非常多样化,既有可以很多人完成的工作也有1人就可完成的工作。
- 热点词汇的平均作者数相差不大,大多在4到5附近浮动,说明每个领域的研究难度相差不大,不存在某个领域常常需要很多人才能展开研究。
- 观察热点词汇的平均作者数可以发现detection的平均研究作者数最高,虽然相较于其他热点词汇的作者数并没有高很多,反应了目标检测这一领域研究人数略多,可能需要更多的人手展开工作,进行图像处理等。
八、时间维度上的可视化分析
通过爬虫对2013到2020年的CVPR论文进行爬取并保存,数据预处理同上述的2020预处理方式相同。然后根据数据在时间维度上进行可视化分析,发现其中蕴含的规律。
8.1时间维度上热点词汇变化的河流图
从2013到2020年,计算机视觉不断蓬勃发展,研究的热点也在不断变化。通过可视化2020年前10个热点词汇的在过去8年来词频的变化,来展示研究热点的变化方向。
我使用了pyechart中的ThemeRiver模块进行河流图的绘制,河流图可以清晰的展示不同主题,也就是这10个不同热点词汇随时间变化的规律。
首先需要得到每一年词汇的词频,处理的分词和统计词频的方式同上面2020年统计方式相同,这里不再重复。下面是核心代码:
word_list = ['learning', 'network', 'image', '3d', 'object', 'deep', 'detection', 'segmentation', 'neural', 'multi'] # 要展示的10个词汇
river = (
ThemeRiver(init_opts=opts.InitOpts(width="1000px", height="600px", theme=ThemeType. INFOGRAPHIC)) # 设置大小和主题
.add(series_name=word_list, # 每个名称
data=data, # 历年关键词的词频数据
singleaxis_opts=opts.SingleAxisOpts(pos_top="50", pos_bottom="50", type_="time")
) # 坐标轴
.set_global_opts(
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="line"),
title_opts=opts.TitleOpts(title="Keyword River Map", # 标题
subtitle="Research on the frequency changes of keywords from 2013 to 2020",
pos_bottom="85%", pos_right="50%"))
.render("Keyword River.html") # 保存
)

图8-1时间维度上热点词汇变化的河流图
结果分析:
- 变化最为显著的就是network和deep,在2013年的时候,它们几乎没有多少人研究,但是随着时间的推移network和deep逐渐增多,特别是在2016年左右,这两个领域的占比突然增加的较多,这与当年神经网络和深度学习的火热是对应的。
- 从图8-1可以看出learning在这8年来所占比重一直很大,人们一直在使用learning作为前缀或后缀为标题命名。
- 到2020年研究领域大多由learning,network,image这三者覆盖,它们都属于比较大的类别或者说是用于研究的工具,再往下看就是3d这个热点词汇,说明三维视觉再CV领域是一个长期不断发展的领域,虽然没有突然增涨,但是在整个历史上都占据着重要地位。
- 从图中可以看到,不管是哪一个热点词汇,这八年来的词频都得到了显著增涨,这是计算机视觉蓬勃发展的结果。我认为这与计算机的快速发展离不开关系,计算机视觉的研究是一个需要很高计算机性能的领域,正因为有了更好的显卡,更大的存储空间,我们才可以进行图像的保存和计算,这大大促进了计算机视觉的发展。
8.2 时间维度上高产作者发表论文数变化的折线图
对于前十位高产作者,统计每个作者从2013到2020年发表论文数的变化情况,发现谁是正在冉冉升起的学术新星。由于是黑白打印,所以不同折线不仅由不同的颜色进行区分,也有不同的marker进行区分,下面是核心代码:
author_name_list = [] # 作者名列表
count_list = [] # 当年论文数列表
dict_info = {} # 每一年发表论文数的字典
for name, count in dict2020.items():
if len(count_list) < n: # 只统计前 n 位作者
author_name_list.append(name)
count_list.append(int(count))
# 记录2020年的论文数序列,由于2013-2020处理方式相同就不重复放了
figure, ax = plt.subplots() # 创建绘图
ax.grid(axis="y", color="grey", linestyle="-", alpha=0.5) # 网格线
plt.title("Changes in the number of papers published by authors from 2013 to 2020", fontsize=20) # 标题
marker_list = ["o", "v", "8", "s", "p", "P", "*", "+", "x", "X"] # 线上标记列表
year_list = range(2013, 2021) # 横坐标轴
for index, author in enumerate(author_name_list):
paper_count = [] # 这个作者2013到2020发表论文数列表
for year in range(2013, 2021):
paper_count.append(dict_info[year][index]) #根据字典获取当年该作者发表的论文数
print(year_list, paper_count)
ax.plot(year_list, paper_count, label=author, alpha=0.6, linewidth=2, marker=marker_list[index])
for i in range(2013, 2021): # 显示具体数据
ax.text(i, int(paper_count[i-2013])+0.1, s=paper_count[i-2013],alpha=0.6, fontsize=12, horizontalalignment='center')
ax.set_ylabel("paper count", fontsize=17) # y轴标签
ax.set_xlabel("Year", fontsize=17) # x轴标签
plt.xticks(year_list, fontsize=14); plt.yticks(fontsize=14) # x,y轴标签大小
plt.legend() # 图例

图8-2时间维度上高产作者发表论文数变化的折线图
结果分析:
- 由图8-2可以看出蓝色这条线,也就是圆点标记的那条折线。该作者Qi Tian在2020年发表的论文数最多,且从2013年的2篇开始这8年来不断发表文章,是一名学术大佬。
- 蓝绿色这条线,也就是×标记的那条折线代表的作者Chang Xu,虽然2013-2018年的paper数为0,但是2019到2020发表数从2篇到9篇是一名学术潜力股。
- 绿色这条折线,代表Boxin Shi在2019年只发表了1篇文章,但是2020年发表了12篇,可能是2019年文章发太少发奋图强后研究有了新突破。
- 红色这条线,也就是方框标记的折线,代表作者Chunhua Shen,从2013到2020年一直非常平稳,没有很大波动,但也在持续增长文章数。
- 总体上来看,每位作者的发表文章数都呈现上升趋势,大家发表文章的数量都在随着时间不断增多,说明随着对某一领域长达多年的深耕,可能大家的研究更加得心应手,发现和创新的idea越来越多。
完整代码下载
CVPR会议论文收录信息可视化与分析
https://download.csdn.net/download/qq_45364953/21712744