前言
今天,我试用了闻达开源LLM调用平台。这一框架拥有类AutoGPT和ChatPDF的功能,能根据一句简短的提示自动生成提纲,然后按照提纲自动填充每章内容,使得论文或小说的写作变得更加高效。此外,它能够导入相关知识库,并通过调用知识库查询相关信息,这项技术更加令人叹服。除此之外,该平台还可基于问题生成相关关键词,并在与知识库交互后对每个关键词自动获取多个答案。这一连串自动化和高度的效率操作,令我深感平台的卓越魅力,无法抵挡其吸引力。


喜欢的小伙伴们千万不要错过,当然也欢迎更多小伙伴加入,进行二次开发。
闻达框架简介
闻达是一个综合的开源LLM调用平台。旨在通过使用为小模型外挂知识库查找的方式,实现近似于大模型的生成能力。
目前支持模型:chatGLM-6B、chatRWKV、chatYuan、llama系列。
- 知识库扩展模型能力
- 支持参数在线调整
- 支持chatGLM-6B、chatRWKV、llama系列流式输出和输出过程中中断
- 自动保存对话历史至浏览器(多用户同时使用不会冲突,chatRWKV历史消息实现方式需使用string)
- 对话历史管理(删除单条、清空)
- 支持局域网、内网部署和多用户同时使用。
- 多用户同时使用中会自动排队,并显示当前用户。
前期准备
电脑要求
- python版本要求:3.8
- windows系统:Windows 7 or later (with C++ redistributable)
- 显卡:6G以上GPU
安装anaconda
从anaconda官网,下载安装anaconda。具体教程详见官网教程。
安装相应版本的CUDA
首先在终端查看你的Nividian版本,命令如下:
nvidia-smi
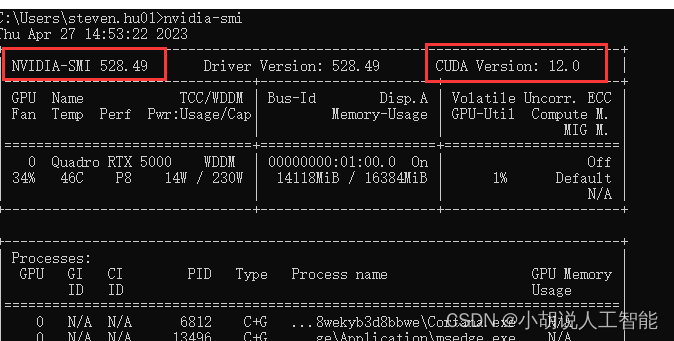
查看到本机可装CUDA版本最高为12.0,版本向下兼容,意思就是CUDA 12.0及以下版本的都可以安装,但一般不建议使用最新版本的。因为可能后续其他安装包没有更新对应版本的可以下载。由于Pytorch(可以从pytorch官网)中可以看到,目前的CUDA版本一般是11.7和11.8,所以建议选择11.8版本以下的。博主这里选择了11.7进行安装。
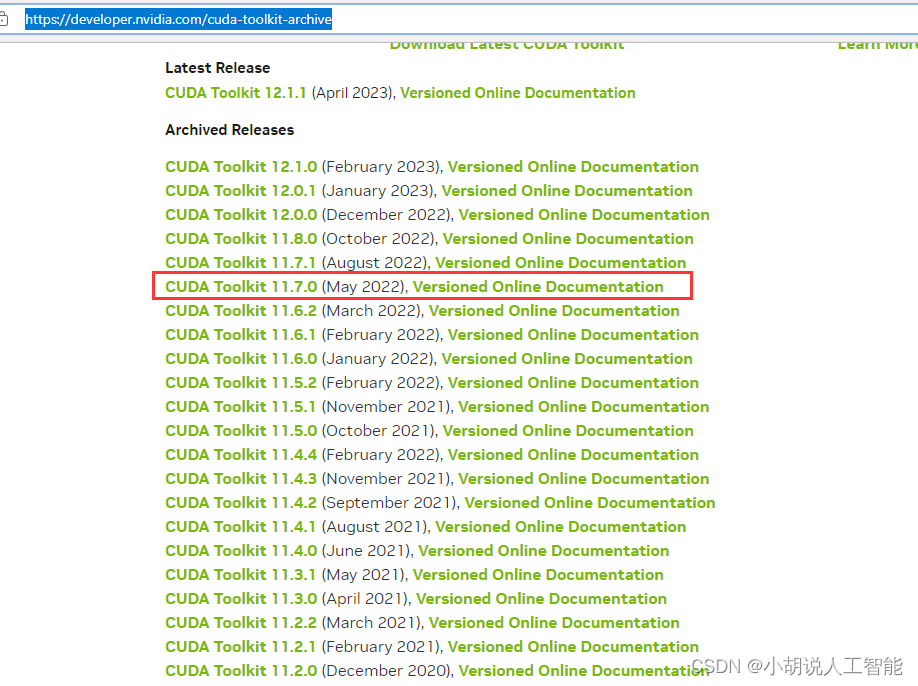
安装完后,注意需要看下系统环境变量中地址有没有相应版本的cuda,比如我的电脑就是配置了下面几个环境变量
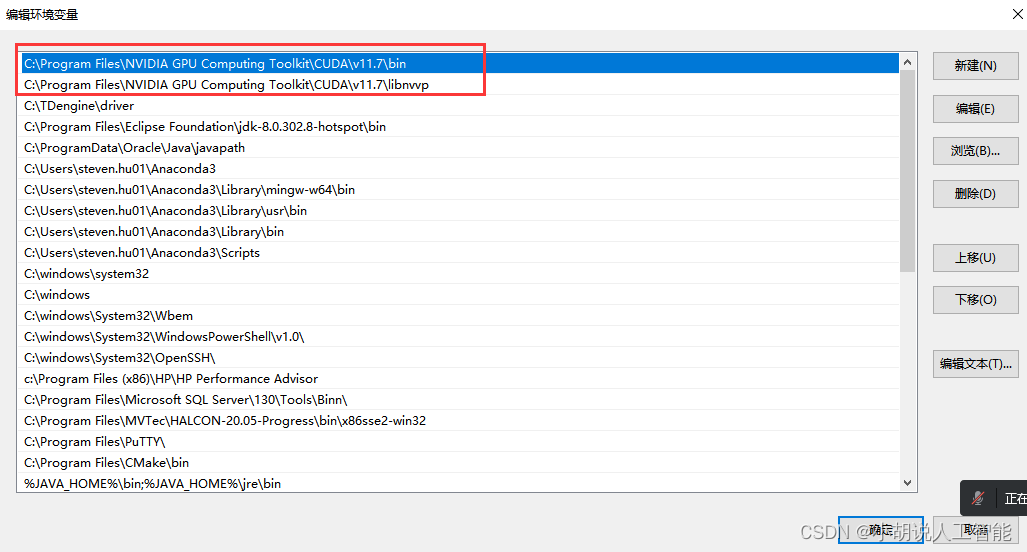
除上面两个之外 ,还可以加入以下环境变量,以保证不会出错。我没配置下面两个,也没出错,所以大家根据实际情况选择是否加入下面两个环境配置。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\CUPTI\lib64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include
不配置可能会报错,Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
配置ChatGLM-6B Conda环境
首先以管理员方式启动windows命令窗口,在搜索中输入cmd即可打开,输入以下命令,新建一个名字为ChatGLM的环境,并安装tensorflow-gpu版本。新建环境过程中选择y,进入下一步
conda create --name ChatGLM python==3.8.10
接下来激活ChatGLM的环境
conda activate ChatGLM
安装pytorch
如果电脑配置了GPU,要注意需安装GPU版本的pytorch,具体可登录官网链接:
这里要注意选择你是什么系统,cuda是安装了什么版本(博主前面选择的是11.7),然后复制下面红框中的命令到终端就可以安装了。
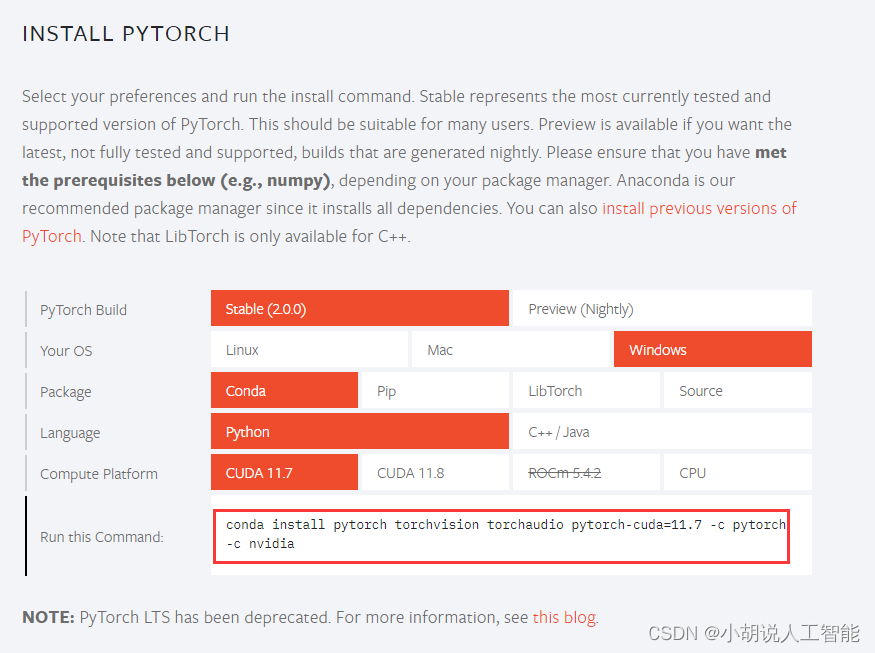
在终端运行下面命令,即可安装成功pytorch-GPU版本:
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
在终端输入python,然后依次输入下面代码,验证torch-GPU版本是不是成功。
import torch
torch.cuda.is_available() ## 输出应该是True

类ChatPDF及AutoGPT开源模型——闻达环境部署及安装
相关代码及模型下载
下载地址:https://pan.baidu.com/s/105nOsldGt5mEPoT2np1ZoA?pwd=lyqz 提取码:lyqz
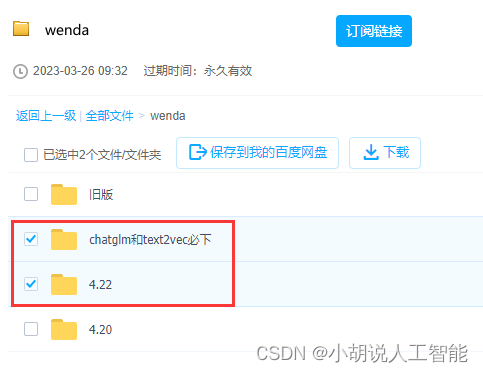
这里只要下载最新的4.22和模型文件夹这两个文件夹即可。
下载下来后,把4.22中的压缩文件解压,说明如下:
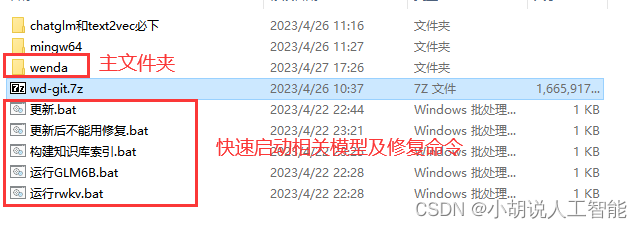
解压模型到指定地址
其中chatglm和text2vec必下文件夹中都是模型文件,依次解压到wenda主文件夹中的model里面。
其中chatglm-6b-int4是低显存版的模型,也是压缩文件chatglm-6b-int4.7z解压出来的模型,如果想要运行最新版本的Chatglm-6b模型,可以参考下面步骤再下载到model/chatglm-6b文件夹中
从hugging face下载所有文件下来,放到model/chatglm-6b文件夹内。
其中模型文件(大于 1G 的)如果下载速度慢,可以在国内清华云源中单独下载这几个模型文件(其他这个源没有的文件还是需要在 huggingface 上下载):https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/
最后model/chatglm-6b文件夹内应该如下显示:
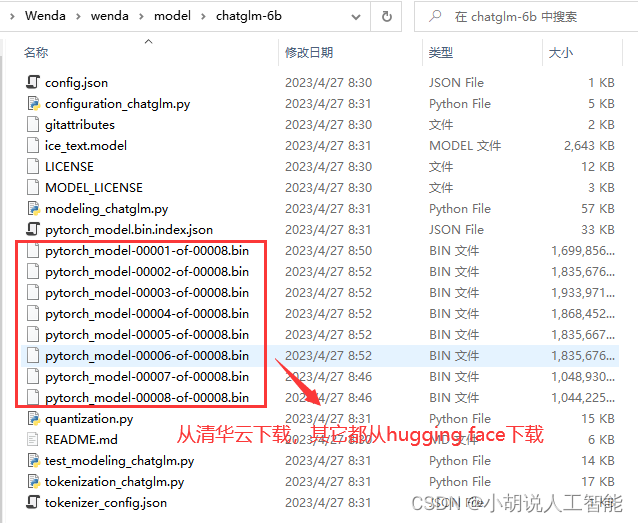
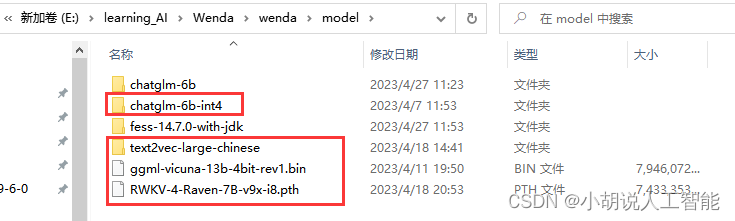
最终model文件夹内应该至少有以下红框标注文件夹或模型,当然闻达框架还可以兼容其它模型,大家也可以根据需求,后期加载各种模型,同时进行相关配置
配置文件修改
主要配置文件为wenda文件夹中的config.xml文件
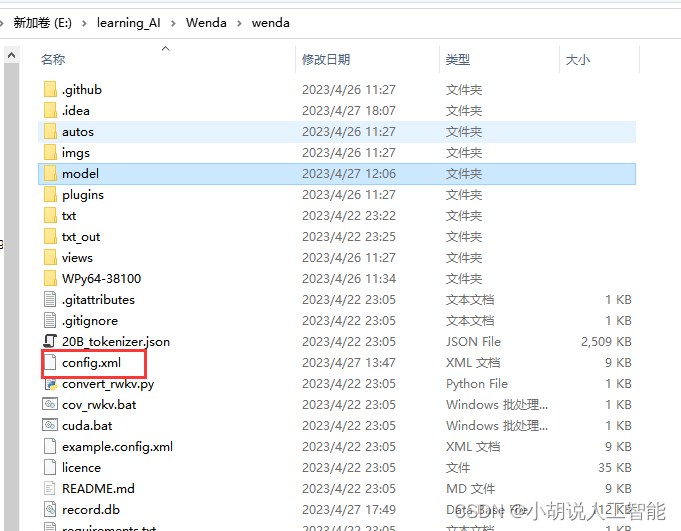
注意对相关模型地址的修改,但如果模型没有按上面解压出来的话,就不需要做其它处理了。如果要使用最新版本的Chatglm-6b模型作为glm模型话,就需要修改<value>model/chatglm-6b-int4</value>为<value>model/chatglm-6b</value>即可
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<General>
<property>
<name>Logging</name>
<value>True</value>
<description>日志</description>
</property>
<property>
<name>Port</name>
<value>17860</value>
<description>WebUI 默认启动端口号</description>
</property>
<property>
<name>LLM_Type</name>
<value>rwkv</value>
<description>LLM模型类型:glm6b、rwkv、llama</description>
</property>
</General>
<Models>
<RWKV>
<property>
<name>Path</name>
<value>model/RWKV-4-Raven-7B-v9x-i8.pth</value>
<description>rwkv模型位置</description>
</property>
<property>
<name>Strategy</name>
<value>cuda fp16</value>
<description>rwkv模型参数</description>
</property>
<property>
<name>HistoryMode</name>
<value>string</value>
<description>rwkv历史记录实现方式:state、string</description>
</property>
</RWKV>
<GLM6B>
<property>
<name>Path</name>
<value>model/chatglm-6b</value>
<description>glm模型位置</description>
</property>
<property>
<name>Strategy</name>
<value>cuda fp16</value>
<description>glm 模型参数 支持:
"cuda fp16" 所有glm模型 要直接跑在gpu上都可以使用这个参数
"cuda fp16i8" fp16原生模型 要自行量化为int8跑在gpu上可以使用这个参数
"cuda fp16i4" fp16原生模型 要自行量化为int4跑在gpu上可以使用这个参数
"cpu fp32" 所有glm模型 要直接跑在cpu上都可以使用这个参数
"cpu fp16i8" fp16原生模型 要自行量化为int8跑在cpu上可以使用这个参数
"cpu fp16i4" fp16原生模型要 自行量化为int4跑在cpu上可以使用这个参数
</description>
</property>
<property>
<name>Lora</name>
<value></value>
<description>glm-lora模型位置</description>
</property>
</GLM6B>
<LLAMA>
<property>
<name>Path</name>
<value>model/ggml-vicuna-13b-4bit-rev1.bin</value>
<description>llama模型位置</description>
</property>
<property>
<name>Strategy</name>
<value></value>
<description>llama模型参数 暂时不用</description>
</property>
</LLAMA>
</Models>
<Library>
<property>
<name>Type</name>
<value>bing</value>
<description>知识库类型:
bing → cn.bing搜索,仅国内可用
fess → fess搜索引擎
mix → 知识库融合,需设置参数
st → sentence_transformers,内测版本
kg → 知识图谱,暂未启用
</description>
</property>
<property>
<name>Show_Soucre</name>
<value>False</value>
<description>知识库显示来源</description>
</property>
<property>
<name>Size</name>
<value>200</value>
<description>知识库最大长度</description>
</property>
<property>
<name>Step</name>
<value>2</value>
<description>知识库默认上下文步长</description>
</property>
<MIX>
<property>
<name>Strategy</name>
<value>st:2 bing:5</value>
<description>知识库融合参数</description>
</property>
<property>
<name>Count</name>
<value>5</value>
<description>知识库抽取数量</description>
</property>
</MIX>
<BING>
<property>
<name>Count</name>
<value>5</value>
<description>知识库抽取数量</description>
</property>
<property>
<name>Academic</name>
<value>True</value>
<description>是否使用必应学术</description>
</property>
<property>
<name>Searc_Site</name>
<value>www.12371.cn</value>
<description>cn.bing站内搜索网址: 共产党员网,留空不使用</description>
</property>
</BING>
<FESS>
<property>
<name>Count</name>
<value>1</value>
<description>知识库抽取数量</description>
</property>
<property>
<name>Fess_Host</name>
<value>127.0.0.1:8080</value>
<description>Fess搜索引擎的部署地址</description>
</property>
</FESS>
<ST>
<property>
<name>Path</name>
<value>txt</value>
<description>知识库文本路径</description>
</property>
<property>
<name>Size</name>
<value>20</value>
<description>分块大小</description>
</property>
<property>
<name>Overlap</name>
<value>0</value>
<description>分块重叠长度</description>
</property>
<property>
<name>Count</name>
<value>3</value>
<description>知识库抽取数量</description>
</property>
<property>
<name>Model_Path</name>
<value>model/text2vec-large-chinese</value>
<description>向量模型存储路径</description>
</property>
<property>
<name>Device</name>
<value>cpu</value>
<description>faiss运行设备</description>
</property>
</ST>
<QDRANT>
<property>
<name>Path</name>
<value>txt</value>
<description>知识库文本路径</description>
</property>
<property>
<name>Model_Path</name>
<value>model/text2vec-large-chinese</value>
<description>向量模型存储路径</description>
</property>
<property>
<name>Qdrant_Host</name>
<value>http://localhost:6333</value>
<description>qdrant服务地址</description>
</property>
<property>
<name>Device</name>
<value>cpu</value>
<description>qdrant运行设备</description>
</property>
<property>
<name>Collection</name>
<value>qa_collection</value>
<description>qdrant集合名称</description>
</property>
</QDRANT>
<KG>
<property>
<name>Count</name>
<value>5</value>
<description>知识库抽取数量</description>
</property>
<property>
<name>Knowledge_Path</name>
<value></value>
<description>知识库的文件夹目录名称,若留空则为txt</description>
</property>
<property>
<name>Graph_Host</name>
<value></value>
<description>图数据库部署地址</description>
</property>
<property>
<name>Model_Path</name>
<value></value>
<description>信息抽取模型所在路径</description>
</property>
</KG>
</Library>
</configuration>
根据使用的不同模型,安装相关库
不同模型有不同的安装库,分别存在requirements.txt及requirements-****.txt文件中
可以依次使用下面命令(注意每次安装都替换掉requirements.txt文件即可)安装:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simp1e
运行体验
安装完成所有库后,就可以根据需求,开始体验了。作为一个能兼容chatGLM-6B、chatRWKV、chatYuan、llama系列等几大语言模型的框架,可以分别体验运行不同模型的感受。
运行chatGLM-6B 大语言模型
在wenda文件夹中打开终端命令,然后运行下面命令。
run_GLM6B.bat
默认参数在GTX1660Ti(6G显存)上运行良好。
自动会在浏览器打开地址:http://127.0.0.1:17860/
- 18大主题功能
- 18大prompt自动生成:只要输入主题,自动补全其它详细提示。比如使用
问题生成:输入ChatGPT的使用,则会自动生成:根据以下内容,生成一个10个常见问题的清单:ChatGPT的使用。

运行chatRWKV 大语言模型
在wenda文件夹中打开终端命令,然后运行下面命令。
run_rwkv.bat
默认参数在GTX1660Ti(6G显存)上正常运行,但速度较慢。
运行llama 大语言模型
先从PyPI安装llama-cpp-python库:
pip install llama-cpp-python
在wenda文件夹中打开终端命令,然后运行下面命令。
run_llama.bat
类AutoGPT功能
使用写论文,或者知识库直读,就能直接触发AutoGPT功能,自动通过多次调用模型,生成最终论文或者根据知识库相关内容生成多个根据内容回答问题的答案。当然这一块,小伙伴们还可以自己二次开发,开发更多的类AutoGPT功能哈。

类ChatPDF功能
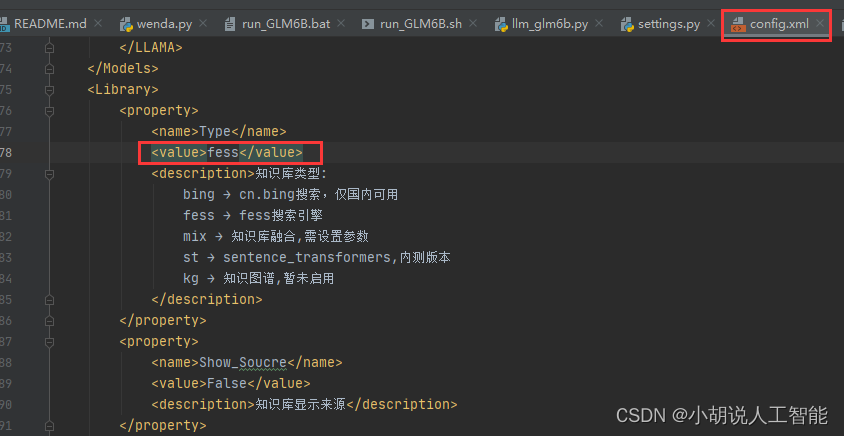
该功能,需要先在config.xml文件中配置value为fess模式:
- 接着下载
fess-14.7.0-with-jdk.7z,解压到平时放软件的盘 见上面:相关代码及模型下载
- 打开解压出来的
fess-14.7.0-with-jdk\bin目录
- 双击
fess.in.bat
-
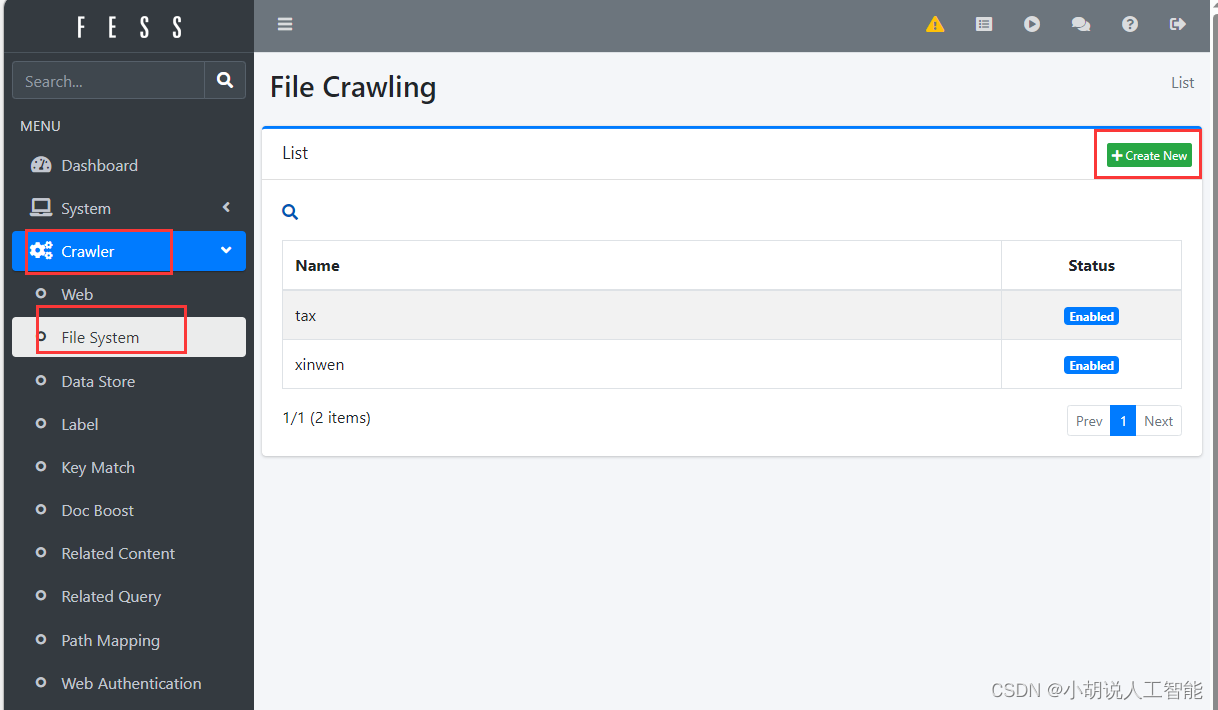
点击侧边栏中的Crawler. 点击File System
- 点击右上角的Create New
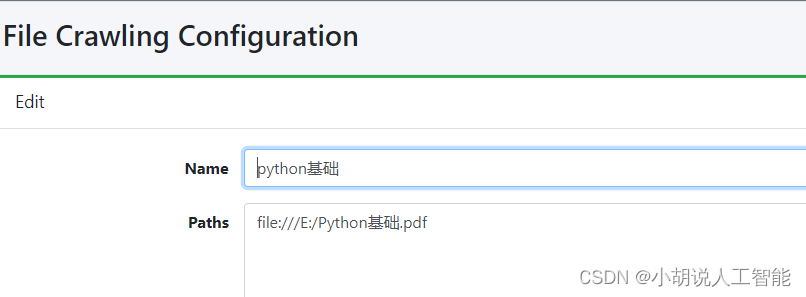
- Name输入便于记忆的资料库的名字
- Paths输入资料库的地址(格式示例:
file:///E:/pdf)
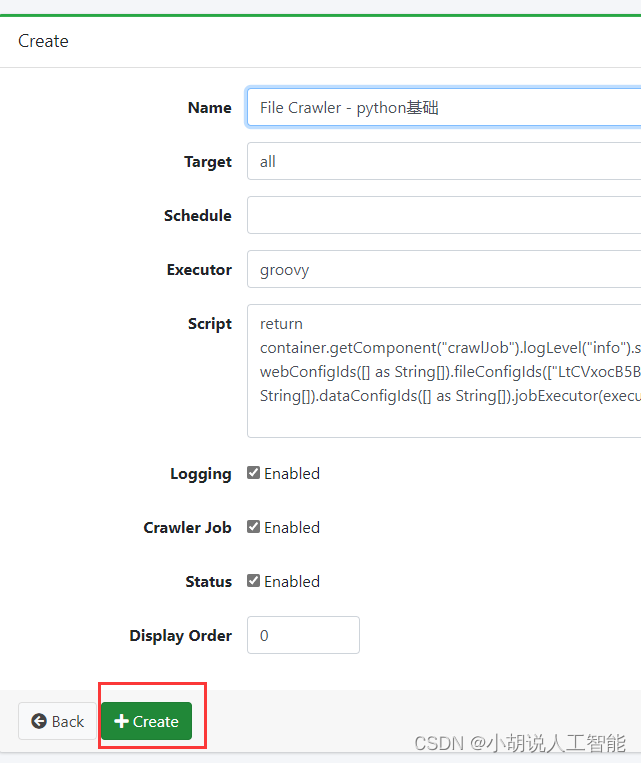
- 其余选项保持默认. 下滚至最下方点击Create
-
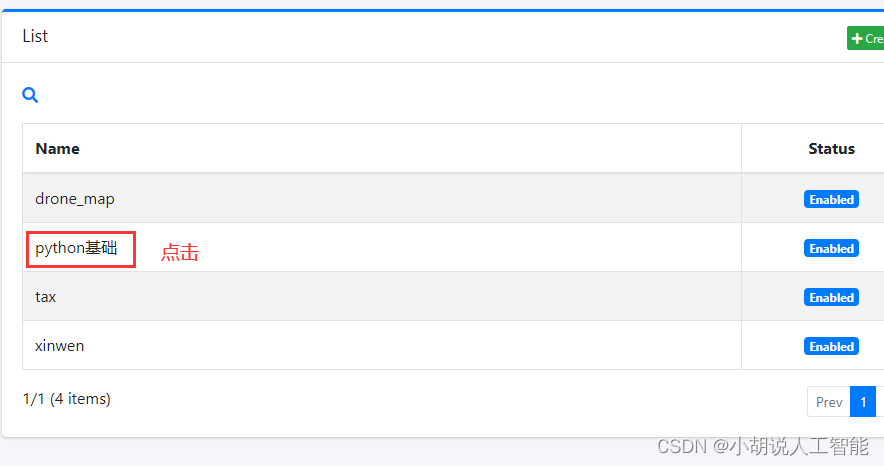
自动返回File System页面. 点击刚才创建的选项(自己输入的Name)
-
点击Create new job. 点击Create
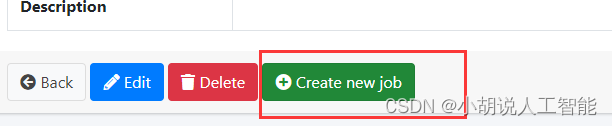
-
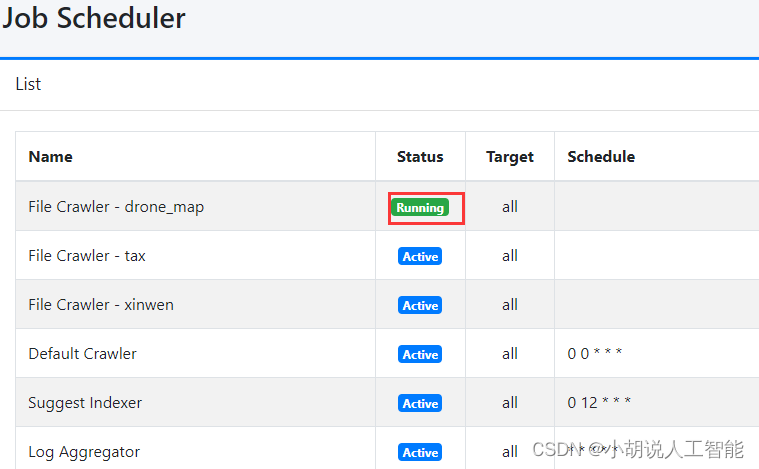
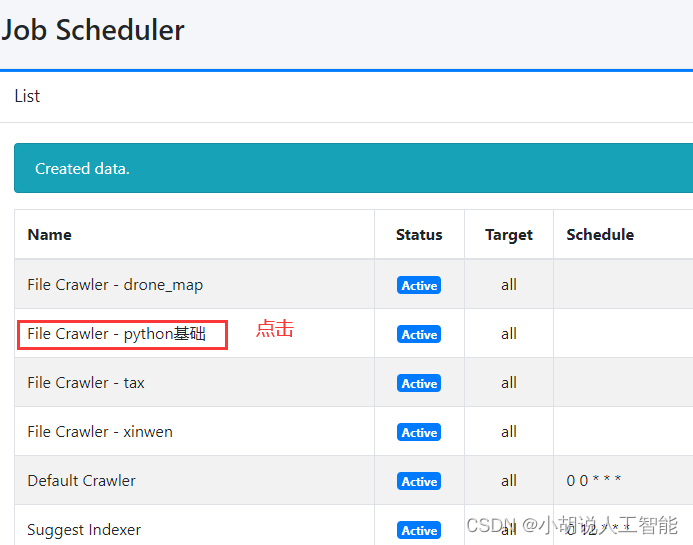
进入侧边栏的System内的Scheduler. 可以看到很多任务
- 目录的前面可以看到刚刚创建的job(示例:File Crawler - pdf search). 点击进入
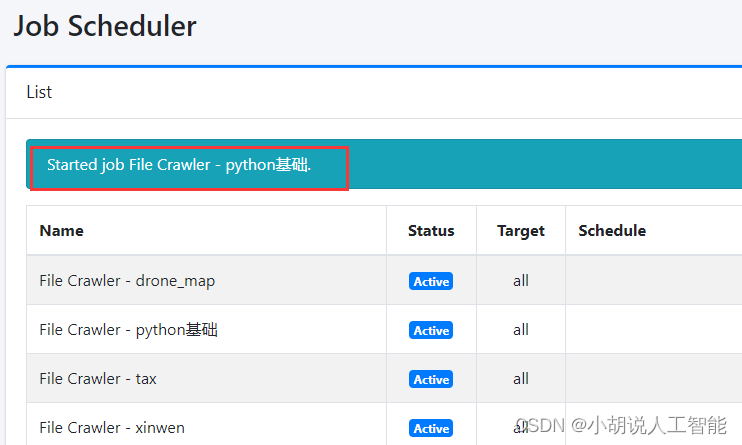
- 点击Start now. 刷新界面即可看到该任务正在运行. running
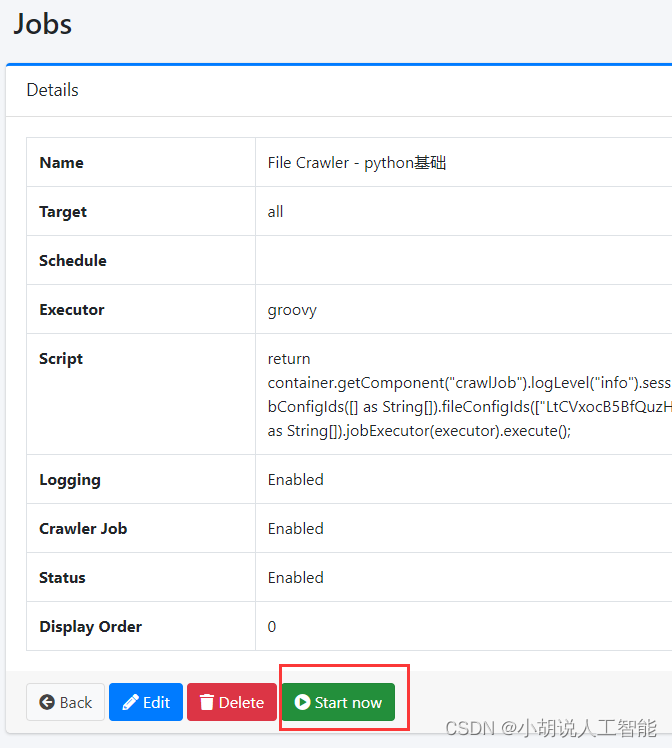
接着就能在知识库中进行测试了,下面这就表示已经导入到知识库了,右上角打开知识库,就能根据知识库来回答相关问题了:

参考资料
闻达:一个大规模语言模型调用平台
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。