前两篇文章介绍了安装,此篇文章算是一个简单的进阶应用吧!它是在Windows下通过Selenium+Python实现自动访问Firefox和Chrome并实现搜索截图的功能。
[Python爬虫] 在Windows下安装PhantomJS和CasperJS及入门介绍(上)
[Python爬虫] 在Windows下安装PIP+Phantomjs+Selenium
自动访问Firefox
可以参照前文安装Selenium环境,目前Selenium这个用于Web应用程序测试的工具支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。但是由于Firefox是默认安装路径,webdriver可以正常访问它,而Chrome和IE需要设置driver路径。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import sys
reload(sys)
sys.setdefaultencoding('gb18030')
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
assert "百度" in driver.title
elem = driver.find_element_by_name("wd")
elem.send_keys("Eastmount")
elem.send_keys(Keys.RETURN)
assert "谷歌" in driver.title
driver.save_screenshot('baidu.png')
driver.close()
driver.quit()
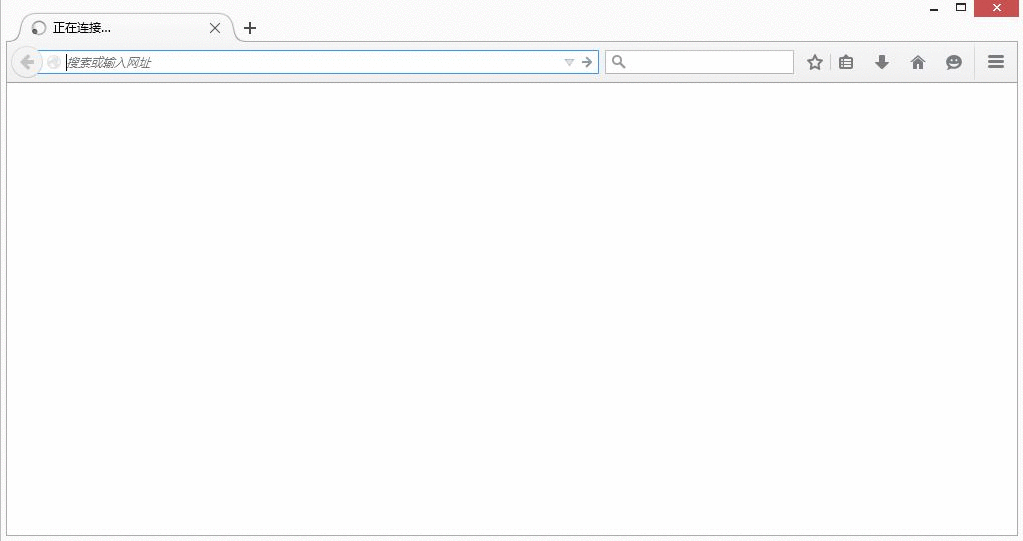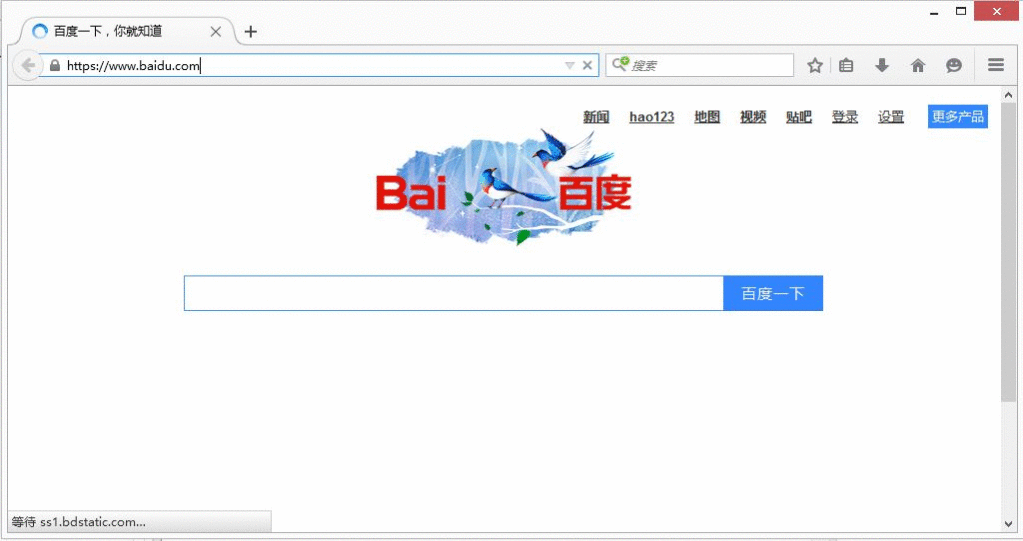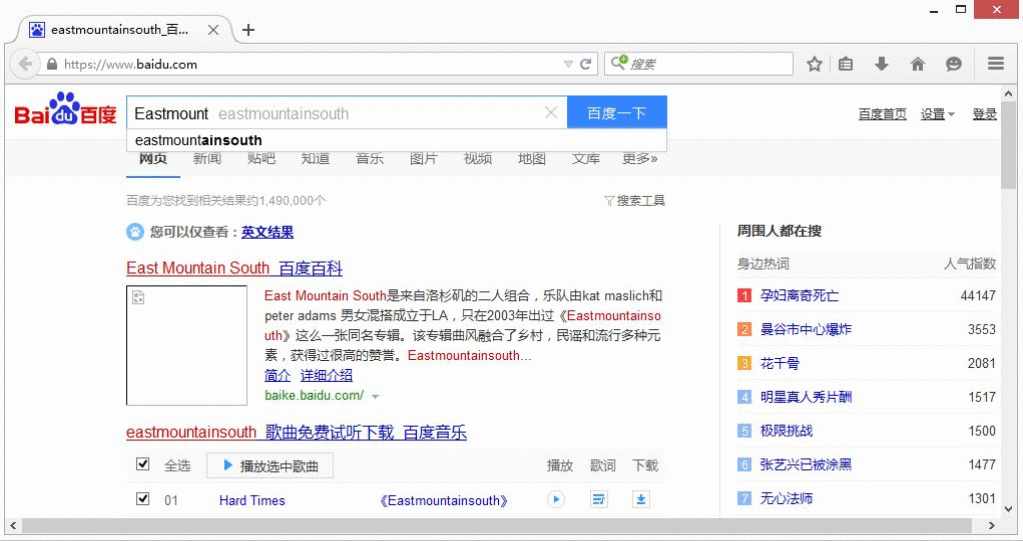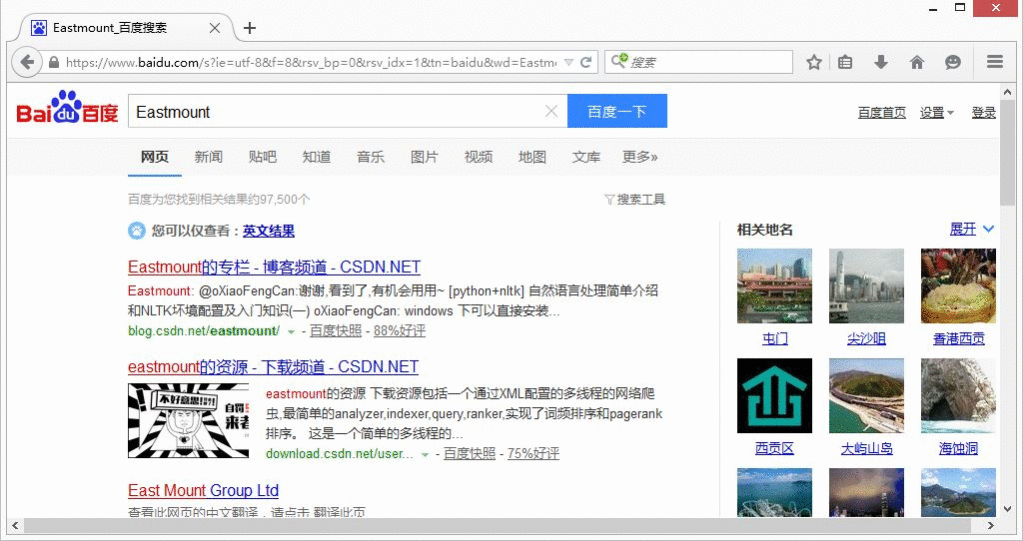
运行效果如下图所示,自动调用Firefox浏览器搜索,同时输出断言错误:
assert "谷歌" in driver.title AssertionError
源码分析
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import sys
首先导入Selenium.webdriver模板,它提供了webdriver的实现方法,目前支持这些方法的有Firefox、Chrome、IE和Remote。同时导入Keys类,它提供了操作键盘的快捷键,如RETURE、F1、ALT等。最后导入sys主要是设置编码方式。
reload(sys)
sys.setdefaultencoding('gb18030')
由于汉语中可能会遇到错误:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 33
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb0 in position 35
所以此处转换成gb编码,该篇不重点介绍了。
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
创建Firefoxwebdriver实例。其中Firefox最简单,其他Chrome还需要driver和配置路径。接下来通过driver.get()打开百度URL网页,webdriver会等待网页元素加载完成之后才把控制权交回脚本。但是,如果要打开了页面在加载的过程中包含了很多AJAX,webdriver可能无法准确判断页面何时加载完成。
assert "百度" in driver.title
assert "谷歌" in driver.title
接下来使用断言判断文章的标题Title是否包含“百度”和“谷歌”。对应的标题是“百度一下,你就知道”,所以其中“百度”包括,而“谷歌”会出现断言报错。
同时提交页面并获得返回结果,为了判断结果是否成功返回也可以使用断言。
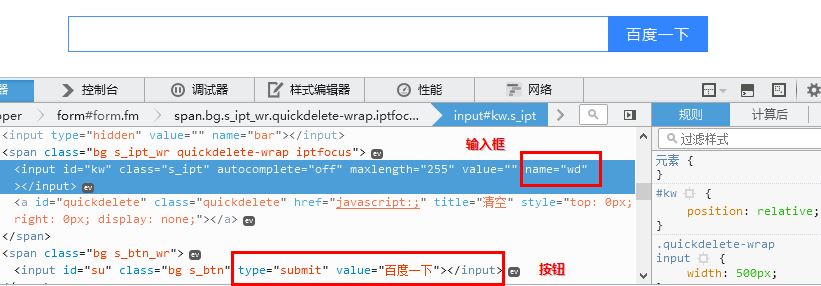
elem = driver.find_element_by_name("wd")
webdriver提供了很多如find_element_by_*的方法来匹配要查找的元素。如利用name属性查找方法find_element_by_name来定位输入框,审查元素name=wd。
元素定位方法可以参考官网:
Locating Elements
elem.send_keys("Eastmount")
elem.send_keys(Keys.RETURN)
send_keys方法可以用来模拟键盘操作,相当于是在搜索框中输入“Eastmount”再按回车键搜索。但首先要从selenium.webdriver.common.keys导入Keys类。
driver.save_screenshot('baidu.png')
driver.close()
driver.quit()
最后是调用save_screenshot进行截图,但是图片是过程中的,怎样获取最后加载的图片呢?同时,操作完成并关闭浏览器。当然,也可以调用quit()方法,两者的区别在于:quit()方法会退出浏览器,而close()方法只是关闭页面,但如果只有一个页面被打开,close()方法同样会退出浏览器。
自动访问Chrome
首先下载chromedriver并置于Chrome安装目录。可能会遇到错误:
WebDriverException: Message: 'chromedriver' executable needs to be in PATH.参考官网解决方法:How to use chromedriver,我采用的是设置driver环境。
代码如下:
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
chromedriver = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.send_keys("selenium")
elem.send_keys(Keys.RETURN)
assert "Google" in driver.title
driver.close()
driver.quit()
需要放置chromedriver如下路径,同时可以通过代码设置。但是由于我的Chrome可能Bug一直未修复,总是打开错误。
driver = webdriver.Chrome(executable_path="G:\chromedriver.exe")
参考资料: