1.网站
输入搜索内容,获取搜索结果,进行保存
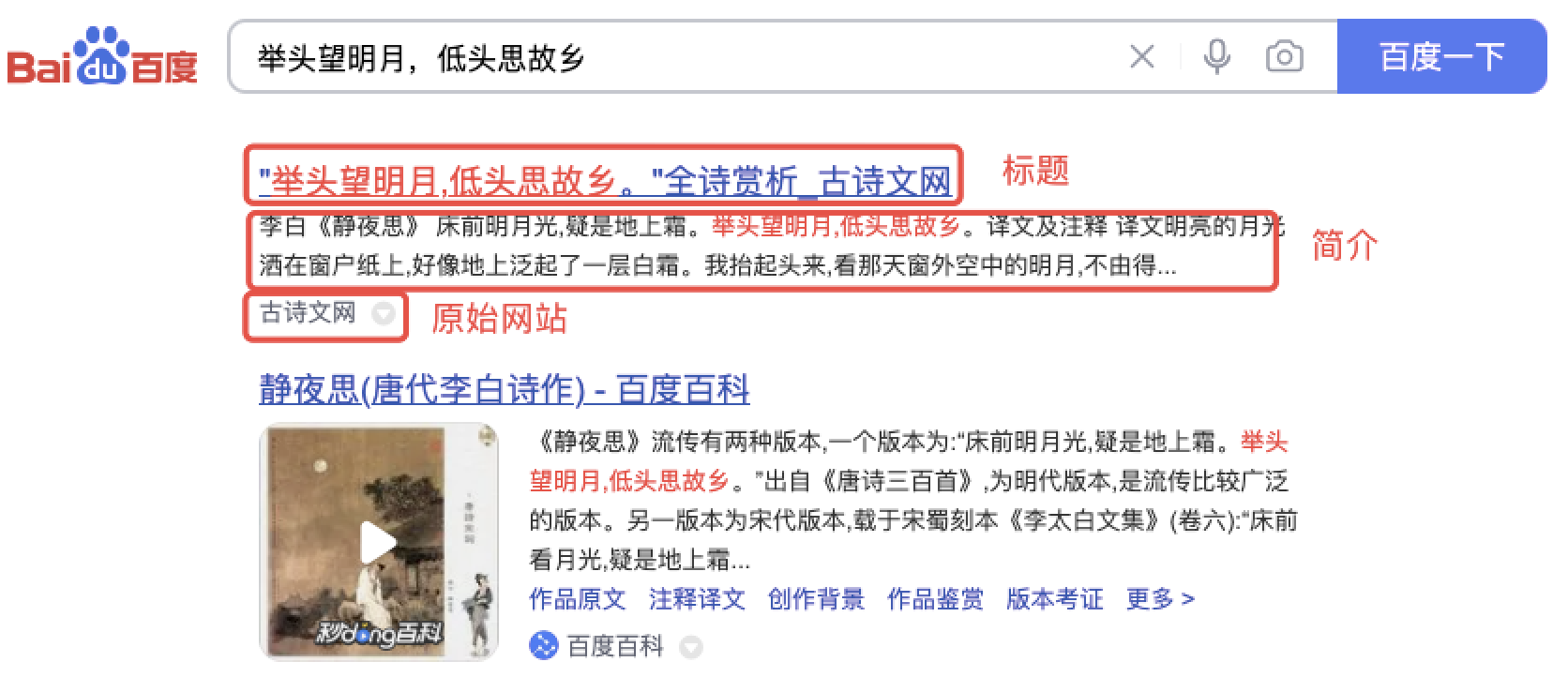
把内容整理后保存到mysql数据库,保存字段:
关键字、标题、真实网址、简介、原网站名称
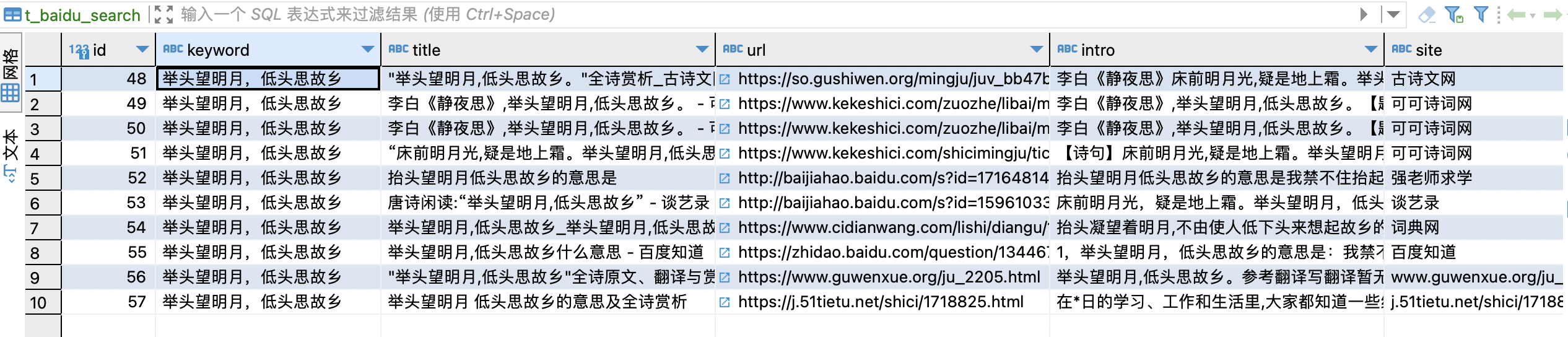
2.爬取结果
3.编写爬虫
爬虫使用scrapy框架编写,分布式、多线程
编写Items
class BaiduSearchItem(scrapy.Item):
# 关键词
keyword = scrapy.Field()
# 标题
title = scrapy.Field()
# 真实链接
url = scrapy.Field()
# 简介
intro = scrapy.Field()
# 网站名称
site = scrapy.Field()
3.1添加管道
class BaiduSearchPipeline:
def open_spider(self, spider):
if spider.name == 'baidu_search':
# 插入
self.insert_sql = "INSERT INTO t_baidu_search(keyword,title,url,intro,site) values(%s,%s,%s,%s,%s)"
pool = PooledDB(pymysql,
MYSQL['limit_count'],
host=MYSQL["host"],
user=MYSQL["username"],
passwd=MYSQL["password"],
db=MYSQL["database"],
port=MYSQL["port"],
charset=MYSQL["charset"],
use_unicode=True)
self.conn = pool.connection()
self.cursor = self.conn.cursor()
def close_spider(self, spider): # 在关闭一个spider的时候自动运行
if spider.name == 'baidu_search':
self.conn.close()
self.cursor.close()
def process_item(self, item, spider):
try:
if spider.name == 'baidu_search':
self.cursor.execute(self.insert_sql,
(item['keyword'], item['title'],
item['url'], item['intro'], item['site']))
self.conn.commit()
except BaseException as e:
print("baidu search错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")
return item
3.2添加解析
def parse(self, res):
html = res.text
page = res.meta['page']
keyword = res.meta['keyword']
soup = BeautifulSoup(html, 'html.parser')
temp_result_arr1 = soup.find_all(class_='result c-container new-pmd')
temp_result_arr2 = soup.find_all(
class_='result c-container xpath-log new-pmd')
temp_result_list = temp_result_arr1 + temp_result_arr2
item = BaiduSearchItem()
for result in temp_result_list:
title = result.find('a').text
href = result.find('a')['href']
real_url = tool.get_real_url(href)
try:
intro = result.find(class_='c-abstract').text
except:
try:
intro = result.find(class_='content-right_8Zs40').text
except:
intro = ""
continue
try:
site = result.find(class_='c-showurl c-color-gray').text
except:
try:
site = result.find(class_='c-color-gray').text
except:
site = ""
if site in WHITE_LIST:
print('白名单网站,不保存...', site)
continue
else:
print('不在白名单中,继续...', site)
item['keyword'] = keyword # 关键词
item['title'] = title # 标题
item['url'] = real_url # 真实链接
item['intro'] = intro.replace(' ', '') # 简介
item['site'] = site.replace(' ', '') # 网站名称
yield item
一次性把待爬关键词放到keywords.csv文件中,每个关键词放一行

4.源码