算法描述
C4.5算法是机器学习和数据挖掘领域中用于处理分类问题的算法。该算法是有监督学习类型的,即:给定一个数据集,每条记录都由一组特征来描述,每条记录仅属于一个标签,在给定的数据集上运行C4.5算法可以学习到一个从特征值到标签的映射,进而可以使用该映射去分类未知的(无标签)数据集。
C4.5算法源于ID3(iterative dichotomizers 3,迭代分解器系列算法的第三代),是一种决策树诱导算法。
所有的树诱导方法大都遵循一种递归模式。即,用根结点表示一个给定的数据集;然后,从根结点开始,在每个节点上测试一个特定的特征,并把不同的测试结果划分为不同的子数据集,并用子树表示;当子集成为“纯”的,即子集中所有数据都属于同一个标签,树停止生长。
可以测试的数据类型
- 布尔型,测试会诱导出两个分之;
- 类别型,就会进行多值测试;
- 连续型,测试就是 <= 或 > 某个阈值的形式。
如何对测试进行选择
C4.5算法使用增益(gain)、增益率(gain ratio)等信息论准则来对测试进行选择。增益被定义为“执行一个测试所导致的类别分布的熵的减少量”。通俗的说,就是数据由混乱变纯的程度。
这里记住相关公式即可:
熵: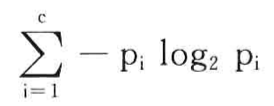
其中,c是标签的数量,pi为取到第i个标签的概率。
条件熵:
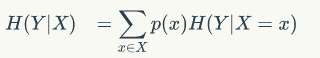
信息增益 = 熵 - 条件熵
但是信息增益有个缺点,会导致算法偏向于选择具有更多输出结果的特征。举个特例,对于一个值是unique的特征,显然不是作为决策树分类的好的特征选择,但这样的特征却具有最大的信息增益。因此C4.5使用信息增益率校正这一负面效应。
信息增益率:
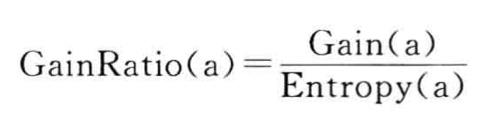
关于特征a的信息增益率 = 关于特征a的信息增益/a的信息熵。
特征a的信息熵仅取决于它的取值的概率分布,与标签无关;而特征a的信息增益是与标签有关的。
有了信息增益率,就可以从所有特征中挑选出第一个根结点开始分类了。
C4.5算法在创建决策树过程中,引入了子树复制问题,根源在于该算法遵循属性选择的贪婪策略。通常情况下,必须通过穷尽搜索才能获得最佳属性,这就要求生长出完全的树。
算法特性
1.决策树剪枝
为了避免生成的树模型过拟合训练数据,必须对树进行剪枝处理。
C4.5算法使用悲观剪枝(Pessimistic pruning,PEP)的方法:通过在训练数据集上的错误分类数量来估算未知数据上的错误率。通过递归计算目标节点的分之的错误率来获得该目标节点的错误率。如果子树被它的最佳叶节点替代后,在训练集上表现更佳,PEP方法就决定用该子树的最佳叶节点代换这颗子树。
这种方法是将叶节点的错误率e建模成服从(0,1)分布(伯努利分布)的随机变量,对于一个置信区间阈值CI(confidence intervals),存在e的一个上界
e
m
a
x
e_{max}
emax,使得
e
<
e
m
a
x
e<e_{max}
e<emax,以
1
−
C
I
1-CI
1−CI的概率成立(CI的默认值设定为0.25)。更进一步,可以用正态分布来逼近e(只要N足够大即可)。基于这些约定条件,C4.5算法的期望误差的上界为:

其中z的选择是基于理想置信区间,假设z是一个拥有零均值和单位方差的正态随机变量,也就是N(0,1)。
剪枝操作是一个单一的、自底向上、直到抵达根节点的遍历过程。在剪枝过程中,非叶节点的子树有三种可能:
- 错误率没有得到改善,维持原状
- 被表现更佳的子树替代
- 被叶节点替代
缺失值处理
面临三个主要问题:
- 在部分数据缺失个别特征值时,如何选出用于分裂树的合适属性?
- 为测试选定特征后,对于缺少该特征值的数据,无法分配到任何测试的结果子集中。这些数据如何参与到下一步树的生长中?
- 将模型用于新的数据时,可能会在树中遇到某个测试,如果该数据没有对应的特征,模型如何执行下去?
前两个问题涉及诱导树的学习,第三个问题发生在使用训练好的模型进行分类的阶段。
解决办法:
4. 在含缺失值的特征a上,进行特征选择准则的计算,包括:
- 忽略带有缺失值的数据
- 选用最常用的值或均值
- 对该特征的信息增益/信息增益率的计算问题,依据涉及缺失值的数据的比重折算
- 对训练数据中的缺失值进行“填充”,例如赋予一种独特的新值,或通过其他已知的特征尝试确定缺失值。
5. 在分裂过程中,有以下方法:
- 直接忽略该数据
- 为该数据缺失的该特征取一个常用值,从而进行数据划分
- 将该数据切分后,赋给每个子数据集,不同子数据集得到该数据的份额同其他已知属性的数据的数量成正比
- 直接将该数据赋给所有子数据集
- 为该特征缺失的情况专门建一个分之
- 确定该特征最可能的值,然后赋给相关的子集数据集
- 不再进行测试,将最有可能的类别赋给该数据
记得关注我的微信公众号