java面试汇总
基础篇
1、一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制?
可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致。
2、Java有没有goto?
java中的保留字,现在没有在java中使用。
3、说说&和&&的区别。
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false。
&&还具有短路的功能,即如果第一个表达式为false,则不再计算第二个表达式,例如,对于if(str != null && !str.equals(“”))表达式,当str为null时,后面的表达式不会执行,所以不会出现NullPointerException如果将&&改为&,则会抛出NullPointerException异常。If(x==33 & ++y>0) y会增长,If(x==33 && ++y>0)不会增长
&还可以用作位运算符,当&操作符两边的表达式不是boolean类型时,&表示按位与操作,我们通常使用0x0f来与一个整数进行&运算,来获取该整数的最低4个bit位,例如,0x31 & 0x0f的结果为0x01。
4、switch语句能否作用在byte上,能否作用在long上,能否作用在String上?
在switch(expr1)中,expr1只能是一个整数表达式或者枚举常量,整数表达式可以是int基本类型或Integer包装类型,由于,byte,short,char都可以隐含转换为int,所以,这些类型以及这些类型的包装类型也是可以的。显然,long和String类型都不符合switch的语法规定,并且不能被隐式转换成int类型,所以,它们不能作用于swtich语句中。
5、short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1 += 1;有什么错?
对于short s1 = 1; s1 = s1 + 1; 由于s1+1运算时会自动提升表达式的类型,所以结果是int型,再赋值给short类型s1时,编译器将报告需要强制转换类型的错误。
对于short s1 = 1; s1 += 1;由于 += 是java语言规定的运算符,java编译器会对它进行特殊处理,因此可以正确编译。
6、char型变量中能不能存贮一个中文汉字?为什么?
char型变量是用来存储Unicode编码的字符的,unicode编码字符集中包含了汉字,所以,char型变量中当然可以存储汉字啦。不过,如果某个特殊的汉字没有被包含在unicode编码字符集中,那么,这个char型变量中就不能存储这个特殊汉字。补充说明:unicode编码占用两个字节,所以,char类型的变量也是占用两个字节。
7、使用final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?
使用final关键字修饰一个变量时,是指引用变量不能变,引用变量所指向的对象中的内容还是可以改变的。
例如,对于如下语句:
final StringBuffer a=new StringBuffer("immutable");
执行如下语句将报告编译期错误:
a=new StringBuffer("");
但是,执行如下语句则可以通过编译:
a.append(" broken!");
有人在定义方法的参数时,可能想采用如下形式来阻止方法内部修改传进来的参数对象:
public void method(final StringBuffer param){
}
实际上,这是办不到的,在该方法内部仍然可以增加如下代码来修改参数对象:
param.append("a");
8、"=="和equals方法究竟有什么区别?
“==”操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用==操作符。
如果一个变量指向的数据是对象类型的,那么,这时候涉及了两块内存,对象本身占用一块内存(堆内存),变量也占用一块内存(栈内存),例如Objet obj = new Object();变量obj是一个内存,new Object()是另一个内存,此时,变量obj所对应的内存中存储的数值就是对象占用的那块内存的首地址。对于指向对象类型的变量,如果要比较两个变量是否指向同一个对象,即要看这两个变量所对应的内存中的数值是否相等,这时候就需要用==操作符进行比较。
equals方法是用于比较两个独立对象的内容是否相同,就好比去比较两个人的长相是否相同,它比较的两个对象是独立的。例如,对于下面的代码:
String a=new String("foo");
String b=new String("foo");
两条new语句创建了两个对象,然后用a,b这两个变量分别指向了其中一个对象,这是两个不同的对象,它们的首地址是不同的,即a和b中存储的数值是不相同的,所以,表达式a==b将返回false,而这两个对象中的内容是相同的,所以,表达式a.equals(b)将返回true。
在实际开发中,我们经常要比较传递进行来的字符串内容是否等,例如,String input = …;input.equals(“quit”),许多人稍不注意就使用==进行比较了,这是错误的,记住,字符串的比较基本上都是使用equals方法。
如果一个类没有自己定义equals方法,那么它将继承Object类的equals方法,Object类的equals方法的实现代码如下:
boolean equals(Object o){
return this==o;
}
这说明,如果一个类没有自己定义equals方法,它默认的equals方法(从Object 类继承的)就是使用==操作符,也是在比较两个变量指向的对象是否是同一对象,这时候使用equals和使用==会得到同样的结果,如果比较的是两个独立的对象则总返回false。如果你编写的类希望能够比较该类创建的两个实例对象的内容是否相同,那么你必须覆盖equals方法,由你自己写代码来决定在什么情况即可认为两个对象的内容是相同的。
9、静态变量和实例变量的区别?
在语法定义上的区别:静态变量前要加static关键字,而实例变量前则不加。
在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名来引用。
例如,对于下面的程序,无论创建多少个实例对象,永远都只分配了一个staticVar变量,并且每创建一个实例对象,这个staticVar就会加1;但是,每创建一个实例对象,就会分配一个instanceVar,即可能分配多个instanceVar,并且每个instanceVar的值都只自加了1次。
public class VariantTest{
public static int staticVar = 0;
public int instanceVar = 0;
public VariantTest(){
staticVar++;
instanceVar++;
System.out.println(“staticVar=” + staticVar + ”,instanceVar=” + instanceVar);
}
}
10、是否可以从一个static方法内部发出对非static方法的调用?
不可以。因为非static方法是要与对象关联在一起的,必须创建一个对象后,才可以在该对象上进行方法调用,而static方法调用时不需要创建对象,可以直接调用。也就是说,当一个static方法被调用时,可能还没有创建任何实例对象,如果从一个static方法中发出对非static方法的调用,那个非static方法是关联到哪个对象上的呢?这个逻辑无法成立,所以,一个static方法内部不可以发出对非static方法的调用。
11、Integer与int的区别
int是java提供的8种原始数据类型之一。Java为每个原始类型提供了封装类,Integer是java为int提供的封装类。int的默认值为0,而Integer的默认值为null,即Integer可以区分出未赋值和值为0的区别,int则无法表达出未赋值的情况,例如,要想表达出没有参加考试和考试成绩为0的区别,则只能使用Integer。在JSP开发中,Integer的默认为null,所以用el表达式在文本框中显示时,值为空白字符串,而int默认的默认值为0,所以用el表达式在文本框中显示时,结果为0,所以,int不适合作为web层的表单数据的类型。
在Hibernate中,如果将OID定义为Integer类型,那么Hibernate就可以根据其值是否为null而判断一个对象是否是临时的,如果将OID定义为了int类型,还需要在hbm映射文件中设置其unsaved-value属性为0。
另外,Integer提供了多个与整数相关的操作方法,例如,将一个字符串转换成整数,Integer中还定义了表示整数的最大值和最小值的常量。
12、请说出作用域public,private,protected,以及不写时的区别
这四个作用域的可见范围如下表所示。
说明:如果在修饰的元素上面没有写任何访问修饰符,则表示friendly。
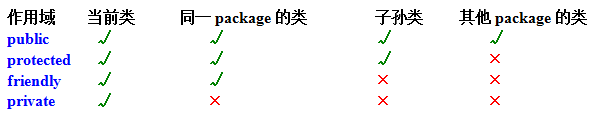
13、Overload和Override的区别。Overloaded的方法是否可以改变返回值的类型?
Overload是重载的意思,Override是覆盖的意思,也就是重写。
重载Overload表示同一个类中可以有多个名称相同的方法,但这些方法的参数列表各不相同(即参数个数或类型不同)。
重写Override表示子类中的方法可以与父类中的某个方法的名称和参数完全相同,通过子类创建的实例对象调用这个方法时,将调用子类中的定义方法,这相当于把父类中定义的那个完全相同的方法给覆盖了,这也是面向对象编程的多态性的一种表现。子类覆盖父类的方法时,只能比父类抛出更少的异常,或者是抛出父类抛出的异常的子异常,因为子类可以解决父类的一些问题,不能比父类有更多的问题。子类方法的访问权限只能比父类的更大,不能更小。如果父类的方法是private类型,那么,子类则不存在覆盖的限制,相当于子类中增加了一个全新的方法。
至于Overloaded的方法是否可以改变返回值的类型这个问题,要看你倒底想问什么呢?这个题目很模糊。如果几个Overloaded的方法的参数列表不一样,它们的返回者类型当然也可以不一样。但我估计你想问的问题是:如果两个方法的参数列表完全一样,是否可以让它们的返回值不同来实现重载Overload?这是不行的,我们可以用反证法来说明这个问题,因为我们有时候调用一个方法时也可以不定义返回结果变量,即不要关心其返回结果,例如,我们调用map.remove(key)方法时,虽然remove方法有返回值,但是我们通常都不会定义接收返回结果的变量,这时候假设该类中有两个名称和参数列表完全相同的方法,仅仅是返回类型不同,java就无法确定编程者倒底是想调用哪个方法了,因为它无法通过返回结果类型来判断。
override可以翻译为覆盖,从字面就可以知道,它是覆盖了一个方法并且对其重写,以求达到不同的作用。对我们来说最熟悉的覆盖就是对接口方法的实现,在接口中一般只是对方法进行了声明,而我们在实现时,就需要实现接口声明的所有方法。除了这个典型的用法以外,我们在继承中也可能会在子类覆盖父类中的方法,在覆盖要注意以下的几点:
1、覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2、覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3、覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4、被覆盖的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
overload对我们来说可能比较熟悉,可以翻译为重载,它是指我们可以定义一些名称相同的方法,通过定义不同的输入参数来区分这些方法,然后再调用时,VM就会根据不同的参数样式,来选择合适的方法执行。在使用重载要注意以下的几点:
- 在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int,float),但是不能为fun(int,int));
- 不能通过访问权限、返回类型、抛出的异常进行重载;
- 方法的异常类型和数目不会对重载造成影响;
- 对于继承来说,如果某一方法在父类中是访问权限是priavte,那么就不能在子类对其进行重载,如果定义的话,也只是定义了一个新方法,而不会达到重载的效果。
14、has a与is a的区别
is-a表示的是属于的关系。比如兔子属于一种动物(继承关系)。
has-a表示组合,包含关系。比如兔子包含有腿,头等组件。
15、ClassLoader如何加载class?
jvm里有多个类加载器,每个类加载器可以负责加载特定位置的类,例如,bootstrap类加载负责加载jre/lib/rt.jar中的类, 我们平时用的jdk中的类都位于rt.jar中。extclassloader负责加载jar/lib/ext/*.jar中的类,appclassloader负责classpath指定的目录或jar中的类。除了bootstrap之外,其他的类加载器本身也都是java类,它们的父类是ClassLoader。
16、分层设计的好处
把各个功能按调用流程进行了模块化,模块化带来的好处就是可以随意组合,举例说明:如果要注册一个用户,流程为显示界面并通过界面接收用户的输入,接着进行业务逻辑处理,在处理业务逻辑又访问数据库,如果我们将这些步骤全部按流水帐的方式放在一个方法中编写,这也是可以的,但这其中的坏处就是,当界面要修改时,由于代码全在一个方法内,可能会碰坏业务逻辑和数据库访问的码,同样,当修改业务逻辑或数据库访问的代码时,也会碰坏其他部分的代码。分层就是要把界面部分、业务逻辑部分、数据库访问部分的代码放在各自独立的方法或类中编写,这样就不会出现牵一发而动全身的问题了。这样分层后,还可以方便切换各层,譬如原来的界面是Swing,现在要改成BS界面,如果最初是按分层设计的,这时候不需要涉及业务和数据访问的代码,只需编写一条web界面就可以了。
分层的好处:
1.实现了软件之间的解耦;
2.便于进行分工
3.便于维护
4.提高软件组件的重用
5.便于替换某种产品,比如持久层用的是hibernate,需要更换产品用toplink,就不用该其他业务代码,直接把配置一改。
6.便于产品功能的扩展。
7.便于适用用户需求的不断变化
17、hashCode方法的作用?
hashcode这个方法是用来鉴定2个对象是否相等的。
equals方法和hashCode方法这2个方法都是用来判断2个对象是否相等的,但是他们是有区别的。
一般来讲,equals这个方法是给用户调用的,如果你想判断2个对象是否相等,你可以重写equals方法,然后在代码中调用,就可以判断他们是否相等了。简单来讲,equals方法主要是用来判断从表面上看或者从内容上看,2个对象是不是相等。举个例子,有个学生类,属性只有姓名和性别,那么我们可以认为只要姓名和性别相等,那么就说这2个对象是相等的。
hashcode方法一般用户不会去调用,比如在hashmap中,由于key是不可以重复的,他在判断key是不是重复的时候就判断了hashcode这个方法,而且也用到了equals方法。这里不可以重复是说equals和hashcode只要有一个不等就可以了!所以简单来讲,hashcode相当于是一个对象的编码,就好像文件中的md5,他和equals不同就在于他返回的是int型的,比较起来不直观。我们一般在覆盖equals的同时也要覆盖hashcode,让他们的逻辑一致。举个例子,还是刚刚的例子,如果姓名和性别相等就算2个对象相等的话,那么hashcode的方法也要返回姓名的hashcode值加上性别的hashcode值,这样从逻辑上,他们就一致了。
要从物理上判断2个对象是否相等,用==就可以了,如果两个对象的物理(内存)地址相等,那么这两个对象肯定就是同一个对象。
18、什么是AOP?
1.AOP概念介绍
所谓AOP,即Aspect orientied program,就是面向方面(切面)的编程。
面向切面编程Aspect-Orlented-Programming,即AOP是对面向对象的思维方式的有力补充。
AOP的好处是可以动态地添加和删除在切面上的逻辑而不影响原来的执行代码
2.解释什么是方面(切面)
所谓方面(切面),指的是贯穿到系统的各个模块中的系统一个功能就是一个方面(切面),比如,记录日志,统一异常处理,事务处理,权限检查,这些功能都是软件系统的一个面,而不是一点,在各个模块中都要出现。
3.什么是面向方面编程
把系统的一个方面的功能封装成对象的形式来处理就是面向方面(切面)编程
4.怎么进行面向方面编程
把功能模块对应的对象作为切面嵌入到原来的各个系统模块中,采用代理技术,代理会调用目标,同时把切面功能的代码(对象)加入进来。所以,用spring配置代理对象时只要要配两个属性,分别表示目标和切面对象(Advisor)。
19.谈谈你对mvc的理解
MVC是Model—View—Controler的简称。即模型—视图—控制器。MVC是一种设计模式,它强制性的把应用程序的输入、处理和输出分开。
MVC中的模型、视图、控制器它们分别担负着不同的任务。
- 视图: 视图是用户看到并与之交互的界面。视图向用户显示相关的数据,并接受用户的输入。视图不进行任何业务逻辑处理。
- 模型: 模型表示业务数据和业务处理。相当于JavaBean。一个模型能为多个视图提供数据。这提高了应用程序的重用性
- 控制器: 当用户单击Web页面中的提交按钮时,控制器接受请求并调用相应的模型去处理请求。然后根据处理的结果调用相应的视图来显示处理的结果。
MVC的处理过程:首先控制器接受用户的请求,调用相应的模型来进行业务处理,并返回数据给控制器。控制器调用相应的视图来显示处理的结果。并通过视图呈现给用户。
提升篇
1、springCloud微服务通过什么方式实现分布式开发
现在的应用越来越复杂,并且并发量很大对于服务器而言压力会很大,对于垂直系统而言,会把好多不相关的业务分成单独的一个应用,但是业务比较复杂了,难免就设计到服务之间的调用,所以才会有了分布式系统的概念。
它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。
通过Eureka服务发现与注册中心实现服务的集群、通过Ribbon实现负载均衡通过用@Configuratio的配置类通过@LoadBalance引入负载均衡还有相应的一些负载均衡的算法、Feign整合了Ribbon和Eureka还有Hystrix。一般还要搭配zuul实现不同集群服务之间的调用。一般开发中都通过Feign进行服务间的调用,因为原先的restTemplate要进行http-url的拼接比较的麻烦
在要调用的集群服务提供的接口地方通过在自己定义的接口上标注@FeignClient注解来获取集群服务的方法实现,里面的value就是服务提供者的在yml文件中通过application name对应项目名就可以知道事那个相应的集群服务了,然后通过zuul的网关路由设置再yml文件中有个route还有个serviceId进行服务调用的请求映射,在EureKa的客户端的启动类上增加@EnableFeignClients注解开Feign服务即可。调用的时候可以直接注入@Autowired自己相应的接口,由Feign通过value去集群的服务中找到该接口中方法的实现即可。
假如你的Service是单独编译一个jar包,那么在使用@EnableFeignClients注解时需要指定basePackages的值。
2、springCloud如何实现解耦
当一个项目的业务非常非常的复杂的时候,并且某几天突然并发量很大,靠单一一个程序还有服务器是很难支持的、所以才有了springCloud分布式开发了、把一些公共的业务代码独立的作为一个模块提取出来了、而且采用了服务集群在大并发情况下采用了负载均衡等方法实现了分布式的开发。
Feign还可以搭配hystrix实现解耦,可以单独的创建一个公共方法项目,然后再这个公共方法的项目之中通过@FeignClient标注的接口来确定是哪个集群的服务,然后将所有的公共方法都放在一个类中并实现FallbackFactory通过实现里面的create方法,将Feign调用的方法以及自定义的放在写在create中实现解耦的、把所有的公共代码都抽取出来,这样hystrix一些降级和异常处理时候的友好提示交互页面不用再织入到业务代码中了。
3、Eureka是什么、如何配置实现集群
为什么要集群,因为高并发扛不住,通过集群可以减轻每个服务注册中心的压力。
Eureka是Netflix开发的服务发现框架,本身是一个基于Http的REST的服务,像Dubbo则是RPC,Eureka实现了服务注册与发现。
默认情况,如果服务注册中心再一段时间内没有接收到某个微服务实例的心跳,服务注册中心会注销该实例(默认90秒)。
Eureka包含两个组件,一个是客户端的一个是服务器的,标注@EnableEurekaClient注解的启动类启动后会向Eureka Server发送心跳,如果多个心跳周期没有接收该节点的心跳,则会在服务注册表中进行移除。除此之外,client还有个内置的基于轮询算法的负载均衡器。并在yml文件中设置客户端实例名称 instance appname,通过client defaultZone把所有服务注册中心的交互地址表明,除此之外,client还有个内置的基于轮询算法的负载均衡器。
在启动类中标注@EnableEurekaServer表明该应用为注册服务中心、各个服务注册节点启动后会在客户端服务注册列表中看到,如果要集群的话还要修改yml中eureka client 的register-with-eureka设置为false,不向自己注册,fetch-registry false也不向自己检索。service-url 暴露其他服务祖册中心即可。
4、Rest与RPC的区别
操作对象即资源、对外提供了Post、get等方法可以通过,通过http+json的方式在对外暴露接口,对外提供服务方面rest比价简单和方便、http更加的规范,所有的语言都支持http协议。
RPC效率更高,而且不用考虑底层实现的细节。
5、有那些负载均衡的算法
RetryRule(重试机制)、BestAvailableRule选择一个最小并发请求的server、RoundRobinRule轮询方式、RandomRule 随机选择
6、通过什么方式进行服务间的调用
通过Ribbon实现负载均衡通过用@Configuratio的配置类通过@LoadBalance引入restTemplate,然后再IRule中retrun对应的负载均衡的算法。
Feign整合了Ribbon的方式进行服务之间的调用、在Eureka的客户端的启动类增加@EnableFeignClients注解,然后再配置类中进行Ribbon的相应配置。可以吧要调用的公共方法都提出来实现解耦,并在要调用的方法的接口上面标注@FeignClient注解调用yml文件中通过spring application配置的各个集群的微服务应用名称,然后将这个接口注入到controller即可实现服务间方法的调用。一般情况下还要设置zuul路由网关的设置,在yml文件中设置zuul,有个path还有一个serviceId对应的就是映射的每个集群的项目名。调用的时候就是通过该映射获取服务,然后通过springMVC进行服务调用即可。
Ribbon可以从Eureka Server中获取服务提供者列表信息,基于某一个负载均衡的算法请求某一个服务提供者实例。
7、zuul的配置
需要单独启一个项目,并且在启动类上标注@EnableZuulProxy,然后再yml文件中设置前缀,和访问的映射path以及serviceId每个集群项目的应用名即可,这样就可以避免了直接通过项目名来调用服务安全的问题了,通过zuul还有一定的身份过滤等功能提升安全性。
8、zull的过滤与身份验证
首先我们自定义的过滤类要继承ZuulFilter,然后重写里面的run方法等等,run方法就是过滤器具体要执行的逻辑,需要在配置文件中AccessFilter方法中return new 我们刚刚定义好的过滤类即可。
9、Hystrix怎么实现熔断服务和降级处理的呢
依赖有问题了,不会整体都有问题,不让用户的请求继续等待。在yml文件中增加 feign hystrix enabled:true。
在Eureka的客户端的启动类增加@EnableCircuitBreaker注解,然后就是提取出来的公共类@FeignClient注解中增加fallbackFactory参数并将实现了fallbackFactory的类作为指定类。里面有个create方法,在里面写服务出错时候的处理操作,进行解耦。可以在yml文件中设置超时时间 timeoutToMillSecond。
服务集群的监控,在监控项目的启动类上增加@EnableTurbine注解,然后再yml中配置turbine app-config指定要监控的应用名称即可。
10、什么是服务器的雪崩效应
当请求的服务无法访问,异常、超时的情况下,用户的请求将会被阻塞,如果这时候有多个用户同时都在请求这个服务,那么就会使得整个系统变得很卡最终会陷入了阻塞状态。
11、什么是Duubo
随着互联网的发展,网站的规模和并发量不断的扩大,常规的垂直架构应该无法应对了。Dubbo就是一个分布式框架,可以有效的治理并且保证系统能有条不紊的进行。
12、有几种架构
单一架构 ORM,只需要一个应用,所有的功能都能部署在一起。
垂直架构,访问量不断的增加,将应用拆分为互不相干的几个应用,web框架MVC。
分布式架构、垂直应用越来越多,应用之间不可避免的存在交互,将核心的业务抽离出来,独立的作为服务,形成稳定的服务中心,有Rest还有RPC两张分布式应用框架。
流动式计算机框架,当服务越来越多,容器的评估,小服务资源浪费的问题越来越明显,此时需要增加一个调度中心(SOA)基于访问压力实时管理集群容量,提高集群容器利用率和资源调度。
13、zookeeper是什么
zookeeper是Dubbo的服务注册中心,然后Dubbo服务到zookeeper中,在dubbo的配置文件,dubbo-demo-provider中进行配置。大概有dubbo:application 应用名用户计算依赖关系。dubbo:registry 使用zookeeper暴露的服务地址,dubbo:protocal 设置端口号,然后通过spring获取bean实现服务。context.start()
消费者服务之间的调用 dubbo:reference id interface为提供者的方法,然后通过spring的getBean方法获取服务,调用方法。
14、Dubbo服务集群与调用
在dubbo的配置文件中dubbo-demp-provider中使用zookeeper暴露的服务地址dubbo:registry address。然后通过dubbo协议在某个端口暴露服务 dubbo:protocol name port 。最后将service的实现类作为一个bean。 通过dubbo:service ref引用实现类的id interface声明需要暴露的服务接口,就可以发布dubbo服务了。最后通过dubbo:reference来消费暴露的服务 interface,最后通过new ClassPathXMLApplication获取配置文件实例,调用getBean方法获取消费者的id即可。
dubbo的集群只需要修改配置文件的端口号即可。
restTemplate进行服务之间的调用
springBoot通过在配置类@Configuration中通过@Bean定义的方式引入,也可以直接通过new RestTemplate方式获取实例来调用。
restTemplate.postForEntity(url,要传入的参数,返回值类型) postForObject() Object还不确定类型
restTemplate.getForEntity(url) getForObject(url,返回值类型) getForObjec()
JDK与JRE的区别
JDK是开发java应用的程序包用来将java文件编译成字节码文件,包含了JRE(java运行环境),还有client和server端,需要配置环境变量,还包括了一系列java命令,其实面对java开发人员的,开发之后还要进行编译调试,这时候就要用到jre了。
JRE java运行环境,执行编译后的字节码文件。被编译的字节码文件计算机不能读懂的,需要jvm处理后形成计算机语言传递给计算机处理,jvm就存于jre中。
所以当安装一个java程序需要jdk,要运行一个java程序就需要jre
JVM只有运行环境
请简要的说明一下JVM的内存分配与回收
java程序是交由JVM执行的,java程序具体的执行流程,java源码.java ---- 经过java的编译器为java的字节码文件.class -------交由jvm中类加载器和执行引擎来执行,在程序执行的过程中,jvm会用一段空间来存储程序执行期间所用到的数据和相关信息,这就是运行时数据区也是JVM的内存,对这片空间进行内存的分配与回收。
jvm的划分,通常被划分为程序计数器,java栈,本地方法栈,方法区和堆。
程序计数器和汇编语言中的物理概念上的cpu寄存器概念差不多,用来指示执行那条指令的。多线程是通过线程的轮流切换来获得CPU的执行时间,任何一个具体的时刻,一个cpu的内核只会执行一条线程中的指令,每个线程都需要自己独立的计数器,并且互相不干扰,程序计数器是每个线程所私有的。
java栈,当线程执行一个方法的时候,都会创建一个对应的栈帧,并将建立的栈帧压栈,方法执行之后便会出栈。每个线程执行的方法可能不同,每个线程都有一个自己的java栈并且互不干扰。
堆,用来存储对象本身和数组的,数组的引用存放在java栈中,堆是所有线程所共享的,jvm只有一个堆。
方法区,被线程所共享的区域,方法区存储了每个类的信息,包括了类名、方法名、字段名、静态变量、常量等等。方法区还有一个地方就是常量池,类和方法加载到jvm后,运行时常量池就被创建了
java什么是静态区、堆区、栈区、常量区
静态区保存全局变量和static变量的,静态区的内容在整个程序的生命周期内都存在的,由编译器在编译的时候分配。
堆区new操作符分配的内存,特点灵活空间比较大但容易出错。
栈区编译器会自动释放,保存局部变量的,栈上的内容只在函数范围内存在,当函数运行结束,这些内容也会自动被销毁,
常量区 常量字符,程序结束自动释放。
对volatile的解析
vscode的使用
eclipse的安装与eclipse的快捷键
eclipse有两种安装模式,一种是安装程序安装,另一种是下载不同功能项的eclipse压缩包,下载后手动解压即可。
安装程序安装:进入官网选择下载,下载完成后运行eclipse安装程序,安装项选择,选择【Eclipse IDE for Java EE Developers】然后点击下一步,选择安装目录并且选择创建快捷方式然后安装。安装完成后要选择接受协议才行,有时候eclipse需要指定的JDK版本才行。
也可以选择压缩包下载,进入官网选择DownLoad Packages,然后选择下载目录进行下载即可。下载好之后解压,选择eclipse.exe文件双击运行即可。
注意eclipse的安装目录必须全英文,否则后面找不到项目的根路径。
有时候eclipse启动的时候会有很多的验证,比较慢我们可以手动的取消,Windows - > Preferences -> Validation,点击“全部禁用(Disable All)”然后仅仅留下(Classpath Dependency Validator)类路径依赖验证即可。
取消某个项目的验证,properties中Builder中可以将JavaScript Validator或java的编译验证去掉即可。对某个文件取消验证,选择则某个文件右击Validate点击就可以了。
启动禁用Windows -> Preferences,键入“startup”,选择“Startup and Shutdown”,勾去你不需要的选项即可。
注意project-Build Automatically勾选之后才会编译最新的源码。
eclipse中JDK如何配置
windows的perferences中输入JRE然后有个Installed JREs选择Add里面的Standard VM找到JDK1.8的安装目录,即可设置全局的JDK。然后点击项目选择Build Path里面的Configure build path,里面有个Libraries右边有个Add Library选择JRE System Library把刚才设置的全局变量workspace default jre设置进去设置单个项目的JDK,然后就可以选择对应项目的编译版本了java Compiler。
右击项目,Project Facets选择web项目的java类编译版本java 1.8,如果和项目里面build path的jdk版本不一致,eclipse会报错。
也可以选择eclipse的全局编译环境Window ->preferences->java->compiler,选择编译版本,如果编译版本如果高于jdk的版本的时候会提示报错的,而且编译时jdk的版本也不能高于某个项目中build path的运行时jdk的版本。
设置某个项目的编译版本,右键–>Properties–>Java Compiler,选择对应的编译版本,如果选择了1.6那么java文件便编译为1.6的class文件了。
有时候web项目的problems中会莫名的报错,选择项目右键–>Properties–>Project Facets,然后设置java类的编译版本,如果java类的编译版本与build path中的jdk版本不一致就会报错了。
eclipse中Tomcat如何配置
全局也可以进行配置,在windows的perferences中输入server,找到tomcat的安装目录进行配置就可以进行设置了,同时也可以选择对应的JRE的版本。单个项目也可以引入tomcat右击选择build path在Libraries的Add Library 中选择server Runtime选择全局的配置即可。某些web项目需要依赖tomcat运行环境,点击Project Facets,在这里面就可以选择Runtimes中的tomcat版本了。
tomcat-service的设置双击server服务,将里面的的server locations设置为user tomcat installations然后将Deploy path设置为TOMCAT_HOME/webapps 。也可以在服务中去除项目的根路径,然后右击项目选择properties然后输入web,选择Web Project Setting即可。
有时候启动服务的时候会报错,首先将tomcat下的项目移除之后,右击clean之后,启动tomcat一次,如果能正常启动,之后再把项目放入服务中启动即可。
eclipse如何引入项目依赖
选择java项目,右击选择build path,选择project就可以引入其他项目了,同时切换到Libraries,选择Add JARS可以将一些额外的jar包引入项目。
同时如果是web项目引入其他代码工程的时候还要右击项目,选择Deployment Assembly,再引入一次,否则部署运行的时候可能会找不到依赖的jar包,然后就可以在server中看到项目所引入的依赖以及jar包了。
引入的jar包,在部署的时候会自动复制到WEB-INF/lib路径下,如果把jar包复制到该路径下的话,需要手动的build path --- Add to Build Path 去引入到项目中。
验证依赖,在tomcat的server服务中就可以看到几个项目已经关联发布了。同时web项目需要依赖运行环境,可以在Project Facets选择Runtimes。
eclipse中Maven的配置
首先要在环境变量中设置一个M2_HOME的环境变量,配置项就是Maven中有bin的那一级目录。然后在window-perferences中搜索Maven,在installation中同样找到Maven的bin安装路径。在user settings中找到Maven的setting文件,setting文件中可以设置本地的仓库localRepository以及远程仓库镜像或阿里云镜像,本地仓库如果没有jar包的话回去远程仓库获取的。maven配置最好勾选上下载源代码,然后update project之后会自动下载了。
配置Maven的时候最好下载Maven的源代码,
有时候运行Maven项目的时候会报错,右击项目选择project references查看有没有引入Maven依赖,如果没有右击项目选择Maven选项,update project即可。
有时候Maven install的时候也会报错,因为maven需要javac来编译项目,也就是需要jdk,而eclipse只需要jre就可以编译java文件了。Window->preferences->Java->Installed JREs,更改直接Add->Standard VM,点击directory,选择相应的jdk路径确定即可。
tomcat项目的部署
mysql的安装与卸载
mysql有两种方式进行安装,一种是通过安装包进行安装一直下一步然后有个端口号,编码和默认root用户名的密码的设置就可以安装mysql了。
mysql还有一种方式就是通过zip压缩包解压进行安装,首先需要解压然后再环境变量中将mysql解压的bin安装目录设置进去,之后以管理员的方式运行cmd,进入mysql的bin目录,然后输入mysqld -install安装mysql也可以删除安装的mysql 通过mysqld -remove,然后不要急着启动mysql 通过net start mysql,启动之后也可以关闭服务,net stop mysql。第一次登陆的时候要重置密码先进入mysql的data目录,然后mysql -uroot --skip-password跳过密码登陆,然后通过set password for root@localhost = password('root');设置root的密码。然后退出到bin目录启动mysql服务,然后mysql -uroot -p 就可以登陆mysql了。
mysql的5.7的err文件下还有个随机密码,否则还是一样第一次登陆不了的。
mysql的卸载涉及到注册表的问题,首先输入net stop mysql禁用mysql服务。
开始删除首先控制面板中删除mysql,然后删除注册表中所有mysql的选项,然后删除C:\ProgramData\MySQL下的文件夹即可。
sqlyog的安装,同理点击下一步,然后选择安装的路径,安装就好,登录的时候通过注册表破解注册就行了。有时候sqlyog第一次登陆的时候会报错,是因为没有给root或者其他用户赋权限后就可以登陆了。
oracle的安装
mysql导入导出脚本
cmd下先进入mysql所在的bin文件下,然后输入mysqldump -t 数据库名 -uroot -proot 表名 --where = " " >导出指定文件夹下的sql文件,导入导出的sql文件还是要先进入bin目录,然后进入mysql 输入mysql -u 用户名 -p 然后输入密码进入,之后输入use 数据库名 然后source 要导入到sql文件名即可导入文件。
通过sqlyog可以右键点击表选择备份/导出 备份表为sql转储。
导入,选择数据库点击导入-执行sql脚本即可。
大数据下通过sqlyog导入会有一定的问题,一般在数据库客户端通过csv进行数据的备份,右击表-备份/导出 --选择导出表数据作为csv即可。导入的时候csv一定不能放在中文的文件夹下。
从excel中导入数据,第一行一定要和数据库的字段对应,主键需要自己通过excel下拉手动生成。有时候会遇到varchar类型转为double类型的问题,一般情况下把excel数字列设置为文本列。然后选择数据库点击导入,导入外部数据。选择对应的页签和字段即可导入。
oracle数据库的备份
数据导出 exp file
输入sqlplus / as sysdba 进入oracle数据库。然后根据表明查询默认的表空间,然后 drop tablespace 删除表空间。然后创建临时表空间 temporary tablespace,然后穿件数据表空间,然后删除用户,然后创建新的用户并指明表空间,然后给用户授权,crtl+c退出,然后imp导入即可。
Maven的依赖管理
父pom中设置modules节点引入所有的子模块,根据artifactId进行引入,然后设置dependencyManagement 将所有的公共jar包都引入,子模块就不要再引入jar包了,还可以设置properties将所有的版本号进行统一的管理。
子模块设置需要设置parent节点 将父模块引入。
Maven的生命周期
1、pre-clean执行一些clean前需要的配置工作。2、clean清理上一次构建的文件3、post-clean执行一些清理后要完成的工作
Log4j与SLF4J一般如何进行配置的
SLF4J不是具体的日志解决方案,只提供了一个接口运行用户在部署系统的时候使用其所希望的日志系统,最终的输出还是以具体的日志系统配置来实现的。
Log4j的配置Maven引入log4j的jar包,然后设置log4j.properties配置文件,最后通过Logger的静态方法或者SLF4J的LoggerFactort根据当前类获取日志,通过log4j实例来输出方法如log.error(“错误信息”,ex);log.info();log.debug();log.warn();
log4j.properties配置文件rootLogger会将INFO层级以及以上层级(ERROR、WARN)的输出到Console或文件以及其他自定义的目的地。layout日志输出格式PatternLayout,以及指定某个等级到文件中Threshold,到大指定大小之后覆盖或者追加文件RollingFileAppender
一般情况下log4j.properties放在Maven的resources目录下,不用再web.xml中进行配置引入。
Mybatis的标签有那些呢
insert delete update select choosewhen foreach if test trim resultMap resultType associate parameterType include set id result
Mybatis的mapper文件可以重载么
接口方法不能重载,每一个方法都是唯一的命名
Mybatis的namespace
Mapper中的namespace用于绑定Dao接口的,即面向接口编程。
Mybatis数组与集合如何拼接sql进行批量处理
直接将数组或集合当做一个参数传入,xml文件中通过foreach的mybaits的标签来接收,如果是数组则通过 collection="array" 如果是集合通过collection="list" 来确定了类型,如果传入的参数是多个的话,就需要用Map进行封装了,这个时候collection就为map对应的key了。然后如果是数组item是什么就是什么通过#进行拼接,如果是结合item.属性进行sql的拼接。
Mybatis的#与$有什么区别
$可以直接将传入的数据显示在sql中,传入的什么就是什么、有时候直接会传入一个string类型的sql进行查询的、进行模糊查询的时候也会用到 '%${processState}%' 排序 order by的时候也会用到。
#则是相当于一个占位符?会自动加入引号的,也可以有效的防止sql的注入
Mybatis中的特殊字符的处理
可以不用处理,直接加入CDATA即可
<![CDATA[
${value}
]]>
mybatis的resultType与resultMap的区别
都是在查询的时候
resultMap可以提供级联查询缓存等功能、如果用resultType的时候,则要确定结果集的列名与java的属性名对应,resutlMap则不需要,可以自定义。
resultType的时候可以不用再最前面写BaseResultMap,直接传入对象的类名就可以了
mysql的分页
在数据量较少的情况下物理分页limit 开始第几条数据,往后查询多少条数据,逻辑分页先查询到所有的数据放到内存中,然后再从内存中取数据,性能是哪个物理分页要好于逻辑分页。
在数据量非常大的情况下,需要利用主键或唯一索引进行数据分页。
oracle的分页
oracle通过rowNum进行分页的,内层控制查询的最大数,外层控制起始数。小于等于page*rows+1 大于(page-1)*rows
spring与springmvc的理解
springIOC控制反转是spring的核心,贯穿始终,就是spring来控制对象的生命周期和对象之间的关系。简单的来说,所有的类都由spring来控制,所有的类都会在spring容器中进行登记,告诉spring这是一个什么东西,当需要的时候,可以在spring的配置文件之中通过bean标签声明一个类,用@Component注解,就变为了spring可以管理的bean了,可以不用再spring配置文件中进行什么了。
在Dubbo中就是通过命名空间获取bean的。可以通过new ClassPathXMLApplication获取配置文件对象,然后通过这个对象.getBean()就可以获取响应的类,调用对应的方法了。
也可以通过在spring的配置文件中声明 context:component-scan扫描所有的service controller等类,然后通过applicationContext获取spring应用的上下文环境,然后通过getBean的方式获取被扫描的类的对象了。对于标注了@Service的类spring通过@Autowired直接注入
这样需要另一个对象的时候就不用再去new一个对象了,控制对象的生命周期不再是调用它的对象了,而是spring,这就是控制反转。
springCloud因为spring自动已经配置好了,所以通过@Bean标签就可以获取到该bean进行调用了。像RestTemplate被bean注释之后通过@Autowired就可以进行调用了。
springAOP
主要目的就是为了解耦,对影响了多个类的公共方法封装到一个可重用的模块,一般通过注解进行配置,@Aspect定义切面类,然后定义@PointCut定义要切入的类,然后通过@Before @AfterReturn @After进行实物的织入。里面有个JoinPoint对象,封装了切面方法的信息可以通过getSignature获取响应的构造获取类名、方法名还有参数joinPoint.getArgs();
还有一种AOP是声明式的,比如事物的处理,transactionManager引用对应的数据源,然后通过tx:advice进行统一的事物管理,然后通过aop:config aop:pointcut定义要切入的类, aop:advisor advice-ref 还有point-ref引用统一的事物还有要切入的类即可。
简要说说spring的配置文件在web.xml中的加载方式
web.xml加载spring的配置文件主要是依据配置文件的名称以及存放位置的不同来区分的。如果spring的配置文件的名称是applicationContext.xml则直接添加ContextLoaderListener监听即可。如果是其他自定义的配置文件如果是存在WEB/INF下则需要在context-param中指定WEB/INF下的配置文件或通配符即可。
在Maven项目的的resource目录下,通过classpath与classpath*来加载配置文件的,在web.xml中定义contextConfigLocation参数,Spring会使用这个参数去加载所有逗号分隔的xml文件,如果没有这个参数,Spring默认加载web-inf/applicationContext.xml文件,contextConfigLocation 参数的<param-value>定义了要装入的 Spring 配置文件。如果既没有applicationContext.xml 文件,也没有使用contextConfigLocation参数确定配置文件,或者contextConfigLocation确定的配置文件不存在,都将导致Spring 无法加载配置文件或无法正常创建ApplicationContext 实例。
简单说说springmvc如何配置
首先在web.xml中的servlet中配置DispatcherServlet,引入spring-mvc的xml文件,然后再servlet-mapping中默认匹配所有的请求,在配置servlet的时候会有个load-on-startup元素标记,必须是整数,如果是负数或者没有设置则容器会当servlet被请求的时候再加载,如果为0或正整数则表示应用启动时初始化并加载这个servlet,值越小优先级越高。
然后就配置spring-mvc.xml了,context:component-scan自动扫描包下符合@Controller以及@ControllerAdvice或者@Service以及@Repository的类,同时context:property-placeholder可以引入额外的配置文件。通过AnnotationMethodHandlerAdapter启动springmvc的注解功能,完成请求和注解的映射还有JSON转换器。然后可以配置jsp或者Freemarker的视图解析器。最后配置Ajax请求以及文件上传还有异常处理还有静态资源的处理问题即可。
简单说说spring如何加载配置文件的
如何获取spring管理的bean
当一个类实现了ApplicationContextAware接口之后,这个类就可以很方便的获得ApplicationContext对象了,spring发现某个bean实现了ApplicationContextAware接口,spring容器会在创建该Bean之后,自动调用Bean的setApplicationContextAware()方法。调用该方法的时候,会将容器本身ApplicationContext对象作为参数传给该方法,可以通过applicationContext实例变量来访问容器本身。
InitializingBean接口,当一个类实现了该接口,spring容器启动的时候,初始化bean时则会自动调用afterPropertiesSet()方法,如果在配置文件中指定了init-method,系统先调用afterPropertiesSet(),然后调用init-method中指定的方法去完成一些用户自定义的初始化操作。spring是通过反射调用init-method方法的。
首先在spring的配置文件中声明一个实现了ApplicationContextAware与InitializingBean的类或者通过@Service或@Component把该类注入到spring容器中,通过spring的ConfigurableApplicationContext的getBean()方法根据获取到的类或者是是被spring管理的类(不论是通过注解还是在spring文件中什么的bean)来获取该类的对象bean,然后可以使用该bean中的方法。
最后还可以通过new ClassPathXMLApplication加载配置文件获取ApplicationContext实例,然后通过getBean获取配置文件srping管理的类。
springmvc是什么
springmvc其实就是spring的后续产品,在spring的基础上又提供了web应用的MVC模块,springmvc就是spring的一个子模块。
springmvc的原理
发送请求到中央控制器 DispatcherServlet,然后调用处理器映射器HandlerMapping找到处理器对象Handler,然后通过处理器适配器调用具体的处理器,就会返回ModelAndView,然后再解析视图ViewResolver,最后通过freemarker进行视图的渲染。
springmvc处理乱码
web.xml中进行配置有filter过滤器标签 引入CharacterEncodingFilter标签,然后init-param中设置encoding 为utf-8,然后filter-mapping标签对所有的请求都进行过滤。
springmvc如何实现文件上传的
要在spring的配置文件中bean中引入对应上传的工具类CommonsMultipartResolver,然后设置属性property 默认的编译方式defaultEncoding还有就是文件最大能上传多大的。然后再html页面的form标签中 增加enctype="multipart/form-data"属性,然后通过springmvc将要上传的文件的name设置的与属性值一致。后台controller通过MultipartFile来接收上传的文件,然后通过绝对路径和file.getOriginalFilename拼接要上传的路径地址,通过file.transferTo将文件进行输出即可。
获取项目与文件的绝对路径
在freemarker里面通过在spring的配置文件中配置rc,然后再html页面同${rc.contextPath}就可以获得contextPath。
通过HttpServletRequest对象调用getContextPath()来获取绝对路径。也可以通过request.getServletContext().getRealPath("/")获取。
获取当前类以及文件的classpath路径,还是通过request对象以及类名getResource( )加载文件。
http请求
有三部分组成:请求方法Post/Get 请求url 以及版本协议HTTP/1.1.剩下的就是报文头还有报文体了。报文体就是参数可以通过request.getParameter根据key-value来获取,而报文头中有cookie、Accept 文字/图片/视频影像,浏览器的对象,Content-Type等等吧。
http如何和springmvc进行请求协议的
get请求与post请求的区别
get把参数放在了url上不太安全而且请求的长度也有限制,而post则把参数放在了reques的body里面
get方式会把header和data一并发出去比较快,返回值200
post会发送两次请求比较慢
request对象和response对象
在springmvc中,请求数据是通过方法形参的方式进行提交的与接收的。客户端请求的key/value数据,经过参数绑定,将key-value的数据绑定到controller的形参上,这里面还有HttpServletRequest对象、HttpServletResponse对象,HttpSession对象、还有ModelMap对象。
web服务器收到客户端的http请求,会针对每一次的请求,分别创建一个用于代表请求的request对象和代表响应的response对象。获取客户提交过来的数据只需要request对象即可,要向客户机输出数据就需要response对象了。
设置response对象输出信息,如输出文本信息response.setHeader(“content-type”,"text/html;charset=UTF-8")输出数据库中的表单数据response.setCharacterEncode(“utf-8”);response.setContentType("multipart/form-data"),response.setHeader("Content-Disposition", "attachment;fileName="+new String(fileName.getBytes("utf-8"),"iso8859-1"));即可。如果输出图片信息则通过HttpServletResponse获取输出流对象ServletOutputStream sos = null; sos = response.getOutputStream();然后对response进行设置response.setHeader("content-disposition", "attachment;filename=" + kpId + ".png");response.setHeader("content-type", "image/jpeg");response.setHeader("Content-Length", String.valueOf(fis.available()));即可。
HttpServletRequest代表客户端的请求,当客户端通过Http协议访问服务器的时候,Http请求头中的所有信息都封装在了这个对象中,通过这个对象的方法可以获取到Ip地址,主机名,参数,请求头等等吧。
可以通过new ModelAndView()的方式获取model对象,springBoot通过model,addObject()的方式处理数据通过setViewName的方式处理返回的页面。
springMvc则通过然后通过Model对象的model.addAttributes与return的方式进行数据映射。
session与cookie有什么区别
cookie以文本的形式存储在浏览器客户端的,session是存在服务器上的比较安全。登录的时候我们可以把用户名和密码保存在cookie中,这样就不需要登录网站了,也可以通过设置为永久保存,不安全。session当通过http请求访问,将传递到web服务器上并与访问信息相匹配,关闭浏览器则会话结束,安全性更高的网址需要session进行设置。
如何设置session与获取session中的值
通过HttpServletRequest对象的getSession(true/false)方法来获取session,可以设置为true如果request中的HttpSession为null会创建一个新的session,如果为false则会返回null,默认为true一般存的时候用true取的时候用false获取session即可。然后通过session.setAttribute()方法来设置session,获取到的session使用request.getSession().getAttribute()根据key来获取request对象中的session了。
如何设置cookie与获取cookie中的值
java中可以通过new Cookie然后key-value的方式设置无生命周期的cookie关闭浏览器消失,有生命周期的通过setMaxAge()即可。正常的cookie只能在一个应用中访问,想要多个应用共享还需要设置cookie.setPath("/");然后addCookie到response对象中,获取的时候通过request对象getCookies()遍历获取,需要自己根据key与value封装为map方便使用。
因为cookie是运行在客户端的所以也可以通过js来设置cookie,通过document.cookie="name="+username;方式进行设置,获取通过相应的四则根据key来获取value,也可以相应的清除cookie。
springmvc的ajax和json请求
ajax传递json格式的数据
如果是ajax请求的话,首先dataType要设置为json,并且controller要增加@ResponseBody注解
如果ajax的type设置为了"GET"方法,后台的@RequestMapping method=RequestMethod.GET。
前台可以通过$.toJSON()或JSON.stringify()将对象或数组转为json格式的字符串
后台就可以通过fastJson如果是对象则通过JSONObject.parseObject(string)进行JSON字符串的解析为JsonObject然后通过该对象调用getString方法获取值.或者通过JSON.parseObject(string,要解析对象的类型)将json字符串转为对应实体类型的对象。
如果是数组则通过JSONArray.parseArray(string)进行解析,然后通过遍历获取的对象.getJSONObject(i).get("key")通过key属性值来获取对应的value。或者通过JSON.parseArray(string.要转为的对象类型)将json字符串转为对应实体类型的集合。
前台也可以通过设置contentType:“application/json”的方式传递json格式的数据。
在后台的controller中也可以通过@RequestParam获取ajax请求的data key-value的参数。
$.get方法可以将参数直接跟在url后面也可以跟多个参数用?拼接,第一个参数用@Pathvariable接收,后面的用@RequestParam接收即可。
$.post方式可以直接把序列化的数据传递到后台
后台也可以通过JSON.toJsonString()的方法和JSONArray.toJSONString的方法将对象转为json字符串
有时候后台会传递一个类似于Map<String,String>的json字符串,前台则需要通过Jquery.parseJSON()进行解析为对象了。
如果不需要返回JSON数据的话,不用加@ResponseBody注解,然后再ModelAndView中通过addObject以及setViewName设置值与页面,最后在Freemarker中${code}来进行数据的渲染。在springBoot中也可以使用@RestControllerAdvice 代替 @ControllerAdvice这一都不需要加@ResponseBody。
请简要的说一说如何读取JSON文件并转为字符串
可以通过apache的FileUtils工具类,将获取的json文件转为字符串readFileToString()并指定编码格式,然后即可获取了JSON字符串。
java与js如何实现异步请求
js实现异步请求可以通过ajaxSetup进行全局的设置、也可以单独在一次请求之中设置async:true。
springmvc的3.2版本以上也提供了对请求的异步处理,在web.xml的spring-mvc的配置文件中增加<async-supported>true</async-supported>,然后controller类支持async返回java.util.concurrent.Callable来完成异步处理来支持异步操作。
springmvc对于静态资源的处理
对于静态资源而言,springmvc的分发dispatcher会拦截所有的请求,包括静态资源。通过在配置文件中增加mvc:resources 通过设置mapping映射路径和location文件位置来处理静态资源。
关于序列化表单数据
通过form表单dom元素,调用serializeArray()方法,然后通过一定封装的方法将序列化的表单变为json字符串传到后台。
后台直接可以通过该对象的实体类来获取了,也可以通过fastJson进行解析传过来的json字符串。
springBoot的认识
初衷就是简化spring应用初始化的搭建和开发过程。创建独立的spring应用程序、嵌入tomcat无需war包就可以进行部署。简化了Maven的配置,自动配置spring。
springBoot又增加了一些注解可以实现数据的交互
@getMapping可以获取resultful风格的资源url。
controller通过@PathVariable(url,responseType)接收参数
第一个参数是请求方法的资源url,第二个请求方法的返回值类型。
@PostMapping获取表单的数据,通过restTemplate.postForObject(url,request,responseType)
第一个参数是请求方法的url,第二个参数请求的方法需要传入的对象,第三个参数是请求方法返回值类型
@RestController 可以不用再方法上表明@ResponseBody类
spring拦截器的设置
继承HandlerInterceptorAdaptor里面有个postHandle请求处理之后调用,还有一个preHandle请求处理之前调用
springBoot的拦截器
springBoot直接实现了HandlerInterceptor接口,里面有preHandler、postHandler还有就是afterCompletion请求结束之后并且视图渲染之后调用的。然后重写一个类继承WebMvcConfigurerAdapter然后把重写addInterceptors,把我们自己定义的拦截器添加到拦截器类中registry new
springBoot的Data JPA
定义了一系列对象持久化的标准,开发者唯一要做的就是声明持久层的接口,然后就交给Data JPA来操作了。
只需要在sts创建的spring starter project的springBoot中的SQL选择则JPA 和对应Mysql,然后就会自动的引入Maven的jar包了。然后yml文件中进行数据库驱动的配置还有jpa的配置即可。然后创建一个实体,@Entity注解标注@Table定义表名,然后@Id声明主键还有@GeneratedValue自动生成主键 @Column设置其他的列,然后启动启动类自动生成表了。实体类还有好多其他的注解如@NotEmpty @NotNull @Min等等吧。
然后是持久层的接口要继承JpaRepository<类名.主键类型>即可。不用写service业务层了,然后再controller中注入持久层,然后调用持久层的方法即可,就可以直接findAll()方法,getOne() delete save等等方法。
转发与重定向
重定向redirect 地址会变,重定向甚至可以重定向到其他站点的资源而转发仅仅是当前应用中的资源,可以通过respnse.sendRedirect(url)进行。
转发forward: 可以带数据并且地址不会变,是服务器的行为,转发比较快只做了一次访问请求。
有那些spring的注解
@SpringBootApplication
@Controller
@service
@Resource
@Autowired
@PathVariable
@RequestParam
@RequestBody
@ResponseBody
@RestController
@PostMapping
@GetMapping
@RequestMapping
@Aspect
@Component
@FeignClients
@Configuration
@Value
@Bean
@LoadBalanced
@EnableEurekaClient()
@EnableFeignClients()
@FeignClient()
@Component注解有什么作用
在spring的配置文件之中通过bean的方式来配置类,或者在类上添加@Component注解。
spring全局异常的处理方式
在项目中没有办法避免异常的出现,在之前的项目没有进行任何的配置,容器自动会打印错误信息,如果我们再web.xml中进行error的配置,就会进行错误拦截的处理,然后就会跳转到指定的错误页面。
上面的方式比较落后了,可以通过spring的HandlerExceptionResolver接口来捕获所有的异常,就可以打印错误日志或返回ModelAndView跳转到对应的视图了。
还有一种方式就是spring的3.2之后新增了@ControllerAdvice注解,并且可以@ExceptionHandler为要拦截的异常、@InitBinder、@ModelAttribute,并应用到所有@RequestMapping中。并且@ModelAttribute上在Model上设置的值可以被所有的 @RequestMapping 注解方法的ModelMap 获取。
java的反射原理与实现
使用反射如果想从一个对象动态的获取他的所有方法,私有属性等等就用反射。
首先获取class对象,通过.class或class.forName()获取也可以通过getClass().getSuperClass()获取父类class对象,一个jvm只会有一个实例。然后通过这个class对象调用getName可以获取完整的类名,getFilds()获取所有的public属性 getDeclaredFields()获取所有类的属性,包括private声明的,getMethods()获取所有的public类型的方法 getDeclaredMethods()获取所有的方法包括private方法,getMethod(name,Class[])获取指定的方法,通过方面名和参数类型数组。getConstructors()获取构造方法,newInstance()通过不到参数的构造方法创建一个类的对象。
通过invoke可以执行Method对象的某个方法,method.invoke(反射调用方法所属类的对象,具体的参数值没有返回值可以不写)
简要的说明一下java的深拷贝和浅拷贝
如何复制一个对象,Object类有一个protected的clone方法,对一个对象进行赋值就需要重写clone方法了。
浅复制的步骤被复制的实体类需要实现Clonenable接口并且重写clone()方法,通过super.clone()得到需要的复制对象如 Student stu = (Student)super.clone();直接使用即可 Student stu2 = (Student)stu1.clone();
深度复制,由于浅复制仅仅是复制了addr变量的引用,并没有真正的开辟另一块空间,并不是正在的复制对象,而是纯粹的引用复制。我们同样需要对实体类中的实体对象如Address address也要实现Cloneable接口。Student stu = (Student) super.cloen(),stu.addr = (Address)addr.clone();
当然也可以通过spring或者Apache的BeanUtils对象和属性的拷贝与复制,通过copyProperties(A,B)方法来实现,不过引入的jar包不同方法也不一样,spring是将A值赋给B,而Apache是将B值赋给A。
Map与实体类的转换
有时候业务有一个操作的临时表,通过这个临时表完成业务的增删改查,为了减轻临时表与实体表之间的数据库操作,可以通过通过Map与实体表进行转换,要求临时表与实体表的字段必须一致,然后先通过临时表转为Map然后同Map的反射实现属性的复制。也可以同apache的BeanUtils方式实现对象与map的转换。
AbstractRoutingDataSource实现多数据源的切换
再spring在配置文件之中BasicDataSource也可以也可以使用DruidDataSource配置主从数据源,然后再spring的配置文件之中引入继承了AbstractRoutingDataSoure并重写determineCurrentLookupKey方法类实例化一个bean,在determineCurrentLookupKey方法中要返回的就是ThreadLocal本地线程变量中通过枚举设置的主从数据库名,然后spring的配置文件之中<map>标签根据entry的key来确定是哪个数据源。
具体调用的时候通过本地线程变量设置枚举的值来确定使用哪个数据源。
ehcache缓存怎么使用
EhCache是一个纯java的进程缓存框架,在spring的配置文件中引入CacheManger,通过获取这个CacheManager类的实例调用.getCache方法通过cacheName和cacheKey获取缓存数据,如果获取到的数据为null的话,则把cachekey和要缓存的数据put进去。
进程与线程并发与并行的区别
一个程序至少有一个进程,一个进程至少有一个线程。
多线程就是为了增加cpu的利用率,每个用户请求交给一个线程去做,服务器处理用户请求的时候可以继续监听并处理其他的用户请求,不用等到一个用户请求完成以后再去执行另一个用户的请求。
并行是同一时间点同时进行,而并发则是同一时间片段同时进行。进程之间是相互独立的可以实现并行,而线程只能并发执行,如果一个线程挂了整个进程也挂了,线程因为切换的时间很短,好像看起来并行了。
简单的说说对java并发编程的理解
假如有两个任务A和B,任务A在执行到一半的过程中,需要大量的IO操作,而此时的CPU只能静静的等待任务A读取之后才能继续执行,浪费了CPU的资源。可以在任务A读取数据的时候,让任务B去执行,这就是并发的概念。宏观上看起来好像一个时间段有多个任务在执行,实际上在一个具体的时刻只有一个任务占用CPU资源(单核CPU)。
并发中进程是最基本的一个单位,一个进程对应一个程序每个进程对应一个内存地址空间,各个进程之间互不干扰。并且进程保存了程序每个时刻的运行状态,就为进程的切换提供了可能。
线程是比进程跟家小的一个单位,如果一个进程有多个子任务,比如说听歌,播放视频,又要处理人机交互。每一个子任务就是一个线程,让线程轮流的获取cpu的资源,让用户感觉同时在做很多的事情,满足了用户对实时性的要求。线程是共享进程占用的资源和地址空间的,会存在线程安全的问题。
进程是资源分配的基本单位,而线程则是系统进行任务调度的基本单位。
java创建线程与进程
创建线程有两种方式一是继承Thread类重写run方法调用start()方法就可以去启动一个新线程了,通过run()方法只会调用主线程,并不会创建新的线程。第二种方法是实现Runnable接口,这种方式必须将Runnable作为Thread类的参数,最后通过Thread的start()方法创建一个新的线程来执行该子任务。
创建进程的两种方式,通过Runtime.exec()方法来创建一个进程,由于exec方法不支持不定长度所以必须得要把命令拼好后再传入。第二种方法通过ProcessBuilder的start方法来创建进程。比如打开cmd获取ip地址可以这么实现ProcessBuilder pb = new ProcessBuilder(“cmd”,“/c”,"ipconfig/all") Process process = pb.start();也可以通过传入Runtime进行实现 String cmd = "cmd"+“/c”+"ipconfig/all"; Process process = Runtime.getRuntime().exec(cmd);的方式进行。
请简要概述线程的状态
线程有创建状态(new)、就绪状态(runnable)、运行(running)、阻塞(blocked)、time waiting、waiting、消亡(dead)。
使用线程来执行某个子任务的时候就会创建了一个线程,创建线程之后不会立即进入就绪状态,只有为线程分配了一定的内存空间之间才会进入就绪状态。进入就绪状态之后不会立即获取CPU的执行时间,当得到真正CPU的执行时间之后线程才会进入运行状态。运行状态的过程中用户也可以主动的让线程进入睡眠状态,主动的让出或被同步块阻塞。突然中断或子任务执行完毕之后,线程就会被消亡。
Tread的start()方法来启动一个线程获取cpu的执行时间、run()方法会具体执行的任务,sleep()方法让线程睡眠让cpu去执行其他的任务,sleep方法不会释放锁,当前线程持有某个对象的锁,调用sleep其他线程也无法访问这个对象,必须等到执行完毕释放锁之后其他线程才能继续进行,调用sleep()方法必须捕获InterrruptedException。yield()方法会让当前线程交出CPU权限,让CPU去执行其他线程,同样不会释放锁,yield()方法只会让相同优先级的线程获取CPU执行时间的机会,但是yield方法不会进入阻塞状态而是让线程进入就绪状态。join()方法会等待其他线程执行完毕或执行一段事件之后再去执行当前的线程,join方法会让线程进入阻塞状态,并且会释放线程占用的锁,并交出CPU的执行权限。interrupt()方法可以用来中断一个处于阻塞状态的线程并抛出异常,也可以通过Interrupt()或isInterrupte()方法来停止正在运行的线程。stop()方法已经废弃直接终止run方法。守护线程setDaemon和isDaemon用来设置是否为守护线程,守护线程依赖于创建它的线程,如果在main线程中创建一个守护线程,当main方法执行完毕之后,守护线程也会随着消亡的,而用户线程则会一直执行完毕。
线程的上下文切换,单核cpu一个时刻只能运行一个线程,当一个线程中转去运行另外一个线程,这个过程叫做上下文切换,存储和恢复CPU状态的过程,它使得线程执行能够从中断点恢复执行。
线程锁synchronized的作用
线程安全问题,多线程编程中会同时出现访问同一个资源(临界资源)的情况,由于线程执行过程是不可控的。多个线程执行一个方法的时候,方法内部的局部变量并不是临界资源,因为方法是在栈上执行的,而java栈是线程私有的不会产生线程安全。
在java中提供了两个方式实现同步互斥访问:synchronized和Lock。
synchronized方法是顺序执行的,当一个线程正在访问一个对象的synchronized方法,那么其他的线程不能访问该对象的其他synchronized方法,一个对象只有一把锁,当一个线程获取了该对象的锁之后其他的线程无法获取该对象的锁,所以无法访问该对象的其他synchronized方法。
synchronized代码块,线程执行代码块的时候,会获取对象锁,从而使其他线程无法同时访问该代码块。对象锁可以是this,代表获取当前对象的锁,也可以是类中的一个属性,代表获取该属性的锁。代码块比synchronized方法要灵活的多,因为一个方法只有一部分代码需要同步,如果对整个方法使用synchronized进行同步会影响程序的执行效率。
关于对象锁和类锁,对象锁就是非static synchronized方法,类锁是static synchronized两种类型的锁并不会产生互斥行为。
对于synchronized方法或者synchronized代码块,出现异常JVM会自动释放当前线程占用锁,因此不会由于异常导致死锁现象。
请说说sychronized与Lock有什么不同
如果获取锁的线程由于要等待IO或者其他的原因被阻塞了,但是又没有释放锁,一直等待影响了执行效率,通过Lock就可以知道线程有没有成功获得锁,必须要手动释放锁,如果没有主动释放锁就会出现死锁现象。
一般来说Lock必须在try{}catch{}块中进行,并且把释放锁的操作放在finally块中进行,防止出现死锁问题。获取锁有lock()方法、tryLock()如果获取锁则返回true,tryLock(long time,TimeUnit unit)拿不到锁在一段时间期限内如果还拿不到锁则返回false。lockInterruptibly()通过这个方法获取锁能响应中断抛出InterruptedException异常而synchronized会让线程一直等待下去,如果某个对象获取了锁则会一直进行等待并且是不会通过interrupt()方法来中断的正在运行过程中的线程。
锁有那些种类
可重入锁是基于线程的分配而不是基于方法的分配,不会造成访问某个方法而同时访问某个对象的锁造成死锁,可重入锁ReentrantLock是唯一实现了Lock接口的类。
可中断锁,Lock的lockInterruptibly就是可中断锁,当一个线程正在执行锁中的代码,另一个线程等待时间过长可以先中断自己去处理其他的事情。
公平锁尽量以请求锁的顺序来获取锁,多个线程等待第一个锁,当释放锁的时候,等待最久的线程会优先获取该锁。ReentrantLock(true)就为公平锁了,false为非公平锁
读写锁,ReentrantReadWriteLock实现了ReadWriteLock接口,可以将文件的读写操作分开,分成两个锁给多线程使得多个线程可以同时进行读操作,大大的提升了读操作的效率。如果一个线程已经占用了写锁,则此时其他线程如果申请写锁或者读锁,则申请的线程则一直会等待。
java的线程池
线程池的作用就是限制系统中执行线程的数量,防止消耗过多的内存,而对服务器造成的压力,使得系统处于最佳的运行状态,减少了资源的浪费,我需要一个线程就放到了线程池中有空闲就执行没有空闲就等待,而且工作线程中线程可以被重复的利用,减少了创建和销毁线程的次数。
线程池有两种方式Executors.newCachedThreadPool()方法缓存长度超过所需会灵活的回收当时当线程的总数超过200的时候回内存溢出,还有一种方式就是newFixedThreadPool可控制线程的最大并发数,超过则等待。来获取ExecutorService对象,通过这个对象调用execute方法来执行当前线程的任务。
QuartzJob定时任务如何实现的
quartzJob是用来实现定时任务的,首先要定义一个类实现Job接口,实现execute方法,在这个方法之中就是要执行的定时任务。任务调度需要在spring中配置,成为spring容器中的一个bean,然后从调度程序工厂获取一个调度实例Scheduler,并将调度工厂实例还有调度实例传入到自己定义的任务生产工厂之中,在这个工厂之中会查询所有数据库中调度的类以及调度时间等等的默认配置吧。然后通过newJob把刚刚实现类job的类添加进去再添加一些定时任务传入调度器,任务名和任务以及时间的配置,最后通过newTrigger触发器传入调度名和执行时间周期获取调度器对象。任务的执行通过调度器实例sched.scheduleJob(newJob的实例.触发器的实例),通过调用sched.start()就可以执行定时任务了。
jquery定时器的设置
可以初始化一个对象=setInterval(function(){ 回调方法}.时间间隔)
清除定时器 clearInterval(定义好的对象)
高德地图如何封装的
引入js的入口脚本标签,将其中的key该为自己申请的key。在div中的id设置地图容器,然后通过new AMap.Map("地图容器id",center:[].zoom)。自己的平台通过构造方法对象的方式this高德地图的API将封装到一个对象之中,然后就可以通过这个对象对用高德地图的API了。比如划线drwaLine(line) 坐标数组 删除线removeLine drawPoint showInfoWindow() centerAt方法。
arcgis地图如何引用的
arcgis地图单独的一个web服务启动,然后再js中通过ip端口号调用arcgisService.js。还是通过new 对象的方式,把一些地图配置如地图容器,中心点什么的作为参数参数new 封装的地图API中,然后就可以通过这个对象调用arcgis地图的服务了。
请简要概述eCharts如何使用
前台需要引入echarts的相关js,然后再定义一个div容器。通过echarts.init(document.getElementById('demo1'));加载容器实例,然后通过容器实例将后台获取到的数据根据eCharts的API进行setOption()渲染即可。
eCharts可以绘制雷达图、折线图、饼图、柱状图还可以跟定时器配合动态的绘制图。一般情况下,需要将后台的数据通过Map进行封装并且组装为JSON数据返回到前台,如果没有组装为JSON实体前台还需要jQuery.parseJSON()来解析返回的JSON对象,然后就可以通过key就可以获取后台封装的指定数据了。
Freemarker模板引擎如何渲染数据的
${key!‘ ’} 后面跟默认值
<#if ??> 判断是否为空
<#list 传来的数据 as item>
${item.属性}
ztree树的实现
ztree树的初始化,$.fn.zTree.init("地图容器的id",setting,zNodes),同expandAll(true)实现树的展示
引入fuzzySearch插件,fuzzySearch("容器ID",“输入框的id”,null.true)
spring的配置文件如何引入properties文件的参数信息
在spring管理的bean中有个PropertyPlaceHolderConfigurer文件 然后 property name="locations"中 通过<list>标签进行引入。
企业微信如何发送消息推送的
在spring的配置文件中引入WxCpServiceImp,然后把一些配置信息通过property 标签引入即可。然后再spring的配置文件中将要执行微信相关业务的service也作为一个bean,property的ref就是上面的WxCpServiceImp,调用的时候在要执行微信业务的类中直接通过@Autowired直接注入spring容器管理的WxCpServiceImp。通过这个WxCpServiceImpl的实例调用sendTextMessage方法即可。
简单的说说对于JQuery的理解
执行var jq = $.noConflict()后,$将不再控制当前的JQuery,而是让渡给jq变量,此时jq("div")和JQuery("div")是等价的。jQuery也解决了。
简单的说说如何扩展jquery的基元
可以通过apply的方式进行扩展jquery的基源,通过传入arguments参数,如 coreJquery = function (){ return $.apply(this,arguments)} 如果用jquery调用的话,则等价于让当前调用的对象this拥有JQuery的所有属性arguments。然后通过定义另一个工具对象例如 coureUtil = function () { return Object.apply(this,arguemnts)} ,然后我们把coreUtil对象的引用指向到coreQuery上,coreJquery.util = coreUtil,就已经完成了JQuery的基源扩展了。
我们就可以通过插件的定义方式coreUtil.fn=coreUtil.prototype={},coreJquery.fn = coreJquery.prototype = {}; coreUtil.document = window.document,使我们闭包中的coreUtil对象上定义的方法扩展到JQuery对象上了,比如coreUtil.getRequest = function(){ } ,coreUtil.request = coreUtil.getRequest,具体调用的时候通过JQuery就可以调动了,如$.util.request['tempid']就可以使用闭包中定义的方法了,一般情况下JQuery基于扩展中的this都是window对象。
谈谈对js的var变量的理解
全局变量属于window对象,可以被在其范围内所有的地方使用,类似于类里面的成员变量可以被他的方法所改变。
定义变量时如果不使用var关键字,总会被视为全局变量,即使在函数内定义。
var a = b = 10输出什么
如果这种写法在函数内,b其实是全局变量会输出10 a其实是局部变量为undefined。
var a=10,b=10; 这时候两个都是局部变量了。
js的var变量和let变量有什么区别
let声明的变量,在声明前是无法使用的,否则会报错,而且被let声明并且初始化的变量无法再重新赋值了否则会报错,如果未初始化let变量则自动分配undefined,let变量作用的范围仅仅在声明它的块中。
jquery的选择器
基本选择器根据id,class 元素标签类型
层次选择器 $(“form input”) ul>li>inputLchecked ul li,div
过滤选择器 li:first :last even odd li:eq(0) div:has(p) td:empty
表单选择器 :input :text
$("input",$("body"))
$("[href=‘#’]")
jquery的标签选择器有哪些
siblings()获取被选元素的所有同胞元素,find("dom")获取当前元素集合中每个元素的后代。filter(dom)获取指定属性值的dom元素
a标签都有什么属性
a标签为超链接标签,从一个页面链接到另一个页面,href属性知识链接的目标。 除此之外还有download固定被下载的超链接目标,target()在何处打开链接文档,type为链接文档的MIME类型。
关于页面加载函数window.onload与$(document).ready(function(){})
window.onload必须等到页面内所有的元素包括图片和js都加载之后才会执行,而$(function(){ })是dom结构绘制好之后就执行了。
$(document).ready(function(){})可以简写成$(function(){ });而且可以同时编写多个,自执行函数(function(){ })(JQuery)利用js的闭包,会自动执行。
jquery的filter过滤器
过滤器可以获得类名或其他属性名为指定类型的dom元素。
jquery如何获取数组中的某个指定的元素合并为一个全新的数组元素
可以通过js自带的map方法 return所要求的的数据。jquery也有map方法不过要处理的元素在map里面作为一个参数。
如何初始化数组
可以通过js自带的fill方法通过自带的fill('')就可以实现初始化数组,也可以指定开始的位置以及长度
jquery添加dom元素
append()与prepend()是往元素内的前后添加,而after()和before()是往元素外的前后添加。
简单说说对js中的argumens对象的认识
在js中不需要明确的指出参数名就可以访问它们,通过类似于数组下标的方式。js并没有重载函数的功能,而arguments对象就可以模拟重载,arguments对象不能显示的创建,只有函数开始的时候才可以用。
js中递归的实现
递归就是自己调用自己,实现的三要素方法中出现自己调用自己,要有分支,要有结束条件。递归关键是要找出循环的一句和各个步骤的相同点相同的逻辑然后将这些逻辑实现在一个方法中,什么情况下要继续循环,什么情况下要终止循环。
callee属性是arguments对象的一个成员,仅当相关函数正在运行的时候才可用。calle属性的初始值就是正被执行的Function函数,通过calle运行匿名的递归函数,递归一定有一种情况下可以退出的情况,并且总是尝试将问题化简到更小的规模,父问题与子问题不能有重叠的地方。
简单的说说对js的Function的认识
js中的所有对象都是由函数Function实现的,可以通过new的方式实例化构造函数也可以通过 var=function Method(){ }的方式构建对象,在对象或者表达式后面直接增加圆括号的方式表示执行这个函数如var C = new A() C().。每个对象都有一个构造函数,不过Function这个对象比较特殊,它的构造函数就是它自己,因为Function可以看成一个函数也可以看成一个对象。所有的函数和对象都是由Function构造函数得来的。
js中对prototype的认识,什么是原型链
js的所有函数都有一个prototype属性,而prototype是函数所独有的属性,一个函数通过prototype所指向的一个对象就是函数的原型对象,例如Person.prototype(person._proto_ === Person.prototype它们两个是完全等价的)。例如有一个Person函数,可以通过Person函数来构造对象。Person.prototype的值便是一个对象,里面有两个属性就是(constructor和_proto_可以通过hasOwnProperty验证),prototype主要的作用就是便于方法或者属性的重用,也可以利用函数的prototype添加扩展属性和方法,我们可以把不变的属性和方法直接定义在prototype上。
_proto_和constructor是对象所独有的属性,_proto_的值都取自构造函数的prototype的值,即指向它们的原型对象(一个对象指向另一个对象),也可以理解为父对象,_proto_的作用就是访问一个对象属性的时候,如果对象内部不存在这个属性,那么就回去_proto_属性所指向的那个对象,由_proto_属性连接对象直到null的一条链就是所谓的原型链。
constructor属性是从一个对象指向一个该对象的构造函数,创建对象的前提是需要有constructor。Person.prototype.constructor===Person(),通过函数创建对象即使自己没有constructor属性,它也能通过_proto_找到对应的constructor。
js有什么方式可以定义对象
可以通过构造函数的方式创建,如下,定义变量与方法通过冒号进行定义,如下:
<script type="text/javascript">
var name="The Window";
var object={
name:"My object",
getNameFunc:function(){
var name="object func";
return function(){
return name;
};
}
};
alert(object.name);//My object
alert(object.getNameFunc()());//The Window 因为this调用的其实是window
</script>
js的执行环境
js的预解析是在程序进入一个新的环境时,把该环境里的变量或函数预先解析到它们能调用的环境中,即每一次预解析的单位是一个执行环境。
js在执行前首先会创建一个当前执行环境下的活动对象,并将那些用var声明的变量、定义的函数设置为活动对象的属性,但是此时变量的赋值都是undefined。
在js解析执行阶段,遇到变量需要解析,首先会从当前的执行环境中查找,如果没有找到并且当前的执行环境的拥有这有prototype属性时会从prototype链中查找,否则会按照作用域链查找。变量赋值在解析阶段完成。
js的活动对象
js函数的作用域
js的作用域只有一个就是函数作用域,函数有自己的作用域,比如for循环,for循环转一次,就会创建一个自执行函数,在自执行函数中都有自己独立的i,而且不会释放掉,所以for循环遍历之后,加入循环了五次就会创建5个自执行函数,并且在自执行作用域中,分别存储了5个不同的i变量。
在java中有块作用域的概念,块中的语句对外是封闭的。在js的函数中,用var定义的变量是局部变量,不用var定义的变量是全局变量。
js的作用域与作用域链
js的闭包
内部函数被外部函数之外的变量所引用就是一个闭包,就是让函数使用其定义外的变量。在实际应用开发的时候,会将闭包和匿名函数联系在一起使用,(function (document){ })(document),这样在window全局对象中定义的变量引用就不会被GC了,变量一直存在内存中可以在闭包外的任何地方调用闭包内的方法与变量,满足了闭包的条件。
闭包的好处,可以避免全局依赖也可以避免第三方的破坏与兼容JQuery操作符$和JQuery,不增加额外的全局变量,执行过程中所有的变量都是在匿名函数内部。
使用插件不会污染顶级对象和全局变量,因为闭包可以使全局的变量变为私有。
闭包其实也是匿名函数,JQuery将自己的所有代码都封装在了一个闭包内,用闭包防止命名空间的变量污染,(function(){ var jQuery = (function (){ var jQuery = function(){ } return (window.$=window.jQuery = jQuery) }) })(jQuery),当匿名函数执行完毕,其作用域链会立即销毁,可以减少闭包占用资源的问题。
js的call与apply
apply是用来替换this的指向,用指定对象替换函数的this值,同时用指定数组替换函数的参数。
call方法用一个对象替换当前的对象,可以接收多个参数。
obj1.getMethod.apply(obj2,[10,200]) 让obj2拥有obj1中的方法,也可以实现继承,Animal.apply(this,[name])this当前对象就被Animal对象替换了,同时当前对象也可以调用Animal对象的所有方法了。
js的caller与callee
caller属性获取调用当前函数的函数,主要用于查看函数本身被那个函数调用了,
callee属性,返回正被执行的Function对象,arguments.callee是一个指向正在执行的函数的指针,通过arguments.callee来调用函数就可以实现递归
js的event
所有事件函数都可以传入event如$(“p”).click(function(event){ event.type//click })。event代表事件的状态,event对象只在事件发生的过程中才有效,event的某些属性只对特定的事件有意义,如fromEvent和toEvent只对onmouseover和onmouseout有效。
大概有event.pageX事件发生时,鼠标距离网页左上角的水平距离,event.pageY垂直距离,event.which按下了哪一个键,event.data在事件对象上绑定的数据,event.target事件针对的网页元素,event.preventDefault()阻止事件的默认行为,比如点击链接打开新页面,event.stopPropagation()停止向上冒泡。
jquery插件的实现
$.fn.extend({})给dom对象添加方法,相当于为类添加了成员函数,必须通过实例才能调用。
$.extend({}) 为JQuery类本身增加新的方法
通过JQuery.fn.方法名=$.prototype.extend(方法名)扩展一个对象到jquery的property里去,就实现了插件机制。
jQuery插件的实现,平时我们使用的fn插件其实就是jQuery原型,jQuery就是返回了一个init为构造函数的对象,我们平时用的jQuery对象实质上是jQuery对象自己原型中的一个构造函数对象。我们将init的原型指向了fn,而fn指向的是jQuery原型,相当于init的原型是指向jQuery原型的。
var jQuery = (function(){
var jQuery = function(){
return new jQuery.fn.init(selector, context);
}
jQuery.fn = jQuery.prototype = {
init: function(){}
};
jQuery.fn.init.prototype = jQuery.fn;
return (window.$ = window.jQuery = jQuery);
});
jQuery命名空间的工厂函数,这样就可以在jQuery类中加入静态对象了,在jQuery内核里的对象或方法往往要调用对象内的私有属性。jQuery.extend = jQuery.fn.extend = function(){ }
通过闭包就可以实现自己的自定义插件了:
;(function($){
;(function($){
debugger;
var options = {
fieldCode: "gfyId",
url: "../../Security/selector/user/PublicServiceUserList.html?s=" + Math.random(),
multi: false,
code: "gfyId,gfyIdName",
keyRespField: "gfyId,id",
dictCode: "publicserviceName",
area: ['90%','90%']
};
/*引用查询选择*/
function renderSelectorMy(options){
debugger;
var defaults = {};
this.settings = $.extend({},defaults,options);
var $domObj = $("#" + this.settings.fieldCode + "-popSelector");
this.settings.url = $domObj.attr("action") ? $domObj.attr("action") : this.settings.url;
this.settings.multi = $domObj.attr("multi") ? $domObj.attr("multi") : this.settings.multi;
this.settings.code = $domObj.attr("codeAndName") ? $domObj.attr("codeAndName").split(",") : this.settings.code.split(",");
this.settings.keyRespField = this.settings.keyRespField ? this.settings.keyRespField.split(",") : "";
this.init();
}
//为函数添加原型链上的方法
renderSelectorMy.prototype = {
init: function(){
debugger;
var _self = this,
_keys = _self.settings.code;
$("input[name='" + _keys[0] +"']").parent().parent().find("button").unbind('click').bind('click', function(){
var action = "_self." + $(this).attr("action");
eval(action);
});
},
//扩展jquery类方法
$.extend({
renderSelectorMyf : function(options){
return new renderSelectorMy(options);
}
});
})(jQuery)
debugger;
renderSelector = $.renderSelectorMyf({
fieldCode: "gfyId",
url: "../../Security/selector/user/PublicServiceUserList.html?s=" + Math.random(),
multi: false,
code: "gfyId,gfyIdName",
keyRespField: "gfyId,id",
dictCode: "publicserviceName",
area: ['90%','90%']
});
_self.renderSelectors = [renderSelector];
一般要把所有插件的定义都放在闭包中,闭包的封装机制对项目的空间隔离有很大的作用,双层闭包和内层调用可以防止命名空间的污染,逻辑结构也非常的清晰,对于内层私有变量的保护和外层库的扩展这种设计模式在开发中有很大的意义。
我们平常用的$()或jQuery()是用jQuery的init方法new的一个jQuery的init对象。
(function(window, undefined){
<span style="white-space: pre;"> </span>//内核
var jQuery = (function(){})();
//非依赖私有变量的类方法
(function(){
//可以直接调用jQuery外层应用类对其进行扩展
jQuery.support = {};
jQuery.extend({/*TODO*/}
})();
})();
自己实现一个jQuery全局对象
function(){
function _$(ele){
this.eles = [];
for(var i = 0, i < eles.length ;++i){
var ele = ele[i];
if(typeof ele == 'string'){
ele = document.getElementById(element);
}
this.eles.push(ele);
}
}
window.$ = function(){
return new _$(arguments);
}
})();
vue与JQuery的对比
vue为渐进式JavaScript框架(可只使用其一部分功能),Mvvm框架实现数据与试图双向动态绑定,数据发生变化通过指令或双括号表达式渲染到前台。
vue类似于java有个new的实例。有个el和data属性,el为渲染哪一个容器里,data里面的属性与值可以自定义,vue-devtools插件可以调试vue进行调试。过双大括号可以把数据进行渲染,通过v-model=“”的方式操作就可以只关心数据了,并且v-model是基于input中的监听器。
vue的常用指令有哪些
主要分为模板语法、条件渲染、列表渲染、事件处理四个方面,模板语法有v-text/v-html 作为文本或作为html标签解析,v-once(只绑定一次)、v-bind(:style :href :class(v-bind的省略写法) 可使用驼峰写法,此时就脱离了公共的css样式除非使用json的{aa:true,cc:true}设置为true即可,一般多个样式可以通过数组或json的格式定义多个属性)、v-for、v-on、v-if、v-model(v-model双向数据绑则修改了v-model相同data属性的关键字会一起发生变化如双向数据绑定v-model=“sex”表单,同时v-model也可以机进行属性的计算,只要将属性的运算规则放在computed属性下通过v-model引入方法即可这是单向的,如果想双向的只需要重写get()和set()即可)、条件渲染有v-if、v-show、列表渲染有v-for指令(v-for循环(对象 索引) in data中的内容替换jquery的append,如果遍历的数组:key是index如果是对象则:key是key对象的id保证唯一性用的,就可以获取每一个实例对象了),事件处理一般通过v-on指令(事件修饰符@代替 v-on),还可以自己定义一些方法在methods属性中,根据传入的参数通过this操作当前的属性了。
同时可以自定义指定,使用Vue实例的directive属性进行设置全局指令和局部指令,然后使用v-xxx就可以使用data属性里面的属性项了。也可以通过Vue实例的filter设置全局过滤器和局部过滤器,第一个参数是双大括号{{ | }}右边要过滤的方法函数,左边就是要过滤的值和数据了。
请简要的说一下vue的生命周期
vue实例在整个生命周期中挂在了很多回调函数,这些回到函数可以访问属性放来来进行操作的,有beforeCreate方法、created方法、beforeMount方法、mounted方法、beforeUpdate方法、updated方法,和methods一个层级的
oracle的函数
abs() upper() substr() trim() concat() ceil() floor() trunc() to_number() to_char() to_date() extract()
mysql的函数
CONCAT()
oracle的索引
索引为了加快数据的检索,如果没有索引查找某个条件的时候,会搜索所有的记录,如果在要查询的字段上简历索引,会构建索引条目,直接就可以查找到对应的地方。
简历索引 create index index_sno on student(‘name’)
mapper3与baseEntity
在dao接口继承Mapper<实体名>,dao接口就可以不用写任何的方法了,在service实现BaseService ,在service的实现类中继承BaseServiceImp<dao接口名称,类名称>
在实现层就可以通过@Autowired引入,selectByPrimaryKey,insert等等的方法
js的二次开发
excelPoI的相关方法
一些基本的API new HssfWorkbook() 定义工作薄, wb.createSheet 创建一个sheet页,sheet.creatRow创建行 sheet.createCell()创建单元格子,然后通过FileOutputStream 进行输出即可。
spring如何引入jdbcTemplate
在spring的配置文件之中,通过bean的方式注入spring.core.jdbcTemplate 然后通过constructor-args ref 引入刚刚实现的动态数据源 dynameDataSource
java的GC
在java中,程序员不需要关心内存的动态分配和垃圾回收的问题,一切交给JVM来处理。java通过引用来和对象进行关联,也就是说如果要操作对象,必须通过引用来进行。如果一个对象没有任何引用那么就可能成为被回收的对象了,这种方式成为引用计数法。可达性分析法,通过一系列的"GC Roots"对象作为起点进行搜索,如果和一个对象之间没有任何路径可达的就没有引用了。
强引用通过赋值为null,即可中断引用和某个对象之间的关联,来进行垃圾回收清理工作。
软引用SoftReference<String> sr = new SoftReference<String>(new String(“hello World”))内存不足的情况下,会将String对象判定为可回收对象,用于网页缓存、图片缓存。
弱引用WeakReference<String> st = new WeakReference<String>(new String("hello World")) 无论什么情况下String对象都可判定为可回收对象,通过system.gc()即可回收。
虚引用并不影响对象的生命周期,对象与虚引用关联则与没有引用与之关联一样,任何时候都可能被垃圾回收器回收。虚引用必须和引用队列关联,通过判断队列是否加入了虚引用来决定是否要回收。ReferenceQueue<String> queue = new RefereneceQueue<String>() PhantomReferenece<String> pr = new PhantomReference<String>(new String("hello"),queue)
对于js的GC理解
在JavaScript中,如果一个对象不再被引用,那么这个对象就会被GC回收,否则这个对象会一直存在内存。当我们需要在模块中定义一些变量,并且希望这些变量一直保存在内存中但不会“污染”全局变量,就可以用闭包来定义这个模块。
关于访问修饰符
public 可以同类、同包不同类、不同包子类也可以访问父类的public定义的属性。
protected 同类、同包可以访问,不同包下子类可以访问父类protected定义的属性。
private 就是私有的意思体现了java的封装性,同一个类才可以访问,其他情况都不能显示的进行访问只能通过get/set方式进行访问,继承父类也只能访问父类的public和protected成员变量。
java中形参与实参的区别
形参不是实际存在的变量,在定义函数的时候作为的参数,目的是来接收参数的。实参是在调用的时候传递给函数的参数,可以是常量、变量、表达式、函数等。
java的局部变量和全局变量
在方法内声明并且初始化的为局部变量只能受制于某个方法,每个线程执行该方法的时候都会保存一个副本,当然获得的是不同的锁,也不会发生冲突。
成员变量就是全局变量,全局变量是已经初始化了并且分配了唯一的地址在任何的地方都可以调用。
一个类的初始化过程
代码的执行过程,先找到函数的入口,也就是main方法,执行main方法之前,必须先加载类如果发现某个类继承了某个父类,会先去健在父类的,发现有static块会首先执行。当执行new 方法的时候,也会先调用父类的构造器,然后再调用自身的构造器。
在生成对象的过程中会先初始化父类的静态代码块---子类的静态代码块(先把所有的static类都加载完毕)。父类的构造器调用以及初始化过程一定在子类前面。如果还有成员对象的生成必须先初始化的成员变量不论放在方法之前还是方法之后(也就是说类中的变量会在任何方法包括构造器调用之前就要进行初始化,变量散步与方法定义之间),等成员变量的代码块和构造方法加载完毕之后再去执行剩余的构造器。
关于类中方法的调用,方法的调用子类继承还会涉及到多态,会先执行完父类和子类的构造方法之后,才回按照方法的调用的顺序去调用方法。并且覆盖重写只是针对非静态的方法,隐藏多态不会动态动态绑定,还会是父类方法的实现。在java中除了final和static其他的方法都是动态绑定的。
重写与重载的区别
重写也叫覆盖,以求达到不同的作用,重写对的参数必须和原来的方法相同,否则就是重载了。重写方法的修饰符一定要大于被重写的修饰符,被重写的方法不能是private,否则在其子类只是定义了一个新的方法,没有对其进行重写。静态方法不能重写为非静态方法。重写是基于继承的。
重载定义一些名称相同的方法,通过定义不同的输入参数来区分这些方法,调用的时候VM会根据不同的参数样式,来选择合适的方法执行。
多态的认识
多态的前提,要有继承要有方法的重写,父类的引用指向子类的对象,这样同样的引用调用同样的方法就会根据子类对象的不同表现出不同的行为。多态中成员变量的访问是基于动态绑定的,而且父类的引用不能指向子类的的特有方法,要实现就要通过向下转型的方式。
父类的引用指向子类的具体实现,如果重写的方法是静态的,则多态显示的就是父类的方法,如果是非静态的,则表现子类的方法。
java的抽象类与接口
java的抽象类就是为了继承而存在的,抽象方法必须为public、protected,抽象类不能用来创建对象。抽象类中的非抽象方法可以不用重写,其他的必须重写,但是如果子类也是抽象类的话,也可以不用重写所有的抽象方法,抽象类可以含有静态方法和静态代码块。并且不可以实例化抽象类,抽象类内部的构造函数只是为了初始化声明的通用变量,并且被各种实现所使用。
接口没有普通的属性,只有静态属性,接口中的变量只能用public final static修饰。抽象类是可以实现接口的,而且不用实现接口里面的所有方法。
抽象类与接口对象的的引用必须指向一个实现了所有抽象方法的子类对象。
多态需要方法的重写,子类继承父类重写父类中已有或抽象的方法,比如有两个用户,两个用户都可以登录,但是登陆后要显示不同的页面,进行不同的操作,两个客户都会继承抽象父类的Login()方法,并重写。
从设计层面来说,抽象类是模板式设计,作为很多子类的父类,有着子类共同的东西,表明是什么东西。而接口是行为的规范,是辐射式设计,是除了子类公有的属性外一种附加的行为,就可以设计为接口。
final关键字
final定义的变量都要进行显示初始化,final修饰的变量不能更改地址,但是可以更改里面内部属性。对于一个final变量如果是基本数据类型的变量,数值一旦初始化之后便不能更改了,引用类型的变量初始化之后便不能再让其指向另一个对象。final变量是基本数据类型以及String类型时,如果编译期间能知道确切的值,编译器会把final定义的当为常量来使用。
final修饰的方法不能被覆盖改变,private方法会隐式的指定为final方法。
final修饰的类不能被继承并且里面所有的成员方法都会被指定为final方法。
static关键字
静态变量是所有对象所共享的内存中只有一个副本,static方法就是没有this的方法,在static方法内部不能调用非静态方法与变量,因为static方法不用创建对象就可以调用了,this指向的是创建对象的引用,没有创建对象哪来的this。只要类加载了就可以通过类名进行访问。
static的代码块,类初次加载的时候,会按照static块的顺序一次执行, 每个static代码块只会执行一次,进行初始化条件的操作都会放到static代码块中,减少空间浪费提升效率。
static方法能不能被重写
java中的静态方法可以被继承,但不能重写。但子类如果有个方法名并且参数都一样的方法并且也用static关键字修饰,那么子类会把父类方法隐藏而不是重写并且不支持多态输出的还是父类的方法并不是子类的实现。因为重写(覆盖)是基于运行时的动态绑定的,static方法引用的时候是用类名来调用的是编译时静态绑定的,static方法和类的任何实例都不想关。这也是为什么abstract修饰的方法不能同时定义为static,abstract方法要求子类去重写并且实现,属于实例对象的。
java中也不可以覆盖private方法,因为private变量修饰的变量和方法只能在当前类中使用,其他类继承当前类不能访问private变量和方法的,当然也不能覆盖。
请简要概述一下枚举如何替换静态常量的
jdk1.5之后有了枚举,可以替换以前定义静态常量常用的public static final ...,增加了代码的可读性。以前的switch只支持int,有了枚举之后可以使用char来进行switch的判断,枚举中也可以定义构造器通过get方法可以获取构造器中设置的值,通过values方法可以遍历枚举然后获得里面的所有值,提升了代码的可维护性。
this与static的关键字
this代表的是当前对象,用new的方式创建的对象来调用的方法this就是该对象。用static定义的是全局变量被所有对象锁共享,不用static定义的则是局部变量,用当前对象new的this调用的可以是static全局变量但不能是方法里面定义的局部变量。而且static是不允许修饰方法内的局部变量的。
关于super()的理解
子类继承父类,如果出现了同样的成员变量与方法就会发生隐藏现象,子类的成员变量会隐藏父类的同名成员变量,如果要访问父类的同名成员变量,用super关键字来引用。隐藏只针对成员变量和静态方法,而覆盖针对普通方法。
如果一个类没有提供任何的构造函数,编辑器将增加无参数的构造函数,如果没有的话子类是无法编译通过的,因为任何构造函数的第一句话都是隐式调用super()。父类有参数的构造函数,子类可以通过super(parameter1,parameter2...)显示的调用父类构造器,并且在子类构造器中,必须是子类构造器的第一个语句。
成员内部类的继承内部类的引用方式为 Outter.Inner,并且构造器必须有指向外部类对象的引用,这个引用必须通过.super()的方式来获取。
介绍你所熟悉的设计模式
模板式设计,每个类只能继承一个类,在要继承的类中必须必须继承或编写出所有子类的所有共性,抽象类的功能远超于接口。
辐射式设计,对行为的一种规范,虽然接口在功能上会弱化许多,但是只是针对一个动作的描述。在类中可以实现多个接口。
建造者模式,使用一个简单的对象
请简要的说说在开发的时候如何初始化对象与数组的
js对象可以通过定义{}和下标的方式创建对象,js的对象类似于key-value的形式,可以通过key来定义与获取。js的对象除了可以通过下标的方式来定义外,还可以通过类似于java类对象属性的方式来定义,如定义一个对象 object= {} object.name="www"的方式定义对象。
js也可以通过构造函数的方式创建对象,通过function和this的方式创建,然后通过new 构造函数即可。
js销毁对象,因为js有自己的垃圾回收机制在对象没有引用的时候就可以自动销毁了,可以通过对象=null的方式进行,也可以通过delete obj.name的方式删除对象中的属性。
js的数组是通过定义[]的方式来创建的,可以往数组中动态push对象的方式添加js对象。js的数组都有默认的下标0、1、2...js的数组也可以通过下标的形式获取,通过[][]先获取第几个数组中的元素,然后通过key-value的形式每一个数组元素中的具体的值。
js也可以通过new Array()的方式来定义数组,这种方式相当于Java的new ArrayList();一样,相当于每次调用这个方法的时候就会进行初始化数组,一般用于需要每次都获得一个新数组进行操作。
js中还可以通过prototype将在原型原型上添加属性,可以将通过的属性还有代码放在里面,所有的对象实例可以共享原型对象中的方法和属性节省空间。注意不能通过对象实例改变原型对象中的属性和值,因为实例对象获取某一属性时从本身开始查找的,然后才是原型对象,最后才是构造函数对象,不能改变其中的值,可以通过delete操作符进行删除。
java中创建对象的方式,类构造器是创建java对象的途径之一,通过new构造器完成对象的实例化,创建对象还可以通过反射class类的newInstance()方法调用类的无参构造方法创建对象,Person p2 = (Person) Class.forName("com.test.Person").newInstance();,也可以通过Constructor类的newInstance()方法实现,以及clone最后也可以通过反序列化的方法实现。
java创建数组,java中可以通过String[] args = {1,2,3}或者String[] args = new String[]{1,2,3}方式直接来定义数组的。可以指定数组的长度并初始化 new String[3];这些都是静态初始化数组。
动态的方式就需要根据获取的集合的长度来确定数组的长度如new Object[list.size()],然后通过循环遍历来指定特定元素的值如object[i] = “www”;
数组的定义与二维数组的定义
可以new 类型[长度] 的方式定义数组,或{}大括号的方式定义,或new Object[]{arr}的方式定义
数组有什么方法
集合框架的理解
ArrayList用数组来存储元素的,数组是动态创建的,如果元素超过了数组的容量则会自动扩容 无序重复的
LinkedList 链表存储元素所以是有序的
set集合是不重复的
字符串与数组和集合的转换
集合转为数组 list.toArray(new String[list.size])。
数组转为集合 Arrays.asList(arr),arr可以使字符串通过split(",")转为数组也可以直接传入逗号隔开的数组,然后通过contains方法来判断数组中是否包含某个值了。
有时候还要将集合转为字符串就需要StringUtils的join方法将集合或数组中的每一个元素通过","合并成字符串。
遍历集合
for(string item:items)也可以通过普通的for循环遍历集合通过size()判断遍历次数。
可以通过流的方式遍历数组和集合list.forEach(n->sys(n))
构造集合遍历器 list.iterator()然后通过while循环it.hasNext获取每一个值it.next();,遍历Map一般使用iterator,首先通过keySet获取所有的key,然后通过遍历就可以获取Map中的key了。使用entrySet获取的是一个映射集合,通过该映射集合通过getValue()获取的值要进行强转相应的类型才可以使用,当然也有listIterator可以专门遍历List集合。使用iterator()的remove()还可以一边遍历一边删除集合中符合条件的值。
遍历map集合的方式有values可以获取所有的值没有键,Map.keySet()将所有的key放到set集合中,因为set集合具有遍历器可以根据get方法获取所有的值,map.entrySet()返回映射中包含映射关系的Set视图,就是把(key-value)作为一个整体一对一对地存放到Set集合当中的,迭代后可以获取key也可以获取value,注意keySet的性能不如entrySet的性能好。
js的for(key in items) 获取的是下标,当然js中用的最多遍历集合的方式还是通过each的方式进行遍历的等价于forEach()方法。
去除集合中的重复元素
转为HashSet new HashSet<String>(list) 最后在返回list return new ArrayList<String>(set)
如何对集合或数组进行进行排序
实体实现Comparable接口,重写compareTo方法通过返回正数表明正序,返回负数表明倒序,返回零表明相等,然后通过Collections.sort(list)进行排序即可。也可以Arrays.sort()传入Comparator和数组根据指定的内容进行排序。
Map集合可以根据Comparator比较器进行排序,然后重新生成一个排序好的Map,也可以将Map集合转为list集合通过Collections.sort传入list集合通过Comparator比较器进行升序与降序的排列最后再将排好序的list转为Map即可。也可以将list转为key与value都相同的Map然后通过TreeMap的key自动进行升序或者降序的排序。
对象与集合的排序
通过实体类实现comparable接口、实现里面的compareTo方法,return当前类与this调用类的-1,0,1进行比较、最后通过Collections.sort(list)即可实现集合的排序
对于HashMap则需要通过key值进行排序、首先要讲HashMap转为ArrayList、然后还是通过Collections.sort传入list,自己实现比较器Comparator就可以通过value进行排序了...
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() {
//升序排序
public int compare(Entry<String, Integer> o1,
Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
HashMap与HashTable的区别
HashTable不支持Null value,并且是线程安全的。都有一个Synchronize方法
HashMap效率比较高
请说一说集合有什么方法
可以通过Arrays.toString()的方法将数组转为字符串,也可以通过Arrays.asList()可以将数组转为集合,list.toArray()集合转为数组。Arrays还有sort排序、fill填充等方法。
List集合的add方法将元素添加到集合中,还有addAll()方法
Map集合判断是否包含某个元素通过map.containsKey();List直接通过contains()方法判断即可。
js中集合的操作方法join()默认的情况下通过逗号来合并数组中的每一个元素,split()将字符串转为数组,push将元素添加到数组末尾,reverse()反转数组的顺序,sort()排序,shift()删除并返回第一个元素。pop删除数组最后一个元素,并返回被删除的元素,splice()万能删除函数,slice()截取数组,concat数组拼接函数。
js中判断数组中是否包含某个元素可以使用jquery自带的$.inArray()方法即可,也可以使用hasOwnProperty()判断数组中是否包含某个指定的元素。
请简要概述hashCode与哈希算法
哈希表是一种数据结构,它可以提供快速的插入和查找操作。在一般的线性表、树中,记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定关系,查找效率依赖于比较次数。哈希表的存在就在存储位置和关键字之间建立了一个确定的对应关系,使得每一个关键字和结构中的一个唯一的存储位置相对应。
哈希表不可避免的是冲突现象,如根据名字为关键字,刘丽与刘兰地址都是24造成了冲突,我们可以根据某种规律选择其他的位置,其中有一些选择其他位置的算法。
关于hashCode基本所有的程序设计语言都会设计到,主要为了配合散列集合,有HashSet、HashMap、HashTable。当向集合中插入数据的时候如何判断集合中已经有数据了,用equals()进行比较效率是一个很大的问题,hashCode的作用就体现了。添加新的对象时,先调用hashCode方法得到对应的hashCode的值,实际上hashMap中的一些方法的实现都会有一个table用于保存hashCode的值,如果table中没有值,则直接插入不用进行比较了。
hashCode返回的并不一定是对象的存储地址,有些JVM在实现时的确返回对象的存储地址 ,但大多数情况下只是存储地址的一种对应关系,所以并不能直接通过hashCode判断两个对象是否相等的,因为不同的对象可能会根据某种对应关系产生相同的hashcode的值,但如果两个对象的hashCode值不同,一定不是同一个对象。
java的基本类型和引用类型
基本类型8个byte short int long float double char boolean。基本类型在创建的时候,在栈上给其划分一块内存,将数值存在栈上。8中基本变量直接存储的是"值",因此用关系运算符==来进行比较的时候,比较的是"值"本身。
引用类型 类类型、接口类型和数组和枚举等如String。引用类型创建的时候,要给栈上分配一块内存,对象的具体信息都在堆内存上,栈上面的引用指向堆中对象的地址。 引用变量存储的并不是“值”本身,而是其关联的对象在内存中的地址。
java将内存空间分为堆和栈,基本类型直接在栈中存储数值,基本类型保存原始值。引用类型将引用放在栈中,实际存储的值在堆中通过栈中的引用指向堆中的值,保存引用值(对象在堆中所在的位置/地址)。
解释一下java的装箱与拆箱
java的每种数据类型都提供了包装类型,在java5之前要生成一个为5的Integer对象必须要通过 Integer i = new Integer(10)的写法,java5之后提供了装箱特性直接通过Integer i = 10;自动将基本数据类型转为包装数据类型,int n = i,就是将包装类型转为基本数据类型。
装箱调用的是Integer.valueOf(int)方法,而拆箱调动的是Integer.intValue()方法,如果数值在[-128,127]之间,就会指向已经存在的引用,否则会创建新的引用,而Double和Boolean是不同的实现。
java的值传递和引用传递
值传递将一个参数传递给一个函数(或方法)时,函数接收的是原始值的副本,如果参数被函数修改了,改的只是副本。原值可以不变。若引用传递,当将一个参数传递给一个函数的时候,函数接收的是原始值的内存地址,而不是值的副本。因此当这一个参数被函数所修改,调用的原始值也会随之改变。
如果传入的参数被定义为final,由于java采用的是值传递,对于引用变量,传递的也是引用的值,也就是说让实参和形参同时指向了同一个对象,因此让形参重新指向另一个对象对实参没有任何影响。
说明一下Integer i = new Integer(10)与Integer i = 10的区别
第一种方式不会触发自动装箱,第二种方式会触发。但第二种方式的执行效率和资源占用率比第一种方法好一些。
判断 Integer i1 = 100;Integer i2 = 100;Integer i3 = 200; Integer i4 = 200; i1==12 i3==i4输出什么输出true,false,通过valueOf创建Integer对象,如果数值在【-128,127】之间便返回IntegerCache.cache中已经存在对象的引用,否则创建一个新的Integer对象。Double的valueOf方法和Integer的ValueOf是不同的实现,都会是false不会从缓存中获取的。
字节与字符有什么区别
字节是存储容量的基本单位,字符由数字,字母,汉字以及其他语言的各种符号,1个字节等于8个二进制单位;一个字符由一个字节或多个字节的二进制单位组成。
字符char是没有符号的,取值范围是[0-2^16-1]。
String是值传递还是引用传递
String是引用类型,在java字符串常量池的机制下,声明或连接字符串常量均需要用到字符串常量池,若常量池中有该字符串序列则返回。
String str="scce"; //创建了一个对象,于栈上分配内存
String str2="scce"; //指向一个对象,不是新建
str==str2返回true //==判断的是否为同一个引用地址,是同一个内存地址
String str2=new String("scce"); str==str2返回false //新建了一个对象,内存地址不一样,于堆上分配内存!
当String调用intern方法之后,首先会检查常量池是否含有该字符串,如果有机会得到相同的引用。注意采用new的方式创建的字符串不会进入常量池的。
字符串的相加String d = "a" + "b"; String e = "b"; String f = "a" + e;都是采用静态字符串的结果添加到字符串池,如果其中含有变量则不会进入字符串池了。
初始化字符串String abc = "" 与String abc = null有什么区别
String abc = null未分配堆内存空间,String abc;分配了一个内存空间没有存入任何内存对象也就是没有初始化的引用,String abc = "" 分配了一个内存空间并且分配了一个字符串对象。
如果是null的话,调用abc.trim()会报错,所以一般推荐使用String abc = ""避免了很多时候判断字符串是否漏掉了这种情况,调用String的方法的时候也会出错。
请说一说字符串有什么方法
js中用的比较多的是indexOf和contains()方法判断字符串是否包含某个元素。或者search方法以及test()match()等四则方法判断字符串中是否包含某个元素。字符串可以通过split()方式转为数组然后遍历数组通过StringBuilder的append()方法获取新的数组。
字符串还有replaceFirst(",","")方法把传到后台拼接的字符串的第一个逗号去掉。
length()长度、charAt()截取一个字符、setCharAt(),getChars()截取多个字符,getBytes()、toCharArray()将字符串转为字符数组,equals()与equalsIgnoreCase()、regionMatches()比较字符串的一个特定区域与另一个特定区域。startsWith()与endsWith()是否以特定字符串开始与结束。compareTo()与compareToIgnoreCase()比较字符串。indexOf()字符串第一次出现的地方,lastIndexOf()查找最后一次出现的位置。substring()截取字符串,concat连接两个字符串,repace()替换,trim()去掉前后两边空格,String.valueOf()转为字符串,toLowerCase()转为小写 toUpperCase()转为大写,capacity()可分配容量,append拼接字符串。reverse()颠倒字符串,subSequence()截取字符串,join()方法,codePointAt()方法
Math都有什么方法
Math.sqrt()求平方根,cbrt()立方根,pow(a,b)b次方,max计算最大值min计算最小值,abs绝对值,ceil()逢余进一,floor()向下取整,rint()四舍五入返回double,Math.round()四舍五入 float返回int double返回long,Math.random()随机数。
String str = new String("abc")创建了多少个对象
new在代码运行期间只创建了一个对象在堆上,而s只是一个引用变量。“abc”本身就是常量池的一个对象,在运行new String()的时候把常量池的字符串复制出来在堆中,并且交给了s,所以创建了两个对象,一个在常量池中,一个在堆中...如果是String str1 = new String("abc")String str2 = new String("abc")就一共创建了三个对象了。
String、StringBuilder、StringBuffer的区别
String类是被final修饰的,String类不能被继承,并且他的成员方法都默认为final方法,不会被覆盖,String对象的任何改变都不会影响原对象,都会生成一个新的对象。String其实通过char数组来保存字符串的。
String str="hello world"和String str=new String("hello world")的区别,JVM的执行引擎首先回去运行时的常量池查找是否存在相同字面常量,如果存在则直接将引用指向已经存在的字面常量,否则在常量池开辟一个空间来存储字面常量。new生成的对象实在堆区的,而在堆区生成的对象不会去检验对象是否已经存在的,通过new创建的一定是一个新的对象,而String str="hello world"如果字符串内容相同则是同一个对象。
String+=“hello”就是通过StringBuilder对象append()方法来实现的,最后通过toString()返回字符串。StringBuffer只多了一个synchronized关键字,多线程起到了保护的作用,是线程安全的。
如果字符串相加操作或改变较小的情况下,建议使用String str = "hello",在字符串相加较多的情况下,建议使用StringBuilder,多线程使用StringBuffer
String b = "hello" + 2 和String b = "hello"; String c = b + 2;返回的不是一个对象, b + 2不会当做字面常量来处理,生成的对象是在堆上的,不是同一个对象。inal String b = "hello"; final修饰之后,class文件的常量池会保存一个副本,会优化返回同一个对象。
java中字符串与数组的转换也可以通过遍历,获取数组中的每一个值,然后通过StringBuilder或StringBuffer的append()放来进行拼接,最后toString()即可。
a=a+b与a+=b的区别
a+=b执行的实际过程先计算a的值,然后用一个temp的对象存储,之后和b进行相加,将值赋给a引用。+=如果两边的操作数的精度不一样,会自动向低类型转换。
a=a+b先计算a+b然后赋值给a的引用,不会自动类型转换,需要手动类型转换不然会产生错误。
同理如果是short s1=1;s1=s1+1;s1+1在运算的时候会自动提升类型为int型,将int赋值给short会报错。short s1=1;s1+=1则可以正常编译通过。
除此之外a+=b的效率会高一些,会在编译期间进行优化减少append等相关操作。
java双重for循环如何使用的
双重for循环可以按照某一个规则例如日期月份等等的顺序进行集合的排序,同时也可以进行补零的操作。
for循环外层遍历的是循环的次数,内层遍历的是比较的次数,内层的if条件判断左边是最外层要进行比较的值,右边则是内层循环的值,进行比较是否相等,如果满足了条件说明符合外层的数组或集合的排序规律。
关于for循环补0操作,可以设置标识符,如果内存的for循环结束了都没有改变这个标识符,则表明是要进行补零的操作。
也可以使用while循环搭配迭代器listIterator进行外循环,控制循环的次数,和内层循环进行比较,实现去除集合中重复的元素。
简要说说java的循环控制语句continue、break、return
return返回的值在运行期间才能确定,并不是同一个对象。
简单的说一说equals与==的区别
==如果两边的操作数都是包装类型的引用,则比较指向的是否是同一个对象,如果其中一个是操作数表达式含有算术运算符,则比较的是数值,如果两边都是基本类型则比较的是"值"是否相等。
equals()方法是基类Object中的方法,因此所有的继承于Object的类都会有该方法,有许多的包装类型都是通过重写equals()来比较所存储的内容是否相等。
equals()不能用作基本类型的变量,equals()方法如果是包装类型,并不会进行类型转换。会先触发自动拆箱过程,再触发自动装箱过程,c.equals(a+b)会先各自调用intValue方法,得到加法运算后的数值后,便调用Integer.valueOf()方法,如果类型是Long的话则调用Long.valueOf()方法进行自动装箱的,如3L.equals(1+2L)//true 3L.equals(1+2)//false。
当一个类如String重写了equals()方法的时候,必须要重写hashCode方法,让equals()方法和hashCode()方法始终在逻辑上保持一致。
js中==与===有什么区别
==用来比较是否相同,===用来比较是否严格相同,用==号的时候,会先检查两个操作数的数据类型如果相同则会进行===比较,如果不同则会做类型的转换,转为相同的类型然后去比较;如果是===比较的时候,类型不同则会直接返回false。
==如果一个是null一个是undefined则相同,如果一个是字符串一个是数值则会转换后进行比较。
===如果两边都是数值并且一个是NaN那么不相同,通过isNaN()来判断是否为数值数字。如果相同的字符串、相同的true或false、两边的值引用同一个函数或对象、两个都是null或undefined则相同。
判断是否为空
字符串判断为空通过spring框架或者Apache commons lang3的StringUtils进行判断,有isEmpty方法以及isBlank方法,isBlank方法还判断是否为空格制表符"\t",回车符"\r","\n"等,whitespace只能用于判断是否为空串不能判断是否为null,除此之外还有apache还有isAnyBlank,isAnyEmpty,只要有一个为空就为true,isNoneBlank,isNoneEmpty只要有一个为空就为false,这四个方法是用于判断多个字符串是否为空;
Object类型是否为空要根据instanceof判断如果是字符串则需要通过引用是否为空null==以及值是否为空"".equals()。其他的Date、Integer、Double类型的只需要判断引用是否为空即可。
集合(Collection、Map)可以通过引用null==以及长度size()==0是否为0判断为空,也可以通过apache下的common包的CollectionUtils的isEmpty()进行判断。java的util下Collection也有判断集合是否为空的方法isEmpty()不过判断的仅仅集合是不是包含元素,自己还需要手动判断是否为null才行。
判断数组是否为空需要判断引用是否为null==以及长度是否为0 s.length == 0(java中判断字符串是否为空str.length() == 0);
js字符串判断是否为空要通过是否为""和undefined以及null来进行判断的,也可以根据type来判断类型是否为string、array、date、object类型,判断object是否为空可以直接根据$.isEmptyObject进行判断。
js判断数组是否为空可以先判断类型是不是Array然后判断是否为undefined最后判断length长度是否为0进行判断。
请简单的说说java中的对象和引用
什么是对象,java有个思想叫"万物皆对象",每个对象都是类的一个实例,比如说人类是一个类那么张三就是他的一个对象了。
对象的引用,Person person: person = new Person(“张三”);person = new Person(“李四”)。 java的new 是要在堆上创建对象的,此时的person只是一个引用,是一个可以指向person类的对象的引用,真正的创建对象的语句还是new Person(“张三”)。然后又指向了李四,person只是一个类的引用,可以指向任何Person类的实例。
一个引用可以指向多个对象,一个引用也可以被多个对象所指,Person person2 = person1。
java的序列化与反序列化用在什么地方
序列化就是把堆内存中的Java对象数据,通过某种方式写到流上便于传输和存储在磁盘文件或传递给其他的网络节点,这里写到流中的对象是原始对象的一个拷贝,因为原始对象还存在JVM中。
反序列化就是把磁盘或网络节点上的对象数据恢复成Java对象模型的过程,可以通过序列化产生克隆对象然后通过反序列化获取这个对象。
每个序列化的类都要事先Serializable接口,如果某个属性不需要序列化,则声明为transient即可。
IO流的分类
根据数据流可以分为输入流和输出流,输入流将外界的数据(键盘、文件、网络)输入到程序,输出流将程序中的数据输出到外界(显示器)。也可以分为字节流:数据流中最小的数据单元是字节一般用于传输图片、视频等等。字符流:java中的字符是Unicode编码、一个字符占两个字节。
OutputStream是字节流可以处理任何类型的数据,而PrintWriter是字符流,只能处理字符数据。RandomAccessFile随机文件操作流,可以从文件任何位置开始进行存取。
字符流与字节流的区别,字节流本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流使用了缓冲区,在关闭字符流时会强制的将缓冲区的内容进行输出,如果程序没有关闭,也可以通过flush()完成输出,否则缓冲区的内容无法输出。
如何使用IO流显示图片
File imageFile = new File(路径+图片名.jpg) FileInputStream fis = new FileInputStream(imageFile)然后一个字节一个字节的读取文件byte[] b = new byte[1024];while((len = fis.read(b))!=-1) 最后通过HttpServletResponse获取ServletOutputStream的实例sos进行写的操作sos.write(b,0,len);
如何利用IO流下载文件
使用HttpServletResponse对象就 可以实现文件的下载了,文件下载的实现思路,获取要下载文件的绝对路径,获取下载的文件名,设置content-disposition响应头控制浏览器以下载形式打开文件response.setHeader(“conten-disposition”,“attachment;filename=”+fileName),获取要下载的文件输入流,创建数据缓冲流,最后outPutStream将缓冲区的数据输出到客户端浏览器。
通过ServletOutputStream和FileInputStream进行文件的下载,File file = new File(fullname); ServletOutputStream out = response.getOutputStream();FileInputStream fis = new FileInputStream(file);可以设置response对象response.setHeader("Content-Length", String.valueOf(fis.available()));设置下载文件的大小。
下载文件的时候,中文文件名要使用URLEncoder.encode方法进行编码,否则则出现文件名乱码response.setHeader(“content-disposition”,"attachment;filename="+URLEncodere.encode(fileName,"UTF-8"))
请说说NIO的概念与理解
NIO关键的概念是:Channel(通道),Buffer(缓冲区),Selector(选择器),传统的InputStream实际就是读取文件的一个通道是单向的,OutputStream只能进行写操作。
NIO中的Channel则是双向的,既可以用来读操作,也可以用来写操作,有FileChannel可以从文件读取或向文件写入数据,SocketChannel以TCP向网络连接的两端读写数据,ServerSocketChannel能够监听客户端发起的TCP连接,DatagramChannel以UDP协议来向网络连接两端读写数据。
在NIO中所有数据的读和写都离不开Buffer,而且是必须的读取的数据只能放在Buffer中,写入的数据也只能写入Buffer中。
在NIO中最核心的一个东西便是Selector,用来轮询每一个注册的Channel,一旦发现Channel有注册事件的发生,便获取事件然后进行处理。
具体的使用通过输出流获取FileChannel channel = outputStream.getChannel(); 然后获取Buffer缓冲区 ByteBuffer buffer = ByteBuffer.allocate(1024) ,然后将要输出的文字放入缓冲区中buffer.put(string.getBytes()),调用channel的方法必须要调用buffer的flip方法,否则无法正确的写入内容,最后关闭channel和outputStream。
java内部类的意义
内部类就是在一个类中定义另外的一个类,定义内部类可以访问外部类的所有方法和属性,包括私有属性,java单继承就可以实现多继承了。每个内部类都能独立的继承一个借口的实现,内部类使得多继承成为了可能。内部类可以将存在一定逻辑关系的类组织在了一起,又可以对外界进行隐藏。方便编写线程代码与事件驱动程序。
成员内部类可以无条件的访问外部类的所有成员属性和成员方法包括private成员和静态成员,如果有和外部类相同的成员变量和方法会把父类的隐藏,要想访问外部类的同名成员,需要使用外部类.this.成员变量即可。成员内部类必须依赖外部类的实例化对象。创建成员内部类对象 外部类类名.内部类类名 xxx = 外部类对象名.new 内部类类名()。
局部内部类,定义在一个方法或一个作用域里面的类,访问权限仅限于方法内或者改作用域内。
匿名内部类是唯一一个没有构造器的类,只使用一次比较方便。需要某一个对象,通过传入一个接口或类的实现即可如(new Method(){ @override public void InnerMethod(View v){ }}) Class InnerMethod implements OtherMethod,这样匿名内部类能够在实现父类或者接口中的方法的情况下同时产生一个相应的对象。
局部内部类和匿名内部类的局部变量和形参必须都是final定义的,因为局部变量的值在编译期间就确定了,则直接在匿名内部类内部创建一个拷贝,如果局部变量的值无法在编译期间确定,则通过构造器传参的方式进行拷贝和赋值。
静态内部类是不需要依赖外部类的,并且不能使用外部类非static成员变量和方法。创建静态内部类对象的一般形式 外部类类名.内部类类名 xxx = new 外部类类名.内部类类名();
java的异常
检查形的异常 用try catch 或者throws,这种错误一般是由程序运行在未知环境导致的,程序员无法进行干预的,SQL IO ClassNofFoundExection,这些异常是我们可以进行处理的。通过try...catch进行捕获,然后再catch块中进行相应处理,还有一种方法是让调用的地方去处理,在方法中没有进行异常的处理,但是调用了这个方法的时候要进行try...catch进行处理了,如createFile() throws IOException { },throws表示异常的一种可能,并不一定会发生,thrwos后面可以跟多个异常类型如throws FileNotFoundException,ParseException。也可以通过throw手动抛出异常,如 if(index<0||index>=data.length) throw new ArrayIndexOutOfBoundsException(“数组下标越界”),然后再cathc中获取即可 catch(Exception e){e.getMessage()}
非检查形的异常 Error RuntimeException 这种异常往往是代码写的有问题 NullPointer ClassCast ArrayIndexOutOfBounds 。spring对RuntimeException 异常才会有回滚作用。
在try ... catch ... finally 中无论catch块中是否包含return 语句,都会执行finally,而且要把小的异常放在catch的最前面,否则后面的catch永远捕获不到,千万不要在finally中使用return,否则会覆盖catch的return,finally一般进行资源的释放如文件的读取和网络的操作以及数据库的操作等等。
关于继承中异常的使用,如果父类没有使用异常,则子类重写该方法的使用不能声明异常,并且子类重写该父类方法的异常不能是该异常的父类,如果父类声明的异常只有非运行/运行时异常,则子类也只能是同样类型的异常。
异常会严重的影响性能,如果是if 或boolean变量来进行逻辑判断的话,尽量少的使用异常,从而避免不必要的异常捕获。也不要捕获异常后什么都不做,切忌使用空的catch块,空的catch块意味着忽略了错误,可能会导致不可控的运行结果。如果异常不处理最后也以日志的方式进行显示,方便进行维护。
尽量少的使用检查型的异常,如果确实需要调用者处理的话,可以使用。一般用非检查异常,交由上层处理。
java的自定义异常的使用
自己定义一个类继承Exception或RuntimeException,然后写无参的构造方法和有参数的构造方法,然后在调用的时候通过throw new 自定义异常类名("XXX")设置参数,通过MyException ex ex.getCode()来获取参数与进行页面数据的渲染即可。
简单说一说vue的机制
vue为渐进式JavaScript框架(可只使用其一部分功能),Mvvm框架实现数据与试图双向动态绑定,数据发生变化通过指令或双括号表达式渲染到前台。
vue类似于java有个new的实例。有个el和data属性,el为渲染哪一个容器里,data里面的属性与值可以自定义,vue-devtools插件可以调试vue进行调试。
请说一说你所知道的vue指令有哪些
v-text/v-html 作为文本或作为html标签解析,v-if v-else 成队出现的,v-show加入display样式,
v-for循环(对象 索引) in data中的内容,v-bind绑定属性(只能通过vue对象的data里面进行绑定) :style(v-bind的省略写法) 可是使用驼峰写法。v-model双向数据绑定 v-once之绑定一次
计算机安全方面
windows下设置密保,计算机有个锁定功能和切换用户功能,在控制面板可以创建用户并设置密码,可以通过win+L进入锁定页面。
简单的说说有哪些DOS命令
运行jar包 java -jar *.jar
编译java文件 javac *.java
查看编译后的字节码文件 javap -c *
打开画图工具 mspaint
打开记事本 notepad
简要的说明一下你了解那些算法
我的个人理解算法并不难,最主要的就是把问题想清楚了,然后将问题模型化也就是建模,通过图图画画的方式使得问题的本质得以直观的展示,最后只需要通过模型以及一定具体的解决方式将问题实现即可。
算法本质是为了提升性能,可以进行快速的运算。算法本身就是一种思想和语言没有多大的关系,想出来写出来就是算法,编码并不难。数据结构与算法无法分离的,算法+数据结构=编程。
推荐算法(机器学习)、大数据搜索定义、语音识别算法并智能回应算法、人脸识别(计算机识别)、动画3D虚拟图形算法、迷宫生成算法、扫雷算法等等
算法思想:分治算法、归并算法、贪心算法、排序选择算法,插入排序算法,递归算法,归并排序算法,快速排序算法,双路排序算法,三路排序算法,Shift Up/Down、堆排序、二分查找法、二分搜索树、层序遍历、树、并查集、路径压缩、图算法、树形结构、prim算法、Krusk算法、最小生成树算法、最短路径和松弛操作、Dikstra算法等等算法,动态规划、最短路径。
排序算法之选择排序法如何使用的
排序算法最优的复杂度级别是O(nlogn),找出最小的数字然后放在第一个位置,然后在剩余部分放到当前进行排序的位置即可。
具体的代码的实现,定义一个方法有两个参数,第一个是数组,第二个是数组的个数。然后两个for循环,第一个for循环中寻找当前[1,n)区间内最小的数,要设置一个中间变量来存储寻找到的当前最小值,判断当前的值是否小于中间变量的值,如果小于则更新中间变量,就可以寻找[1,n)中的最小值,并获取了最小的索引。最后要定义一个方法将i和最小值索引的位置进行交换。
如何使用模板函数或泛型进行选择排序
java基本类型的中有个Comparable类型,通过定义为Comparable类型的数组,并且实现compareTo()方法就可以实现了同一个方法对不同数据类型的数组进行选择排序,如果一个类实现了Comparable接口,并且重写了compareTo方法也可以使用同一个方法传入一样的参数进行比较。
随机生成数如何生成
一般情况下的测试数组都是采用硬编码的,如果是百万数量级的数组应该用程序进行生成的,需要自己定义一个生成随机数方法。通过使用assert关键字,如果rue,则程序继续执行来代替if,然后通过Matn.random来生成随机数和创建定义数组即可。
如何测试算法性能的方法
通过将排序算法还有随机生成的数组作为参数传入算法性能比较方法中,通过反射获取排序算法,根据类名获取类实例,然后获取里面的静态的排序算法实例,通过该方法实例调用invoke(null,param)即可调用该方法,因为调用的是个静态方法,所以第一个参数就不用填写一个已实例化对象了。最后通过 System.currentTimeMillis();来计算时间即可。
请说一下插入排序如何实现的
思想从第一个元素考虑,第一个元素已经排好序了,从第二个元素看和第一个元素比较,这样前两个元素就排序好了。第三个元素跟第二个元素比较之后再跟第一个元素比较,以此类推。
还是双重for循环,外层遍历数组的循环的次数,然后内层的for循环做的事情是当前的i元素的合适的插入位置,因为最适合的位置在前面所以j要从i开始往前面倒,在j大于0(最多考察到j=1的情况)的时候j--。然后判断j当前的位置的值是不是比它前面的值还要小,如果小两个相邻的位置交换就可以了,如果j的值比一开始紧邻的值要打就break跳出当前的循环。
对插入排序的优化,因为插入排序在比较的过程中不断地进行着交换,在考察第二个元素的时候,不是和第一个元素(前面的元素)比较,而是拷贝一个元素(复制副本),然后判断当前位置是不是适合第二个元素,如果不适合则将前一个元素挪(复制)到第二个位置(前一个位置)。然后再继续考察备份的副本是不是适合放在更前一个位置,如果还是小的话,则前一个元素继续往后移动直到为第一个位置不用比较了。实质上就是比较后做了一次的交换。
实现 j=i,j实际上就要要保存元素e要插入的位置(看看元素i是不是应该放在e的位置),然后判断j前面的元素j-1是不是比e要大,如果大说明还不是最终的位置,还要继续循环。 arr[j] = arr[j-1];实现了前一个位置的元素往后挪了一下。
冒泡排序的过程
希尔排序
归并排序算法怎么实现的
复杂度O(nlogn),实现原理归并排序首先把数组分为两部分(log2^8 = 3),先将左边的数组排序然后将右边的数组排序然后归并在一起,然后要对左边和右边的数组进行排序的时候先要把左边的数组分为一半,右边的数组分为一半再排序,当分为一定细度的时候只有一个元素就不用排序了。最后要对已经有顺序的数组进行向上归并,归并到上一个层级之后继续进行归并直到有序。
归并过程,如果左右两个数组都已经排好序,我们首先要辅助的开辟一个新的同样大小临时的数组空间进行归并。然后定义3个索引在数组内追踪(定义变量i,j,k(下一个需要比较的地方)),第一个就是原始数组需要跟踪的位置,另外两个索引就是两个已经排好序的数组当前要考虑的元素,然后将临时数组两个索引进行比较然后放在原始数组索引需要跟踪的地方。