带有物体级重定位的视觉惯性多实例动态SLAM
Ren Y, Xu B, Choi C L, et al. Visual-Inertial Multi-Instance Dynamic SLAM with Object-level Relocalisation[C]//2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022: 11055-11062.
0. 摘要
提出了一个紧耦合的视觉惯性物体级多实例动态SLAM系统,可以在极端动态场景中优化相机位姿、速度、IMU漂移并且重建环境的3D稠密物体级地图。在鲁棒的传感器和物体检测技术的支持下,系统通过增量地将颜色、深度、语义和前景物体概率融合到每个物体中,以鲁棒地跟踪和重建任意物体的几何、语义和运动。另外,当物体丢失或被移出相机视场时,系统可以在重新观测到时可靠地恢复其位姿。作者在现实世界数据序列中定性和定量地测试了系统的鲁棒性和准确性。
1. 引言
物体层面的跟踪和建图不需要依赖于什么物体是静态的先验信息,而是通过推断来实现,可以应对包含很多潜在动态物体的大型静态环境。
先前的动态物体SLAM工作的局限性:(1)预先设定动态、静态物体的语义标签;(2)假定动态物体不会占据相机视场主体;(3)只在非重复性动态设定中评估,造成重复的物体建模。
本文,以紧耦合方式读取IMU、RGB-D数据,估计相机位姿、速度 和 IMU漂移,这个过程中保持重力方向可观测,对于创建有意义的物体地图来说非常重要,进一步的,为了在一个更大场景鲁棒跟踪物体位姿,通过使用基于关键帧的特征匹配恢复先前建构建的模型,引入物体重定位步骤。它在物体级地图和新的观测之间建立可靠的数据关联,减少了机器人在大范围探索时物体地图的重复。

动态场景重建结果:第一行-输入的RGB图,第二行-语义融合,第三行-几何重建
主要的贡献有三个方面:
- 第一个紧耦合稠密RGB-D-Inertial物体级多实例动态SLAM。
- 提出了一种物体重定位方法,以恢复在视场中消失又出现的物体。
- 在从小尺度到房间大小的动态环境中进行了广泛测试,验证有效性和鲁棒性。
2. 相关工作
2.1 物体级动态SLAM
从[13]开始,物体级动态SLAM被认为是一个SLAM领域的一个重要议题,因为它对机器人理解周围包含动态物体的环境来说非常重要。这样一个系统的目标是检测和跟踪动态物体,同时在这样的动态环境中鲁棒地估计传感器位姿。有了稠密SLAM领域的极大进步[2],[14](KinectFusion,ElasticFusion),近年来跟踪物体的不同方法也被纳入进来。[6](Co-Fusion)的工作中,使用运动残差跟踪环境中移动的物体,[7](MaskFusion)中使用实例分割持续地将颜色和几何信息融合到每个物体独立的地图中。上述工作的物体地图表示是基于ElasticFusion[14]中构建的表面,而表面不能提供未占用的空间信息以辅助机器人应用。相反,MID-Fusion[8]利用高效存储的八叉树表示SDF,并且进一步对检测到的物体进行语义融合。在提高这些系统的稳健性和准确性方面已经取得了重大进展。EM-Fusion[15]提出直接将物体SDF与输入帧对齐来估计物体位姿。另一方面,DetectFusion[16],将2D物体检测和3D几何分割结合起来,以检测和分割语义上未知的物体的运动。
与视觉静态SLAM类似,而不是想大多数稠密SLAM系统那样交替优化跟踪和建图(如[17](DSO)中所解释的那样),另一个方向是在地图和位姿制定联合概率推断,以获得更高的物体跟踪精度[18],但需要牺牲稠密地图表示。DynaSLAM-II[9]使用稀疏点云表示物体,并且在一个位姿图优化中联合优化相机位姿、物体位姿以及几何。ClusterSLAM[19]将物体检测和跟踪定义为路标运动的聚类,并将其作为批优化问题来解决。在此之后,他们将其重新制定为在线VO SLAM,同时考虑语义检测[20](ClusterVO)。
以前的工作已经探索了使用一个运动模型来跟踪物体,如[7],[8](MaskFusion,MID-Fusion),例如,使用一个零速度模型跟踪物体,[9](DynaSLAM-II)中的工作使用了恒定速度模型,而[20],[21](ClusterVO,State Estimation for Robotics)使用了加速时的白噪声先验。然而,这些运动假设可能不足以描述任何物体的真实运动,特别是当物体在相机视图中消失再重新出现的时候。在这项工作中,我们放弃了对运动先验的需求,并将基于关键帧的特征匹配和稠密残差验证阶段相结合,制定了物体重定位管线。
2.2 视觉惯性里程计/slam
近年来,通过融合IMU和相机数据来估计机器人位姿越来越受欢迎,因为它在许多机器人应用中被证明是稳健和准确的。VIO/VI-SLAM通常有两种方法:松耦合系统和紧耦合系统,早期的VIO系统通过IMU和相机观测独立地估计机器人位姿,然后后期融合在一起,这种松耦合方法能够降低计算复杂性,如[22]。然而,随着处理能力的提高,最近最先进的VIO系统采样紧耦合方法,通过考虑所有状态之间的所有相关性联合优化所有状态,同时利用IMU和相机观测,如[23],[24](LSVO,MSCKF)。
另一种对视觉惯性估计问题的分类策略是评估其是使用了递归滤波还是批处理非线性优化的方法。递归滤波方法从视觉数据更新状态,并且只使用IMU测量进行状态传播。MSCKF[23]是第一个介绍基于紧耦合滤波的VIO工作。ROVIO[25]同样采用了紧耦合的滤波方法,但是使用了直接光度残差,而不是间接的特征关联。基于非线性优化的方法联合优化视觉误差项和积分后的IMU观测。通过边缘化操作,OKVIS[24]将优化限制在有限的关键帧滑动窗口,在保持试试速度的同时实现了高精度。OKVIS2[26]进一步进行了扩展,从边缘化的观测构建位姿图因子并且进行了回环闭合。ORB-SLAMIII[27]也是一种最近的实时VI-SLAM系统,然而,在修复旧状态时,它会降低过去估计的不确定性。
这些稀疏VIO/VI-SLAM系统在各种环境中显示出稳健和准确的估计。然而,重建的地图过于稀疏,不利于安全的机器人导航和有意义的场景理解。一些研究也着眼于进行视觉-惯性稠密建图。VI-ElasticFusion[28]扩展了ElasticFusion[14],提出了一个能够进行地图变形的稠密RGB-D-惯性SLAM系统。Kimera[29]还使用VIO前端创建了稠密的网格重建,并提供了带有回环矫正的位姿图优化后端。它还可以为场景理解提供语义注释的地图。
即使稠密的VIO/VI-SLAM系统可以稠密地重建全局场景,但它们通常缺乏对场景中物体的感知。许多研究已经对视觉惯性物体级SLAM进行了研究。使用惯性测量、尺度和重力方向变得可以观测。视觉惯性物体级SLAM可以同时为视觉识别[30]和语义建图[31]提供尺度识别和全局定位。通过将物体姿态和形状包含到紧密耦合滤波VIO系统[32]中,还可以进一步改进传感器姿态估计。
然而,大多数现有的VIO/VI-SLAM系统只针对静态环境,尽管IMU提供了传感器自我运动的可靠测量。移动的物体被仔细地从估计的状态中排除。最近的一些工作将其扩展到动态场景中,但物体主要由稀疏的3D地标([33],[34])组成。相比之下,本篇工作以紧耦合的非线性优化方式将IMU与RGB-D传感器测量融合在一起,即使在极端动态场景下,也能提供鲁棒的传感器跟踪,同时密集跟踪和重建场景中每个检测到的物体。我们进一步提供了物体重定位步骤来管理重新访问的移动物体。
3. 系统概览
VI-MID系统在基于八叉树的物体级多实例动态SLAM系统MID-Fusion基础上构建,管线如图2所示,包含跟踪、分割、融合和光线投射四个主要部分,相机位姿通过光度、几何、IMU残差联合优化,在系统运行过程中,动态物体被检测和跟踪,并且通过光度和几何残差细化它们的位姿。最后的融合、光线投射部分与MID-Fusion相同。
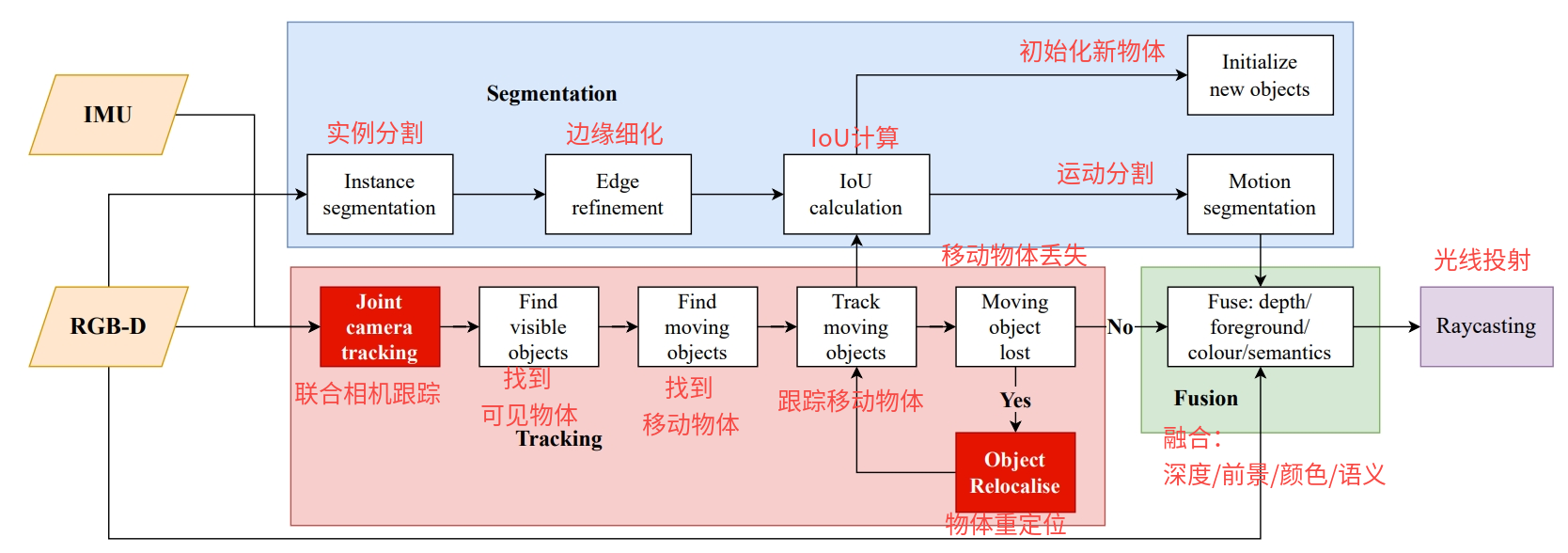
图2:VI-MID系统管线
4. 符号定义
论文中将使用三种不同的坐标系:
∙
\bullet
∙
→
F
W
{\overset{\mathcal{F}}{\rightarrow}}_W
→FW,世界坐标系,与重力方向对齐的第一帧相机位置。
∙
\bullet
∙
→
F
C
{\overset{\mathcal{F}}{\rightarrow}}_C
→FC,RGB-D被观测的相机坐标系。
∙
\bullet
∙
→
F
S
{\overset{\mathcal{F}}{\rightarrow}}_S
→FS,IMU数据被观测的传感器坐标系。
相机和传感器坐标系之间的外部偏移是事先校准的。相机和IMU之间的时间偏移被认为是同步的,可以忽略不计。
5. 跟踪模块
5.1 状态
每次收到一个新的RGB-D测量,跟踪模块在世界坐标系估计RGB相机的位置
W
r
C
∈
R
3
_W\mathbf{r}_C\in\mathbb{R}^3
WrC∈R3 、朝向
q
W
C
∈
S
3
\mathbf{q}_{WC}\in S^3
qWC∈S3,传感器坐标系下的IMU速度
S
v
W
S
∈
R
3
_S\mathbf{v}_{WS}\in\mathbb{R}^3
SvWS∈R3以及陀螺仪和加速度计的漂移
b
g
∈
R
3
,
b
a
∈
R
3
\mathbf{b}_g\in\mathbb{R}^3,\mathbf{b}_a\in\mathbb{R}^3
bg∈R3,ba∈R3。由此组成了特定时刻的系统状态向量
x
\mathbf{x}
x:
x
:
=
[
W
r
C
T
,
q
W
C
T
,
S
v
W
S
T
,
b
g
T
,
b
a
T
]
T
∈
R
3
×
S
3
×
R
3
\mathbf{x}:=[_W\mathbf{r}_C^T,\mathbf{q}_{WC}^T,_S\mathbf{v}_{WS}^T,\mathbf{b}_g^T,\mathbf{b}_a^T]^T\in\mathbb{R}^3\times S^3\times\mathbb{R}^3
x:=[WrCT,qWCT,SvWST,bgT,baT]T∈R3×S3×R3
…因此,局部最小坐标表示为:
δ
x
=
[
δ
r
T
,
δ
α
T
,
δ
v
T
,
δ
b
g
T
,
δ
b
a
T
]
T
∈
R
15
\delta\mathbf{x}=[\delta\mathbf{r}^T,\delta\mathbf{\alpha}^T,\delta\mathbf{v}^T,\delta\mathbf{b}_g^T,\delta\mathbf{b}_a^T]^T\in\mathbb{R}^{15}
δx=[δrT,δαT,δvT,δbgT,δbaT]T∈R15
类似地,我们也定义了一个群操作
⊟
\boxminus
⊟ 作为
⊞
\boxplus
⊞ 操作的逆操作。进一步的细节和更详细的微分处理可以在[24]和[25]中找到。
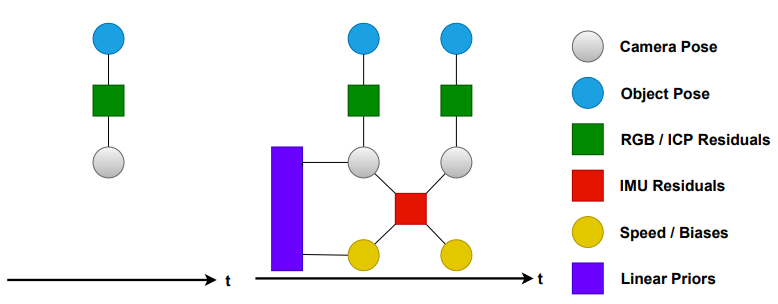
图3:对比MID-Fusion和VI-MID系统中状态变量和观测量的因子图:结合惯性测量引入时间约束,通过速度和IMU偏差增强状态。
5.2 RGB-D-Inertial 传感器跟踪
跟踪问题旨在估计参考状态
x
R
\mathbf{x}_R
xR 和活动状态
x
L
\mathbf{x}_L
xL 。这可以通过最小化代价函数
E
t
r
a
c
k
E_{track}
Etrack 的方式来解决。代价函数包括四项:光度误差(RGB)
E
photo
E_{\text{photo}}
Ephoto,稠密点-面ICP误差(Depth)
E
ICP
E_{\text{ICP}}
EICP,惯性误差(IMU)
E
inertial
E_{\text{inertial}}
Einertial以及非线性优化框架中的边缘化先验
E
prior
E_{\text{prior}}
Eprior。图3展示了这个跟踪代价函数的因子图,并且与MID-Fusion[8]进行了比较。每个误差项包含残差之和
e
e
e,根据各自的测量不确定性
w
w
w 加权(边缘化除外),边缘化先验中作者使用了与[28]相同的边缘化方案,
H
∗
\mathbf{H}^*
H∗ 和
b
∗
\mathbf{b}^*
b∗ 都是通过边缘化参考状态
x
R
\mathbf{x}_R
xR 得到的先验。
E
track
(
x
R
,
x
L
)
=
E
photo
+
E
ICP
+
E
inertial
+
E
priors
E
photo
=
∑
u
R
∈
M
R
w
p
ρ
(
e
p
)
E
ICP
=
∑
u
L
∈
M
L
w
g
ρ
(
e
g
)
E
inertial
=
w
s
ρ
(
∥
e
s
∥
)
E
priors
=
1
2
(
x
R
⊟
x
ˉ
R
−
H
∗
−
1
b
∗
)
T
H
∗
(
x
R
⊟
x
ˉ
R
−
H
∗
−
1
b
∗
)
\begin{aligned} &E_{\text{track}}(\mathbf{x}_R,\mathbf{x}_L)=E_{\text{photo}}+E_{\text{ICP}}+E_{\text{inertial}}+E_{\text{priors}}\\ &E_{\text{photo}}=\sum_{u_R\in M_R}w_p\rho(e_p)\\ &E_{\text{ICP}}=\sum_{u_L\in M_L}w_g\rho(e_g)\\ &E_{\text{inertial}}=w_s\rho(\Vert\mathbf{e}_s\Vert)\\ &E_{\text{priors}}=\frac{1}{2}(\mathbf{x}_R\boxminus\bar{\mathbf{x}}_R-\mathbf{H}^{*-1}\mathbf{b}^*)^T\mathbf{H}^*(\mathbf{x}_R\boxminus\bar{\mathbf{x}}_R-\mathbf{H}^{*-1}\mathbf{b}^*) \end{aligned}
Etrack(xR,xL)=Ephoto+EICP+Einertial+EpriorsEphoto=uR∈MR∑wpρ(ep)EICP=uL∈ML∑wgρ(eg)Einertial=wsρ(∥es∥)Epriors=21(xR⊟xˉR−H∗−1b∗)TH∗(xR⊟xˉR−H∗−1b∗)
其中
ρ
(
⋅
)
\rho(\cdot)
ρ(⋅)是一个鲁棒核函数(使用了柯西损失函数),另外
M
R
,
M
L
M_R,M_L
MR,ML 是掩膜,用于排除无效对应、遮挡环境和动态物体导致的RGB和深度数据的无效测量。
(1)稠密光度残差:光度残差的目的是最小化参考帧
I
R
I_R
IR 和 活动帧
I
L
I_L
IL 中观测到的参考像素
u
R
\mathbf{u}_R
uR 的强度差,其定义如下:
e
p
(
T
W
C
L
)
=
I
R
[
u
R
]
−
I
L
[
π
(
T
W
C
L
−
1
T
W
C
R
π
−
1
(
u
R
,
D
R
[
u
R
]
)
)
]
e_p(T_{WC_L})=I_R[\mathbf{u}_R]-I_L[\pi(T^{-1}_{WC_L}T_{WC_R}\pi^{-1}(\mathbf{u}_R,D_R[\mathbf{u}_R]))]
ep(TWCL)=IR[uR]−IL[π(TWCL−1TWCRπ−1(uR,DR[uR]))]
其中
π
(
⋅
)
\pi(\cdot)
π(⋅) 是将相机坐标系中的一个3D点投影到图像平面上的函数,
π
(
⋅
)
−
1
\pi(\cdot)^{-1}
π(⋅)−1则执行相反的操作,将图像点反投影回3D点。
T
W
C
L
,
T
W
C
R
T_{WC_L},T_{WC_R}
TWCL,TWCR是RGB相机活动帧与参考帧的相对位姿,
D
R
D_R
DR 是被渲染出的参考深度图。这与使用最新深度测量的标准光度残差形成了直接对比,当原始输入深度不可用时,这个决定增加了跟踪的鲁棒性,例如相机太接近墙壁或表面时。
(2)ICP残差:除了光度误差,使用[2]中提出的方法,ICP残差通过最小化深度图和渲染的参考深度图之间的点平面深度残差,在RGB-D测量之间增加了额外的几何约束:
e
g
(
T
W
C
L
)
=
W
n
r
[
u
R
]
⋅
(
T
W
C
L
C
L
v
[
u
L
]
−
W
v
r
[
u
R
]
)
e_g(T_{WC_L})={_W}\mathbf{n}^r[\mathbf{u}_R]\cdot(T_{WC_L}\ {_{C_{L}}}\mathbf{v}[\mathbf{u}_L]-{_W}\mathbf{v}^r[\mathbf{u}_R])
eg(TWCL)=Wnr[uR]⋅(TWCL CLv[uL]−Wvr[uR])
其中
C
L
v
{_{C_{L}}}\mathbf{v}
CLv 是通过反向投影在相机坐标中的实时顶点地图,
W
v
r
{_W}\mathbf{v}^r
Wvr 和
W
n
r
{_W}\mathbf{n}^r
Wnr 是世界坐标系中渲染出的顶点地图和法方向地图。对于活动坐标系中的每个像素
L
u
_L\mathbf{u}
Lu,它在参考坐标系中对应的像素
u
R
\mathbf{u}_R
uR 可以通过投影和重投影计算出来。
u
R
=
π
(
T
W
C
R
−
1
T
W
C
L
π
−
1
(
u
R
,
D
R
[
u
R
]
)
)
\mathbf{u}_R=\pi(T_{WC_R}^{-1}T_{WC_L}\pi^{-1}(\mathbf{u}_R,D_R[\mathbf{u}_R]))
uR=π(TWCR−1TWCLπ−1(uR,DR[uR]))
(3)测量不确定性权重:为了公平地权衡RGB和深度传感器对于RGB相机位姿
T
W
C
T_{WC}
TWC 的贡献,需要对获得每个传感器测量值的不确定度。对于RGB相机,假定每个像素的测量不确定度是统一且固定的。对于深度传感器,深度测量值的质量与RGB-D传感器的结构和深度范围有关。使用 [28] 中深度测量不确定度的逆协方差定义,给定基线
b
b
b,视差
d
d
d,焦距
f
f
f以及 x-y 平面
σ
x
y
\sigma_{xy}
σxy 和视差方向
σ
z
\sigma_z
σz,
x
,
y
,
z
x,y,z
x,y,z 坐标上的深度测量的标准差
σ
D
\sigma_D
σD 可以建模为:
σ
D
(
D
L
[
u
L
]
f
σ
x
y
,
D
L
[
u
L
]
f
σ
x
y
,
D
L
2
[
u
L
]
f
b
σ
z
)
\sigma_{D}(\frac{D_L[\mathbf{u}_L]}{f}\sigma_{xy},\frac{D_L[\mathbf{u}_L]}{f}\sigma_{xy},\frac{D_L^2[\mathbf{u}_L]}{fb}\sigma_{z})
σD(fDL[uL]σxy,fDL[uL]σxy,fbDL2[uL]σz)
因此,使用测量不确定度逆协方差的ICP残差的权重为:
w
g
=
1
(
W
n
r
)
T
W
n
r
σ
D
T
σ
D
w_g=\frac{1}{({_W}\mathbf{n}^r)^T{_W}\mathbf{n}^r\sigma_D^T\sigma_D}
wg=(Wnr)TWnrσDTσD1
(4)惯性残差:为了使我们的系统对视觉或深度数据具有鲁棒性,我们采用[28]中的方法,并于惯性项中在参考帧与实时帧之间对IMU测量值进行了数值预积分,以估计参考帧和实时帧的RGB相机姿态,以及速度和IMU偏差。惯性残差如下:
e
S
=
x
^
L
(
x
R
)
⊟
x
L
\mathbf{e}_S=\hat{\mathbf{x}}_L(\mathbf{x}_R)\boxminus\mathbf{x}_L
eS=x^L(xR)⊟xL
其中
x
R
\mathbf{x}_R
xR 是参考状态,
x
^
L
\hat{\mathbf{x}}_L
x^L 是从参考状态通过IMU测量传播预测的实时状态。
5.3 物体跟踪
为了处理环境中的物体,我们采用了MID-Fusion [8] 中的方法,在实时坐标系
T
C
L
O
i
T_{C_LO_i}
TCLOi 中估计第i个物体
O
i
O_i
Oi 和RGB相机位姿
C
C
C 的相对位姿。这一部分计算是与传感器跟踪分离开的。首先,物体掩膜使用Mask R-CNN提取,紧接着进行几何和运动的细化。其次,与之关联的光度和ICP残差项都被参数化到以物体为中心的形式,以估计
T
C
L
O
i
T_{C_LO_i}
TCLOi。与物体关联的ICP残差被修改,以使活动物体帧中的活动顶点图与参考物体帧中的渲染顶点图对齐:
e
g
(
T
C
L
O
i
)
=
C
W
O
i
−
1
W
n
r
[
u
R
]
⋅
(
T
C
L
O
i
−
1
C
L
v
[
u
]
L
−
T
W
O
i
−
1
W
v
r
[
u
R
]
)
e_g(\mathbf{T}_{C_LO_i})=\mathbf{C}_{WO_i}^{-1}{_W}\mathbf{n}^r[\mathbf{u}_R]\cdot(T_{C_LO_i}^{-1}\ {_{C_L}}\mathbf{v[\mathbf{u}]}_L-T_{WO_i}^{-1}{_W}\mathbf{v}^r[\mathbf{u}_R])
eg(TCLOi)=CWOi−1Wnr[uR]⋅(TCLOi−1 CLv[u]L−TWOi−1Wvr[uR])
类似地,光度残差被重新参数化为:
e
p
(
T
C
L
O
i
)
=
I
R
[
u
R
]
−
I
L
[
π
(
u
L
)
]
e_p(\mathbf{T}_{C_LO_i})=I_R[\mathbf{u}_R]-I_L[\pi(\mathbf{u}_L)]
ep(TCLOi)=IR[uR]−IL[π(uL)]
其中
u
L
\mathbf{u}_L
uL 现在是
u
L
=
T
C
L
O
i
T
C
R
O
i
−
1
π
−
1
(
u
R
,
D
R
[
u
R
]
)
\mathbf{u}_L=T_{C_LO_i}T_{C_RO_i}^{-1}\pi^{-1}(\mathbf{u}_R,D_R[\mathbf{u}_R])
uL=TCLOiTCROi−1π−1(uR,DR[uR])
然后使用Causs-Newton算法对上述以物体为中心的残差进行三层从粗到细的优化。
5.4 物体重定位
在许多实际应用中,环境中的物体并不总是静态的,RGB-D传感器也不总是可以观察到的,这使得以前丢失的物体在稍后的时间重新观察到具有挑战性。以前的工作并没有解决这个问题。在这项工作中,作者提出了一种基于关键帧的物体重定位方法来处理这种情况。
与MID-Fusion类似,作者进行物体层面的光线投射,将物体检测结果与已有模型关联起来。对于每个不匹配的物体,我们初始化一个基于八叉树的体素表示的[12]新物体模型。它的物体坐标w.e.t.世界坐标系
T
W
O
i
T_{WO_i}
TWOi 被设置为单位旋转矩阵和根据深度测量
D
L
D_L
DL 得到的平移量。当一个物体与一个已经存在的物体匹配的IoU超过0.8时,我们就将这些颜色、深度和语义概率集成到模型之中。与物体相关联的物体关键帧也会被创建,带有被检测到的BRISK特征点[36]。新的关键帧只在视角变化大于
10
°
10\degree
10° 时才被添加。每一个物体关键帧都包含了相机到物体的相对位姿
T
C
O
i
T_{CO_i}
TCOi、图像关键点
z
∈
R
2
\mathbf{z}\in\mathbb{R}^2
z∈R2、特征描述符和相机坐标系下的与每个关键点关联的物体点
C
p
∈
R
3
_C\mathbf{p}\in\mathbb{R}^3
Cp∈R3 。
一个物体离开相机的视场被标记为丢失,并且在每个后续帧中进行重定位。为了节省计算资源,重定位管线仅在物体中心不接近图像边缘的每个不匹配检测时触发,这以重定位阈值
R
(
O
i
)
R(O_i)
R(Oi) 的形式实现,并定义为:
R
(
O
i
)
=
S
current
(
O
i
)
S
max
(
O
i
)
R(O_i)=\frac{S_{\text{current}}(O_i)}{S_{\text{max}}(O_i)}
R(Oi)=Smax(Oi)Scurrent(Oi)
其中
S
current
(
O
i
)
S_{\text{current}}(O_i)
Scurrent(Oi) 是当前物体掩膜的大小,
S
max
(
O
i
)
S_{\text{max}}(O_i)
Smax(Oi) 是最大物体掩膜大小,我们发现
R
(
O
i
)
>
0.7
R(O_i)>0.7
R(Oi)>0.7 的结果最好。
当一个丢失的物体被重新观测到且上面的重定位阈值满足要求时,重定位管线如下(如图4所示):
1)通过以前的物体关键帧获取物体关键点和特征描述子,以进行迭代,
2)对物体原有与当前帧新检测到的特征点进行匹配,
3)找到所有物体关键帧中的最佳匹配,
4)在最匹配的特征点上进行Pnp求解,以获取被检测物体的相对位姿
T
C
R
C
L
T_{C_RC_L}
TCRCL ,再用以获得
T
C
L
O
i
T_{C_LO_i}
TCLOi,
5)物体位姿
T
W
O
i
T_{WO_i}
TWOi 使用公式(14)(15)进一步细化。如果残差太大,物体匹配结果会视为无效,
6)一旦物体位姿被恢复,我们将删除新的重复物体模型并检索先前重建的物体模型。
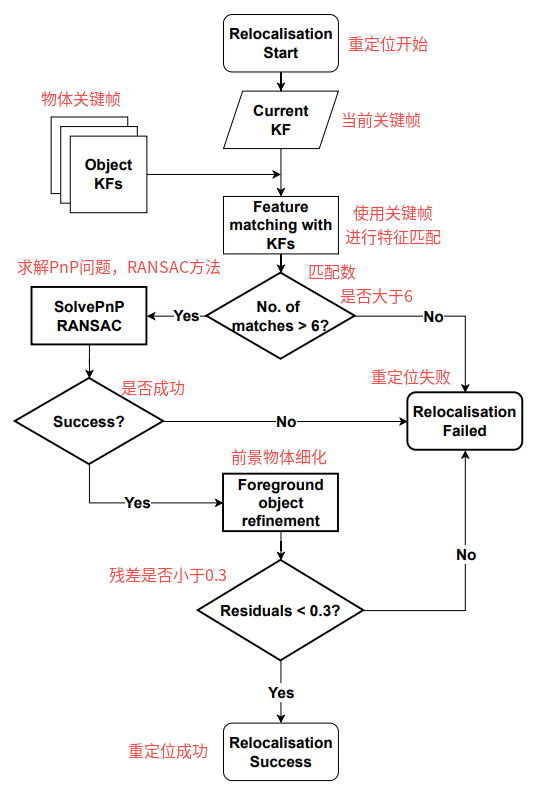
图4:物体重定位管线
6. 实验结果
6.1 实验设置
6.2 跟踪性能评估
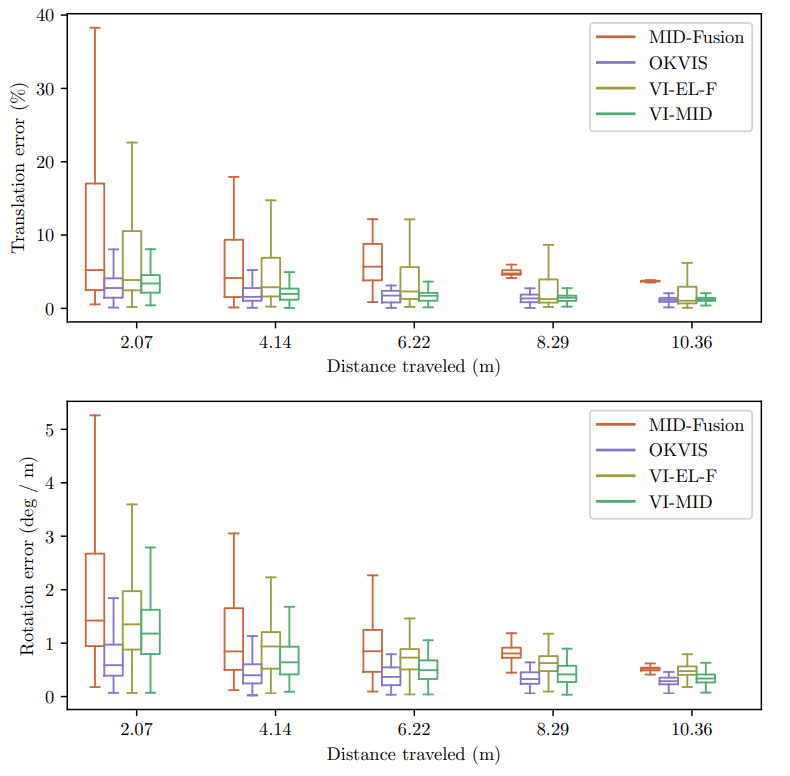
图5:MID-Fusion,OKVIS,VI-EL-F和VI-MID在VD-3序列上的漂移分析。VI-MID随时间漂移最小,而MID-Fusion不能完成轨迹。
6.3 物体重建

图6:房间尺度场景重建定性验证。

图7:MID-Fusion和VI-MID之间的定性比较:左图-输入的RGB图像爱嗯,中间-MID-Fusion重建结果,右图-VI-MID重建结果。
6.4 物体重定位
![在这里插入图片描述]()

图8:使用/不使用物体重定位时瓶子重建效果的定性比较。
6.5 运行时间分析
6.6 讨论
7. 总结
作者介绍了一种能够处理多动态物体的视觉惯性稠密SLAM系统,主要优点:IMU增强了跟踪鲁棒性,减轻Mask R-CNN间歇物体检测的影响(依靠从物体地图获得的渲染掩码持续跟踪环境中的物体)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)